深度学习-门控循环单元(GRU)
GRU
GRU(Gated Recurrent Unit,门控循环单元)是循环神经网络(RNN)的重要变体,专为解决传统 RNN 的 “长序列依赖” 问题而设计。它在 LSTM 的基础上简化了结构,同时保留了处理时序数据的能力,在自然语言处理、时间序列预测等领域应用广泛。以下从结构细节、模型对比、应用场景、改进变体等方面补充 GRU 的深度知识。
预备知识
GRU 的核心是门控机制,通过两个门控单元(更新门、重置门)控制信息的流动,最终输出一个 “隐藏状态”(hidden state)来保留时序信息。其核心公式和机制可拆解为:
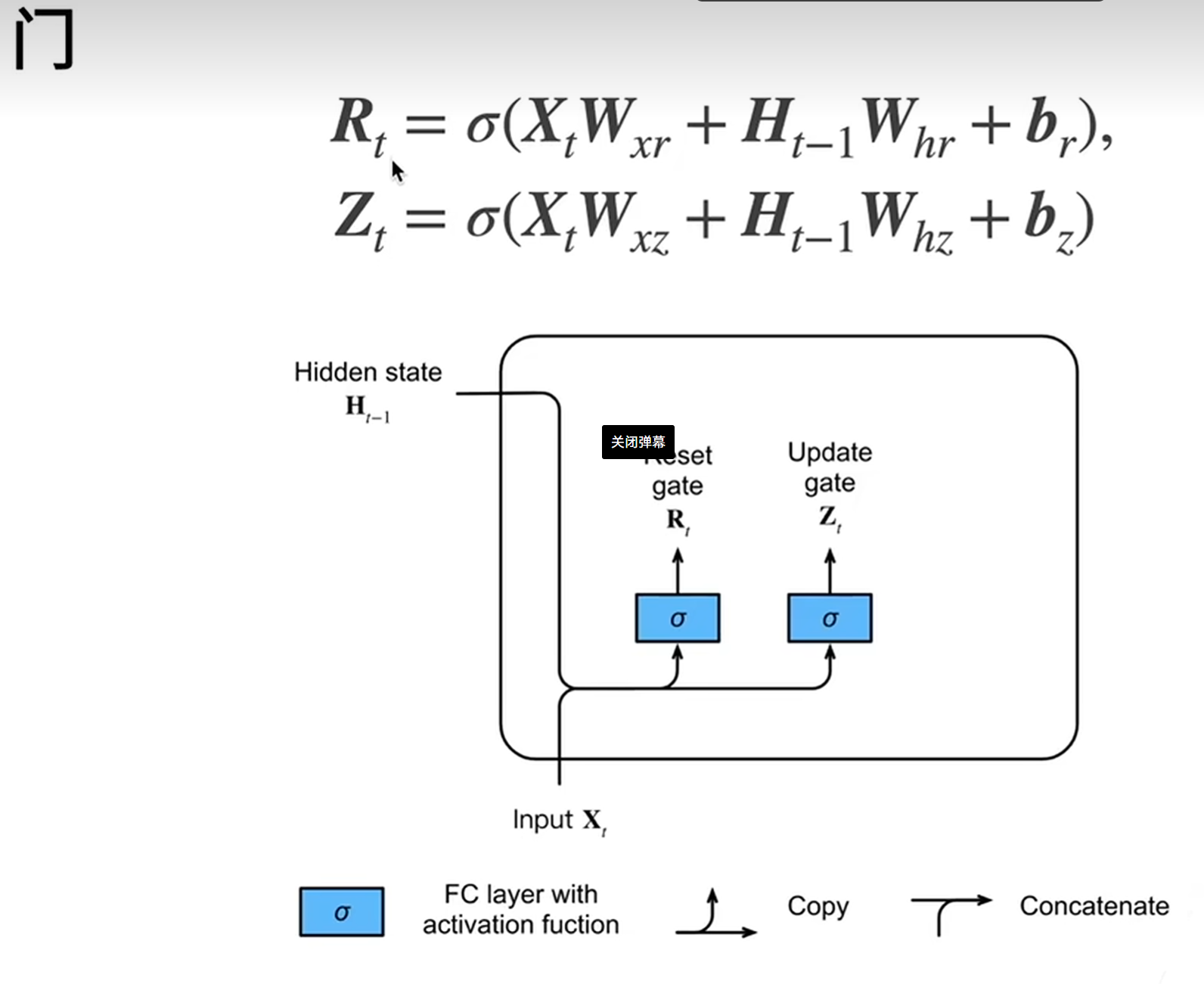
- 门控单元的作用GRU 通过两个门控单元(均使用 sigmoid 激活函数,输出范围 [0,1])控制信息传递:
-
- 重置门(Reset Gate):决定如何利用历史隐藏状态与当前输入 “拼接” 生成新信息。公式:
-
-
为当前输入,
为上一时刻隐藏状态,
为权重矩阵,
为偏置,
-
-
- 若
趋近于1:保留更多历史信息,适合学习长序列依赖;
- 若
- 若
-
-
- 更新门(Update Gate):决定保留多少历史隐藏状态,以及融入多少当前新信息。公式:
-
-
- 若
趋近于1:更多保留历史状态
- 若
。
-
- 若
-
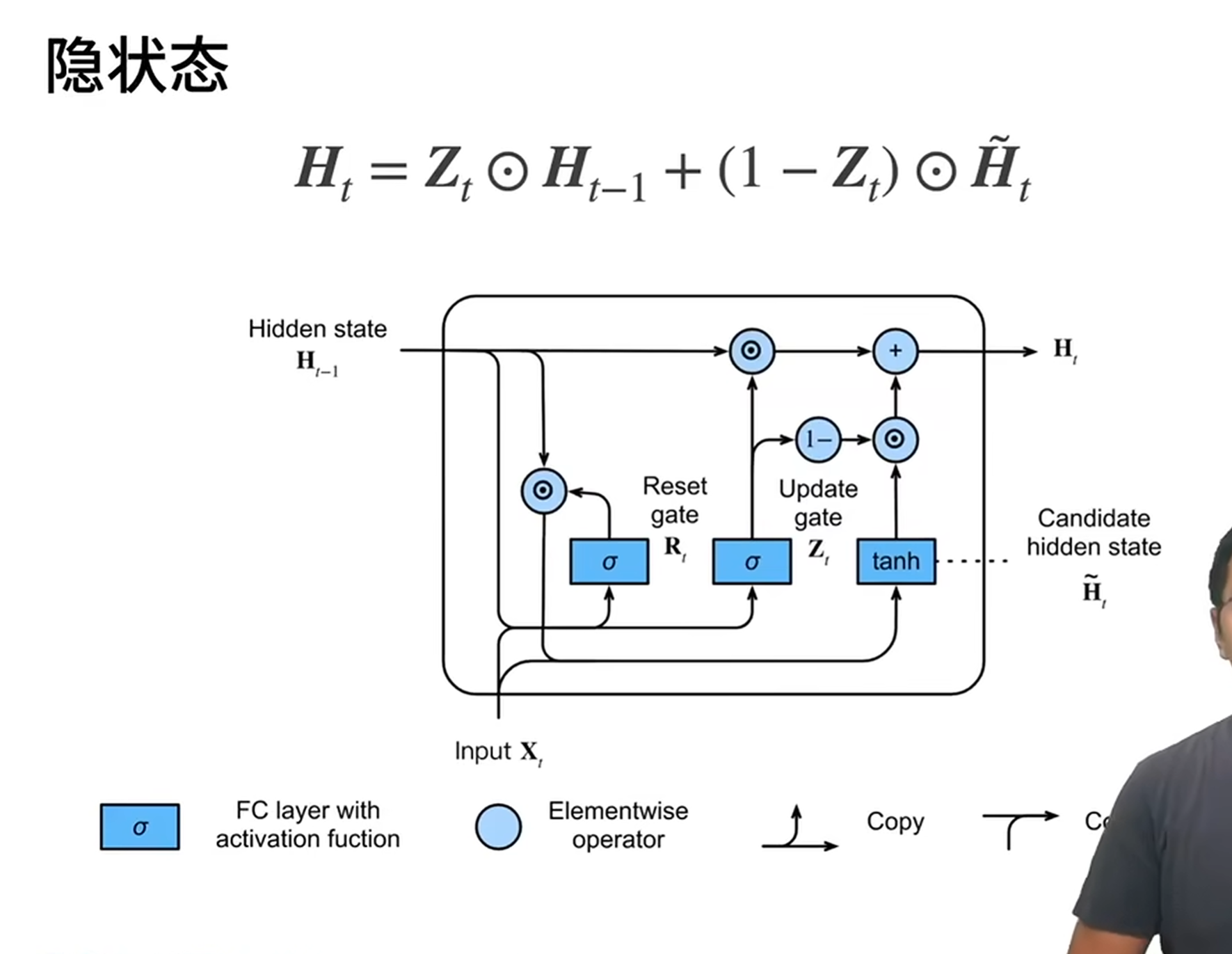
- 候选隐藏状态与最终状态
-
- 候选隐藏状态\(\tilde{h}_t\):结合重置门筛选后的历史信息与当前输入,用 tanh 激活(输出范围 [-1,1]):
-
- 最终隐藏状态\(h_t\):由更新门平衡历史状态与候选状态:
获取参数
def get_params(vocab_size,num_hiddens,device):
num_inputs=num_outputs=vocab_size
def normal(shape):
return torch.randn(size=shape,device=device)*0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device=device))
w_xz,w_hz,b_z=three()#更新门参数
w_xr,w_hr,b_r=three()#重置门参数
w_xh,w_hh,b_h=three()#候选隐状态参数
#输出层参数
w_hq=normal((num_hiddens,num_outputs))
b_q=torch.zeros(num_outputs,device=device)
params=[w_xz,w_hz,b_z,w_xr,w_hr,b_r,w_xh,w_hh,b_h,w_hq,b_q]
for param in params:
param.requires_grad_(True)
return params这段代码定义了一个get_params函数,用于初始化循环神经网络(具体来说是 GRU,门控循环单元)的参数。以下是解释:
- 函数作用:创建并返回 GRU 模型所需的所有参数,包括权重和偏置项,并将这些参数设置为可训练(需要计算梯度)。
- 参数说明:
-
vocab_size:词汇表大小,用于确定输入和输出层的维度num_hiddens:隐藏层的维度大小device:参数存放的设备(如 CPU 或 GPU)
- 内部函数:
-
normal(shape):生成指定形状的随机张量,使用均值为 0、标准差为 0.01 的正态分布初始化,这是神经网络参数初始化的常用方法three():生成一组包含三个参数的元组,分别对应输入到隐藏层的权重、隐藏层到隐藏层的权重,以及偏置项
- GRU 核心参数:
-
- 更新门(update gate)参数:
w_xz, w_hz, b_z - 重置门(reset gate)参数:
w_xr, w_hr, b_r - 候选隐状态(candidate hidden state)参数:
w_xh, w_hh, b_h
- 更新门(update gate)参数:
- 输出层参数:
-
w_hq:从隐藏层到输出层的权重b_q:输出层的偏置项
- 参数处理:
-
- 将所有参数收集到一个列表中
- 为每个参数设置
requires_grad_(True),表示这些参数需要在反向传播时计算梯度,从而可以通过梯度下降进行更新
这段代码的作用是初始化 GRU 模型的所有可学习参数,为后续的模型训练做好准备。通过这种方式手动初始化参数,而不是使用框架自带的层,有助于更深入地理解 GRU 的内部工作机制。
隐藏层和gru函数
def init_gru_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),)
def gru(inputs,state,params):
w_xz, w_hz, b_z, w_xr, w_hr, b_r, w_xh, w_hh, b_h, w_hq, b_q=params
H, =state
outputs=[]
for X in inputs:
Z=torch.sigmoid((X@w_xz)+(H@w_hz)+b_z)
R=torch.sigmoid((X@w_xr)+(H@w_hr)+b_r)
H_tilta=torch.tanh((X@w_xh)+((R*H)@w_hh)+b_h)
H=Z*H+(1-Z)*H_tilta
Y=H@w_hq+b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)这段代码实现了 GRU(Gated Recurrent Unit,门控循环单元)的核心功能,包括初始化隐藏状态和 GRU 的前向计算过程。下面是详细解释:
1. init_gru_state 函数
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),)- 功能:初始化 GRU 的隐藏状态
- 参数说明:
-
batch_size:批次大小(一次处理的样本数量)num_hiddens:隐藏层神经元数量device:计算设备(CPU 或 GPU)
- 返回值:一个包含初始化隐藏状态的元组,隐藏状态是形状为
(batch_size, num_hiddens)的零矩阵
GRU 与标准 RNN 不同,它只有一个隐藏状态(而 LSTM 有细胞状态和隐藏状态两个),这里用元组包装是为了保持与其他循环神经网络接口的一致性。
2. gru 函数
def gru(inputs, state, params):
# 解包参数
w_xz, w_hz, b_z, w_xr, w_hr, b_r, w_xh, w_hh, b_h, w_hq, b_q = params
H, = state # 解包隐藏状态
outputs = []
# 对输入序列中的每个时间步进行计算
for X in inputs:
# 计算更新门 Z (Update Gate)
Z = torch.sigmoid((X @ w_xz) + (H @ w_hz) + b_z)
# 计算重置门 R (Reset Gate)
R = torch.sigmoid((X @ w_xr) + (H @ w_hr) + b_r)
# 计算候选隐藏状态 H_tilta
H_tilta = torch.tanh((X @ w_xh) + ((R * H) @ w_hh) + b_h)
# 更新隐藏状态 H
H = Z * H + (1 - Z) * H_tilta
# 计算当前时间步的输出
Y = H @ w_hq + b_q
outputs.append(Y)
# 拼接所有时间步的输出,并返回最终隐藏状态
return torch.cat(outputs, dim=0), (H,)参数说明:
inputs:输入序列,形状为(时间步数量, 批次大小, 输入特征维度)state:初始隐藏状态,由init_gru_state函数生成params:GRU 的所有可学习参数,包括:
-
- 更新门参数:
w_xz(输入到更新门的权重)、w_hz(隐藏状态到更新门的权重)、b_z(更新门偏置) - 重置门参数:
w_xr(输入到重置门的权重)、w_hr(隐藏状态到重置门的权重)、b_r(重置门偏置) - 候选隐藏状态参数:
w_xh、w_hh、b_h - 输出层参数:
w_hq(隐藏状态到输出的权重)、b_q(输出偏置)
- 更新门参数:
GRU 核心计算过程:
- 更新门(Z):决定保留多少过去的隐藏状态,取值范围 (0,1)
-
- 接近 1 表示更多保留过去的隐藏状态
- 接近 0 表示更多采用新的候选隐藏状态
- 重置门(R):决定如何结合新输入和过去的隐藏状态,取值范围 (0,1)
-
- 控制过去的隐藏状态对候选隐藏状态的影响
- 候选隐藏状态(H_tilta):结合当前输入和经过重置门过滤的过去隐藏状态
- 更新隐藏状态(H):通过更新门平衡过去的隐藏状态和新的候选隐藏状态
- 输出(Y):根据当前隐藏状态计算输出
这个实现清晰地展示了 GRU 的门控机制如何解决传统 RNN 的梯度消失问题,通过学习控制信息的流动,使模型能够更好地捕捉长序列依赖关系。
模型训练
vocab_size,num_hiddens,device=len(vocab),256,d2l.try_gpu()
num_epochs,lr=500,1
model=RNNFromScratch.RNNModuleScratch(vocab_size,num_hiddens,device,get_params,init_gru_state,gru)
RNNFromScratch.train_ch8(model,train_iter,vocab,num_epochs,lr,device)这段代码是使用深度学习框架(基于 d2l 库)实现和训练一个循环神经网络(RNN),具体来说是 GRU(门控循环单元)模型,用于自然语言处理任务(如文本生成)。以下是逐步解释:
- 变量初始化:
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()-
vocab_size:词汇表大小,即文本数据中不重复词的总数num_hiddens:隐藏层的维度大小,这里设置为 256device:计算设备,使用d2l.try_gpu()尝试获取可用的 GPU,如果没有则使用 CPU
- 训练参数设置:
num_epochs, lr = 500, 1-
num_epochs:训练的轮数,这里设置为 500 轮lr:学习率,这里设置为 1
- 模型实例化:
model = RNNFromScratch.RNNModuleScratch(vocab_size, num_hiddens, device, get_params, init_gru_state, gru)-
- 创建了一个自定义的 RNN 模型实例
- 参数包括词汇表大小、隐藏层维度、计算设备
- 还传入了三个关键函数:
-
-
get_params:用于获取模型参数init_gru_state:用于初始化 GRU 的隐藏状态gru:GRU 的前向传播函数
-
- 模型训练:
RNNFromScratch.train_ch8(model, train_iter, vocab, num_epochs, lr, device)-
- 调用自定义的训练函数开始训练模型
- 传入的参数包括:模型实例、训练数据迭代器、词汇表、训练轮数、学习率和计算设备
train_ch8是指第 8 章的训练函数
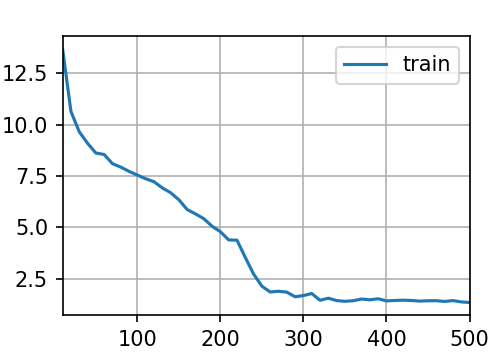
总的来说,这段代码完成了一个 GRU 模型的初始化和训练设置,准备用于处理文本数据。这类模型通常用于文本生成、语言建模等自然语言处理任务。训练过程会通过多次迭代优化模型参数,使模型能够学习文本序列中的模式和规律。
输出结果:

简洁实现
注意,RNNFromScratch和RNNSimple都是由本人实现的python文件,并不是导入的python库
#简洁实现
num_inputs=vocab_size
gru_layer=nn.GRU(num_inputs,num_hiddens)
model=RNNSimple.RNNModule(gru_layer,len(vocab))
model=model.to(device)
RNNFromScratch.train_ch8(model,train_iter,vocab,num_epochs,lr,device)
plt.show()这段代码展示了使用深度学习框架(看起来是 PyTorch)简洁实现 GRU(门控循环单元)模型并进行训练的过程,相比上一段代码更偏向于使用框架内置组件而非手动实现:
注意:RNNFromScratch和RNNSimple都是本人自己写的python文件,并非某些python库
- 输入维度设置:
num_inputs = vocab_size
这里将输入维度设为词汇表大小,因为文本数据通常会通过独热编码或嵌入层转换为与词汇表大小匹配的输入维度。
- 创建 GRU 层:
gru_layer = nn.GRU(num_inputs, num_hiddens)
使用 PyTorch 的nn.GRU创建了一个 GRU 层,参数包括:
-
num_inputs:输入特征的维度(即词汇表大小)num_hiddens:隐藏层的维度(与前面的 256 保持一致)
- 构建完整模型:
model = RNNSimple.RNNModule(gru_layer, len(vocab))
将 GRU 层封装到一个自定义的 RNN 模块中,第二个参数是词汇表大小,可能用于模型的输出层(将隐藏状态映射到词汇表空间)。
- 设置计算设备:
model = model.to(device)
将模型移动到之前指定的计算设备(GPU 或 CPU)上进行计算。
- 模型训练:
RNNFromScratch.train_ch8(model, train_iter, vocab, num_epochs, lr, device)
使用与之前相同的训练函数进行模型训练,参数包括模型、训练数据迭代器、词汇表、训练轮数、学习率和计算设备。
- 显示图像:
plt.show()
显示训练过程中可能生成的图表(如损失曲线、准确率曲线等)。
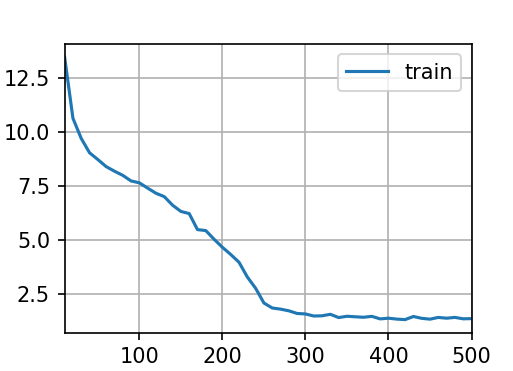
总的来说,这段代码通过使用框架内置的 GRU 层简化了模型实现过程,无需手动定义参数和前向传播逻辑,更适合实际应用开发。训练过程与之前的手动实现共享同一套训练函数,保证了实验的一致性。
输出结果:

代码汇总
import torch
from torch import nn
from d2l import torch as d2l
import NaturalLanguage_Dataset
import RNNFromScratch
import RNNSimple
import matplotlib.pyplot as plt
batch_size,num_steps=32,35
train_iter,vocab=NaturalLanguage_Dataset.load_data_time_machine(batch_size,num_steps,max_tokens=10000)
def get_params(vocab_size,num_hiddens,device):
num_inputs=num_outputs=vocab_size
def normal(shape):
return torch.randn(size=shape,device=device)*0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device=device))
w_xz,w_hz,b_z=three()#更新门参数
w_xr,w_hr,b_r=three()#重置门参数
w_xh,w_hh,b_h=three()#候选隐状态参数
#输出层参数
w_hq=normal((num_hiddens,num_outputs))
b_q=torch.zeros(num_outputs,device=device)
params=[w_xz,w_hz,b_z,w_xr,w_hr,b_r,w_xh,w_hh,b_h,w_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
def init_gru_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),)
def gru(inputs,state,params):
w_xz, w_hz, b_z, w_xr, w_hr, b_r, w_xh, w_hh, b_h, w_hq, b_q=params
H, =state
outputs=[]
for X in inputs:
Z=torch.sigmoid((X@w_xz)+(H@w_hz)+b_z)
R=torch.sigmoid((X@w_xr)+(H@w_hr)+b_r)
H_tilta=torch.tanh((X@w_xh)+((R*H)@w_hh)+b_h)
H=Z*H+(1-Z)*H_tilta
Y=H@w_hq+b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)
vocab_size,num_hiddens,device=len(vocab),256,d2l.try_gpu()
num_epochs,lr=500,1
model=RNNFromScratch.RNNModuleScratch(vocab_size,num_hiddens,device,get_params,init_gru_state,gru)
RNNFromScratch.train_ch8(model,train_iter,vocab,num_epochs,lr,device)
#简洁实现
num_inputs=vocab_size
gru_layer=nn.GRU(num_inputs,num_hiddens)
model=RNNSimple.RNNModule(gru_layer,len(vocab))
model=model.to(device)
RNNFromScratch.train_ch8(model,train_iter,vocab,num_epochs,lr,device)
plt.show()
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)