Pandas数据分析(小白五分钟从入门到精通)
Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过标签来快速访问和操作数据。Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。用得最多的pandas对象是Series,一个一维的标签化数组对象,另一个是DataFrame,它是一个面向列的二维表结构。在数据结构中,每
Pandas 简介
3.1.1 Pandas 是什么?
Pandas 是 Python 数据分析工具链中最核心的库,充当数据读取、清洗、分析、统计、输出的高效工具。
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas是基于NumPy构建的专门为处理表格和混杂数据设计的Python库,其核心设计理念包括:
- 标签化数据结构:提供带标签的轴(行索引和列名)
- 灵活处理缺失数据:内置NaN处理机制
- 智能数据对齐:自动按标签对齐数据
- 强大IO工具:支持从CSV、Excel、SQL等20+数据源读写
- 时间序列处理:原生支持日期时间处理和频率转换
名称由来
pandas这个名字源于panel data(面板数据,这是多维结构化数据集在计量经济学中的术语)以及Python data analysis(Python数据分析)。
pandas兼具numpy高性能的数组计算功能以及电子表格和关系型数据库(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,能更加便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
pandas功能:
- 有标签轴的数据结构
在数据结构中,每个轴都被赋予了特定的标签,这些标签用于标识和引用轴上的数据元素,使得数据的组织、访问和操作更加直观和方便
应用场景
|
工具 |
功能特色 |
适用场景 |
|
Excel |
图形界面,简单上手 |
人工分析、小规模数据 |
|
SQL |
高效读写,最终数据源 |
数据库查询和联表 |
|
Python + Pandas |
算法和分析部署核心 |
数据清洗,统计分析,可视化等 |
- 与Excel对比:
- 优势:
- 处理百万级数据不卡顿(Excel约100万行限制)
- 可复用的分析流程(脚本 vs 手工操作)
- 支持复杂数据转换(如:分组聚合、时间重采样)
- 局限:
- 可视化交互性较弱
- 学习曲线较陡峭
- 与数据库对比:
- 优势:
- 无需SQL知识即可分析
- 适合探索性分析(即时反馈)
- 丰富的数据清洗函数
- 局限:
- 数据量受内存限制
- 不适合高并发访问
- 与纯Python代码对比:
- 优势:
- 向量化运算比for循环快10-100倍
- 内置统计分析方法(如:相关系数计算)
- 丰富的数据透视功能
- 局限:
- 需要额外学习Pandas API
行业洞见:根据2023年Kaggle调查,Pandas是数据科学家使用率最高的工具(占比93%),远超第二名Excel(占比32%)
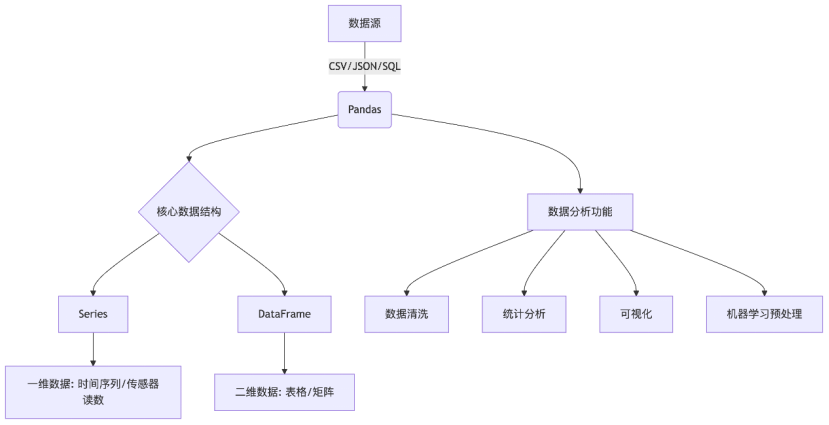
3.1.2 了解 Pandas 核心数据结构:Series 和 DataFrame
Pandas 基于 Numpy,并提供了 2 大核心数据结构:
- Series:一维带有标签的数组
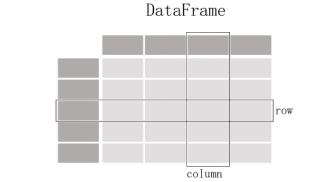
- DataFrame:二维表格结构,可看作多个 Series 的组合
用得最多的pandas对象是Series,一个一维的标签化数组对象,另一个是DataFrame,它是一个面向列的二维表结构。
|
特性 |
Series |
DataFrame |
|
维度 |
一维 |
二维 |
|
索引 |
单索引 |
行索引+列名 |
|
数据存储 |
同质化数据类型 |
各列可不同数据类型 |
|
类比 |
Excel单列 |
整张Excel工作表 |
|
创建方式 |
pd.Series([1,2,3]) |
pd.DataFrame({'col':[1,2,3]}) |
 |
 |
Pandas 与 Numpy 的关系与区别
就像学习数学要先掌握算术才能学代数一样,NumPy就是数据分析的"算术基础"。虽然可以直接用计算器(Pandas),但理解底层原理才能走得更远。
3.2 核心数据结构:Series
3.2.1 创建与访问
什么是Series
类似于 NumPy 一维数组,但增加了 "标签",可以理解为「一维标签化数组」
Series 是 Pandas 中的一个核心数据结构,类似于一个一维的数组,具有数据和索引。
Series 可以存储任何数据类型(整数、浮点数、字符串等),并通过标签(索引)来访问元素。Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过标签来快速访问和操作数据。

Series 特点:
- 一维数组:Series 中的每个元素都有一个对应的索引值。
- 索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
- 大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
- 操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
- 缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
- 自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。
我们可以使用 Pandas 库来创建一个 Series 对象,并且可以为其指定索引(Index)、名称(Name)以及值(Values):
Python
import pandas as pd
s = pd.Series([10, 20, 30], index=["a", "b", "c"])创建Series
直接通过列表创建Series
Python
import pandas as pd
s = pd.Series([4, 7, -5, 3])
print(s)
# 0 4
# 1 7
# 2 -5
# 3 3
# dtype: int64|
Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。 |
- 通过列表创建Series时指定索引
Python
s = pd.Series([4, 7, -5, 3], index=["a", "b", "c", "d"])
print(s)
# a 4
# b 7
# c -5
# d 3
# dtype: int64- 通过列表创建Series时指定索引和名称
Python
s = pd.Series([4, 7, -5, 3], index=["a", "b", "c", "d"],name="hello_python")
print(s)
# a 4
# b 7
# c -5
# d 3
# Name: hello_python, dtype: int6名称的作用,与变量名的区别
在 Pandas 的 Series 中,name 参数用于给整个 Series 对象赋予一个名称。这个名称有以下几个用途:
1. 标识作用
- name 可以作为 Series 的标识,类似于给数据列取一个名字。
- 当你打印 Series 时,name 会显示在输出的最下方(如你的例子所示)。
2. DataFrame 列名
- 如果你将一个 Series 转换成 DataFrame 或与其他 DataFrame 合并,name 会自动成为列名。
- 例如:
|
输出:
|
3. 对齐操作
- 在 Pandas 运算(如 concat、merge 等)时,name 可以帮助对齐数据。
4. 导出数据
- 当你将 Series 导出为 CSV 或其他格式时,name 会成为列名。
name 的主要作用是 给 Series 一个标识,方便后续数据处理、合并或导出。如果只是单独使用 Series,name 可能看起来作用不大,但在更复杂的数据操作中(如 DataFrame 整合),它会很有用。
- 直接通过字典创建Series
Python
dic = {"a": 4, "b": 7, "c": -5, "d": 3}
s = pd.Series(dic)
print(s)
# a 4
# b 7
# c -5
# d 3
# dtype: int64
s1 = pd.Series(dic,index=["a","c"],name="aacc")
print(s1)
# a 4
# c -5
# Name: aacc, dtype: int64访问Series数据
以下是 Pandas 中访问 Series 数据的主要方法汇总表格:
|
方法分类 |
语法示例 |
描述 |
返回值 |
是否支持切片/布尔索引 |
|
位置索引 |
s.iloc[0] |
通过整数位置访问(从0开始) |
标量值 |
是 |
|
s.iloc[1:3] |
位置切片(左闭右开) |
Series |
||
|
标签索引 |
s.loc['a'] |
通过索引标签访问 |
标量值 |
是 |
|
s.loc[['a','b']] |
通过标签列表访问 |
Series |
||
|
直接索引 |
s[0] |
类似iloc(当索引非整数时可能混淆) |
标量值/Series |
是 |
|
s['a'] |
类似loc(优先标签索引) |
|||
|
布尔索引 |
s[s > 3] |
通过布尔条件筛选 |
Series |
是 |
|
s[~(s > 3)] |
取反条件 |
|||
|
函数访问 |
s.at['a'] |
快速访问单个标签(类似loc但效率更高) |
标量值 |
否 |
|
s.iat[0] |
快速访问单个位置(类似iloc但效率更高) |
|||
|
头部/尾部 |
s.head(3) |
访问前N行(默认5) |
Series |
否 |
|
s.tail(2) |
访问后N行(默认5) |
|||
|
取唯一值 |
s.unique() |
返回唯一值数组 |
ndarray |
否 |
|
值计数 |
s.value_counts() |
统计各值出现次数 |
Series |
- 优先使用**loc****/****iloc**:直接索引[]的行为可能因索引类型不同而变化,明确场景时建议显式使用loc(标签)或iloc(位置)。
- 切片差异:
- loc切片为闭区间(包含两端)
- iloc切片为左闭右开(与Python列表一致)
- 布尔索引:常用于条件过滤,如s[s > 3 & s < 10]。
Python
s = pd.Series([10, 20, 30, 40], index=['a', 'b', 'c', 'd'])
# 位置索引
print(s.iloc[0]) # 10
# 标签访问
s["a"]
# 标签索引
print(s.loc['b']) # 20
# 布尔索引
print(s[s > 25]) # c:30, d:40
# 花式索引
print(s[['a', 'c']]) # a:10, c:30
#使用布尔索引从Series中筛选满足某些条件的值
bools = s > s.mean() # 将大于平均值的元素标记为 True
print(bools)
# a False
# b True
# c True
# d False
# dtype: bool
print(s[bools])
# b 3.5
# c 6.8
# dtype: float64
# 使用where过滤
print(s.where(s > 20, -1)) # 小于等于20的值替换为-1Series的常用属性
|
属性 |
说明 |
|
index |
Series的索引对象 |
|
values |
Series的值 |
|
dtype或dtypes |
Series的元素类型 |
|
shape |
Series的形状 |
|
ndim |
Series的维度 |
|
size |
Series的元素个数 |
|
name |
Series的名称 |
|
loc[] |
显式索引,按标签索引或切片 |
|
iloc[] |
隐式索引,按位置索引或切片 |
|
at[] |
使用标签访问单个元素 |
|
iat[] |
使用位置访问单个元素 |
Python
import pandas as pd
arrs = pd.Series([11,22,33,44,55],name="atguigu",index=["a","b","c","d","e"])
# print(arrs)
# index Series的索引对象
print(arrs.index)
for i in arrs.index:
print(i)
print(arrs.values) # values Series的值
print(arrs.ndim) # ndim Series的维度
print(arrs.shape) # shape Series的形状
print(arrs.size) # size Series的元素个数
# dtype或dtypes Series的元素类型
print(arrs.dtype)
print(arrs.dtypes)
# name Series的名称
print(arrs.name)
# loc[] 显式索引,按标签索引或切片
print(arrs.loc["c"])
print(arrs.loc["c":"d"])
# iloc[] 隐式索引,按位置索引或切片
print(arrs.iloc[0])
print(arrs.iloc[0:3])
# at[] 使用标签访问单个元素
print(arrs.at["a"])
# iat[] 使用位置访问单个元素
print(arrs.iat[3])3.2.2 Series的运算
Plain Text
s1 = pd.Series([1, 2, 3, 4])
s2 = pd.Series([10, 20, 30, 40])
# 基本运算
print(s1 + s2) # 对应位置相加
print(s1 * 2) # 标量乘法3.2.3 常用方法与统计
|
用途分类 |
方法 |
说明 |
示例代码 |
|
数据预览 |
head() |
查看前 n 行数据,默认 5 行 |
s.head(3) |
|
数据预览 |
tail() |
查看后 n 行数据,默认 5 行 |
s.tail(2) |
|
条件判断 |
isin() |
判断元素是否包含在参数集合中 |
s.isin([1, 2]) |
|
缺失值处理 |
isna() |
判断是否为缺失值(如 NaN 或 None) |
s.isna() |
|
聚合统计 |
sum() |
求和,自动忽略缺失值 |
s.sum() |
|
聚合统计 |
mean() |
平均值 |
s.mean() |
|
聚合统计 |
min() |
最小值 |
s.min() |
|
聚合统计 |
max() |
最大值 |
s.max() |
|
聚合统计 |
var() |
方差 |
s.var() |
|
聚合统计 |
std() |
标准差 |
s.std() |
|
聚合统计 |
median() |
中位数 |
s.median() |
|
聚合统计 |
mode() |
众数(可返回多个) |
s.mode() |
|
聚合统计 |
quantile(q) |
分位数,q 取 0~1 之间 |
s.quantile(0.25) |
|
聚合统计 |
describe() |
常见统计信息(count、mean、std、min、25%、50%、75%、max) |
s.describe() |
|
频率统计 |
value_counts() |
每个唯一值的出现次数 |
s.value_counts() |
|
频率统计 |
count() |
非缺失值数量 |
s.count() |
|
频率统计 |
nunique() |
唯一值个数(去重) |
s.nunique() |
|
唯一处理 |
unique() |
获取去重后的值数组 |
s.unique() |
|
唯一处理 |
drop_duplicates() |
去除重复项 |
s.drop_duplicates() |
|
抽样分析 |
sample() |
随机抽样 |
s.sample(2) |
|
排序操作 |
sort_index() |
按索引排序 |
s.sort_index() |
|
排序操作 |
sort_values() |
按值排序 |
s.sort_values() |
|
替换值 |
replace() |
替换值 |
s.replace({1: 100}) |
|
转换结构 |
to_frame() |
将 Series 转为 DataFrame |
s.to_frame() |
|
比较判断 |
equals() |
判断两个 Series 是否完全相等 |
s1.equals(s2) |
|
信息提取 |
keys() |
返回 Series 的索引对象 |
s.keys() |
|
统计关系 |
corr() |
计算相关系数(默认皮尔逊) |
s1.corr(s2) |
|
统计关系 |
cov() |
协方差 |
s1.cov(s2) |
|
可视化 |
hist() |
绘制直方图(需安装 matplotlib) |
s.hist() |
|
遍历操作 |
items() |
返回索引和值的迭代器 |
for i, v in s.items(): print(i, v) |
Python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# head() 查看前n行数据,默认5行
print(arrs.head())
# tail() 查看后n行数据,默认5行
print(arrs.tail(3))
# describe() 常见统计信息
print(arrs.describe())
# count() 非缺失值元素的个数
print(arrs.count())
# keys() 返回Series的索引对象
print(arrs.index)
print(arrs.keys())
# isin() 判断数组中的每一个元素是否包含在参数集合中
print(arrs.isin([11]))
# isna() 元素是否为缺失值
print(arrs.isna())
#统计
# sum() 求和,会忽略 Series 中的缺失值
print(arrs.sum())
# mean() 平均值
print(arrs.mean())
# min() 最小值
print(arrs.min())
# max() 最大值
print(arrs.max())
# var() 方差 每个元素与平均值的差 的平方 的和
print(arrs.var())
# std() 标准差 方差的平方根
print(arrs.std())
# print(arrs.var())
# median() 中位数
# 若数据集的元素个数为奇数,中位数就是排序后位于中间位置的数值。
# 若数据集的元素个数为偶数,中位数则是排序后中间两个数的平均值。
# 去除缺失值之后,arrs 就变成了 [11, 22, 44, 22]。
# 对 [11, 22, 44, 22] 进行排序,得到 [11, 22, 22, 44]
print(arrs.median())
# mode() 众数
print(arrs.mode())
# quantile() 指定位置的分位数,如quantile(0.5)
# 分位数:分位数是把一组数据按照从小到大的顺序排列后,分割成若干等份的数值点。
# 0.25 分位数就是将数据从小到大排序后,位于 25% 位置处的数值。
# 插值方法:当计算分位数时,若位置不是整数,就需要借助插值方法来确定分位数值。# "midpoint" 插值方法是指当分位数位置处于两个数据点之间时,取这两个数据点的
# 平均值作为分位数值。
# 对于有 n个数据点的有序数据集,q分位数的位置 i可以通过公式 i=(n−1)q来计
# 算。这里 n=4,q=0.25,则 i=(4−1)×0.25=0.75。这意味着 0.25 分位数处于第一个# 数据点(值为 11)和第二个数据点(值为 22)之间。使用 "midpoint" 插值方法,
# 分位数值就是这两个数据点的平均值,即 (11+22)÷2=16.5
print(arrs.quantile(0.25, interpolation="midpoint"))
print(len(arrs))
# drop_duplicates() 去重 这里可以看出,底层None也作为NaN处理
print(arrs.drop_duplicates())
# unique() 去重后的数组
print(arrs.unique())
# nunique() 去重后非缺失值元素元素个数
print(arrs.nunique())
# sample() 随机采样
print(arrs.sample())
# value_counts() 每个元素的个数
print(arrs.value_counts())
# sort_index() 按索引排序
print(arrs.sort_index())
# sort_values() 按值排序
print(arrs.sort_values())
# replace() 用指定值代替原有值
print(arrs.replace(22,"haha"))
# to_frame() 将Series转换为DataFrame
print(arrs.to_frame())
# equals() 判断两个Series是否相同
arr1 = pd.Series([1,2,3])
arr2 = pd.Series([1,2,3])
print(arr1.equals(arr2))
# corr() 计算与另一个Series的相关系数
# arr1.corr(arr2):由于 arr1 和 arr2 的值完全相同,它们之间是完全正相关的,
#因此相关系数为 1。
# arr1.corr(arr3):arr1 的值是递增的,而 arr3 的值是递减的,它们之间是完全
# 负相关的,所以相关系数为 -1。
# arr1.corr(arr4):arr1 和 arr4 的值都是递增的,且变化趋势一致,它们之间是
# 完全正相关的,相关系数为 1。
# arr5.corr(arr6):arr5 和 arr6 的值之间没有明显的线性关系,它们的相关系数
# 为 0。
arr3 = pd.Series([3,2,1])
arr4 = pd.Series([6,7,8])
arr5 = pd.Series([1, -1, 1, -1])
arr6 = pd.Series([1, 1, -1, -1])
print(arr1.corr(arr2))
print(arr1.corr(arr3))
print(arr1.corr(arr4))
print(arr5.corr(arr6))
# cov() 计算与另一个Series的协方差
# 协方差用于衡量两个变量的总体误差,其值的正负表示两个变量的变化方向关系:
# 正值表示同向变化,负值表示反向变化。
print(arr1.cov(arr3))
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)