三种数据标准化方法的对比:StandardScaler、MinMaxScaler、RobustScaler
在数据预处理中,标准化是常见的步骤,常用的方法包括StandardScaler、MinMaxScaler和RobustScaler。StandardScaler通过减去均值并除以标准差进行标准化,适用于正态分布数据,但对异常值敏感。MinMaxScaler将数据缩放到固定范围(如[0,1]),适用于需要固定范围的场景,但对异常值同样敏感。RobustScaler基于中位数和四分位距进行标准化,对异
StandardScaler(标准差标准化,适用于正态分布数据),MinMaxScaler(极差标准化,适用于分布范围稳定的数据)和RobustScaler(稳健标准化,适用于异常值较多的数据)
1 StandardScaler()—标准差标准化
from sklearn.preprocessing import StandardScaler
# 选择需要标准化的列(通常不标准化类别变量,如 hour, month, is_weekend)
numeric_cols = ['lag_1', 'lag_2', 'lag_3', 'lag_4', 'total_power'] # 数值列
scaler = StandardScaler() #(Z-score标准化)
# 标准化数值列
data[numeric_cols] = scaler.fit_transform(data[numeric_cols])
- 计算方法:
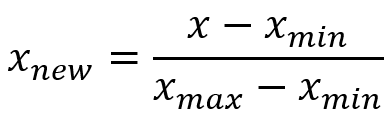
μ是列的均值,σ 是标准差。
- 结果范围
如果数据原本服从正态分布,标准化后约 99.7%的数据落在[-3,3]区间内(根据 3σ原则),如果数据有极端异常值,可能会超出这个范围(例如-5或10)。
2 MinMaxScaler()—极差标准化(归一化)
scaler = MinMaxScaler() #(归一化)- 计算方法:
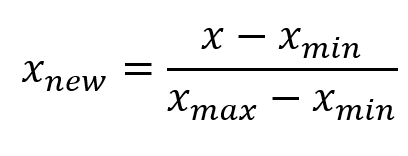
- 结果范围:在[0, 1]之间
- 如果指定目标范围不是 [0,1],而是 [a,b],则公式扩展为:
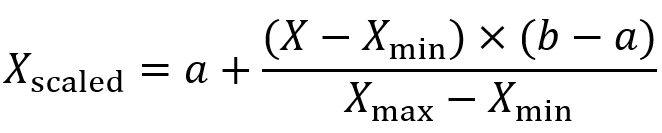
3 RobustScaler()—稳健标准化
scaler = RobustScaler()- 计算方法:
计算中位数:对于每个特征,计算其中位数(第50百分位数)
计算四分位距(IQR):IQR=第75百分位数(Q3)-第25百分位数(Q1)
缩放数据:对每个数据点执行以下转换:
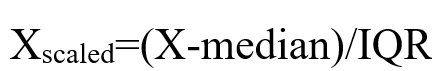
- 结果范围:没有严格的上下限
4 三种标准化方法比较
|
特性 |
StandardScaler |
MinMaxScaler |
RobustScaler |
|
计算方法 |
(X - μ) / σ(μ: 均值,σ: 标准差) |
(X - min) / (max - min) |
(X - median) / IQR(IQR = Q3 - Q1) |
|
结果范围 |
无固定范围(理论±∞,通常±3内) |
默认 [0, 1](可调范围) |
无固定范围(异常值可能超出) |
|
对异常值敏感度 |
高(均值和标准差受异常值影响大) |
高(min/max 直接受异常值影响) |
低(基于中位数和IQR) |
|
适用场景 |
数据近似正态分布且无显著异常值 |
需要固定范围(如图像像素归一化) |
数据含异常值或非正态分布 |
|
优点 |
保留原始分布形状,适用于许多模型 |
结果严格限定范围,直观易解释 |
抗异常值能力强,适用于非正态数据 |
|
缺点 |
受异常值影响大 |
对异常值敏感,可能压缩正常数据 |
非异常值范围可能不如StandardScaler稳定 |
|
Scikit-learn 类 |
sklearn.preprocessing.StandardScaler |
sklearn.preprocessing.MinMaxScaler |
sklearn.preprocessing.RobustScaler |
选择建议:
- 无异常值且分布较正态→StandardScaler(如线性回归、SVM、神经网络)
- 需要固定范围→MinMaxScaler(如深度学习输入归一化、图像处理)
- 存在异常值或长尾分布→RobustScaler(如金融数据、离群点多的场景)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)