AGI| Neo4j 处理模型数据,轻松实现效率翻倍
想象一下,知识图谱就像一张巨大的蜘蛛网,只不过网上挂的不是露珠,而是无数个知识点,比如"苹果""牛顿""万有引力""iPhone"……每个知识点(实体)之间用线(关系)连接起来,线上还贴着标签,比如"牛顿→发现→万有引力""苹果→是→水果"或者"小米→生产→小米su7"。类比于乐高积木:每个积木块代表一个事物(比如"雷军","水"),积木之间的接口形状不同,只有匹配的关系才能拼在一起(比如"雷军→
23年中旬的时候参与到了公司自研产品"贾维斯"的一次交付项目,首次接触到了传统的NLP,23年六月份时,RAG还没有成为一个非常热门的技术,对于长文本,那时我们还需要用人工录入的形式,用枚举法将无数用户的相似提问命中从政府文件中提取出的标准答案,费时费力。因此大学时产生了将传统NLP与大模型相结合的想法,通过对NLP的探索接触到了Neo4j,在探索过程中发现了知识结构化对模型数据处理一些新的可能性。本次分享希望能帮助大家在面对特定需求场景时能够多一个技术选项。
目录
1. Neo4j

1.1 什么是知识图谱
想象一下,知识图谱就像一张巨大的蜘蛛网,只不过网上挂的不是露珠,而是无数个知识点,比如"苹果""牛顿""万有引力""iPhone"……每个知识点(实体)之间用线(关系)连接起来,线上还贴着标签,比如"牛顿→发现→万有引力""苹果→是→水果"或者"小米→生产→小米su7"。
类比于乐高积木:每个积木块代表一个事物(比如"雷军","水"),积木之间的接口形状不同,只有匹配的关系才能拼在一起(比如"雷军→喝→水"能拼,"雷军→喝→汽车"就拼不上)。
人脑中的联想能力:当你想到"咖啡",大脑会自动跳出"提神""咖啡豆""瑞幸""苦"……知识图谱就是模仿这种联想能力,让计算机也能"触类旁通"。
破案用的线索墙:美剧里墙上贴满照片,用红线标记人物关系,知识图谱就像数字化的线索墙,能瞬间找到"张三的表弟的同事曾经投资过哪家公司"这种复杂关联。
举个实际例子:
如果你问手机:"泰坦尼克号导演还拍了哪些电影?"
知识图谱会立刻拆解问题:
-
- 泰坦尼克号 → 导演 → 詹姆斯·卡梅隆
- 詹姆斯·卡梅隆 → 导演 → 《阿凡达》《终结者》…… 然后直接告诉你答案
1.2 什么是图谱数据库
图数据库是基于图论的数据管理系统,通过节点(Node)、关系(Relationship)和属性(Property)构建网络化数据结构。与传统关系型数据库相比,图数据库直接存储实体间的关系,避免了多表连接的复杂性,尤其擅长处理社交网络、知识图谱等高度关联的场景。
1.3 什么是 Neo4j?
Neo4j 的核心概念:
节点(Node):
表示实体(如用户、商品),支持标签(Label)分类(如 :Person、:Product),每个标签可附加多个属性(如 {name: "kunkun", age: 30})。
路径(Path):由节点和关系组成的序列,用于描述遍历路径。
关系(Relationship):
有向边连接两个节点,必须定义类型(Type)(如 :FRIEND、:BROTHER),可包含属性(如 {count: 2025})。
关系支持索引优化,提升查询效率。
属性(Property):
键值对存储附加信息,支持动态扩展(如节点属性 name: "kunkun",关系属性 weight: 5)
Neo4j 的特性与生态
-
- 高性能:遍历深度与数据量无关,十亿级节点关系仍可保持毫秒级响应
- 灵活性:无固定模式(Schema-free),支持动态调整数据结构
- 生态系统:
- Neo4j AuraDB:全托管云服务,简化运维
- Graph Data Science(GDS):集成 65+图算法(如PageRank、社区发现),支持机器学习与图分析
- Neo4j Bloom:无代码可视化工具,便于业务人员探索数据
- 1.4 Cypher 查询语言
Cypher 查询语言非常类似于SQL语言,
例:
MATCH:类似 SQL 的SELECTCALL:调用图算法或存储过程(如apoc.path.expand,可以DIY的遍历算法)RETURN:定义返回结果,支持聚合函数(如COUNT、SUM)WHERE:同SQL
MATCH (n) RETURN n(查询所有节点)
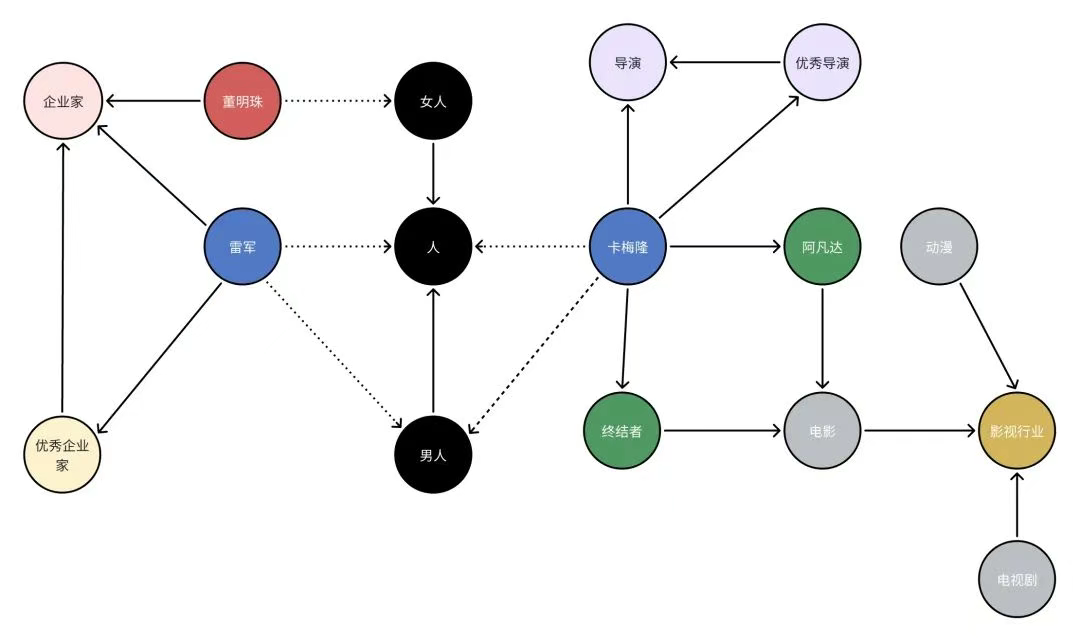
MERGE (董明珠:人:女人 {name: "董明珠"})
MERGE (雷军:人:男人 {name: "雷军"})
MERGE (卡梅隆:人:男人 {name: "卡梅隆"})
MERGE (企业家:职业 {title: "企业家"})
MERGE (优秀企业家:职业 {title: "优秀企业家"})
MERGE (导演:职业 {title: "导演"})
MERGE (优秀导演:职业 {title: "优秀导演"})
MERGE (阿凡达:作品 {title: "阿凡达"})
MERGE (终结者:作品 {title: "终结者"})
MERGE (电影:分类 {title: "电影"})
MERGE (动漫:分类 {title: "动漫"})
MERGE (电视剧:分类 {title: "电视剧"})
MERGE (影视行业:行业 {title: "影视行业"});
// 董明珠的关系
MATCH (a:人 {name: "董明珠"}), (b:职业 {title: "企业家"})
MERGE (a)-[:IS_A]->(b);
// 雷军的关系
MATCH (a:人 {name: "雷军"}), (b:职业 {title: "企业家"})
MERGE (a)-[:IS_A]->(b)
WITH a
MATCH (c:职业 {title: "优秀企业 家"})
MERGE (a)-[:IS_A]->(c);
// 卡梅隆的关系
MATCH (a:人 {name: "卡梅隆"}), (b:职业 {title: "导演"})
MERGE (a)-[:IS_A]->(b)
WITH a
MATCH (c:职业 {title: "优秀导演"})
MERGE (a)-[:IS_A]->(c);
// 作品关系
MATCH (a:作品 {title: "阿凡达"}), (b:分类 {title: "电影"}), (c:分类 {title: "动漫"}), (d:行业 {title: "影视行业"})
MERGE (a)-[:BELONGS_TO]->(b)
MERGE (a)-[:BELONGS_TO]->(c)
MERGE (a)-[:BELONGS_TO]->(d);
// 导演关系
MATCH (a:人 {name: "卡梅隆"}), (b:作品 {title: "阿凡达"}), (c:作品 {title: "终结者"})
MERGE (a)-[:DIRECTED]->(b)
MERGE (a)-[:DIRECTED]->(c);
// 分类关系
MATCH (a:分类 {title: "电影"}), (b:分类 {title: "电视剧"}), (c:分类 {title: "动漫"}), (d:行业 {title: "影视行业"})
MERGE (a)-[:BELONGS_TO]->(d)
MERGE (b)-[:BELONGS_TO]->(d)
MERGE (c)-[:BELONGS_TO]->(d);2. Neo4j 的安装与配置
- 2.1 安装方式
- 本地安装:下载 Neo4j Desktop 或 Community Edition(自己尝试的话,建议使用Neo4j Desktop,启动时需要先断网,大陆IP被封锁,会有启动进程卡死的情况)
https://neo4j.com/product/auradb/![]() https://link.zhihu.com/?target=https%3A//neo4j.com/product/auradb/
https://link.zhihu.com/?target=https%3A//neo4j.com/product/auradb/
- Docker 安装:使用
docker run快速启动(开发环境更推荐使用docker)
- 2.3 启动与访问
- 使用 Neo4j Browser 访问数据库
- 默认web访问地址:
http://localhost:7474 - 7687为协议端口
3. Why Neo4j?
谈论为什么选择Neo4j的时候,探讨的是图数据库的优势
高效处理复杂关系数据
- 关系查询性能:图数据库直接存储实体间的关系,避免了关系型数据库的多表连接(JOIN)操作。例如,在社交网络中查询"朋友的朋友"时,图数据库通过指针式遍历(O(1)时间复杂度)即可实现,而传统数据库需要多次JOIN操作(O(n²)复杂度)
- 路径分析能力:支持最短路径、模式匹配等复杂算法。例如,在金融风控中,可通过路径查询快速识别异常交易链路(如循环转账)
- 动态扩展性:数据规模增长对性能影响较小,十亿级节点关系仍可保持毫秒级响应
灵活的数据模型
- 无固定模式(Schema-free):无需预定义表结构,支持动态添加节点、关系和属性。例如,社交网络可随时新增用户兴趣标签或关系类型(如同事,校友")
- 自然表达关联关系:节点和关系均可携带属性,例如用户节点存储年龄、性别,购买关系存储时间、金额,更贴合现实世界的数据逻辑
4. Neo4j 与 Python 的集成
4.1 使用 Py2neo 库
-
- 安装:
pip install py2neo - 连接 Neo4j 数据库
- 基本操作:
- 创建节点和关系
- 执行 Cypher 查询
- 数据更新与删除
- 安装:
4.2 示例代码
from py2neo import Graph, Node, Relationship
#连接 Neo4j
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))#创建节点
xiongone = Node("Person", name="熊大")
xiongtwo = Node("Person", name="熊二")
graph.create(xiongone)
graph.create(xiongtwo)#创建关系
relationship = Relationship(alice, "KNOWS", bob)
graph.create(relationship)#查询数据
result = graph.run("MATCH (n) RETURN n")for record in result:print(record)5.如何与交付项目相结合
在了解Neo4j的一些特点以后,我们会发现其在处理多层级关系和结构化推理上的优势,于是我们可以使用它为文档审查类RAG项目提供独特的增强能力。
![]()
2024年中旬,微软的GraphRAG在github上突然爆火,GraphRAG的思想非常适合于客户提供的审查点之间存在复杂或大量逻辑关联的情况(即较为复杂的制式文档审查),而传统RAG基于相似度检索会略过这种关联关系的检索。
5.1 适合 GraphRAG 的场景
微软在GraphRAG的官方文档中介绍到:GraphRAG通过构建知识图谱、社区层次结构及生成社区摘要来提升语言模型处理复杂信息的能力。一般来说,有大量实体与关系的场景就是适合GraphRAG的场景。
1. 法律条文审查文档(强关联场景)
- 场景:法律条款之间存在复杂的引用、修订和冲突关系(如条款A引用条款B,条款B被条款C废止),传统 RAG 基于文本相似度的检索,而条款之间的关系洞察能力会完全交给模型的通识能力。
- GraphRAG 优势:
- 构建法律条文知识图谱,显式建模条款间的 引用链、修订历史、冲突关系。
- 支持多跳推理(如查询某条款的所有立法依据)。
2. 医药行业文档审查(实体关系密集型场景)
- 场景:药品说明书、临床试验报告中包含大量实体(药物成分、适应症、禁忌症)及其相互作用关系,传统 RAG 难以捕捉隐性关联。
- GraphRAG 优势:
- 构建 药物-成分-副作用 关系网络,快速定位药物禁忌组合(如药物A与药物B存在相互作用风险)。
- 构建 药物-禁忌组合-疗效-对应症 知识图谱,结合模型通识能力,提供患者的用药建议。
3. 金融合规审查(动态规则场景)
- 场景:合规规则常涉及多文档条款组合,传统 RAG 的碎片化检索无法满足逻辑拼图需求。这种场景就更类似于无监督学习结果,被审查文档在规则数据的聚合走一遍后最终到达可能触犯的法律条款的那一个节点
- GraphRAG 优势:
- 将规则拆解为条件节点和逻辑关系。
- 通过图遍历自动触发关联规则链,找到可能触犯的条款。
5.2 GraphRAG 实现思路
核心逻辑:向量检索 + 图关系扩展
微软官方的解释:
- 索引阶段:把输入语料切分成 TextUnits,提取其中实体、关系和关键主张;运用 Leiden 技术对图进行层次聚类;自下而上生成各社区及其组成部分的摘要。
- 查询阶段:有全局搜索、局部搜索和 DRIFT 搜索三种模式,利用构建好的结构为语言模型提供回答问题的材料。
- 知识图谱构建:
- 实体与关系抽取:
- 使用 NLP 工具(如 spaCy、LLM)从文档中提取实体(法律条款、医药成分)及关系(引用、冲突、相互作用)。
- 示例:从法律文本中抽取 条款A-依据于->条款B。从药品说明书中抽取 药物A-有疗效->症状B。
2.图谱存储:将实体和关系导入 Neo4j,附加属性(如条款生效日期、药物剂量范围)。
2. 图增强检索:
-
- 混合检索流程:
- Step 1:rerank获取相似文本。
- Step 2:从相似文本中关联的实体出发,通过图遍历来扩展上下文(实体指向的其它节点)。
例如:rerank文本为,"神州数码是家中国公司",图谱数据库中"神州数码"指向了"上市公司",最后的文本就是"神州数码是家中国公司 上市公司",如果添加了NLP,那文本就可以优化为"神州数码是家中国公司 神州数码是家上市公司"。(然而对于大多数的交付项目来说,为客户的知识图谱再去专门搭一套NLP实在有点奢侈了)
6. 传统 RAG 改造为 GraphRAG 的方法
1. 识别低效场景
- 症状:传统 RAG 出现以下问题时,需考虑引入 GraphRAG:
- 检索结果遗漏关键逻辑链(如条款引用缺失)。
- 长文档上下文碎片化,无法拼接完整逻辑。
- 用户提问涉及多实体关系推理(如"中成药A与哪些西药不能一起服用?")。
2. 改造步骤
- Step 1:轻量级图谱构建
- 从现有文档中提取核心实体及其关系,无需完全构建全量图谱。
- 建议使用大模型来分批处理文本生成Cypher语句。
- Step 2:混合检索架构
向量检索 + 图扩展
def hybrid_retrieval(query):
# rerank
vector_results = vector_db.search(query, top_k=5)
# 用大模型提取实体
entities = llm_extract_entities(vector_results)
# 图扩展
graph_context = neo4j.query(f"""
MATCH (e:Entity)-[r]->(related)
WHERE e.name IN {entities}
RETURN related.text
""")
return vector_results + graph_context #简单粗暴的拼接作者:刘桓羽 | AI交付工程师
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,回复【AI】进入AI社群讨论。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)