8.15 机器学习(2)K最近邻算法
1、定义:K 近邻(K-Nearest Neighbor, KNN)用最近的 K 个已知样本代表/决定未知样本的类别。预测X和Y的值,选择最优K值交叉验证,标明范围。适用小规模、低维、类别边界不规则的数据。④ 统计这 K 个邻居中类别出现频率,K 值选择、距离度量方式决定模型效果。练习:导入葡萄酒数据集(为分类问题)① 计算未知点到所有已知点的距离,③ 选前 K 个(K ≤ 20),⑤ 将频率最高
一、算法核心思想
1、定义:K 近邻(K-Nearest Neighbor, KNN)用最近的 K 个已知样本代表/决定未知样本的类别
2、步骤:
① 计算未知点到所有已知点的距离,
② 按距离升序排序,
③ 选前 K 个(K ≤ 20),
④ 统计这 K 个邻居中类别出现频率,
⑤ 将频率最高的类别作为预测结果,
二、距离度量
-
欧式距离(Euclidean)
多维空间两点直线距离:
d = √Σ(xi – yi)² -
曼哈顿距离(Manhattan)
各维度绝对值之和:
d = Σ|xi – yi|
三、鸢尾花数据集练习(为分类问题)
将鸢尾花数据集导入库,生成数据
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 设置随机种子,保证结果可复现
np.random.seed(0)#加载鸢尾花数据集
iris=datasets.load_iris()
iris分三类
将他们分类、增加特征、类别名
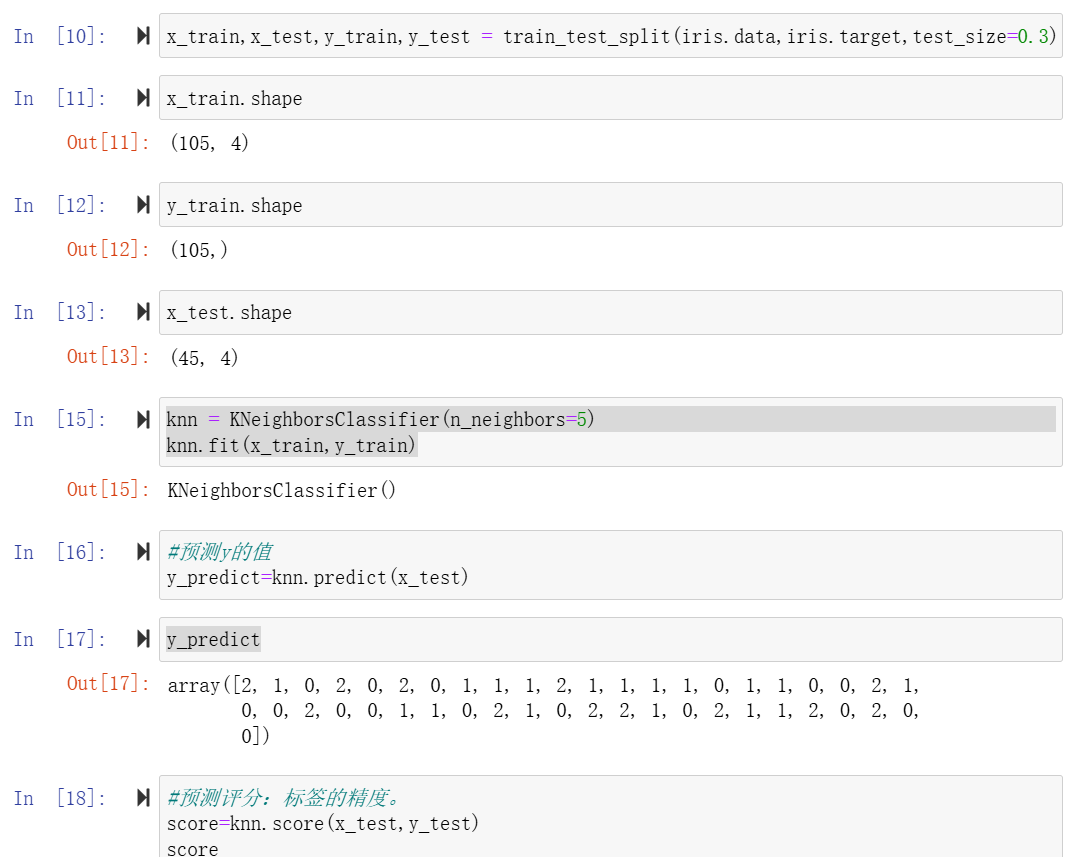
最终KNN邻近值选取并验证
四、自己新找一个数据集
练习:导入葡萄酒数据集(为分类问题)
#导入葡萄酒数据集
wine = datasets.load_wine()
wine加载前十行数据wine.data[:10] 葡萄酒的特征值

给他分类标签并标明特征和类别。
训练和测试X和Y
预测X和Y的值,选择最优K值交叉验证,标明范围。最后画图
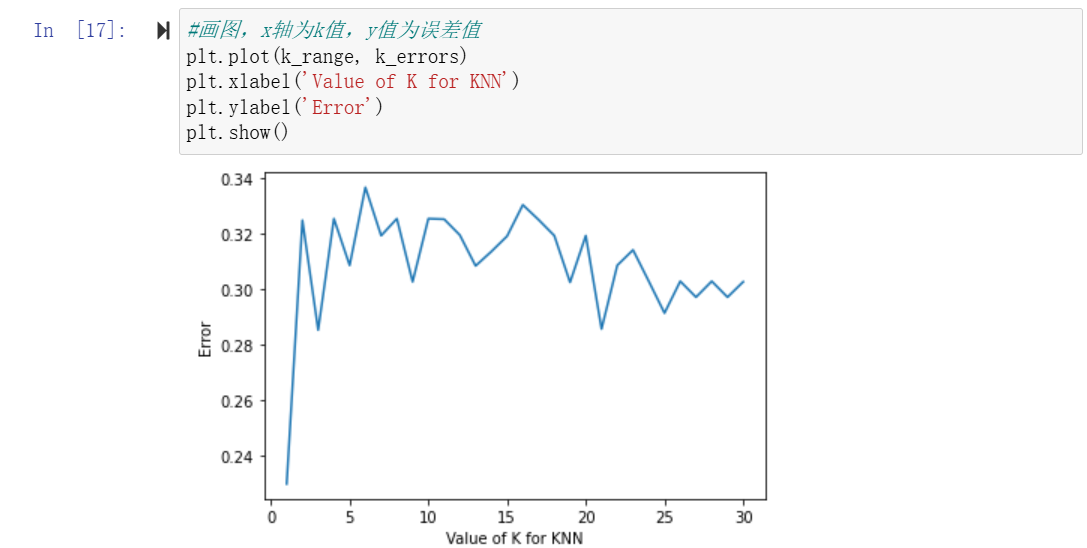
K 值选择、距离度量方式决定模型效果。
适用小规模、低维、类别边界不规则的数据。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)