在Middlebury及ETH3D数据集上在线评估
最近想使用middlebury数据集和ETH3D测一下算法的效果如何,奈何网上没有完整的搭建middlebury离线环境的教程,自己查阅资料和阅读官方readme文档总结如下教程。推荐两个博主的文章,非常有用。
前言
最近想使用middlebury数据集和ETH3D测一下算法的效果如何,奈何网上没有完整的搭建middlebury离线环境的教程,自己查阅资料和阅读官方readme文档总结如下教程。
推荐两个博主的文章,非常有用。
windows下Middlebury离线工具使用(补充)
立体视觉数据集之MiddleBury离线使用踩坑记录(Windows+Cygwin)
Middlebury评估
1.下载内容
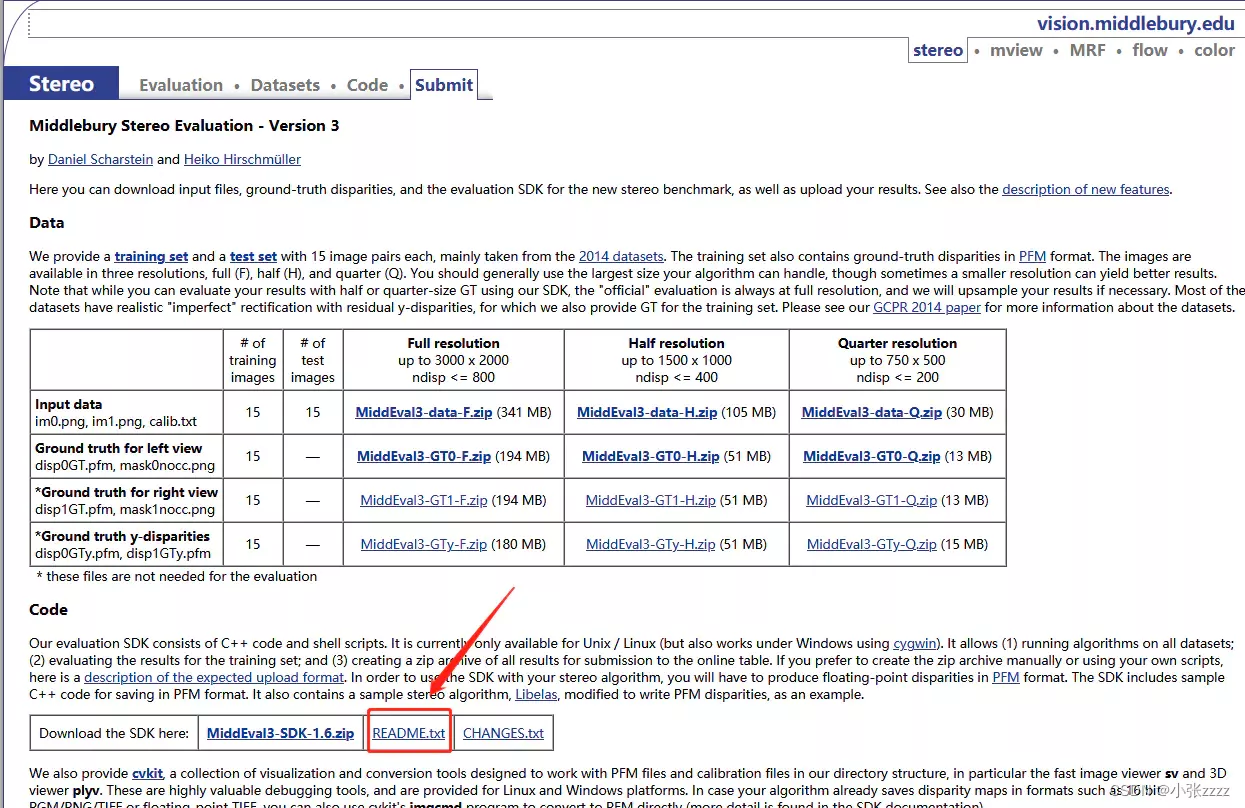
README.txt可以查看官方给的方案。
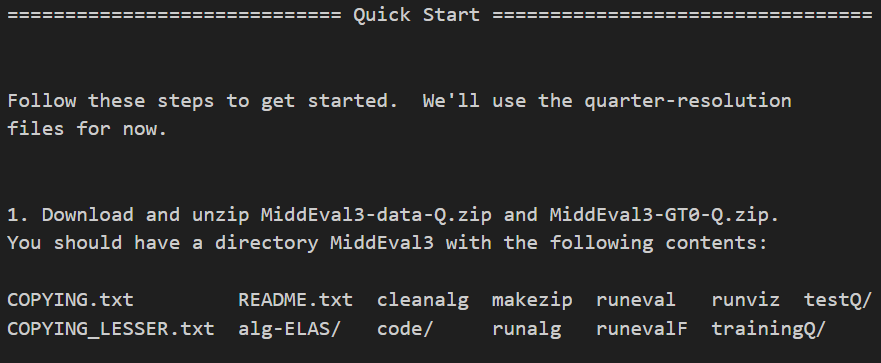
1、下载并解压MiddleEval3-data-Q.zip(原始图片及校正参数)、MiddleEval3-GT0-Q.zip(标准视差图)。(F、H、Q代表了三个不同的分辨率,按照自己的需要下载不同分辨率的图片,也可以都下载下来,一共15组,没多大),解压到同一个文件夹下,合并起来就跟说明书里面的contents部分的结构一样了

2、下载MiddEval3-SDK-1.6.zip(离线评测工具),是一些由c++代码和shell脚本组成的SDK,可以在windows环境下运行,能够在所有数据集上运行算法,评估训练集结果,和为结果创建压缩文件以及上传。进行检测需要使用后缀为.pfg的PFM格式的视差图像(算法处理后的结果图)。

3、下载cvkit工具包,用于查看.pfm格式的文件。

2.配置环境
1、安装cmake
2、安装cygwin(cygwin安装时需要手动选择make和tcsh)
3、安装MinGW(官网下载的MinGW是不包含扩展包的,然而MiddleBury中的使用到了libpng这个扩展包,所以这里分享了一个自带扩展包的MinGW,链接已经在上面了。)
4、分别为cmake、cygwin、MinGM配置环境变量。
直接建立一个env.sh,内容如下,运行即可完成环境配置
echo "-----------------Start building env---------------------"
apt-get update
apt-get install libpng-dev
apt-get install csh
apt-get install bc
apt-get install -y zip unzip
echo "------------Compile alg-ELAS-------------"
cd alg-ELAS/build
cmake ..
make
cd ../..
echo "------------Compile imageLib-------------"
cd code/imageLib
make
cd ..
make
cd ..
chmod 777 runeval
chmod 777 runalg
chmod 777 runevalF
chmod 777 runviz
chmod 777 makezip
echo "------------Finished-------------"3.离线评估
离线情况下只能评估训练集的结果,评估完会输出一个临时的结果表格,以便进行后续算法的迭代。
可以参照README.TXT的内容就行评估,主要就是下面这个指令。运行runeval评估脚本,分辨率选为F,评估所以训练集案例,这里也可以指定单个案例的名称,如Adirondack,1代表bad1.0测试。
./runeval F all 1之后会在终端打印出各个指标
mask:(水平/垂直方向上的)非遮挡区域比例
bad1.0 传递的阈值为1的时候,坏点率:即和真实结果在对应像素点位置的值的差距大于阈值的点的比例
invalid 无效点率 ,指的是那些黑色点,匹配失败,灰度为无穷大
totbad 总体坏点,坏点率 + 无效点率
avgErr 平均误差:所有的有效的点和真实结果的点的灰度差的累加和/所有有效点个数
4.在线评估
在线情况下只允许提交一次,而且提交之前是看不到自己的结果排名的。首先根据自己的双目深度估计模型推理出自己的pfm并计算推理时间txt。这里给出一个示范脚本。这里的视差保存是颠倒操作的,因为这才符合Middlebury的数据格式,如果使用正常的方法还不能正确输出pfm文件,这也会导致评估的结果数值很差,只有这样才能导出正确的pfm格式。
import sys
sys.path.append('core')
import os
import argparse
import glob
import numpy as np
import torch
from tqdm import tqdm
from pathlib import Path
from core.monster import Monster
from core.utils.utils import InputPadder
from PIL import Image
from matplotlib import pyplot as plt
import os
DEVICE = 'cuda'
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
starter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
def load_image(imfile):
img = np.array(Image.open(imfile)).astype(np.uint8)[..., :3]
img = torch.from_numpy(img).permute(2, 0, 1).float()
return img[None].to(DEVICE)
def demo(args):
model = torch.nn.DataParallel(Monster(args), device_ids=[0])
checkpoint = torch.load(args.restore_ckpt)
ckpt = dict()
if 'state_dict' in checkpoint.keys():
checkpoint = checkpoint['state_dict']
for key in checkpoint:
ckpt['module.' + key] = checkpoint[key]
model.load_state_dict(checkpoint, strict=True)
model = model.module
model.to(DEVICE)
model.eval()
output_directory = Path(args.output_directory)
output_directory.mkdir(parents=True, exist_ok=True)
with torch.no_grad():
left_images = sorted(glob.glob(os.path.join('/data2/cjd/StereoDatasets/middlebury/', "MiddEval3", 'testF', '*/im0.png')))
right_images = sorted(glob.glob(os.path.join('/data2/cjd/StereoDatasets/middlebury/', "MiddEval3", 'testF', '*/im1.png')))
print(f"Found {len(left_images)} images. Saving files to {output_directory}/")
for (imfile1, imfile2) in tqdm(list(zip(left_images, right_images))):
image1 = load_image(imfile1)
image2 = load_image(imfile2)
padder = InputPadder(image1.shape, divis_by=32)
image1, image2 = padder.pad(image1, image2)
starter.record()
disp = model(image1, image2, iters=args.valid_iters, test_mode=True)
ender.record()
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)
disp = disp.cpu().numpy()
disp = padder.unpad(disp).squeeze()
file_stem = imfile1.split('/')[-2]
filedir = Path(os.path.join(output_directory, file_stem))
filedir.mkdir(exist_ok=True)
filename = os.path.join(output_directory, file_stem, 'disp0MonoStereo.pfm')
with open(filename, 'wb') as f:
H, W = disp.shape
headers = ["Pf\n", f"{W} {H}\n", "-1\n"]
for header in headers:
f.write(str.encode(header))
array = np.flip(disp, axis=0).astype(np.float32)
f.write(array.tobytes())
filename = os.path.join(output_directory, file_stem, 'timeMonoStereo.txt')
with open(filename, 'wb') as f:
time = '%.2f' % (curr_time / 1000)
f.write(str.encode(time))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--restore_ckpt', help="restore checkpoint", default="/data2/cjd/mono_fusion/checkpoints/middlebury.pth")
parser.add_argument('--save_numpy', action='store_true', help='save output as numpy arrays')
parser.add_argument('-l', '--left_imgs', help="path to all first (left) frames", default=None)
parser.add_argument('-r', '--right_imgs', help="path to all second (right) frames", default=None)
parser.add_argument('--output_directory', help="directory to save output", default='./test_output/middlebury')
parser.add_argument('--mixed_precision', action='store_true', help='use mixed precision')
parser.add_argument('--valid_iters', type=int, default=32, help='number of flow-field updates during forward pass')
# Architecture choices
parser.add_argument('--encoder', type=str, default='vitl', choices=['vits', 'vitb', 'vitl', 'vitg'])
parser.add_argument('--hidden_dims', nargs='+', type=int, default=[128]*3, help="hidden state and context dimensions")
parser.add_argument('--corr_implementation', choices=["reg", "alt", "reg_cuda", "alt_cuda"], default="reg", help="correlation volume implementation")
parser.add_argument('--shared_backbone', action='store_true', help="use a single backbone for the context and feature encoders")
parser.add_argument('--corr_levels', type=int, default=2, help="number of levels in the correlation pyramid")
parser.add_argument('--corr_radius', type=int, default=4, help="width of the correlation pyramid")
parser.add_argument('--n_downsample', type=int, default=2, help="resolution of the disparity field (1/2^K)")
parser.add_argument('--slow_fast_gru', action='store_true', help="iterate the low-res GRUs more frequently")
parser.add_argument('--n_gru_layers', type=int, default=3, help="number of hidden GRU levels")
parser.add_argument('--max_disp', type=int, default=768, help="max disp of geometry encoding volume")
args = parser.parse_args()
demo(args)
这将输出pfm和txt文件作为在线评估的源文件。接着到官网进行评估。点击submission。
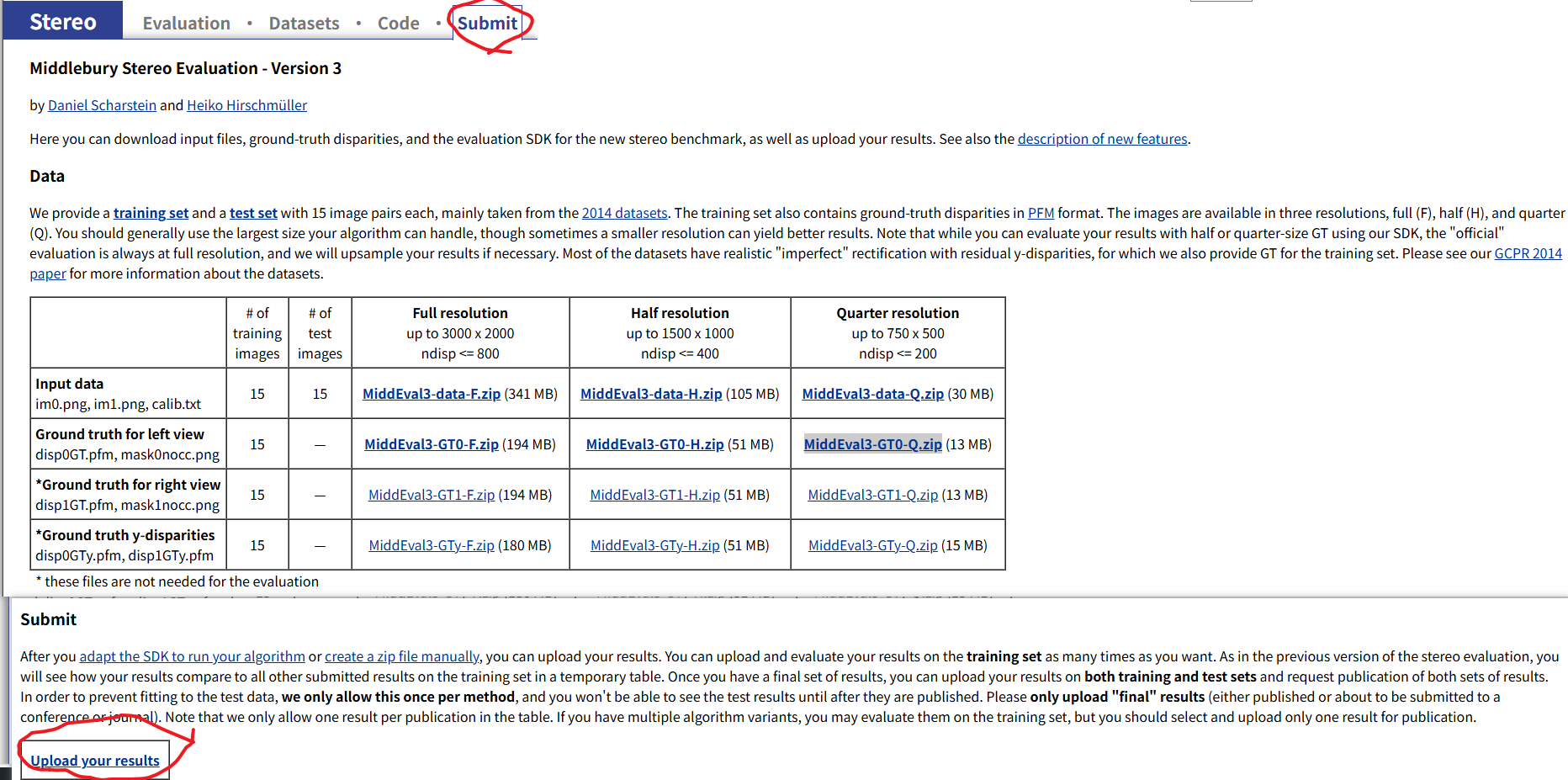
接下来就是按照步骤就行,我主要说一下上传的文件格式问题。
这个上传的文件结构需要特别注意他的要求和规范,我们需要创建一个zip压缩包,如resultF-MS2.zip,在里面把training和test分开,再分别把自己的推理结果分别放到这两个文件夹下的每个测试案例中
其中具体的文件结构如下:
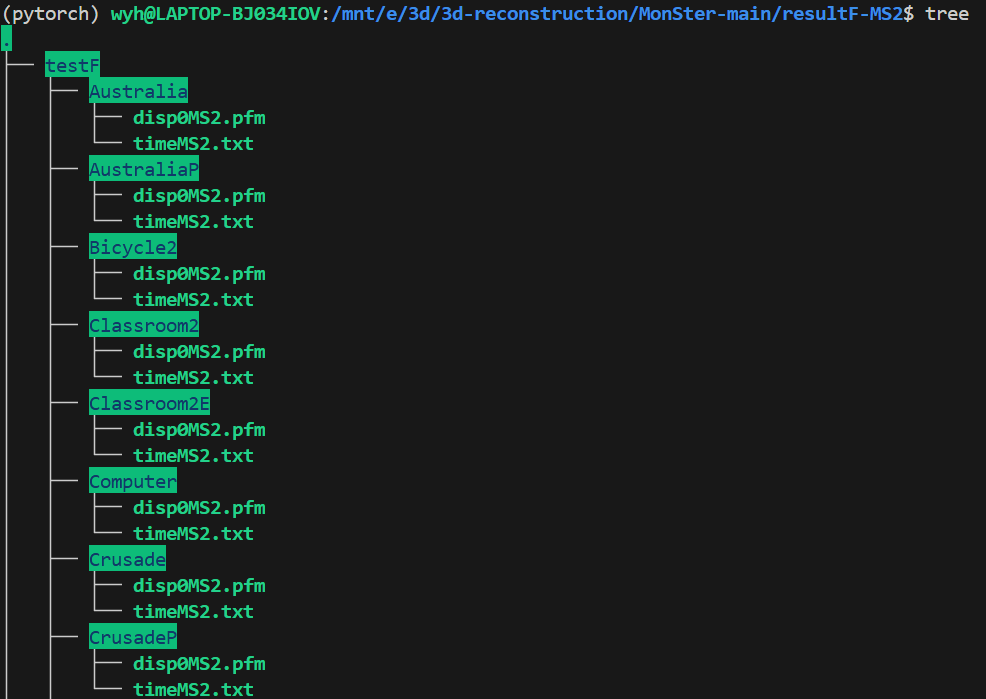
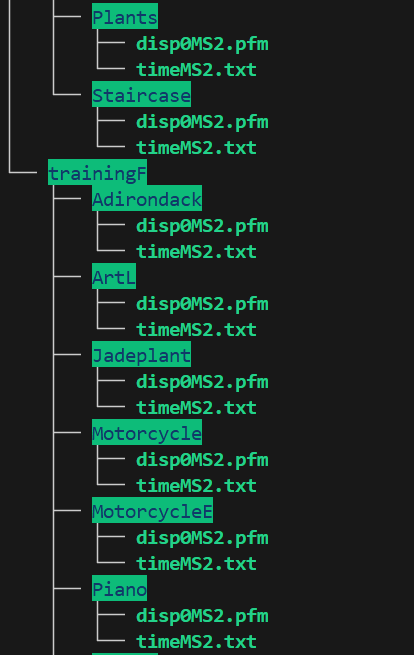
接着就可以上传zip到网站上,等待推理结果了
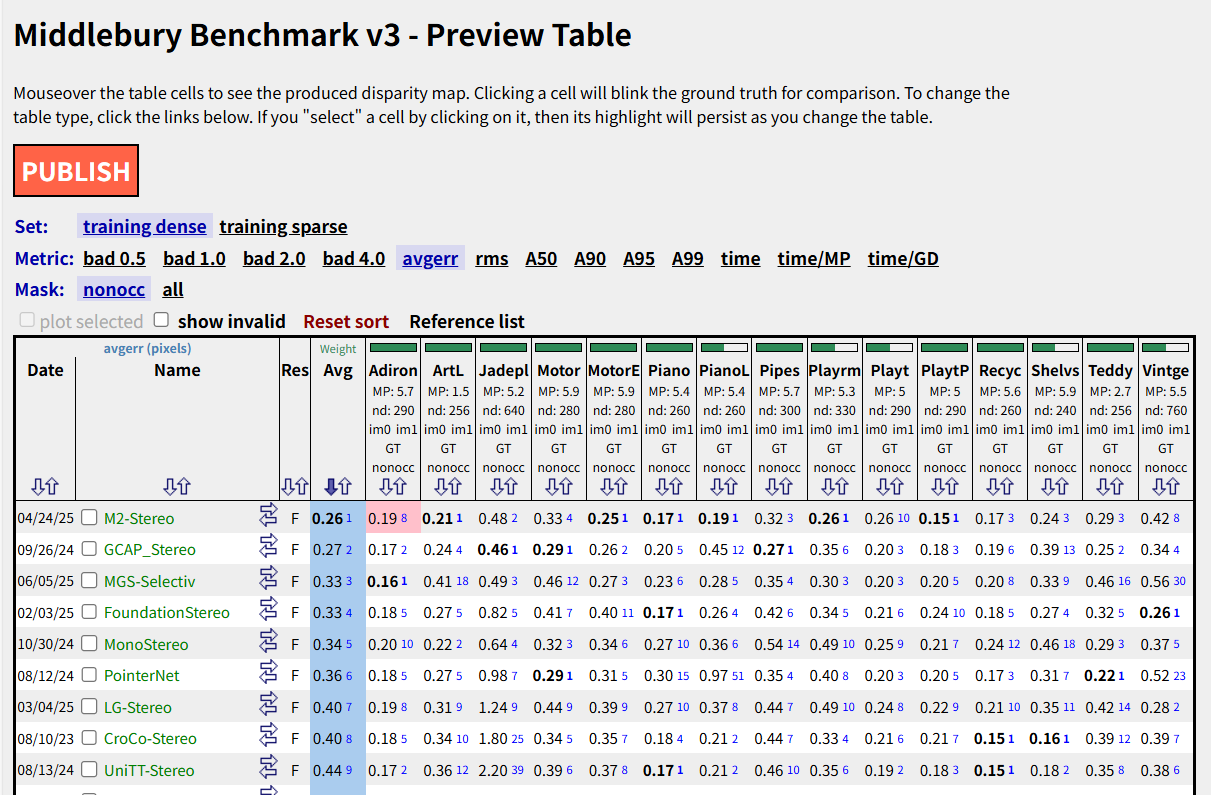

到这一步就可以等待结果发布了。
ETH3D评估
首先根据自己的双目深度估计模型推理出自己的pfm并计算推理时间txt。这里给出一个示范脚本。
import sys
sys.path.append('core')
import os
import argparse
import glob
import numpy as np
import torch
from tqdm import tqdm
from pathlib import Path
from core.monster import Monster
from core.utils.utils import InputPadder
from PIL import Image
from matplotlib import pyplot as plt
import os
DEVICE = 'cuda'
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
starter, ender = torch.cuda.Event(enable_timing=True), torch.cuda.Event(enable_timing=True)
def load_image(imfile):
img = np.array(Image.open(imfile)).astype(np.uint8)[..., :3]
img = torch.from_numpy(img).permute(2, 0, 1).float()
return img[None].to(DEVICE)
def demo(args):
model = torch.nn.DataParallel(Monster(args), device_ids=[0])
checkpoint = torch.load(args.restore_ckpt)
ckpt = dict()
if 'state_dict' in checkpoint.keys():
checkpoint = checkpoint['state_dict']
for key in checkpoint:
ckpt['module.' + key] = checkpoint[key]
model.load_state_dict(ckpt, strict=True)
model = model.module
model.to(DEVICE)
model.eval()
output_directory = Path(args.output_directory)
output_directory.mkdir(parents=True, exist_ok=True)
with torch.no_grad():
datasets_path = '/data2/cjd/StereoDatasets/eth3d/two_view_testing'
for dir_name in os.listdir(datasets_path):
dir_path = os.path.join(datasets_path, dir_name)
if not os.path.isdir(dir_path):
continue
output_file_path = os.path.join(output_directory, dir_name + '.pfm')
timing_file_path = os.path.join(output_directory, dir_name + '.txt')
if os.path.isfile(output_file_path) and os.path.isfile(timing_file_path):
print('Skipping since output already present: ' + dir_name)
continue
print('Processing: ' + dir_name)
# Assemble call.
left_image_path = os.path.join(dir_path, 'im0.png')
right_image_path = os.path.join(dir_path, 'im1.png')
image1 = load_image(left_image_path)
image2 = load_image(right_image_path)
padder = InputPadder(image1.shape, divis_by=32)
image1, image2 = padder.pad(image1, image2)
starter.record()
disp = model(image1, image2, iters=args.valid_iters, test_mode=True)
ender.record()
torch.cuda.synchronize()
curr_time = starter.elapsed_time(ender)
disp = disp.cpu().numpy()
disp = padder.unpad(disp).squeeze()
with open(output_file_path, 'wb') as f:
H, W = disp.shape
headers = ["Pf\n", f"{W} {H}\n", "-1\n"]
for header in headers:
f.write(str.encode(header))
array = np.flip(disp, axis=0).astype(np.float32)
f.write(array.tobytes())
with open(timing_file_path, 'wb') as f:
time ='runtime %.2f' % (curr_time / 1000)
f.write(str.encode(time))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--restore_ckpt', help="restore checkpoint", default="/data2/cjd/mono_fusion/checkpoints/eth3d.pth")
parser.add_argument('--save_numpy', action='store_true', help='save output as numpy arrays')
parser.add_argument('-l', '--left_imgs', help="path to all first (left) frames", default=None)
parser.add_argument('-r', '--right_imgs', help="path to all second (right) frames", default=None)
parser.add_argument('--output_directory', help="directory to save output", default='./test_output/eth3d/')
parser.add_argument('--mixed_precision', action='store_true', help='use mixed precision')
parser.add_argument('--valid_iters', type=int, default=32, help='number of flow-field updates during forward pass')
# Architecture choices
parser.add_argument('--encoder', type=str, default='vitl', choices=['vits', 'vitb', 'vitl', 'vitg'])
parser.add_argument('--hidden_dims', nargs='+', type=int, default=[128]*3, help="hidden state and context dimensions")
parser.add_argument('--corr_implementation', choices=["reg", "alt", "reg_cuda", "alt_cuda"], default="reg", help="correlation volume implementation")
parser.add_argument('--shared_backbone', action='store_true', help="use a single backbone for the context and feature encoders")
parser.add_argument('--corr_levels', type=int, default=2, help="number of levels in the correlation pyramid")
parser.add_argument('--corr_radius', type=int, default=4, help="width of the correlation pyramid")
parser.add_argument('--n_downsample', type=int, default=2, help="resolution of the disparity field (1/2^K)")
parser.add_argument('--slow_fast_gru', action='store_true', help="iterate the low-res GRUs more frequently")
parser.add_argument('--n_gru_layers', type=int, default=3, help="number of hidden GRU levels")
parser.add_argument('--max_disp', type=int, default=192, help="max disp of geometry encoding volume")
args = parser.parse_args()
demo(args)
这将输出pfm和txt文件作为在线评估的源文件。接着到官网进行评估。点击submission。
接下来就是按照步骤就行,我主要说一下上传的文件格式问题。
这个上传的文件结构有所不同,不像Middlebury那样,创建一个zip压缩包,里面把training和test分开,再分别把自己的推理结果分别放到这两个文件夹下的每个测试案例中;ETH3D不区分train和test,它是创建一个文件夹,把所有的94个文件(47个pfm和47个txt)放到一个文件夹下进行压缩上传,具体的文件结果如下图。详细的说就是low_res_two_view_all.zip文件下是一个low_res_two_view_all文件夹,在这个文件夹下面才是pfm和txt,而不是zip下直接就是pfm和txt。这点需要格外注意,否则会评估失败。
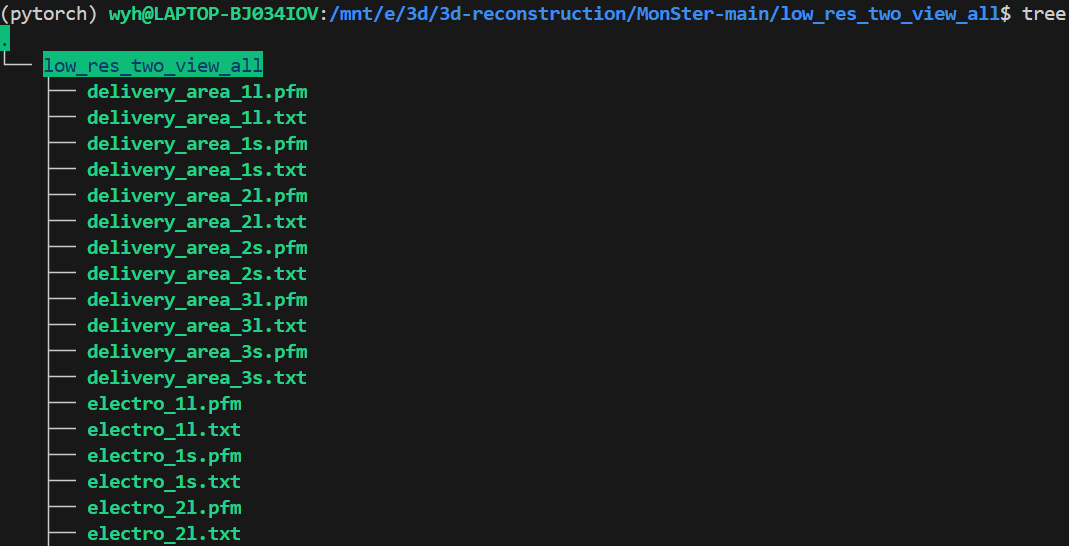
按照这个格式上传就可以进行评估了,接下来就会得到自己模型的结果及排名情况。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)