达梦数据库--分区表的介绍
是一种物理数据库设计技术,通过把数据量庞大的数据库表以各种方式划分成若干个“比较小的部分”,访问时只处理需要的部分,不需要的部分则直接跳过。
分区表
1. 基本概念
1.1 分区表的定义
是一种物理数据库设计技术,通过把数据量庞大的数据库表以各种方式划分成若干个“比较小的部分”,访问时只处理需要的部分,不需要的部分则直接跳过。
1.2 分区表的目的
为了提高数据库在大数据量读写操作和查询效率,DM实现了表分区技术。
1.3 分区表分类
水平分区、垂直分区。
2. 水平分区
2.1 水平分布表支持功能
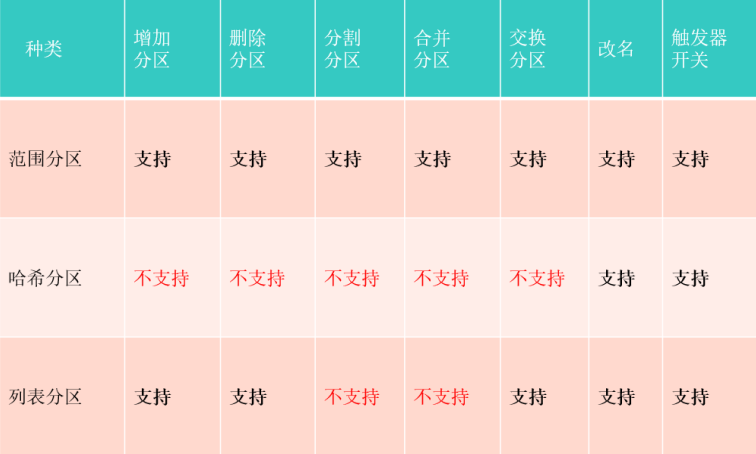
2.2 范围分区
2.2.1 概念
按照某个列的值范围来划分分区,通常是日期、数值等连续数据类型的列。例如,对于一个员工工资信息表,可以按照工资范围划分分区,如0 - 5000为一个分区,5001 - 10000为另一个分区等。
语法格式:
|
CREATE TABLE [表名] ( [列定义1], [列定义2], ... ) PARTITION BY RANGE ([分区列]) ( PARTITION [分区名1] VALUES LESS THAN ([边界值1]), PARTITION [分区名2] VALUES LESS THAN ([边界值2]), ... ); |
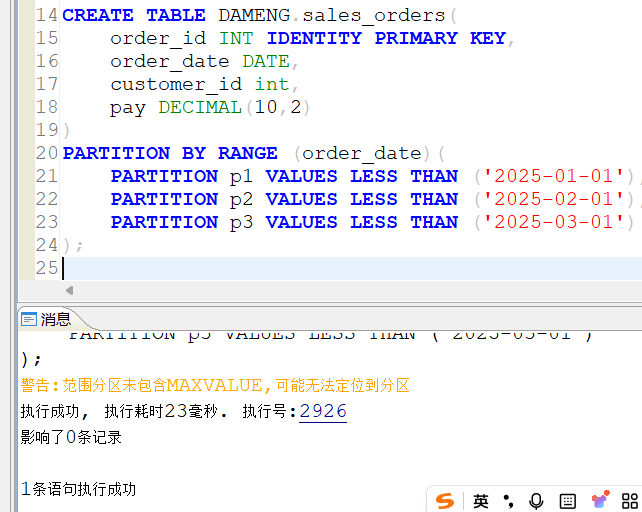
2.2.2 创建表及分区
创建一个销售订单信息表sales_orders,按照日期进行分区
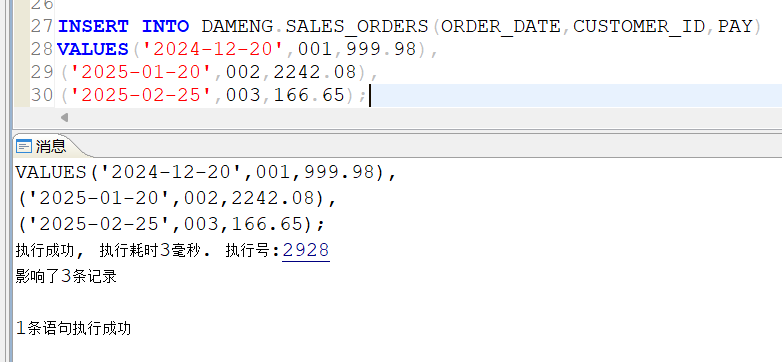
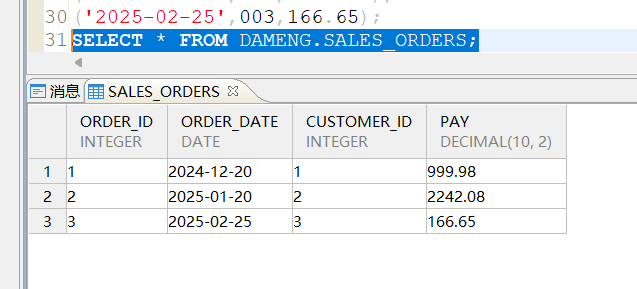
向sales_orders表中插入3条不同日期的订单信息,插入完成后查询sales_orders信息:
2.2.3 验证分区
下面开始验证范围分区是否达到预期效果:
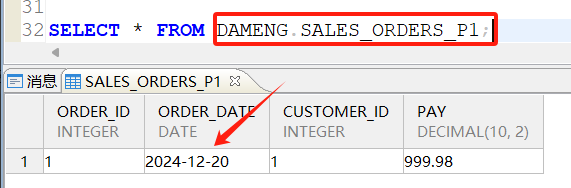
查询P1分区,预期2024-12-20的订单信息应该存储在P1分区:
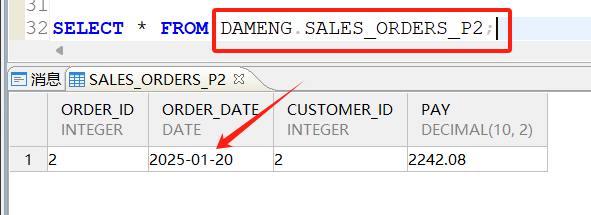
查询P2分区,预期2025-01-20的订单信息应该存储在P2分区:
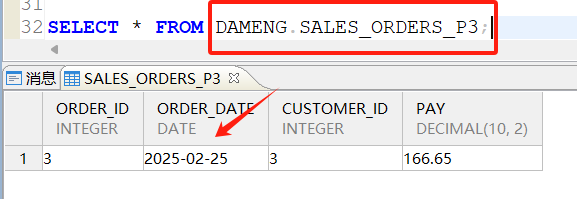
查询P3分区,预期2024-02-25的订单信息应该存储在P3分区:
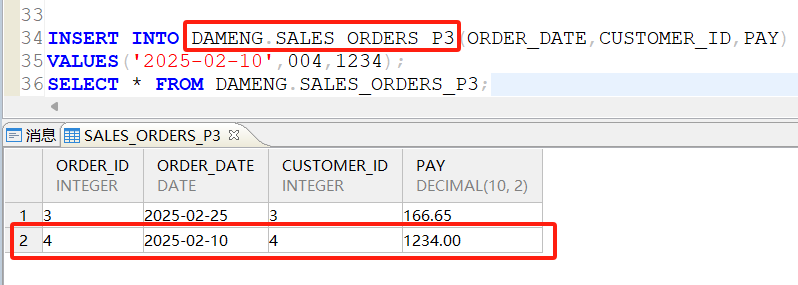
向分区中插入数据并进行select查询(向P3分区插入一条数据):
修改p3分区中customer_id = 4的支付金额为4567:
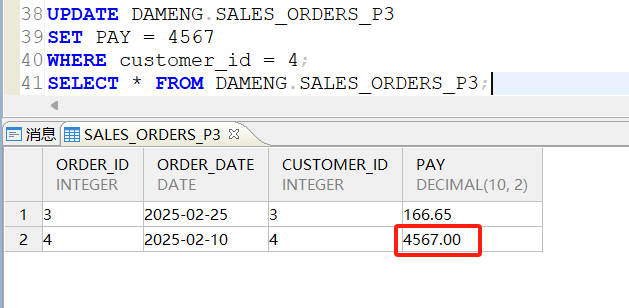
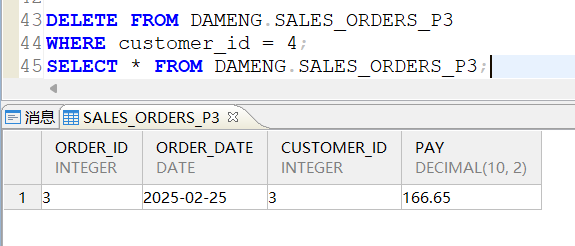
删除p3分区中customer_id = 4的订单信息:
2.2.4 新增分区
增加一个p4分区:

2.2.5 分割分区
分割p4分区为p5和p6分区:

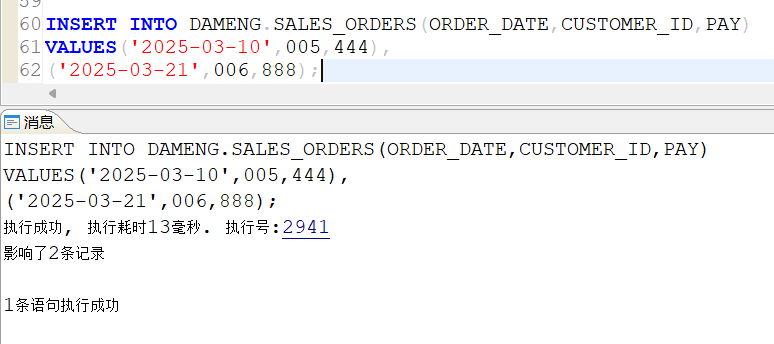
向sales_orders表中插入两条数据来验证p5和p6分区:
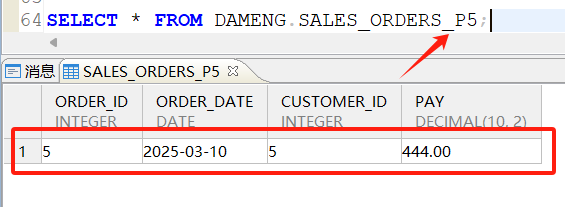
查询p5分区:
查询p6分区:
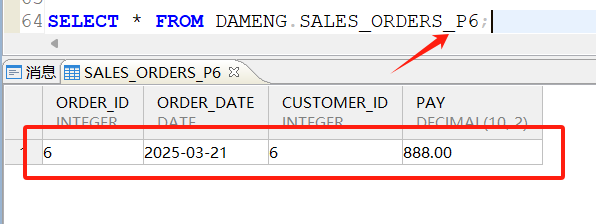
2.2.6 合并分区
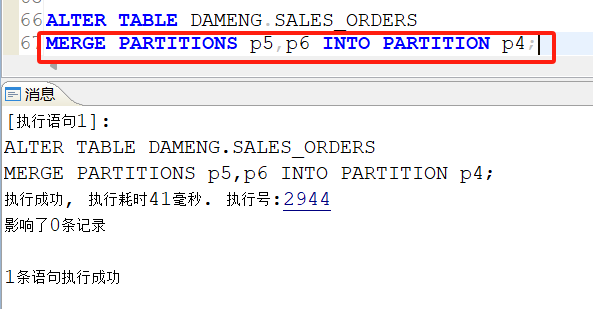
将p5和p6再进行合并分区,合并为p4分区,可以与之前的分割分区同名:
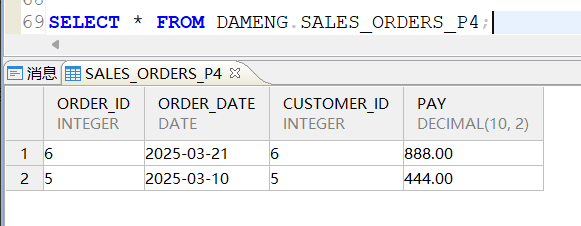
查询p4分区验证合并情况:
2.2.7 交换分区
先创建一个与sales_orders数据结构相同的表copy_sales_orders:
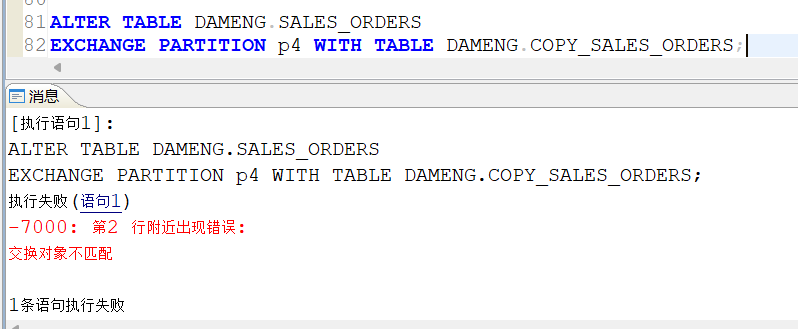
这里报错,可能是因为数据表使用了自增列作id导致的。。。
2.2.8 清空子分区
利用truncate table 表名 partition(分区名) 清空子分区,清空后执行select查询进行验证:
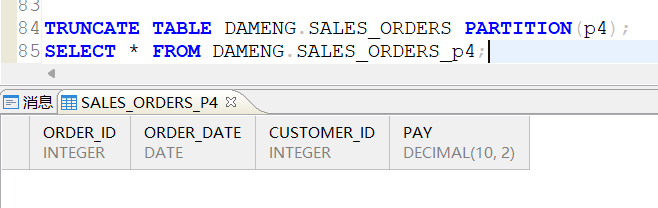
2.2.9 删除分区
删除p4分区:
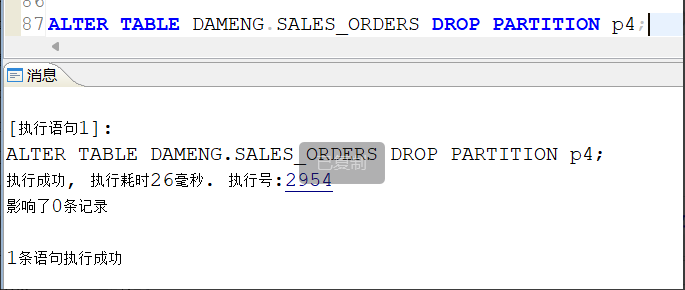
2.3 列表分区
2.3.1 概念
原理:根据列的离散值列表来划分分区。例如,对于一个存储产品信息的表,可以按照产品类别(如电子设备、家居用品、食品等)进行列表分区,每个分区包含特定类别的产品数据。
适用场景:适用于列的取值是有限的几个离散值,且经常按照这些离散值进行分组查询或操作的情况。比如按照地区、部门、产品类别等划分数据。
语法格式:
|
CREATE TABLE [表名] ( [列定义1], [列定义2], ... ) PARTITION BY LIST ([分区键列]) ( PARTITION [分区名1] VALUES ([值列表1]), PARTITION [分区名2] VALUES ([值列表2]), ... PARTITION 默认分区名 VALUES (DEFAULT) – 用于处理未匹配成功的值 ); 参数说明: 分区键列:用于分区的列,需为表中的某一列。 VALUES (值列表):指定该分区包含的离散值,值列表需用括号包裹。 DEFAULT 分区(可选):当分区键列的值不在任何 VALUES 列表中时,数据存入默认分区。 |
2.3.2 创建表及分区
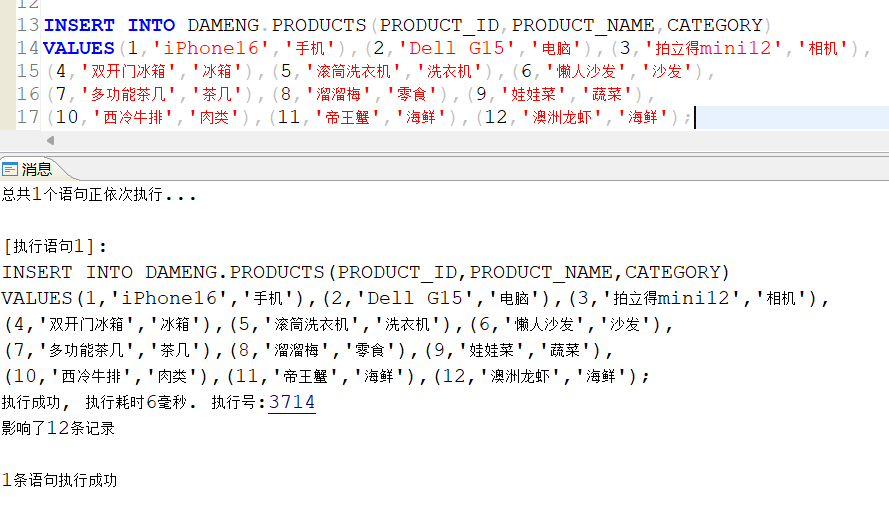
创建产品表products,并利用水平分区中的列表分区对其进行分区。安装产品的类别category为分区的条件,分为电子设备p_electronics、食品p_food、家具p_furniture三大类。

2.3.3 验证分区
先对produs插入数条数据,涉及到所有类别的离散值:
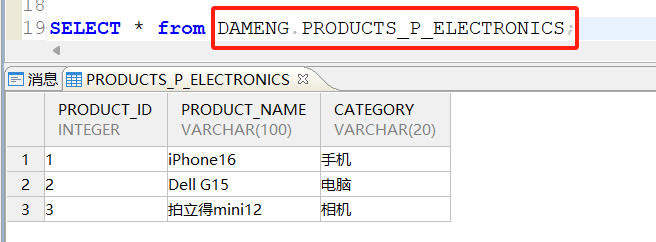
查询电子设备p_electronics分区:
查询食品p_food分区:
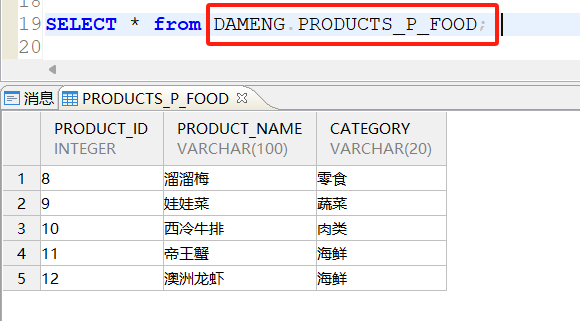
查询家具p_furniture分区:
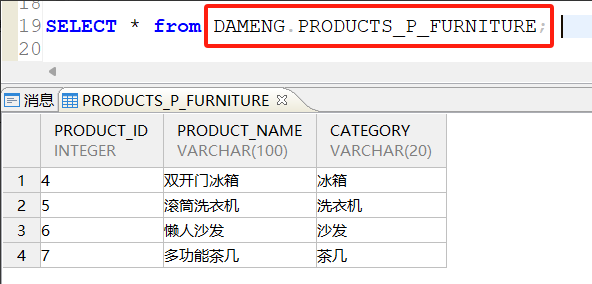
两种查询语法格式都可以:

2.3.4 新增分区
新增护肤品p_hufu和洗漱用品p_xishu分区:
插入数据后查看护肤品p_hufu和洗漱用品p_xishu分区:
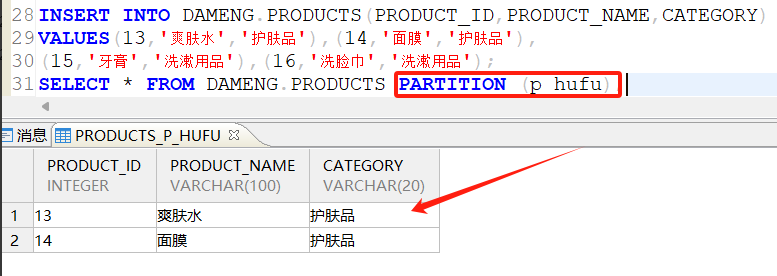
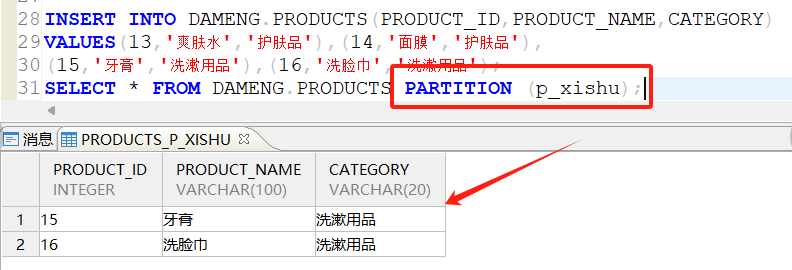
2.3.5 删除分区
删除洗漱用品分区p_xishu:
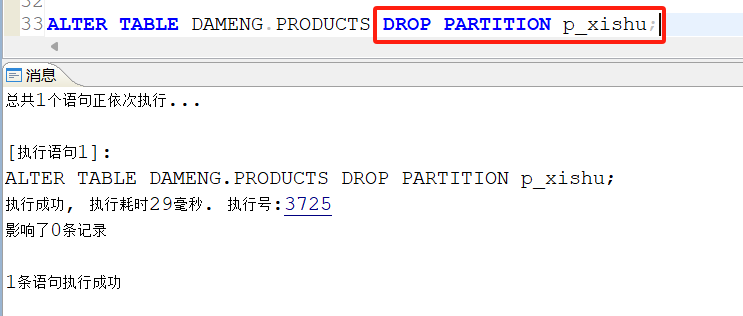
2.4 哈希分区
2.4.1 概念
通过对分区列进行哈希函数运算,根据哈希值来划分分区。哈希分区的目的是将数据均匀地分布到各个分区中,以平衡各个分区的数据量和I/O负载。例如,对于一个存储用户信息的表,可以对用户ID进行哈希分区。
适用场景:适用于数据分布比较均匀,且希望在插入数据时自动将数据均匀分配到各个分区的情况。这种分区方式在大规模数据存储和高并发数据访问的场景中比较常用,如分布式数据库系统。
语法格式:
|
CREATE TABLE [表名] ( [列定义1], [列定义2], ... ) PARTITION BY HASH ([分区列]) PARTITIONS [分区数量]; |
2.4.2 创建表及分区
创建一个教师表teacher,并对其进行哈希分区,设置安装teacher_id列进行哈希分区,分区的数量设置为3个:
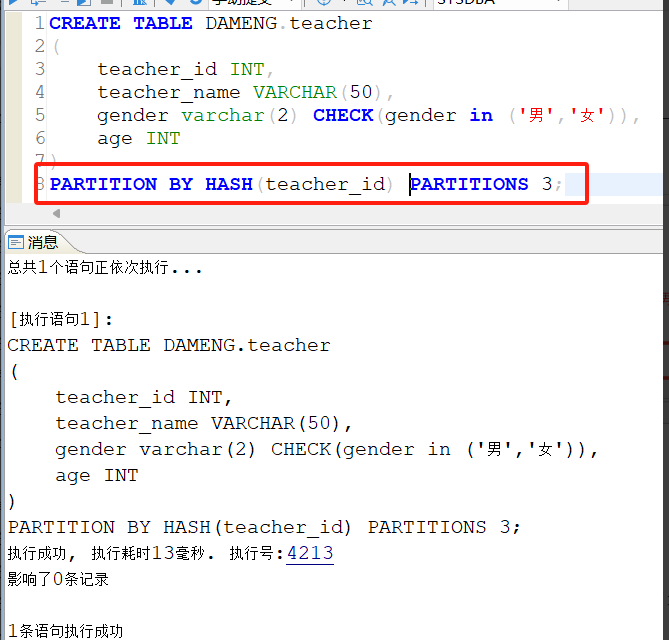
2.4.3 验证分区
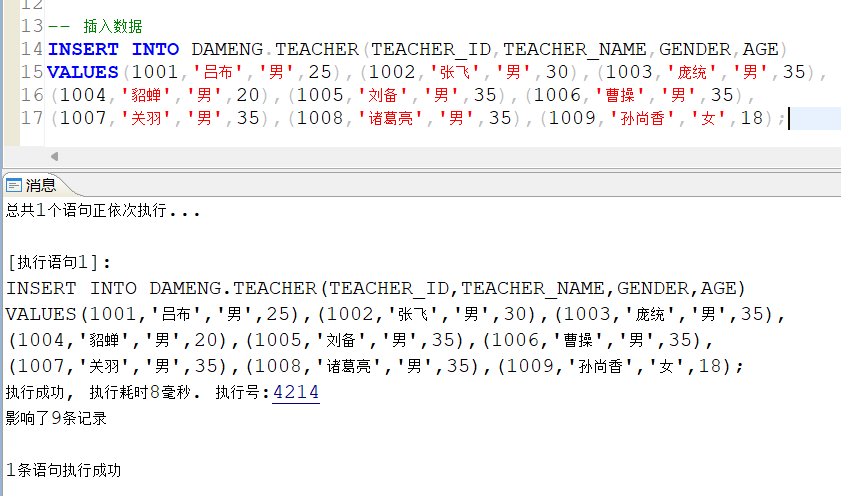
插入多条数据:
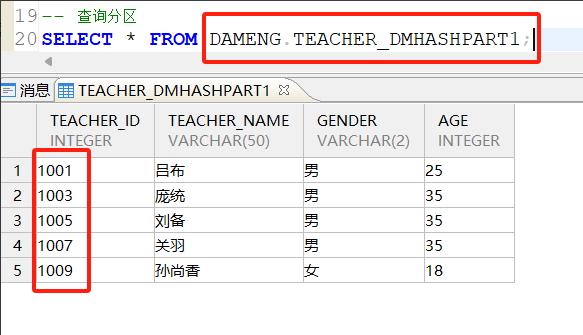
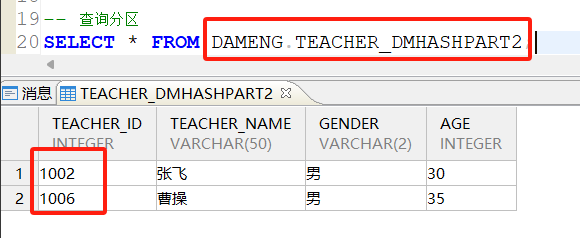
分了三个区:TEACHER_DMHASHPART0,TEACHER_DMHASHPART1,TEACHER_DMHASHPART2,接下来分别查看三个分区中的数据:
TEACHER_DMHASHPART0分区:

TEACHER_DMHASHPART1分区:
TEACHER_DMHASHPART2分区:
3. 垂直分区
基本概念:
垂直分区通过对表的垂直划分来减少目标表的宽度,使某些特定的列被划分到特定的分区,每个分区都包含了其中的列所对应的行。
垂直分区将一个表分为多个子表,每个子表包含较少的列。垂直分区使查询得以扫描较少的数据,减少I/O量,从而提高查询性能。
垂直分区的适用场景:
1. 大字段分离
将 BLOB、TEXT 等大字段独立存储,避免影响小字段的查询性能。
示例:将用户表的头像图片(BLOB)单独分区。
BLOB(Binary Large Object,二进制大对象):是一种用于存储大量二进制数据的容器,常用于数据库中存储图像、音频、视频等多媒体文件BLOB类型的数据可以按文本或二进制格式进行读取, 也可以转换成可读流进行数据操作。
2. 权限控制
将敏感列(如薪资、身份证号)单独分区,限制访问权限。
示例:仅授权特定用户访问 salary 分区。
3. 高频与低频列分离
高频查询的列(例如订单ID、用户ID)与 低频统计列(例如日志、备注)分开存储。
4. 减少I/O开销
避免查询时读取不必要的列,降低磁盘和网络负载。
达梦技术社区 | 达梦数据库: 达梦数据库 - 新一代大型通用关系型数据库 | 达梦在线服务平台

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)