高并发场景下的Spring Boot悲观锁应用:解决超卖与数据一致性问题
• 如果 500 个用户在 2 秒内同时请求更新同一份库存数据,几乎所有并发的更新尝试都会因为版本冲突而抛出。,从而阻止其他事务(线程)对这些行进行修改(某些情况下甚至阻止读取),直到当前事务完成。查询得以继续执行,并读取到已被线程1更新后的数据(例如,库存数量为9)。上时,JVM 级别的锁就无法跨实例同步了,依然会产生并发问题。4. 线程1 继续执行,检查库存(假设当前库存为10)。通过这种方式
先说个真实世界的问题:超卖或超订难题
想象一下,你正在使用 Spring Boot 构建一个票务预订系统或电子商务系统。假设:
-
• 你的库存中有 100 张演唱会门票或 50 件某个热门商品。
-
• 你的应用程序已部署,并且有 1000 个用户正试图同时购买这些门票或商品(例如在618或者双十一秒杀活动等场景下)。
你可能写了一个类似这样的 REST 端点来进行购买操作:
@PostMapping("/purchase")
public void purchaseProduct(Long productId, int qty) {
// 1. 读取产品信息(假设这是数据库操作)
Product product = productRepository.findById(productId).orElseThrow(() -> new RuntimeException("产品不存在"));
// 2. 检查库存
if (product.getQuantity() >= qty) {
// 3. 如果库存充足,则扣减库存
product.setQuantity(product.getQuantity() - qty);
productRepository.save(product); // 4. 保存更新后的产品信息
System.out.println("用户 " + Thread.currentThread().getName() + " 购买成功 " + qty + " 件,剩余库存 " + product.getQuantity());
} else {
System.out.println("用户 " + Thread.currentThread().getName() + " 购买失败,库存不足,需要 " + qty + ",实际 " + product.getQuantity());
throw new RuntimeException("库存不足");
}
}现在问题来了:
⚠️ 尽管上面的逻辑看起来似乎没什么问题,但在高并发情况下,两个或更多用户可能会在几乎同一时刻读取到产品库存(比如都读到还有10件),都判断库存充足,然后所有这些用户的请求都执行了扣减库存的操作(比如每个用户都尝试购买8件)。即使你在扣减前检查了可用库存,这依然会导致超订或超卖(比如卖出去了16件,但其实只有10件)。
发生这种情况是因为并发的读取和写入之间没有有效的同步机制 —— 从而导致了竞争条件 (race condition)。
为什么乐观锁 (Optimistic Locking) 可能不够用?
你可能会尝试使用带有 @Version 注解的乐观锁机制,它在大多数并发不那么激烈的场景下表现良好。但是:
-
• 在高并发系统中,乐观锁会导致频繁的更新失败和重试。
-
• 如果 500 个用户在 2 秒内同时请求更新同一份库存数据,几乎所有并发的更新尝试都会因为版本冲突而抛出
OptimisticLockException,迫使系统频繁重试这些操作,或者直接让大量用户操作失败。
解决方案:悲观锁 (PESSIMISTIC LOCKING)
这是什么?
悲观锁是一种并发控制策略,它假设在并发系统中冲突的发生是大概率事件。因此,当一个事务(线程)读取数据并准备更新时,它会立即在数据库层面锁定相关的行,从而阻止其他事务(线程)对这些行进行修改(某些情况下甚至阻止读取),直到当前事务完成。
你可以把它想象成你进入一个洗手间并锁上了门:在你出来之前,其他任何人都别想使用这个隔间。
它在什么情况下有用?
-
• 在那些数据一致性至关重要的系统中(例如,涉及资金、票务、库存管理等)。
-
• 在高并发场景下,当乐观锁导致重试频繁失败时。
-
• 当你完全无法承受竞争条件(哪怕是偶尔发生一次)所带来的后果时。
“为什么不用 Java 的 synchronized 或 ReentrantLock 呢?”
(尽早解答这个初学者常问的问题)
❓ 为什么不直接使用 Java 语言层面提供的 synchronized 关键字或 ReentrantLock 这些锁机制呢?
因为那些 Java 锁只在单个 JVM 内部有效。当你的应用程序为了扩展性而部署到多个实例或容器上时,JVM 级别的锁就无法跨实例同步了,依然会产生并发问题。你需要的是数据库级别的锁定机制,而悲观锁提供的正是这种能力。
(这澄清了初级开发者常见的一个困惑。)
Spring Boot 悲观锁 —— 一步步实现
让我们来构建它:
1. 实体类 (Entity Class)
首先,我们有一个简单的 Product 实体:
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
// Getters, Setters, Constructors 可以用 Lombok 简化
@Entity
public class Product {
@Id
private Long id;
private String name;
private int quantity; // 库存数量
// 构造函数、getter 和 setter 此处省略
// 请确保有无参构造函数供 JPA 使用,以及必要的 getter/setter
public Product() {}
public Product(Long id, String name, int quantity) {
this.id = id;
this.name = name;
this.quantity = quantity;
}
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getQuantity() { return quantity; }
public void setQuantity(int quantity) { this.quantity = quantity; }
}2. 使用锁注解的 Repository 接口
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Lock;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.jpa.repository.QueryHints;
import org.springframework.data.repository.query.Param;
import jakarta.persistence.LockModeType;
import jakarta.persistence.QueryHint; // 注意是 jakarta.persistence
public interface ProductRepository extends JpaRepository<Product, Long> {
// 使用 @Lock 注解来指定悲观写锁
@Lock(LockModeType.PESSIMISTIC_WRITE)
// 也可以直接在 @Query 中使用 "FOR UPDATE" (取决于数据库方言)
// 但 @Lock 更符合 JPA 规范
@Query("SELECT p FROM Product p WHERE p.id = :id")
Product findByIdWithLock(@Param("id") Long id);
// 如果需要为锁操作设置超时:
@Lock(LockModeType.PESSIMISTIC_WRITE)
@QueryHints({
// 设置JPA锁超时属性 (单位是毫秒)
// "jakarta.persistence.lock.timeout" 是标准属性名 (JPA 2.1+)
// "javax.persistence.lock.timeout" 是旧版JPA的属性名
@QueryHint(name = "jakarta.persistence.lock.timeout", value = "3000") // 3 秒超时
})
@Query("SELECT p FROM Product p WHERE p.id = :id")
Product findByIdWithLockAndTimeout(@Param("id") Long id);
}@Lock(LockModeType.PESSIMISTIC_WRITE) 是这里的核心。
这会让 JPA (Hibernate 作为实现) 在执行查询时,生成类似下面这样的 SQL(具体语法可能因数据库方言而略有不同):
SELECT * FROM product WHERE id = ? FOR UPDATE;FOR UPDATE 子句会在数据库层面锁定被查询到的行,直到当前事务提交 (commit) 或回滚 (rollback)。
其他试图更新或以写锁方式读取这些被锁定行的事务(线程)将会被阻塞 (blocked),即它们必须等待锁被释放后才能继续执行。
悲观锁可能会导致死锁 (deadlocks) 或长时间的等待。因此,为锁操作设置一个合理的超时时间非常重要。上面的第二个方法演示了如何使用 @QueryHints 在 JPA 中为悲观锁设置超时:
💡 这能确保如果锁在3秒内没有被成功获取,就会抛出一个异常(通常是 PessimisticLockException 或 LockTimeoutException)。这有助于避免线程被无限期挂起,从而提高系统的弹性和健壮性。
3. 优雅地处理锁超时异常
你需要捕获并优雅地处理可能因锁超时而抛出的 PessimisticLockException (或其父类 LockTimeoutException)。
示例如下 (通常在调用 Service 的地方,如 Controller 层):
// 在 Controller 或调用端
// try {
// productService.purchaseProduct(productId, qty);
// // return ResponseEntity.ok("购买成功");
// } catch (PessimisticLockException | LockTimeoutException ex) { // 捕获悲观锁或锁超时异常
// // log.warn("获取产品锁超时或发生悲观锁冲突: {}", ex.getMessage());
// // 优雅地处理,比如提示用户稍后再试,或内部进行有限次数的重试
// throw new ResponseStatusException(HttpStatus.SERVICE_UNAVAILABLE, "系统繁忙,请稍后再试"); // 返回 503
// } catch (RuntimeException ex) { // 处理其他业务异常,如库存不足
// // log.error("购买失败: {}", ex.getMessage());
// throw new ResponseStatusException(HttpStatus.BAD_REQUEST, ex.getMessage());
// }解释:
⚠ 特别是在高流量的场景下,务必优雅地处理 PessimisticLockException 或 LockTimeoutException。避免将底层异常直接暴露给用户。
4. 服务层逻辑 (Service Layer Logic)
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional; // 引入事务注解
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
// 整个方法标记为事务性的
@Transactional
public void purchaseProduct(Long productId, int qtyToPurchase) {
// 1. 使用带锁的方法查询产品,此时数据库会对该行加锁
Product product = productRepository.findByIdWithLockAndTimeout(productId);
// 如果锁超时,这里会抛出 LockTimeoutException (或PessimisticLockException)
if (product == null) { // 虽然 findByIdWithLock 通常配置为找不到则抛异常或返回null
throw new RuntimeException("产品 " + productId + " 不存在");
}
// 2. 检查库存
if (product.getQuantity() >= qtyToPurchase) {
// 3. 扣减库存
product.setQuantity(product.getQuantity() - qtyToPurchase);
// 4. 保存产品
// 在 @Transactional 方法中,JPA 实体状态的变更会在事务提交时自动同步到数据库,
// 所以显式的 productRepository.save(product) 调用有时可以省略(取决于JPA配置和具体操作)。
// 但为了明确起见,或者如果 product 是 new 出来的,通常还是会调用 save。
// 此处假设 product 是从数据库加载的受管实体,修改后会自动更新。
// productRepository.save(product); // 如果需要显式保存或触发乐观锁版本更新,则调用
System.out.println(Thread.currentThread().getName() + ": 购买 " + qtyToPurchase + " 件成功,产品 " + productId + " 剩余库存 " + product.getQuantity());
} else {
System.out.println(Thread.currentThread().getName() + ": 购买 " + qtyToPurchase + " 件失败,产品 " + productId + " 库存不足,仅剩 " + product.getQuantity());
throw new RuntimeException("产品 " + productId + " 库存不足");
}
// 5. 当此 @Transactional 方法结束(无异常抛出)时,事务会提交,数据库锁会自动释放。
// 如果中途抛出未捕获的 RuntimeException (或其他配置为回滚的异常),事务会回滚,锁也会释放。
}
}将 purchaseProduct 方法标记为 @Transactional 能确保整个操作(查询、检查、更新)都发生在一个原子性的工作单元内。
数据库会持有这个行锁,直到包含 findByIdWithLockAndTimeout 调用的那个事务结束(即事务被提交或回滚)时,锁才会被释放。
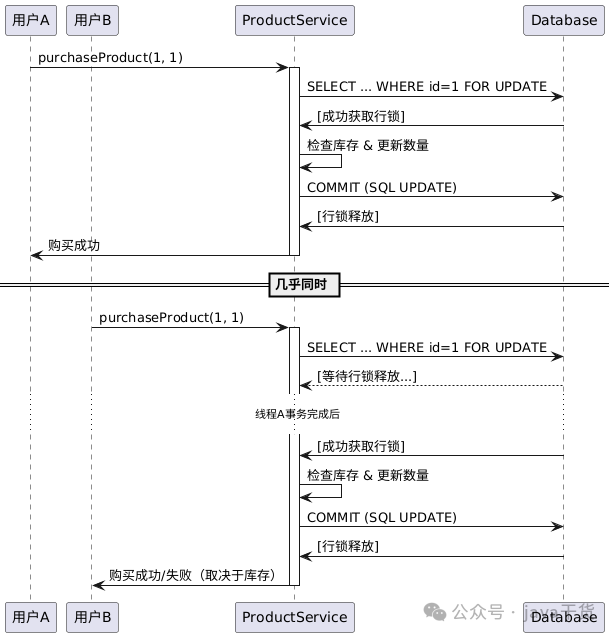
幕后原理 —— 分步执行流程 (UNDER THE HOOD — STEP BY STEP EXECUTION)
当多个线程并发调用 purchaseProduct 方法时,后台大致会发生以下情况:
-
1. 线程1 调用
purchaseProduct(1L, 1)(假设产品ID为1,购买数量为1)。 - 2.
productRepository.findByIdWithLockAndTimeout(1L)执行,向数据库发送类似:SELECT * FROM product WHERE id = 1 FOR UPDATE; -- (并可能带有锁超时参数) -
3. 数据库为
product表中id = 1的行加上排他锁。线程1 成功获取到锁。 -
4. 线程1 继续执行,检查库存(假设当前库存为10)。库存充足。
-
5. 线程1 执行
product.setQuantity(9),将产品数量更新为9。 -
6. 与此同时,线程2 尝试调用
purchaseProduct(1L, 1)。 - 7.
productRepository.findByIdWithLockAndTimeout(1L)在线程2中执行,也尝试向数据库发送:SELECT * FROM product WHERE id = 1 FOR UPDATE; -
8. 但是,由于
id = 1的行已经被线程1锁定,所以线程2 的这个查询会被阻塞——它必须等待线程1释放锁。 -
9. 线程1 的
@Transactional方法执行完毕,事务提交。数据库释放了id = 1行上的锁。 -
10. 线程2 现在获取到了锁,它的
SELECT ... FOR UPDATE查询得以继续执行,并读取到已被线程1更新后的数据(例如,库存数量为9)。 -
11. 线程2 基于更新后的库存(9件)安全地继续执行其购买逻辑。
通过这种方式,对共享资源(产品库存)的临界区代码的访问被串行化 (serializes) 了,从而解决了高并发场景下的数据不一致问题(如超卖)。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)