YOLO实战篇:数据集的制作
🏆🎉🤔本文是YOLO实战的基石篇,详细讲解目标检测数据集制作全流程。文章深入解析VOC和COCO两大基准数据集的结构与标注格式,包括VOC的XML文件组织、COCO的JSON标注体系。重点演示如何将VOC/COCO格式转换为YOLO所需的TXT格式,提供自动化脚本和手动转换两种方法。通过实际代码示例,教会读者下载、解析、筛选和重组数据集,为YOLO模型训练打下坚实基础。适合YOLO初学者和需

前言
Hello,大家好,我是
GISer Liu😁,一名热爱AI技术的GIS开发者。本系列是作者参加DataWhale 2025年6月份Yolo原理组队学习的技术笔记文档,这里整理为博客,希望能帮助Yolo的开发者少走弯路!
🚀 欢迎来到 YOLO 实战的基石篇——数据集制作!在目标检测领域,模型的性能不仅取决于算法的优劣,更离不开高质量、标准化的数据集。“Garbage in, garbage out” 这句话在AI领域是至理名言。
为了能顺利地开展像城市交通车辆检测这样的项目,咱必须先打好内功,彻底搞懂数据集的门道。本文将作为一篇保姆级指南,带你深入探索目标检测的两大基准数据集——VOC 和 COCO,并最终聚焦于YOLO系列实战中应用最广的 YOLO 格式。
通过本文,你将学到:
- 核心数据集的结构与区别:彻底弄懂 VOC 和 COCO 这两大经典数据集的组织方式和标注内涵。
- YOLO 格式的精髓:理解为什么 YOLO 需要自己独特的格式,以及如何将其他格式向它转换。
- 从零到一的实战能力:掌握下载、转换、筛选和创建自定义数据集的全套流程,为你自己的项目扫清障碍。
无论你是刚入门Yolo的大学生,还是希望将YOLO应用于自己项目的开发者,希望本教程能帮到你。OK, 开始吧!🛠️
本文内容随时更新,这里是初始化版本,当前版本v0.1,记录时间20250701;
一、PASCAL VOC 数据集全面解析

PASCAL VOC 是由欧盟资助的 PASCAL 网络组织发起的一个世界级的计算机视觉挑战赛。它所使用的数据集是计算机视觉,特别是目标检测领域的 “Hello, World!”,是无数算法的试验田和基准。
1. 什么是 VOC 数据集?
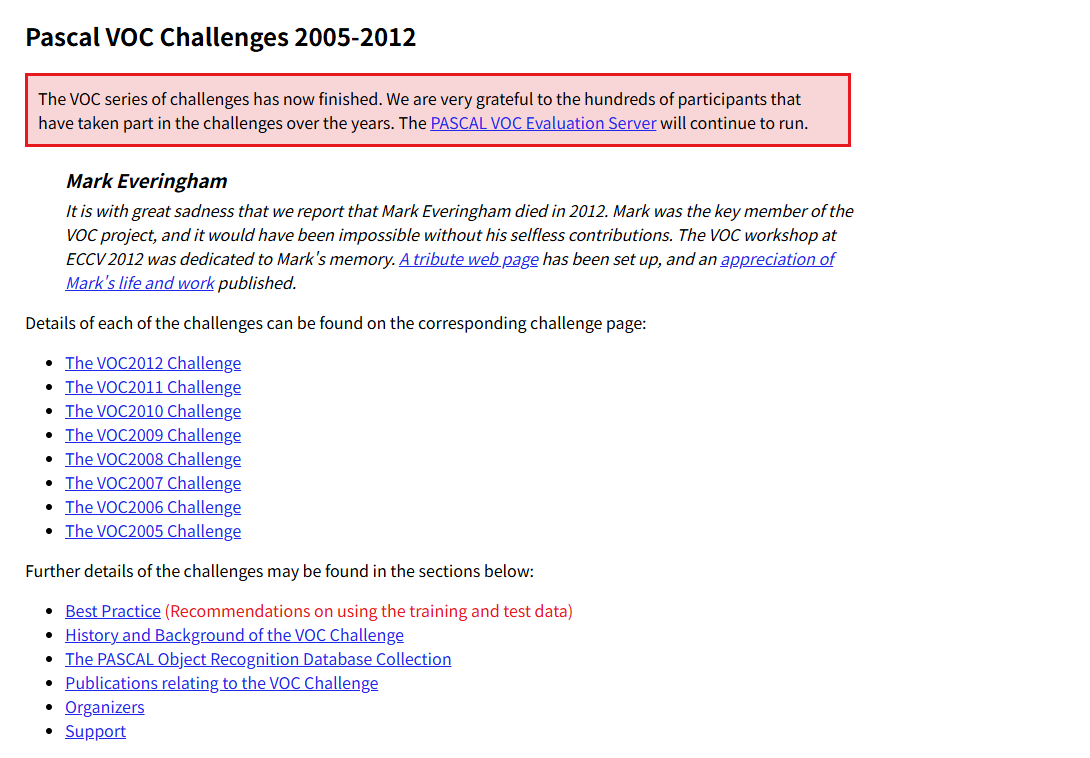
VOC 数据集是一个用于目标检测、图像分割和图像分类任务的著名基准。对于任何从事相关领域研究和开发的工程师来说,它都是一个必不可少的数据集。其主要用途包括:
- 训练和评估深度学习模型:如 YOLO, Faster R-CNN, SSD 等经典和现代的目标检测模型。
- 实例分割研究:为 Mask R-CNN 等模型提供像素级的标注。
- 图像分类任务:其标注信息也可用于训练分类模型。
它总共包含 20个对象类别:aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor。
可以看到图中,存在从 2005 年 - 2012 年的比赛,每年的比赛都提供了相应年份的数据集。这样一看,VOC 数据集其实包括了从 2005 - 2012 年,8 年的数据集。而我们常用的是2007 和 2012 年的数据集,原因如下:
- VOC 2007 数据集是一个巨大的转折点。这个时候的数据集无论是从数据量的规模还是目标的类别都能够满足绝大多数模型的训练要求
- 🤔08 年,VOC 数据集重新建立了新的数据集,然后每年都在这个数据集的基础上,不断进行扩充。到了 11/12 年,数据集数量还是种类都到了顶峰。但是 12 年在 11 年的基础上对标注进行了一些优化改进。大家更习惯喜欢 12 年数据集。
2. VOC2007 与 VOC2012:版本与训练策略
PASCAL VOC 数据集包括两个最核心、使用最广泛的版本:VOC2007 和 VOC2012。这两个数据集的图片是互斥的(没有重叠),在学术论文和工业实践中,研究者们通常会采用一些公认的组合方式来训练和测试模型,以保证结果的公平性和可比性:
07+12: 使用 VOC2007 和 VOC2012 的trainval集(共16,551张图)进行训练,然后在 VOC2007 的test集(4,952张图)上进行测试。这是最常见的配置之一。07++12: 使用 VOC2007 的全部数据 (train+val+test,共9,963张图) 和 VOC2012的trainval集(11,540张图)共同作为训练集。由于 VOC2012 的test集标签未公开,其测试结果需要提交到官方的 PASCAL VOC Evaluation Server 进行评估。07+12+COCO: 迁移学习策略。先在规模更大的 MS COCO 数据集的trainval上进行预训练,获得一个强大的基础模型,然后再使用07+12的训练集进行微调(Fine-tuning),最后在 VOC2007 的test集上测试。07++12+COCO: 与上一条类似,只是在微调阶段使用了更庞大的07++12数据集。同样,其最终性能也需在 VOC2012 评估服务器上获得。
VOC2007与VOC2012数据统计详情:
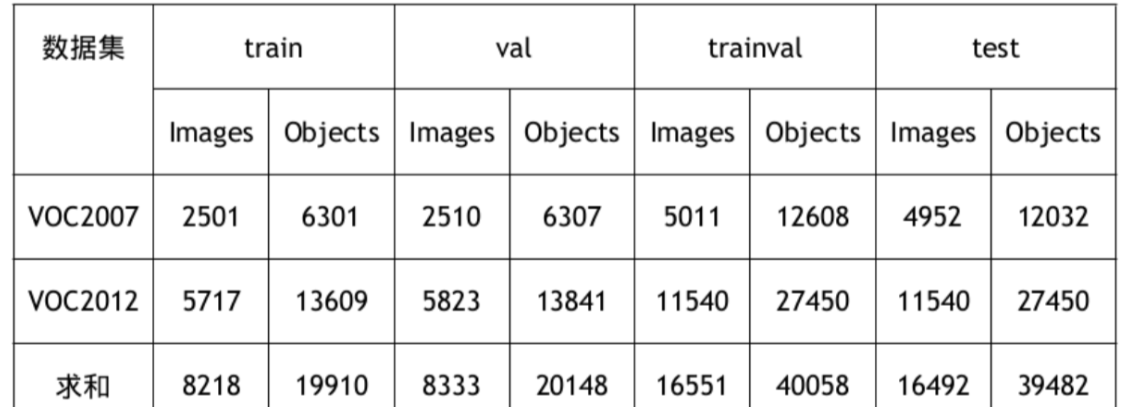
| 数据集 | 用途 | 图片数量 | 标注框数量 |
|---|---|---|---|
| VOC2007 | train |
2,501 | 6,301 |
| VOC2007 | val |
2,510 | 6,307 |
| VOC2007 | trainval |
5,011 | 12,608 |
| VOC2007 | test |
4,952 | 12,032 |
| VOC2012 | train |
5,717 | 13,609 |
| VOC2012 | val |
5,823 | 13,841 |
| VOC2012 | trainval |
11,540 | 27,450 |
| VOC2012 | test |
11540 | 27450 |
3. 文件结构:深入 VOCdevkit
下载并解压 VOC 数据集后,你会得到一个名为 VOCdevkit 的主目录。其内部结构设计得非常规整、层次分明,堪称数据集组织的典范。
# 第一级:数据集开发工具包
VOCdevkit
└── VOC2007
# 第二级:年份版本
├── Annotations/ # 存放所有图像的XML格式标注文件
├── ImageSets/ # 存放定义数据集划分的txt文件
├── JPEGImages/ # 存放所有的.jpg格式原图
├── SegmentationClass/ # 用于语义分割的掩码图
└── SegmentationObject/ # 用于实例分割的掩码图
# 第三级:以Annotations和JPEGImages为例
# Annotations/
# ├── 000001.xml
# └── 000002.xml ...
# JPEGImages/
# ├── 000001.jpg
# └── 000002.jpg ...
# 第三级:深入ImageSets
# ImageSets/
# ├── Layout/
# ├── Main/ # 目标检测主要使用这个目录下的文件
# └── Segmentation/
# 第四级:深入ImageSets/Main/
# Main/
# ├── aeroplane_test.txt
# ├── aeroplane_train.txt
# ├── aeroplane_val.txt
# ... (每个类别都有 train, val, test, trainval 四个文件)
# ├── person_test.txt
# ...
# ├── test.txt # 全局测试集列表
# ├── train.txt # 全局训练集列表
# ├── trainval.txt # 全局训练验证集列表
# └── val.txt # 全局验证集列表
对 ImageSets/Main/ 目录的特别说明:
这个目录是理解 VOC 数据集划分的关键。
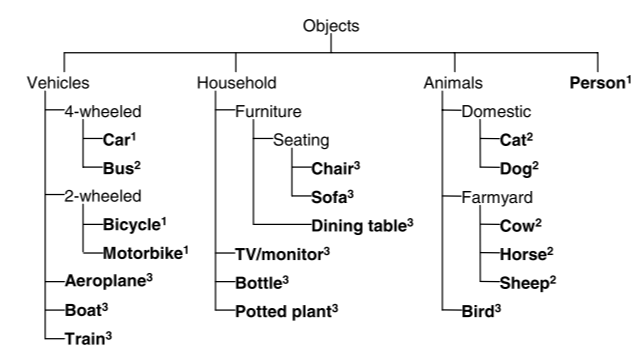
train.txt,val.txt,test.txt: 这几个文件定义了整个数据集的划分。文件中的每一行是对应JPEGImages目录下的一张图片的文件名(不含后缀)。[class_name]_train.txt,[class_name]_val.txt等:这些是针对每一个类别的划分文件。它们与全局划分文件的行数完全一致,但内容稍有不同。在每个图片名后面会跟一个数字:1: 表示这张图片是该类别的正样本(即图片中包含该类别的物体)。-1: 表示这张图片是该类别的负样本(即图片中不包含该类别的物体)。0: (在某些文件中) 表示该物体存在,但是一个困难样本 (difficult=1)。
这种精细的划分方式在早期的机器学习模型(如 SVM)训练中非常有用,可以方便地为每个类别单独准备正负样本集。
4. XML 标注格式:逐个标签解读
VOC 的灵魂在于它的 .xml 标注文件,它以一种人类和机器都易于阅读的方式,存储了图片的所有元信息。让我们以一个真实的 XML 文件为例,逐个标签进行解读。
示例 (2007_000027.xml):
<annotation>
<folder>VOC2012</folder> <filename>2007_000027.jpg</filename> <source> <database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> <width>486</width> <height>500</height> <depth>3</depth> </size>
<segmented>0</segmented> <object>
<name>person</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>174</xmin> <ymin>101</ymin> <xmax>349</xmax> <ymax>351</ymax> </bndbox>
</object>
</annotation>
5. Ultralytics 实战配置:VOC.yaml 解读
现代框架如 ultralytics 极大地简化了数据集的使用。我们只需一个 .yaml 配置文件,就可以让框架自动完成下载、解压、格式转换等所有繁琐工作。下面是对 VOC.yaml 的完整解读。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
# 文档: https://docs.ultralytics.com/datasets/detect/voc/
# 使用示例: yolo train data=VOC.yaml
# 1. 路径定义
path: ../datasets/VOC # 数据集将被下载和解压到的根目录 (相对于ultralytics项目)
# 2. 数据集划分定义 (采用 07+12 策略)
train: # 训练集图片 (共 16551 张)
- images/train2012
- images/train2007
- images/val2012
- images/val2007
val: # 验证集图片 (共 4952 张)
- images/test2007
test: # 测试集 (可选, 这里与验证集相同)
- images/test2007
# 3. 类别名称定义 (索引从0开始)
names:
0: aeroplane
1: bicycle
2: bird
3: boat
4: bottle
5: bus
6: car
7: cat
8: chair
9: cow
10: diningtable
11: dog
12: horse
13: motorbike
14: person
15: pottedplant
16: sheep
17: sofa
18: train
19: tvmonitor
# 4. 内嵌的自动化Python脚本
# 当你运行训练命令时,如果框架找不到数据,就会执行这里的脚本
download: |
import xml.etree.ElementTree as ET
from tqdm import tqdm
from ultralytics.utils.downloads import download
from pathlib import Path
# 核心函数:将VOC的XML标注转换为YOLO的txt格式
def convert_label(path, lb_path, year, image_id):
# 内部函数:执行坐标转换和归一化
def convert_box(size, box):
# size: (width, height), box: (xmin, xmax, ymin, ymax)
dw, dh = 1. / size[0], 1. / size[1]
# 计算中心点和宽高
x, y, w, h = (box[0] + box[1]) / 2.0, (box[2] + box[3]) / 2.0, box[1] - box[0], box[3] - box[2]
# 归一化
return x * dw, y * dh, w * dw, h * dh
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
out_file = open(lb_path, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
names = list(yaml['names'].values()) # 从YAML配置中获取类别列表
for obj in root.iter('object'):
cls = obj.find('name').text
# 忽略困难样本和不在列表中的类别
if cls in names and int(obj.find('difficult').text) != 1:
xmlbox = obj.find('bndbox')
# 提取坐标并进行转换
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
cls_id = names.index(cls) # 获取类别索引
# 写入YOLO格式: class_id x_center y_center width height
out_file.write(" ".join(str(a) for a in (cls_id, *bb)) + '\n')
# 主逻辑:下载和转换
# 定义下载的根目录
dir = Path(yaml['path'])
# 定义下载链接
url = 'https://github.com/ultralytics/assets/releases/download/v0.0.0/'
urls = [f'{url}VOCtrainval_06-Nov-2007.zip',
f'{url}VOCtest_06-Nov-2007.zip',
f'{url}VOCtrainval_11-May-2012.zip']
# 执行下载和解压
download(urls, dir=dir / 'images', curl=True, threads=3, exist_ok=True)
# 主逻辑:执行转换
path = dir / 'images/VOCdevkit'
# 遍历所有需要的数据集部分
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
# 创建目标目录
imgs_path = dir / 'images' / f'{image_set}{year}'
lbs_path = dir / 'labels' / f'{image_set}{year}'
imgs_path.mkdir(exist_ok=True, parents=True)
lbs_path.mkdir(exist_ok=True, parents=True)
# 读取划分文件,获取图片ID列表
with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
image_ids = f.read().strip().split()
# 遍历每张图片进行处理
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # 原始图片路径
lb_path = (lbs_path / f.name).with_suffix('.txt') # 新的标签路径
f.rename(imgs_path / f.name) # 移动图片
convert_label(path, lb_path, year, id) # 调用函数,转换标签
6. 下载、重组与筛选
这个工作流模拟了研究中的一个完整流程:从下载原始数据开始,一步步进行重组、简化,并最终筛选出自己感兴趣的类别来创建一个小型的“玩具”数据集进行快速实验。
① 下载数据 (download_voc.sh)
这是一个 Bash 脚本,用于从 PASCAL VOC 的镜像网站下载数据压缩包,并自动解压。
#!/bin/bash
# download_voc.sh
# 功能:下载并解压 PASCAL VOC 2007 和 2012 数据集
# 检查是否提供了目标目录作为参数
if (( $# != 1 )); then
echo "使用方法: ./download_voc.sh <目标目录>"
exit 1
fi
# 创建目标目录
mkdir -p $1
# 下载文件, -nc 选项表示如果文件已存在则不重新下载
wget -nc -P $1 http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar \
http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar \
http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
# 解压文件到指定目录, -C 选项指定解压路径, > /dev/null 表示不输出解压过程
tar -xvf $1/VOCtrainval_11-May-2012.tar -C $1 > /dev/null
tar -xvf $1/VOCtrainval_06-Nov-2007.tar -C $1 > /dev/null
tar -xvf $1/VOCtest_06-Nov-2007.tar -C $1 > /dev/null
echo "VOC 数据集下载并解压完成!"
exit 0
使用: ./download_voc.sh ./data
② 重组目录 (organize_voc.sh)
下载后的 VOCdevkit 目录结构虽然标准,但训练时我们更喜欢一个清晰的 train/ 和 test/ 结构。此脚本负责完成这个重组工作。
#!/bin/bash
# organize_voc.sh
# 功能: 将VOCdevkit中的数据重组为 train/ 和 test/ 结构
# 检查参数
if (( $# != 1 )); then
echo "使用方法: ./organize_voc.sh <包含VOCdevkit的目录>"
exit 1
fi
BASE_PATH=$1
# 创建新的目录结构
for part in 'train' 'test'; do
mkdir -p $BASE_PATH/VOC_Detection/$part/images
mkdir -p $BASE_PATH/VOC_Detection/$part/targets
done
# 移动 VOC 2007 和 2012 的 trainval 集到新的 train 目录
for year in 2007 2012; do
# 读取 trainval.txt 并移动图片和标注
for img in $(cat $BASE_PATH/VOCdevkit/VOC$year/ImageSets/Main/trainval.txt); do
mv $BASE_PATH/VOCdevkit/VOC$year/JPEGImages/$img.jpg $BASE_PATH/VOC_Detection/train/images/
mv $BASE_PATH/VOCdevkit/VOC$year/Annotations/$img.xml $BASE_PATH/VOC_Detection/train/targets/
done
done
# 移动 VOC 2007 的 test 集到新的 test 目录
for img in $(cat $BASE_PATH/VOCdevkit/VOC2007/ImageSets/Main/test.txt); do
mv $BASE_PATH/VOCdevkit/VOC2007/JPEGImages/$img.jpg $BASE_PATH/VOC_Detection/test/images/
mv $BASE_PATH/VOCdevkit/VOC2007/Annotations/$img.xml $BASE_PATH/VOC_Detection/test/targets/
done
# 删除旧的 VOCdevkit/ 目录
rm -rf $BASE_PATH/VOCdevkit
echo "数据重组完成!"
exit 0
使用: ./organize_voc.sh ./data
③ 简化标注 (simplify_voc_targets.py)
为了方便后续用 pandas 等工具进行筛选,此脚本将 XML 标注文件转换为更易于程序化处理的 CSV 格式。
import os
import argparse
import xml.etree.ElementTree as Et
from tqdm import tqdm
def simplify_targets(dataset_path: str):
"""将XML目标标注文件转换为CSV,并删除原文件"""
for part in ['train', 'test']:
annot_dir = os.path.join(dataset_path, "VOC_Detection", part, "targets")
print(f"正在处理 {part} 目录...")
for annot_file in tqdm(os.listdir(annot_dir)):
if not annot_file.endswith('.xml'):
continue
xml_path = os.path.join(annot_dir, annot_file)
csv_path = xml_path.replace('.xml', '.csv')
with open(csv_path, 'w') as csv_file:
csv_file.write("object,xmin,ymin,xmax,ymax\n")
tree = Et.parse(xml_path)
for obj in tree.getroot().findall('object'):
if obj.find('difficult').text == '0':
label = obj.find('name').text
bbox = obj.find('bndbox')
line = f"{label},{bbox.find('xmin').text},{bbox.find('ymin').text},{bbox.find('xmax').text},{bbox.find('ymax').text}\n"
csv_file.write(line)
os.remove(xml_path)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="将VOC XML简化为CSV")
parser.add_argument('dataset_path', type=str, help='包含VOC_Detection的根目录')
args = parser.parse_args()
simplify_targets(args.dataset_path)
使用: python simplify_voc_targets.py ./data
④ 创建自定义子集 (toy_voc.py)
这是非常实用的一个脚本,可以从处理好的数据中,根据你指定的类别,筛选出所有包含这些类别的图片及其标注,从而创建一个小型的、用于快速实验的“玩具”数据集。
import os
import shutil
import pandas as pd
import argparse
from tqdm import tqdm
def filter_and_copy(source_dir, target_dir, classes, splits):
selected_classes = set(classes.split(","))
for split in splits:
# 创建目标目录
target_img_dir = os.path.join(target_dir, split, "images")
target_tgt_dir = os.path.join(target_dir, split, "targets")
os.makedirs(target_img_dir, exist_ok=True)
os.makedirs(target_tgt_dir, exist_ok=True)
source_tgt_dir = os.path.join(source_dir, split, "targets")
source_img_dir = os.path.join(source_dir, split, "images")
for csv_file in tqdm(os.listdir(source_tgt_dir), desc=f"筛选 {split} 集"):
if not csv_file.endswith('.csv'):
continue
df = pd.read_csv(os.path.join(source_tgt_dir, csv_file))
# 筛选出包含目标类别的行
filtered_df = df[df['object'].isin(selected_classes)]
if not filtered_df.empty:
# 复制图片
img_file = csv_file.replace(".csv", ".jpg")
shutil.copy(os.path.join(source_img_dir, img_file), target_img_dir)
# 将筛选后的标注保存到新目录
filtered_df.to_csv(os.path.join(target_tgt_dir, csv_file), index=False)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="创建VOC的微型子集")
parser.add_argument("--source_voc", required=True)
parser.add_argument("--target_voc", required=True)
parser.add_argument("--classes", required=True)
args = parser.parse_args()
filter_and_copy(args.source_voc, args.target_voc, args.classes, ["train", "test"])
print("微型数据集创建成功!")
使用: python toy_voc.py --source_voc ./data/VOC_Detection --target_voc ./data/small_voc --classes car,person,bus
7. 编写独立的 VOC 到 YOLO 转换器
这个工作流的目标更直接:编写一个独立的 Python 脚本,将一个标准的 VOC 格式数据集,完整地转换为 YOLO 格式。
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
# --- 1. 定义路径和类别 ---
voc_root = "./VOCdevkit/VOC2007" # 源VOC数据集根目录
yolo_root = "./YOLO_from_VOC" # 目标YOLO数据集目录
img_sets_path = os.path.join(voc_root, "ImageSets/Main")
img_path = os.path.join(voc_root, "JPEGImages")
ann_path = os.path.join(voc_root, "Annotations")
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
# --- 2. 坐标转换函数 ---
def convert_coords(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
# --- 3. 主转换逻辑 ---
def convert_annotations(split_name):
print(f"--- 正在转换 {split_name} ---")
# 创建目标目录
yolo_img_path = os.path.join(yolo_root, "images", split_name)
yolo_lbl_path = os.path.join(yolo_root, "labels", split_name)
os.makedirs(yolo_img_path, exist_ok=True)
os.makedirs(yolo_lbl_path, exist_ok=True)
# 读取图片ID列表
with open(os.path.join(img_sets_path, f"{split_name}.txt"), "r") as f:
ids = f.read().strip().split()
for img_id in tqdm(ids):
# 处理标签
in_file = open(os.path.join(ann_path, f"{img_id}.xml"))
out_file = open(os.path.join(yolo_lbl_path, f"{img_id}.txt"), "w")
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find("size")
w = int(size.find("width").text)
h = int(size.find("height").text)
for obj in root.iter("object"):
if obj.find("difficult").text == "1":
continue
cls = obj.find("name").text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find("bndbox")
b = (float(xmlbox.find("xmin").text), float(xmlbox.find("xmax").text),
float(xmlbox.find("ymin").text), float(xmlbox.find("ymax").text))
bb = convert_coords((w, h), b)
out_file.write(f"{cls_id} " + " ".join([f"{a:.6f}" for a in bb]) + '\n')
in_file.close()
out_file.close()
# 复制图片
shutil.copy(os.path.join(img_path, f"{img_id}.jpg"), yolo_img_path)
# --- 4. 执行转换 ---
convert_annotations("train")
convert_annotations("val")
# 如果有 test.txt 也可以转换
# convert_annotations("test")
print("VOC 到 YOLO 格式转换完成!")
二、MS COCO 数据集全面解析

MS COCO (Microsoft Common Objects in Context) 数据集由微软于 2014 年首次发布。如果说PASCAL VOC是目标检测的“Hello, World!”,那么 COCO 数据集就是现代计算机视觉领域的行业黄金标准。它以其庞大的规模、场景的多样性和丰富的标注信息,成为了衡量现代目标检测、实例分割等算法性能最重要的基准之一。
1. COCO 的核心特点
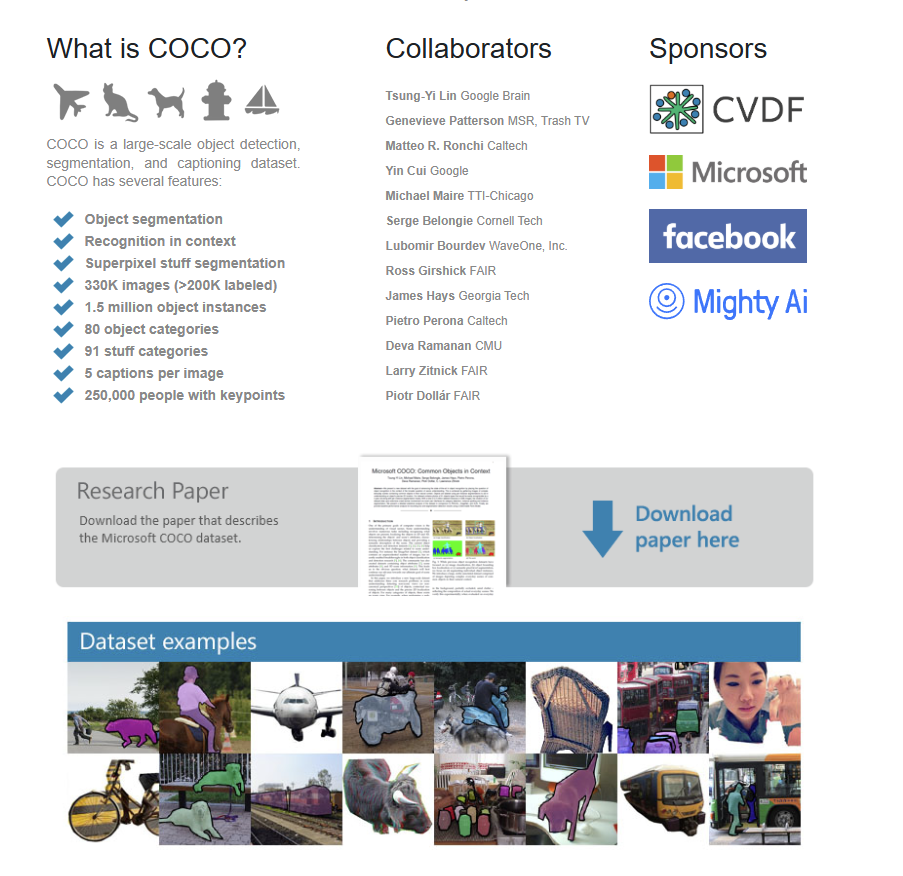
- 大规模:包含超过 33 万张图像,标注了 150 万个物体实例。
- 高多样性:图像覆盖了各种日常场景,包含复杂的物体交互和环境上下文。
- 多任务支持:同一套图像和标注支持目标检测与分割、图像描述 (Captioning)、人体关键点检测 (Keypoint Detection) 等任务。
- 丰富的标注信息:每个物体实例都带有精确的边界框、像素级的分割掩码、以及所属的类别标签。
- 挑战性:COCO 数据集包含大量的小物体、被遮挡的物体以及具有相似外观的不同类别,这使得在其上训练的模型更具鲁棒性和泛化能力。
2. COCO 的主要任务与标注类型
COCO 主要支持以下几个核心的计算机视觉任务,每种任务对应不同的标注文件:
| 任务名称 | 对应标注类型 | 标注文件 (annotations/) |
标注内容 |
|---|---|---|---|
| 目标检测与分割 | Object Instances | instances_train2017.jsoninstances_val2017.json |
每个物体实例的边界框 (x, y, width, height) 和分割掩码 (多边形或 RLE) |
| 人体关键点检测 | Person Keypoints | person_keypoints_train2017.jsonperson_keypoints_val2017.json |
每个人的17个关键点的坐标和可见性 |
| 图像描述 | Image Captions | captions_train2017.jsoncaptions_val2017.json |
每张图像的5条文本描述 |
| 全景分割 | Panoptic Segmentation | (独立的文件集) | 场景中所有物体(stuff 和 thing)的像素级分割和类别标签 |
本文后续将主要关注与目标检测最相关的 instances_*.json 文件。
3. COCO 数据集文件结构
下载并解压 COCO 2017 数据集后,你会看到如下主要的目录结构:
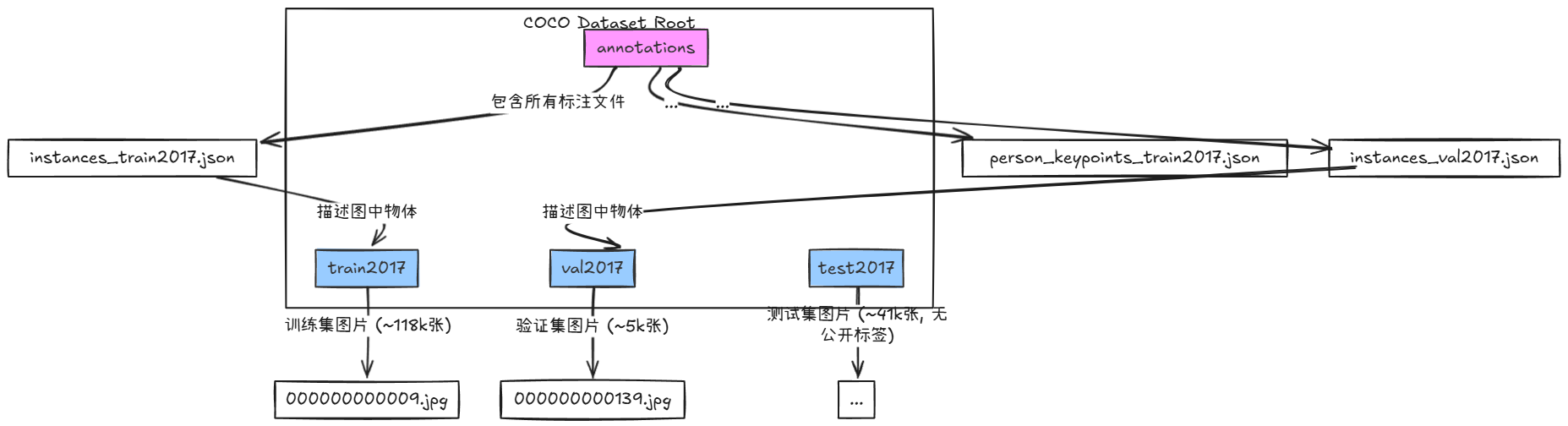
train2017/,val2017/,test2017/: 分别存放训练、验证和测试集的.jpg图像文件。annotations/: 存放所有任务的JSON格式标注文件。JSON 文件将所有标注信息集中存储,而不是像 VOC 那样为每张图创建一个单独的标注文件。
4. JSON 标注格式详解 (instances_*.json)
对于目标检测任务,instances_*.json 文件是核心。它是一个包含五个顶级键 (Key) 的大型JSON对象。
① info
记录数据集的元信息。
{
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "Microsoft COCO group",
"date_created": "2017-09-01 12:00:00"
},
...
}
② licenses
包含数据集中图像的许可信息。
{
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
...
],
...
}
③ images
一个列表,其中每个元素是一个描述单张图片信息的JSON对象。
- 关键字段:
id: 图像的唯一ID (整数)。file_name: 图像的文件名 (字符串)。width,height: 图像的宽高 (像素)。
{
"images": [
{
"license": 3,
"file_name": "000000397133.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg",
"height": 427,
"width": 640,
"date_captured": "2013-11-14 17:02:52",
"id": 397133
},
...
],
...
}
④ annotations
这是标注信息的核心,一个包含数据集中所有物体实例标注的列表。
- 关键字段:
id: 此条标注的唯一ID。image_id: 该标注所属图像的ID (关联到images列表)。category_id: 标注的类别ID (关联到categories列表)。bbox:[x_min, y_min, width, height]格式的边界框。注意:这与VOC的(xmin, ymin, xmax, ymax)不同!area: 物体实例的像素面积。iscrowd:0表示单个物体,1表示一组拥挤的物体。训练时通常会忽略iscrowd: 1的标注。segmentation: 实例分割的多边形坐标。
- 单个物体标注示例 (
iscrowd: 0):
{
"segmentation": [
[510.66, 423.01, 511.72, 420.03, 510.45, 416.0, ..., 510.66, 423.01]
],
"area": 702.10,
"iscrowd": 0,
"image_id": 289343,
"bbox": [473.07, 395.93, 38.65, 28.67],
"category_id": 18,
"id": 1768
}
⑤ categories
一个列表,定义了所有类别的信息。
- 关键字段:
id: 类别的唯一ID。注意:这个ID不一定是连续的! 例如,person的ID是1,bicycle是2,但car的ID是3,跳过了中间的数字。name: 类别名称 (如: “person”, “car”)。supercategory: 更大的类别 (如: “vehicle”, “animal”)。
{
"categories": [
{"supercategory": "person", "id": 1, "name": "person"},
{"supercategory": "vehicle", "id": 2, "name": "bicycle"},
{"supercategory": "vehicle", "id": 3, "name": "car"},
...
{"supercategory": "indoor", "id": 90, "name": "toothbrush"}
]
}
5. COCO 在 Ultralytics YOLO 中的配置 (coco.yaml)
现代框架如Ultralytics通过一个简单的 .yaml 文件即可自动化处理COCO数据集。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset: https://cocodataset.org
#
# Documentation: https://docs.ultralytics.com/datasets/detect/coco/
# Example usage: yolo train data=coco.yaml
# 1. 定义数据集根目录
path: ../datasets/coco
# 2. 定义训练、验证、测试集 (使用txt文件列表)
train: train2017.txt # 训练集图片列表 (~118k images)
val: val2017.txt # 验证集图片列表 (5k images)
test: test-dev2017.txt # 测试集列表
# 3. 定义类别名称 (80个类别)
# 这里的索引 (0-79) 是YOLO使用的class_id, 与原始COCO的category_id不同
names:
0: person
1: bicycle
2: car
3: motorcycle
# ... (为简洁起见,省略其余类别)
79: toothbrush
# 4. 自动化下载脚本
# Ultralytics会在找不到数据时自动执行此脚本
download: |
from ultralytics.utils.downloads import download
from pathlib import Path
# 数据集根目录
dir = Path(yaml['path'])
# 关键步骤:直接下载官方预转换好的YOLO格式标签!
# 这避免了在本地运行复杂的JSON到TXT的转换
urls = ['https://github.com/ultralytics/assets/releases/download/v0.0.0/coco2017labels.zip']
download(urls, dir=dir.parent, unzip=True)
# 下载原始图像文件
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G
'http://images.cocodataset.org/zips/val2017.zip', # 1G
'http://images.cocodataset.org/zips/test2017.zip'] # 7G
download(urls, dir=dir / 'images', threads=3, unzip=True)
关键要点:
与VOC.yaml在本地执行转换不同,coco.yaml的策略是直接下载Ultralytics官方已经转换好的YOLO格式标签。这是一个非常高效的优化,为用户省去了复杂的解析和转换步骤。
6. 动手实战:从零将COCO转换为YOLO格式
尽管框架提供了自动化工具,但理解转换过程对于处理自定义数据集至关重要。以下是一个完整的Python脚本,展示了如何手动将COCO的JSON标注转换为YOLO格式。
import json
import os
from tqdm import tqdm
from collections import defaultdict
def convert_coco_to_yolo(json_path, save_dir):
"""
将COCO标注文件(instances_*.json)的核心边界框信息转换为YOLO格式的标签文件。
:param json_path: COCO格式的 annotations JSON 文件路径。
:param save_dir: 转换后YOLO格式标签的保存目录。
"""
with open(json_path, 'r') as f:
data = json.load(f)
# 创建保存目录
labels_dir = os.path.join(save_dir, 'labels')
os.makedirs(labels_dir, exist_ok=True)
# 1. 创建 category_id 到 0-79 连续索引的映射
categories = data['categories']
cat_id_to_yolo_id = {cat['id']: i for i, cat in enumerate(categories)}
# 2. 创建 image_id 到图片信息的映射 (width, height, file_name)
images = {img['id']: img for img in data['images']}
# 3. 使用defaultdict来收集每个图片的所有标注
annotations_by_image = defaultdict(list)
for ann in tqdm(data['annotations'], desc="Processing annotations"):
# 忽略拥挤的标注
if ann.get('iscrowd', 0) == 1:
continue
image_id = ann['image_id']
annotations_by_image[image_id].append(ann)
# 4. 遍历所有图片,转换并写入文件
for image_id, annotations in tqdm(annotations_by_image.items(), desc="Writing YOLO files"):
img_info = images.get(image_id)
if not img_info:
continue
img_w, img_h = img_info['width'], img_info['height']
# 定义YOLO标签文件的路径
label_file_name = os.path.splitext(img_info['file_name'])[0] + '.txt'
label_file_path = os.path.join(labels_dir, label_file_name)
with open(label_file_path, 'w') as f:
for ann in annotations:
# 获取YOLO格式的类别ID
yolo_class_id = cat_id_to_yolo_id.get(ann['category_id'])
if yolo_class_id is None:
continue
# COCO的bbox: [xmin, ymin, width, height]
x_min, y_min, w, h = ann['bbox']
# 转换为YOLO格式: [class_id, x_center, y_center, width, height] (归一化)
x_center = (x_min + w / 2) / img_w
y_center = (y_min + h / 2) / img_h
norm_w = w / img_w
norm_h = h / img_h
# 写入文件,保留6位小数
f.write(f"{yolo_class_id} {x_center:.6f} {y_center:.6f} {norm_w:.6f} {norm_h:.6f}\n")
print(f"Conversion complete! YOLO labels are saved in: {labels_dir}")
# --- 使用示例 ---
if __name__ == '__main__':
# 假设你的COCO annotations文件在这里
coco_annotation_file = './annotations/instances_val2017.json'
# 定义输出目录
output_directory = './coco_to_yolo_output'
convert_coco_to_yolo(coco_annotation_file, output_directory)
- 核心逻辑:
- 加载JSON: 读取
instances_*.json文件。- 创建类别映射: COCO的
category_id不连续,必须创建一个映射,将它们转换为YOLO要求的0, 1, 2, ...的连续索引。- 创建图像信息映射: 创建一个从
image_id到图像(宽度, 高度, 文件名)的字典,方便快速查询。- 遍历所有标注: 循环处理
annotations列表中的每个对象。- 坐标转换: 对每个
bbox,执行从[x_min, y_min, width, height]到YOLO格式的[class_id, x_center, y_center, width, height](归一化) 的转换。- 写入文件: 将转换后的标注行写入与原始图片同名(但后缀为
.txt)的文件中。
总结
本文我们从零开始,系统地学习了目标检测数据集的核心知识,并亲手实践了从下载、解析到格式转换的数据处理全流程。
回顾一下,我们取得的成果:
✅ 掌握了核心数据集格式:我们彻底搞懂了PASCAL VOC的XML结构和ImageSets划分方式,深入解析了MS COCO的集中式JSON标注体系,并最终聚焦于为实战而生的YOLO .txt格式。
✅ 学会了数据转换与处理:我们学习了将VOC和COCO这两种主流格式转换为YOLO格式的两种核心方法:一种是利用 ultralytics 框架的.yaml配置文件实现一键式自动化处理,另一种是编写独立的Python脚本进行手动转换。这大大增强了我们处理不同来源数据集的灵活性。
✅ 建立了项目思维框架:我们不再仅仅是模型的使用者,更深入理解了AI项目生命周期中至关重要的数据准备阶段。为我们将来解决真实世界的计算机视觉问题,打下了坚实的基础。
希望这个“数据篇”的保姆级教程能为你打开一扇门,激发你探索更多可能性的热情。有了扎实的数据处理能力,你就可以去创造一个真正属于你自己的目标检测应用了😎🎉!
今天我们就学习到这里🏆🎉👌!
文章参考
YOLO系列官方论文:
核心数据集与代码:
- Ultralytics YOLOv8 Documentation
- YOLO Master GitHub by DataWhale
- PASCAL VOC Dataset Home
- COCO Dataset Home
拓展阅读:
- Ultralytics GitHub 仓库 (YOLOv3/v5/v8 的主流实现)
- 作者的算法专栏 - CSDN 博客 (包含更多YOLO技术文章)
💖 感谢您的耐心阅读!
如果您觉得本文对您理解和实践YOLO数据集制作有所帮助,请考虑点赞、收藏或分享给更多有需要的朋友。您的支持是我持续创作优质内容的动力!欢迎在评论区交流讨论,共同进步。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)