数据包分析工具 | Tshark
Tshark 是 Wireshark 的命令行版本,专为在无图形界面环境中分析网络流量而设计。与Wireshark相比,Tshark更适合需要高效操作、脚本化处理以及服务器端使用的场景。尽管缺少GUI,Tshark仍然继承了Wireshark强大的协议解析能力,支持上百种网络协议的流量捕获和分析。
·
一、Tshark简介
Tshark 是 Wireshark 的命令行版本,专为在无图形界面环境中分析网络流量而设计。与Wireshark相比,Tshark更适合需要高效操作、脚本化处理以及服务器端使用的场景。尽管缺少GUI,Tshark仍然继承了Wireshark强大的协议解析能力,支持上百种网络协议的流量捕获和分析。
- 轻量高效:占用资源低,适合在资源有限的环境中运行。
- 支持多平台:兼容Windows、Linux和macOS。
- 灵活强大:支持抓包过滤、显示过滤、数据导出、统计分析等多种功能。
- 自动化能力:方便与脚本结合,实现自动化分析与任务调度。
官方说明文档:https://www.wireshark.org/docs/man-pages/tshark.html
二、安装 Tshark
2.1、Windows
- 下载安装包:访问Wireshark官网,找到适合你系统的安装包。
- 安装过程中勾选 Tshark 组件选项。
- 配置环境变量(可选): 为了在终端中直接使用 Tshark 命令,建议将 Wireshark 的安装目录添加到 PATH 环境变量中。
安装完成后,打开命令行窗口,输入以下命令,验证是否安装成功:
tshark -v
如果显示 Tshark 的版本信息,那就说明成功安装了!
2.2、Linux
1、基于 Debian
sudo apt-get install tshark
2、基于 Red Hat
# 1. 启用EPEL仓库
sudo yum install epel-release -y
# 2. 安装Wireshark(包含tshark)
sudo yum install wireshark -y
# 3. 验证安装
tshark -v # 输出类似 "TShark 1.10.14"
三、参数说明
3.1、抓包接口类
| 参数 | 说明 |
|---|---|
| -i | 设置抓包的网络接口,不设置则默认为第一个非自环接口。 |
| -D | 列出当前存在的网络接口。在不了解OS所控制的网络设备时,一般先用"tshark-D"查看网络接口的编号以供 -i 参数使用。 |
| -f | 设定抓包过滤表达式( capture filterexpression) 。抓包过滤表达式的写法雷同于tcpdump |
| -s | 设置每个抓包的大小,默认为65535,多于这个大小的数据将不会被程序记入内存、写入文件。 |
| -p | 设置网络接口以非混合模式工作,即只关心和本机有关的流量。 |
| -B | 设置内核缓冲区大小,仅对windows有效。 |
| -y | 设置抓包的数据链路层协议,不设置则默认为-L找到的第一个协议。 |
| -L | 列出本机支持的数据链路层协议,供 -y 参数使用。 |
3.2、抓包停止条件
| 参数 | 说明 |
|---|---|
| -C | 抓取的packet数,在处理一定数量的packet后,停止抓取,程序退出。 |
| -a | 设置tshark抓包停止向文件书写的条件,事实上是tshark在正常启动之后停止工作并返回的条件。条件写为test:value的形式,如:“-a duration:5"表示tshark启动后在5秒内抓包然后停止; ”-a filesize:10"表 示tshark在输出文件达到10kB后停止; "-a files:n"表示tshark在写满n个文件后停止。 |
3.3、文件输出控制
| 参数 | 说明 |
|---|---|
| -b | 设置ringbuffer文件参数。ringbuffer的文件名由 -w 参数决定。-b参数采用test:value的形式书写。“-b duration:5"表示每5秒写下一个ringbuffer文件; ”-b filesize:5"表示每达到5kB写下一个ringbuffer文件; "-b files:7"表示ringbuffer文件最多7个,周而复始地使用,如果这个参数不设定,tshark会 将磁盘写满为止。 |
3.4、文件输入
| 参数 | 说明 |
|---|---|
| -r | 设置tshark分析的输入文件。tshark既可以抓取分析即时的网络流量,又可以分析dump在文件中的数据。 |
3.5、处理类
| 参数 | 说明 |
|---|---|
| -R | 设置读取(显示)过滤表达式( read filterexpression) 。不符合此表达式的流量同样不会被写入文件。 |
| -n | 禁止所有地址名字解析(默认为允许所有) |
| -N | 启用某一层的地址名字解析。"m”代表MAC层,“n"代表网络层,"t"代表传输层,“C"代表当前异步DNS查找。如果-n和-N参数同时存在,-n将被忽略。如果-n和-N参数都不写,则默认打开所有地址名字解析。 |
| -d | 将指定的数据按有关协议解包输出。如要将tcp 8888端口的流量按http解包,应该写为"-d tcp.port == 8888,http"。 |
3.6、输出类
| 参数 | 说明 |
|---|---|
| -w | 设置raw数据的输出文件。这个参数不设置,tshark将会把解码结果输出到stdout。“-w"表示把raw输出到stdout。如果要把解码结果输出到文件,使用重定向”>"而不要-w参数。 |
| -F | 设置输出raw数据的格式,默认为libpcap。 "tshark -F"会列出所有支持的raw格式。 |
| -V | 设置将解码结果的细节输出,否则解码结果仅显示一个packet一行的summary。 |
| -X | 设置在解码输出结果中,每个packet后面以HEXdump的方式显示具体数据。 |
| -Y | 使用显示过滤器来筛选数据包。显示过滤器使用 Wireshark 语法。例:-Y "http.request" |
| -T | 设置解码结果输出的格式,包括text、ps、psml、json和pdml, 默认为text。 |
| -t | 设置解码结果的时间格式。"ad"表示带日期的绝对时间,"a"表示不带日期的绝对时间,"r”表示从第一个包到现在的相对时间,“d"表示两个相邻包之间的增量时间(delta ) |
| -S | 在向raw文件输出的同时,将解码结果打印到控制台。 |
| -e | 指定要在输出中显示的字段。 例:-e ip.src -e ip.dst -e tcp.port |
| -l | 在处理每个包时即时刷新输出。 |
| -X | 扩展项。 |
| -q | 设置安静的stdout输出只显示统计信息。 |
| -Z | 设置统计参数。例:-z io,stat,1 |
四、使用示例
4.1、查看接口信息
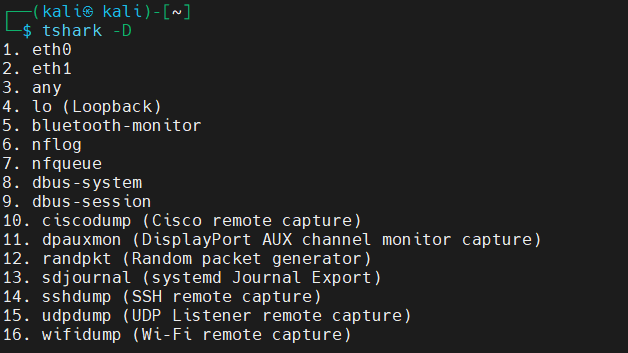
查询当前系统可以捕获的接口信息
tshark -D
4.2、抓取流量
# 抓包 同时支持多个网卡抓包
tshark -i eth0 -i eth1
#设置缓存大小,丢包场景可以设置下,单位为MB
tshark -i eth0 -B 2
#只抓前面512个字节,抓包小,大流量情况下有用
tshark -i eth0 -s 512
# 禁止域名解析 只想看ip
tshark -i eth0 -n
#设置包保存文件格式
tshark -i eth0 -F pcapng -w 1.pcapng
4.3、抓包过滤
语法采用bpf过滤语法,和tcpdump一样的过滤语法。
# 抓tcp端口为22 ,且含有fin标识的数据包
tshark -i eth0 -f "tcp port 22 and (tcp[tcpflags] & tcp-fin != 0)"
# 抓端口为8080或者54的数据包
tshark -i eth0 -f 'port 8080 or port 54'
4.4、自动停止抓包
#以数量作为停止条件
tshark -i eth0 -c 抓包数量
#以时间作为停止条件 60秒
tshark -i eth0 -a duration:60
#以文件大小作为停止条件 单位为KB
tshark -i eth0 -a filesize:10 -w 1.pcap
4.5、文件输出控制
#每5秒写下一个文件,写满2个文件后停止
tshark -i eth0 -b duration:5 -a files:2 -w test.pcap
#每达到5kB写下一个文件,写满2个文件后停止
tshark -i eth0 -b filesize:5 -a files:2 -w test.pcap
4.6、读取并分析数据包
# 读取pcap包
tshark -r test.pcap
# 显示标准点的时间格式
tshark -r test.pcap -t ad
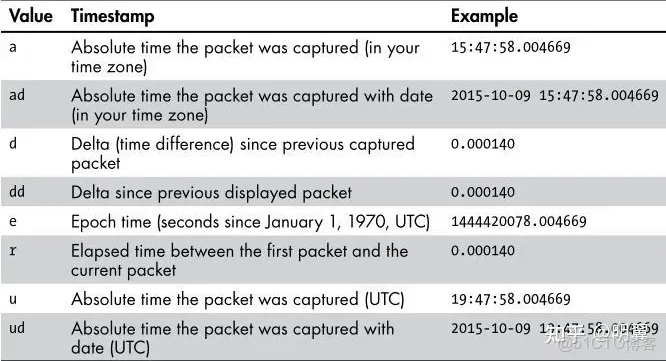
-t 参数设置解码结果的时间格式。
"ad"表示带日期的绝对时间;
"a"表示不带日期的绝对时间;
"r”表示从第一个包到现在的相对时间;
“d"表示两个相邻包之间的增量时间。
4.7、过滤和输出格式处理
# -e 指定要在输出中显示的字段
tshark -r test.pcap -T fields -e frame.number -e ip.src -e ip.dst -e tcp.srcport -e tcp.dstport
# 抓包或者读pcap文件都可以采用-Y语法进行过滤
# 过滤dns协议包含特定域名的
tshark -r test.pcap -Y "matches"in-addr""
# 特定网段
tshark -r test.pcap -Y 'ip.addr == 172.16.0.0/16'
# 端口范围过滤
tshark -r test.pcap -Y "tcp.port in {53 8080}"
# 过滤http协议,且返回状态为200的报文 只会匹配返回报文
tshark -r test.pcap -Y 'http and http.response.code == 200'
# 查看特定时间范围的包 并且写入到文件
tshark -r test.pcap -t ad -Y 'frame.time >= "2016-01-04 19:32:47" && frame.time < "2016-01-04 19:32:50" ' -w a.pcap
4.8、流分析
流分析相当于是在wireshark上直接用右键,选择“追踪流” 。
# 这里的7为tcp.stream的值
tshark -r test.pcap -q -z follow,tcp,ascii,7
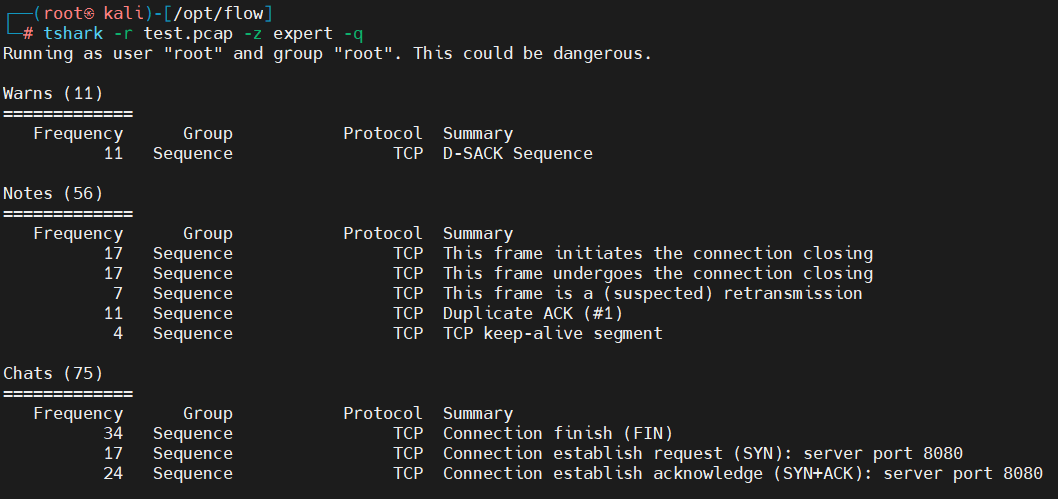
4.9、专家信息统计
tshark -r test.pcap -z expert -q
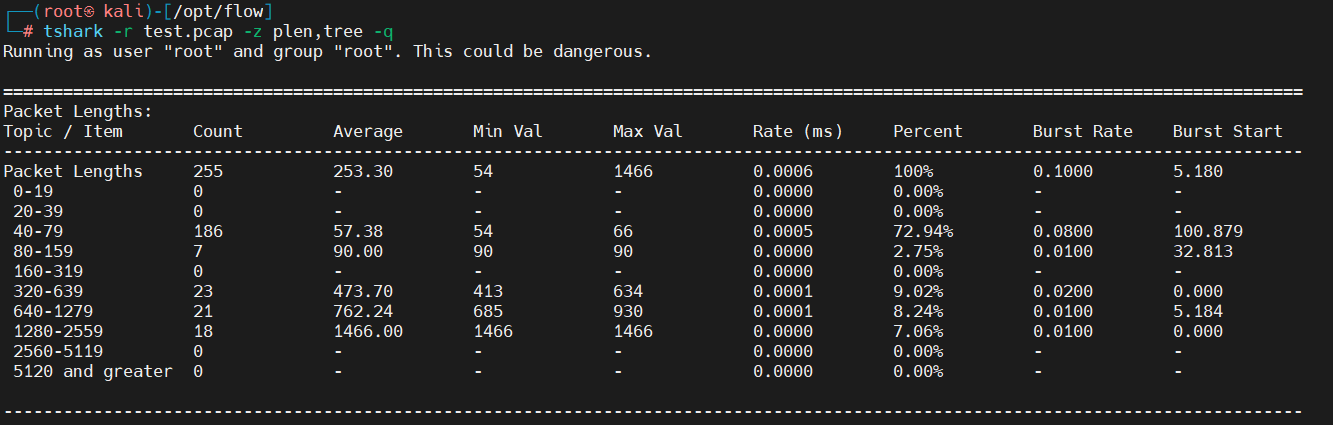
4.10、包长度统计
tshark -r test.pcap -z plen,tree -q
4.11、会话统计
tshark -r test.pcap -z conv,ip -q

4.12、统计所有IP信息
tshark -r test.pcap -z endpoints,ip -q
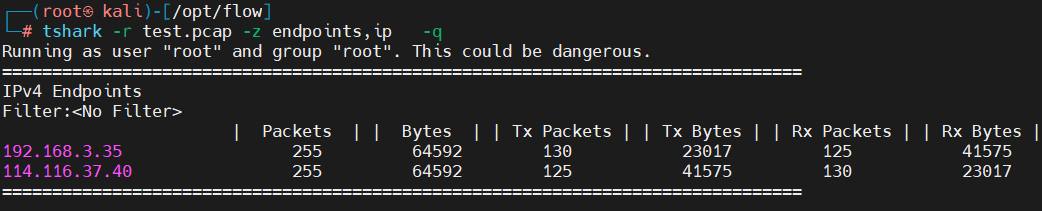
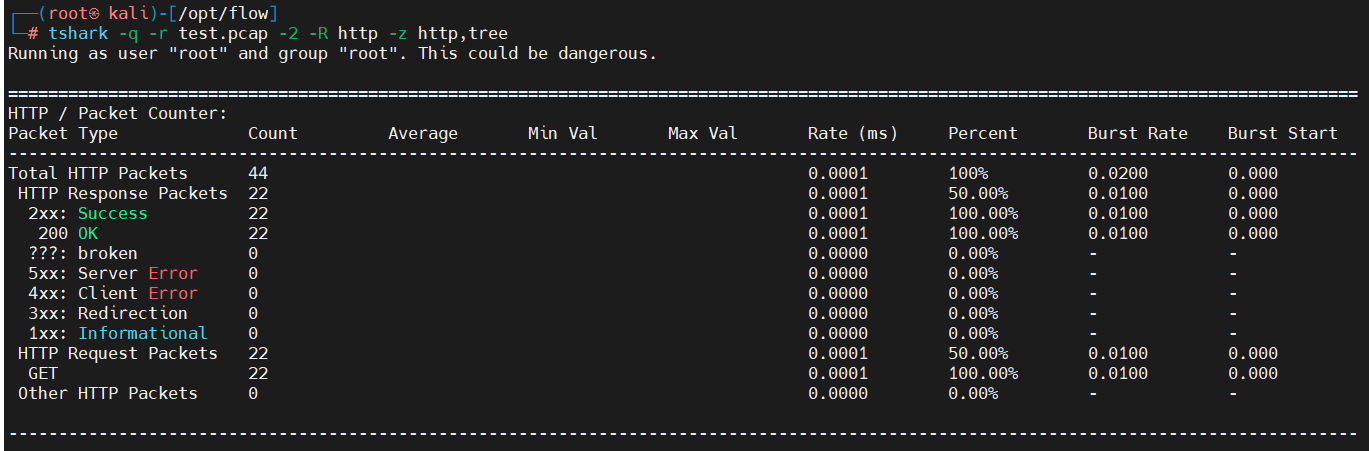
4.13、HTTP包情况统计
tshark -q -r test.pcap -2 -R http -z http,tree
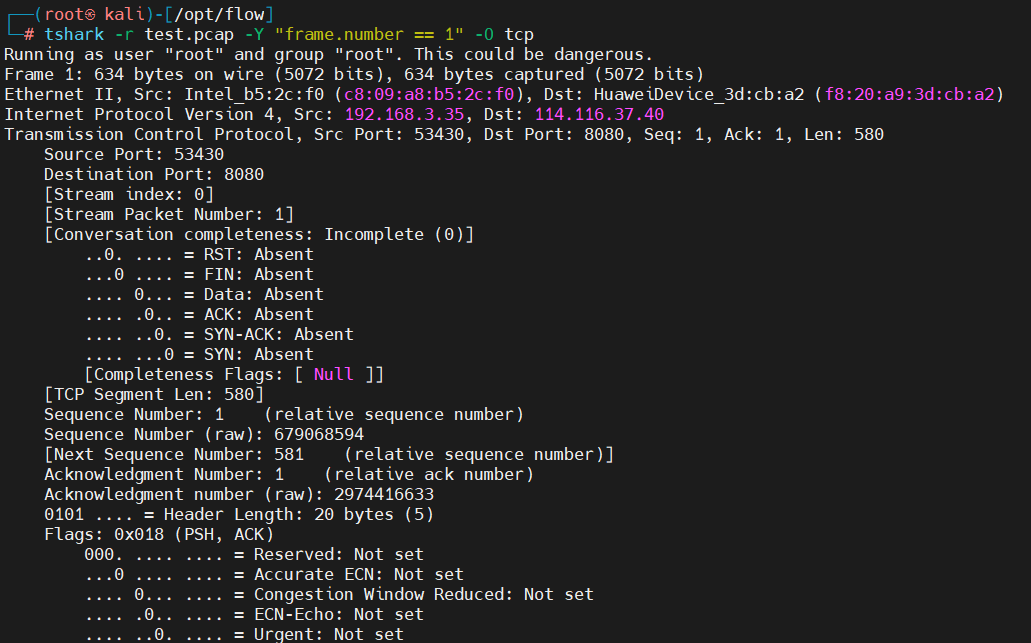
4.15、pcap分层解析
# 查看tcp层
tshark -r test.pcap -Y "frame.number == 1" -O tcp
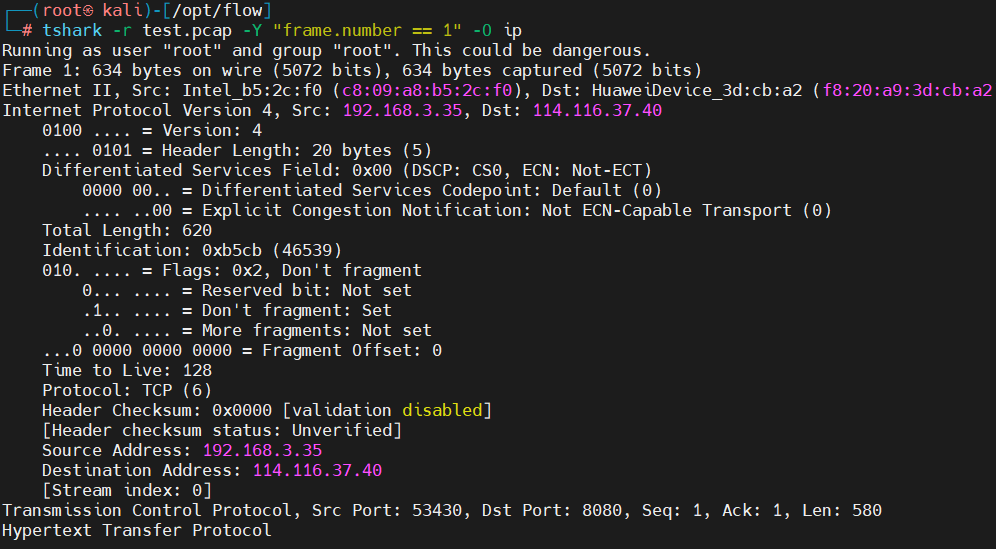
# 查看ip层
tshark -r test.pcap -Y "frame.number == 1" -O ip
# 所有层都展开
tshark -r test.pcap -Y "frame.number == 1" -V
5、PCAP转换为文本
5.1、输出完整协议详情(适合深度分析)
tshark -r input.pcap -V > output.txt
- 功能:生成包含数据包各层协议解析的详细文本(如 Ethernet、IP、TCP 头部及负载)。
- 适用场景:需要完整协议树分析(如调试协议交互问题)。
- 注意:输出内容较长,建议配合
grep过滤关键字段(如tshark -r input.pcap -V | grep "HTTP")
5.2、十六进制转储格式(适合二进制分析)
tshark -r input.pcap -x > hex_output.txt
- 功能:输出十六进制字节 + ASCII 解码格式,保留原始数据包字节级信息。
- 适用场景:修改数据包内容后需重新导入(如 Wireshark 的 File > Import from Hex Dump)
5.3、表格字段提取(适合结构化处理)
tshark -r input.pcap -T fields -e frame.time -e ip.src -e ip.dst -e http.request.uri -E separator=, -E header=y > output.csv
- 功能:提取指定字段生成 CSV/TSV 文件,适合导入 Excel 或数据库。
- 关键参数:
-T fields:指定字段输出模式。-e:选择字段(如tcp.port、http.host)。-E separator=:设置分隔符(如,或\t)。-E header=y:包含字段名标题行。
5.4、 简洁摘要格式(类似 Wireshark 主界面)
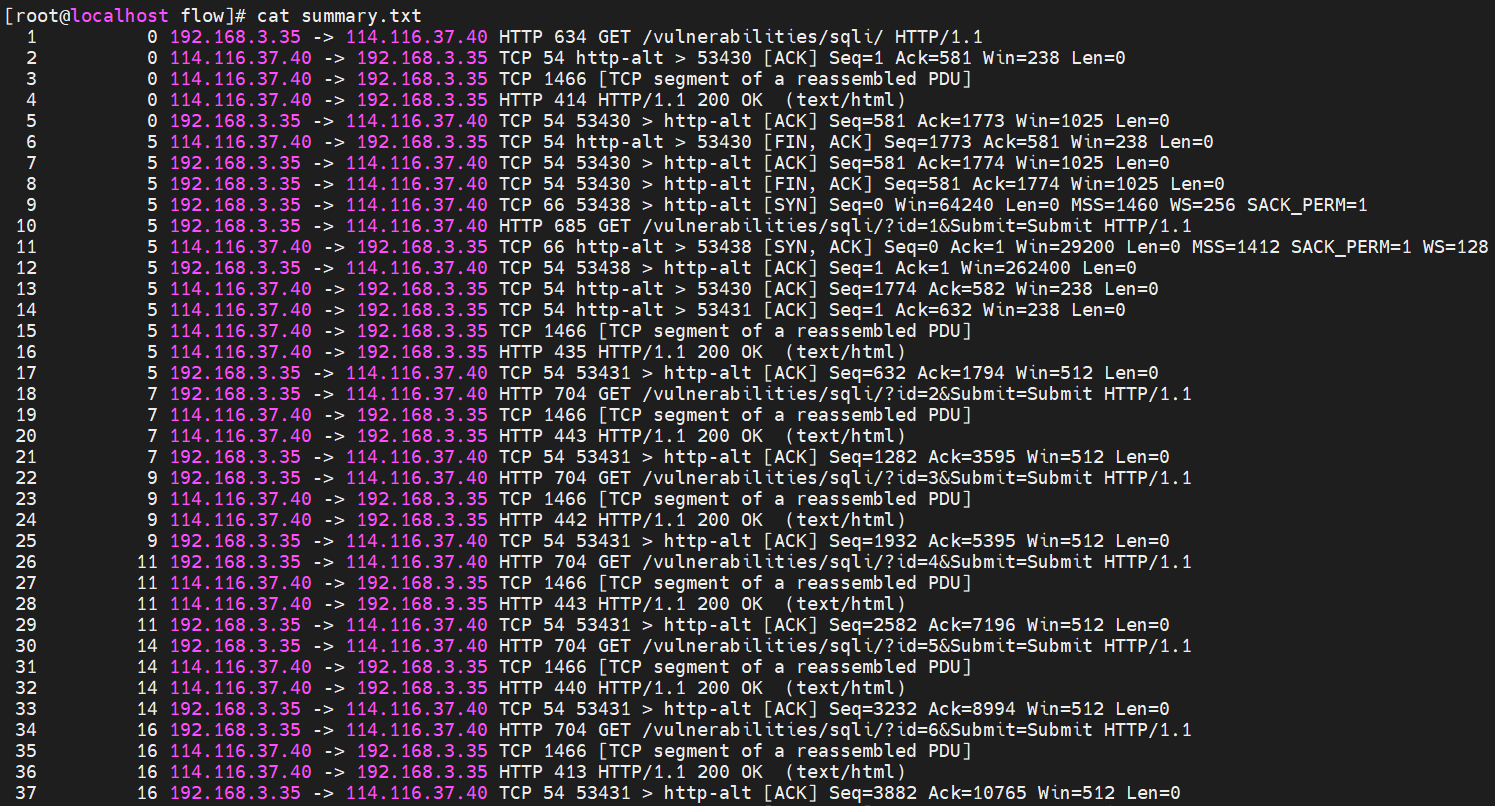
tshark -r input.pcap > summary.txt
- 功能:输出类似 Wireshark 主界面的摘要信息(时间、源/目标地址、协议、长度)
- 适用场景:快速浏览数据包概况。
5.5、JSON 格式(适合编程处理)
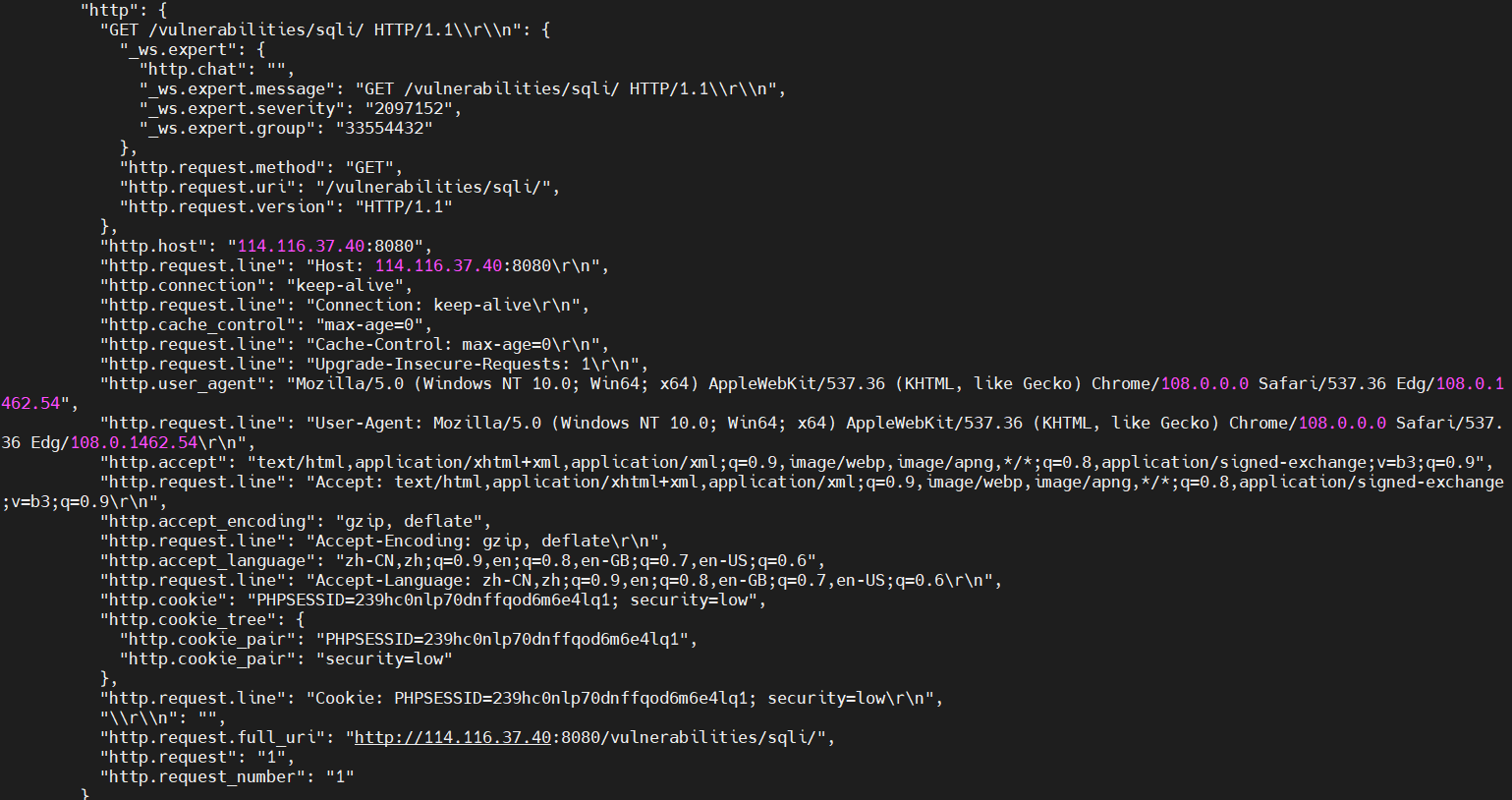
tshark -r input.pcap -T json > output.json
- 功能:生成结构化 JSON 数据,包含每个包的协议字段及原始十六进制数据。
- 优势:支持程序化解析(如 Python 脚本处理)。
- 定制字段:指定输出特定字段(减少文件体积)
tshark -r input.pcap -T json -e ip.src -e http.request.method
6、结合脚本调用
**情景:**需要将PCAP包中的所有的HTTP流合并,并导出为文本格式。
思路:
- 先获取pcap文件中所有HTTP流对应的TCP流ID。使用
tshark -r input.pcap -Y http -T fields -e tcp.stream命令实现。 - 然后循环处理每个流ID,使用
tshark -z follow,http,ascii,<stream_id>导出流内容。 - 将所有流内容追加到同一个输出文件中,流之间用分隔符区分。
脚本如下:
#!/bin/bash
# 功能:提取PCAP文件中的所有HTTP流,输出文件与输入文件同名并添加后缀
# 示例:./extract_http_streams.sh input.pcap [-f ascii|hex|raw] [-i] [-b]
INPUT_PCAP="$1"
# 从输入文件名生成输出文件名(保留路径,添加后缀)
OUTPUT_TXT="${INPUT_PCAP%.*}.txt" # 移除扩展名后添加后缀
FORMAT="ascii" # 默认文本格式
INCLUDE_META=1 # 默认包含元数据
SKIP_BINARY=1 # 默认跳过二进制内容
# 解析选项
while getopts "f:ib" opt; do
case $opt in
f) FORMAT="$OPTARG" ;;
i) INCLUDE_META=0 ;;
b) SKIP_BINARY=0 ;;
*) echo "用法: $0 <input.pcap> [-f ascii|hex|raw] [-i] [-b]"
exit 1 ;;
esac
done
# 检查输入文件是否存在
if [ ! -f "$INPUT_PCAP" ]; then
echo "错误: 输入文件 $INPUT_PCAP 不存在" >&2
exit 1
fi
# 获取所有HTTP流ID
STREAM_IDS=$(tshark -r "$INPUT_PCAP" -Y "http" -T fields -e tcp.stream 2>/dev/null | sort -un)
if [ -z "$STREAM_IDS" ]; then
echo "未找到HTTP流量" >&2
exit 0
fi
# 清空输出文件
> "$OUTPUT_TXT"
# 遍历每个流并导出
for ID in $STREAM_IDS; do
{
# 添加分隔符和流信息
if [ "$INCLUDE_META" -eq 1 ]; then
echo "=================================================================="
echo "HTTP Stream ID: $ID"
echo "=================================================================="
fi
# 导出流内容(根据格式选择)
case $FORMAT in
ascii)
tshark -r "$INPUT_PCAP" -qz "follow,http,ascii,$ID" 2>/dev/null |
awk '!/^===|^$/{print}' # 过滤无关行
;;
hex)
tshark -r "$INPUT_PCAP" -qz "follow,http,hex,$ID" 2>/dev/null |
grep -v '^==='
;;
raw)
tshark -r "$INPUT_PCAP" -qz "follow,http,raw,$ID" 2>/dev/null |
xxd -p
;;
esac
# 跳过二进制内容检测
if [ "$SKIP_BINARY" -eq 1 ]; then
echo "[跳过二进制内容]"
fi
echo -e "\n\n"
} >> "$OUTPUT_TXT"
done
echo "完成! HTTP流已保存至: $OUTPUT_TXT"
提取效果: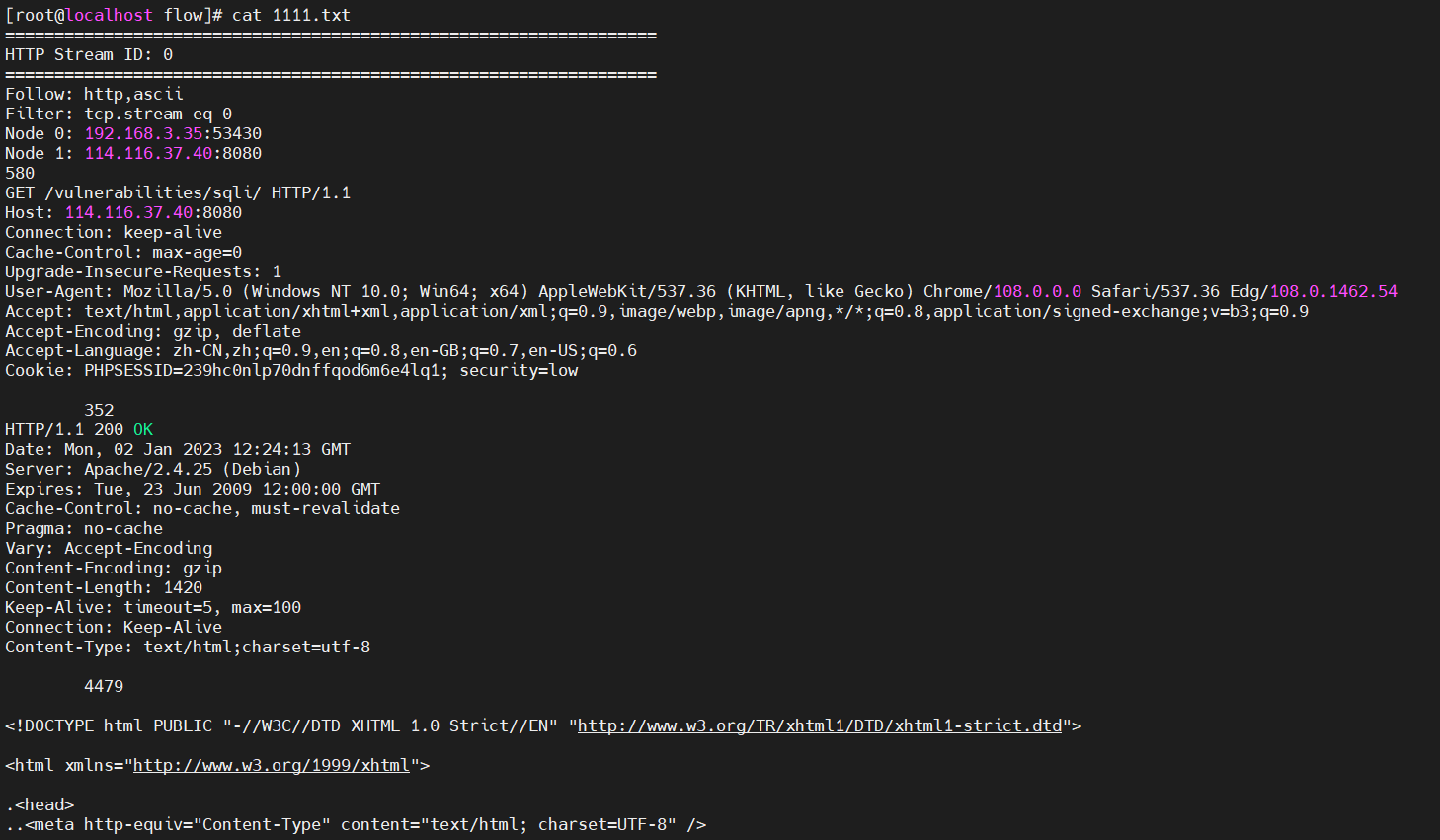

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)