耗时两天半,利用 DrissionPage绕过瑞数6,爬取某药*局数据经历~
本文记录了作者破解某药*局网站数据爬取的过程。起初遭遇瑞数6加密防护,接口地址和参数都经过复杂加密(如base64),通过分析ajax.js找到app_secret和签名算法后,仍被NfBCSins2OywT动态值拦截。在几乎放弃时,受某视频启发采用drissionPage获取cookie,结合Python代码成功突破防护。最终实现每分钟175-180条的数据抓取,并发现模糊搜索存在1万条数据上限
周四临时接了个活,想爬取某药*局注册证号信息,一看接口请求地址都傻眼了,这样哪行啊。第一关就把我拦住了,这明显也加密了,像是base。
/search?7QBHXKaZ=0Aeb1AqlqEog0RJ4ZzF5ssffO94UbTLmKwwICBSwQd.DYihqjJGiTGtr84RiDSRG3FxrcioqneZqcN4INFo44qUcDM8GVeALP1fGgyKo0t_0Fn1ff9mHUaLKSe6SQP2tdpiZZQ.P7XhVl2yJXX5_MHQ0OaM0pFYrXKuRl89It9yGUWc9T2kdcMzGiBtggej0BMz_soGSun6cDusB_KGObRVh7gcn_1fvZTmEBAj84SqhrqXG12Re.vm0lVqvYjL537p5WZWfvPMpV
到了晚上也不知怎的,一下子就看到了真实的地址,这才是我们熟悉的地址嘛!!
/search?itemId=ff80808183cad7500183cb66fe690285&isSenior=N&searchValue=%E6%B3%A8&pageNum=1&pageSize=10×tamp=1749728520000
不过还是没用,还要破解sign的算法,只能去啃ajax.js,先找到了app_secret,再去尝试签名算法。到了周五下午,总算突破了sign签名,但很快又发现了新问题,那就是NfBCSins2OywT的值,一直不知道如何获得,而且这个值刷新频率很高,不像NfBCSins2OywS和acw_tc,导致一直是返回412。也是到这时候才知道网站是瑞数6,以前都没听说过这玩意!
网上也看了不少瑞数6方面的帖子,感觉都讲的很复杂,又是补环境,又是各种打断点调试js,因为不是专业玩爬虫的,理解起来有点费劲,一度都想放弃了。。。
直到周五晚上临睡前,突然刷到了个讲用 drissionPage获取网站cookie方法的视频(感谢某音的Python大数据老王),豁然开朗,周六一大早就赶紧试了一下,果然可以拿到。
于是配合上前面破解签名的Python代码,把该建的表都建上,最终在 Cursor 老师的指导下,历时两天半,顺利拿到了数据,剩下的就是漫漫的抓取入库过程了。目前的抓取速度控制在每分钟175-180条,没敢搞太快~~~
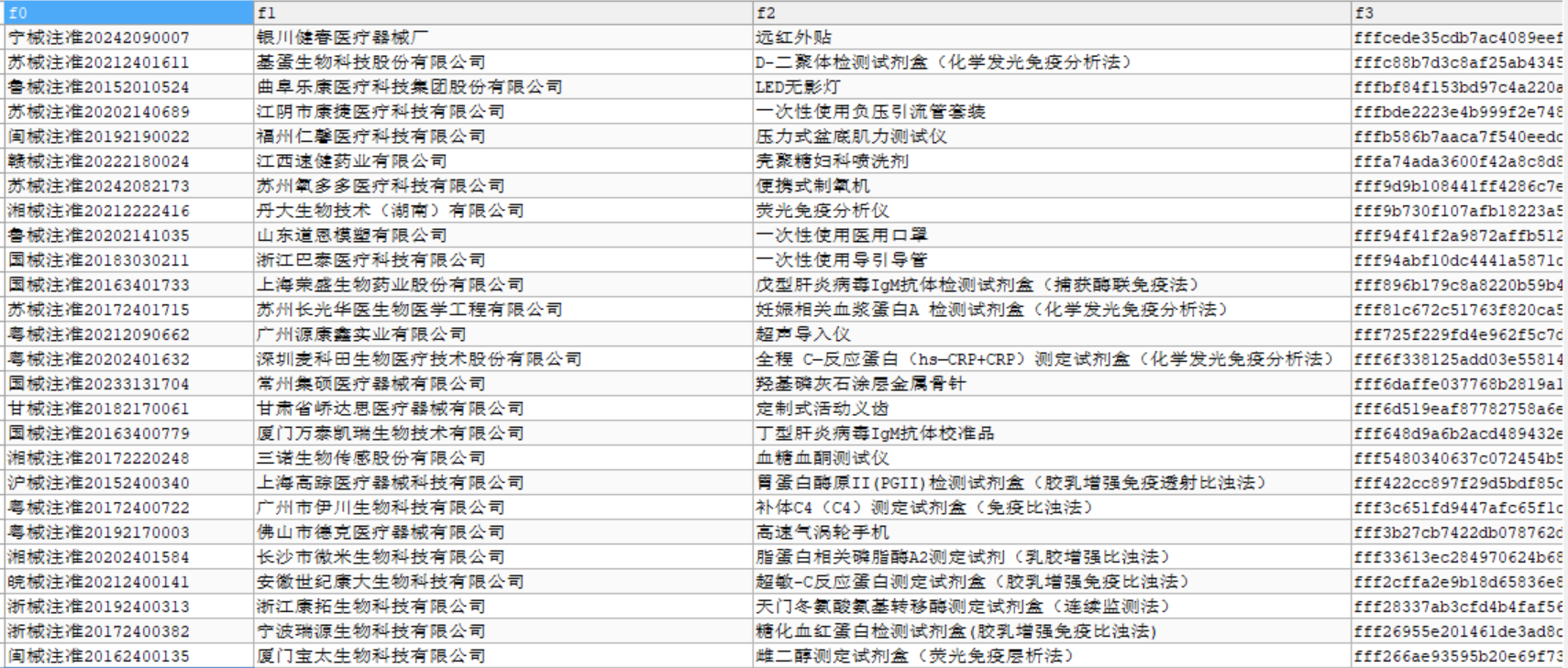 P.S.有个小坑,也是后面才发现,模糊搜索,最多可以查1万条数据,多了就不允许了。所以需要自己根据情况去拆关键词~
P.S.有个小坑,也是后面才发现,模糊搜索,最多可以查1万条数据,多了就不允许了。所以需要自己根据情况去拆关键词~
另外还有一点就是,我是全程开着Charles,感觉关了它就可能412,我也不确定是不是错觉,反正能用,我就一直开着。。。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)