java8版本langchian4j对接qdrant根据元数据搜索踩坑实录
本文分享了基于Java8开发知识库项目的踩坑经验。
最近在做项目中有一个用户知识库的功能,用户可以上传markdown文件,然后后端根据markdown文档等级进行切割成文本框存入向量数据库,后面如果用户向AI询问,AI可以先通过调取向量数据库中与用户问题符合度最高的前几条投入给AI,让AI根据资料进行总结回复。
向量数据库我用的是qdrant,我的langchain4j仍然是适配java8版本的,在与向量数据库对接时候遇到了不少兼容性问题,qdrant以及langchain4j很多文档都是jdk17版本,官方文档很多找不到对应解决方案,现记录一下我的踩坑经历,文末有项目代码github链接。
先贴出我的pom.xml,注意一下版本哈!(其中qdrant依赖还和MySQL的protobuf依赖冲突了,反正坑真的不少…)
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatis-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<exclusions>
<!-- 向量数据库和MySQL坑爹的版本冲突啊!-->
<exclusion>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--Redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--redisson-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
</dependency>
<!--discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--config-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--loadbalancer-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!--langchain4j-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.29.1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.29.1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
<version>0.29.1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
<version>0.29.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!--pdfbox-->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.27</version>
</dependency>
<!--markdown-->
<dependency>
<groupId>com.vladsch.flexmark</groupId>
<artifactId>flexmark-all</artifactId>
<version>0.64.8</version>
</dependency>
</dependencies>
因为这是个微服务项目,所以父依赖我也贴出来一些
<!-- 继承 Spring Boot 父工程 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.2</version>
</parent>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<org.projectlombok.version>1.18.20</org.projectlombok.version>
<spring-cloud.version>2021.0.3</spring-cloud.version>
<spring-cloud-alibaba.version>2021.0.1.0</spring-cloud-alibaba.version>
</properties>
我在存储向量文档时候用了metadata携带用户id和文档id,便于删除、查询时根据此字段来确定文档
private void saveSegment(MarkdownDocs markdownDocs, Long userId, int level, String markdownContent) {
List<MarkdownChunk> markdownChunks = getMarkdownChunksByH(markdownContent, level);
if(markdownChunks.size()==0){
smartSplitByHeading(markdownContent);
}
for (MarkdownChunk markdownChunk : markdownChunks) {
TextSegment segment = TextSegment.from(markdownChunk.toString());
segment.metadata().put("user_id", userId);
segment.metadata().put("doc_id", markdownDocs.getId().toString());
Embedding embedding = embeddingModel.embed(segment).content();
String add = embeddingStore.add(embedding, segment);
log.info("添加成功:{}",add);
}
}
在根据用户id查询的时候我查看了相关API,并且根据文档提示,写出了
// 1. 向量化问题
Embedding queryEmbedding = embeddingModel.embed(message).content();
// 2. 查询向量数据库
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("userId").isEqualTo(37))//假定要删除37号id的
.maxResults(3)
.minScore(0.7)
.build();
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.search(request).matches();
嗯,没问题啊,metadataKey则不就摆明了吗。
但是问题就是死活删不掉,死活匹配不到。我还想了有会不会可能是userId我是Long类型,他存的是String类型不匹配什么的,但是都不行!来来回回试了好几遍!网上也没对应文档,直到我想到了查看源码看看到底他在干嘛
好家伙,我穿的request里的filter你压根没用到啊
这里在findRelevant方法和search方法来回递归,按住ctrl+alt+b即可进入findRelevant的实现方法
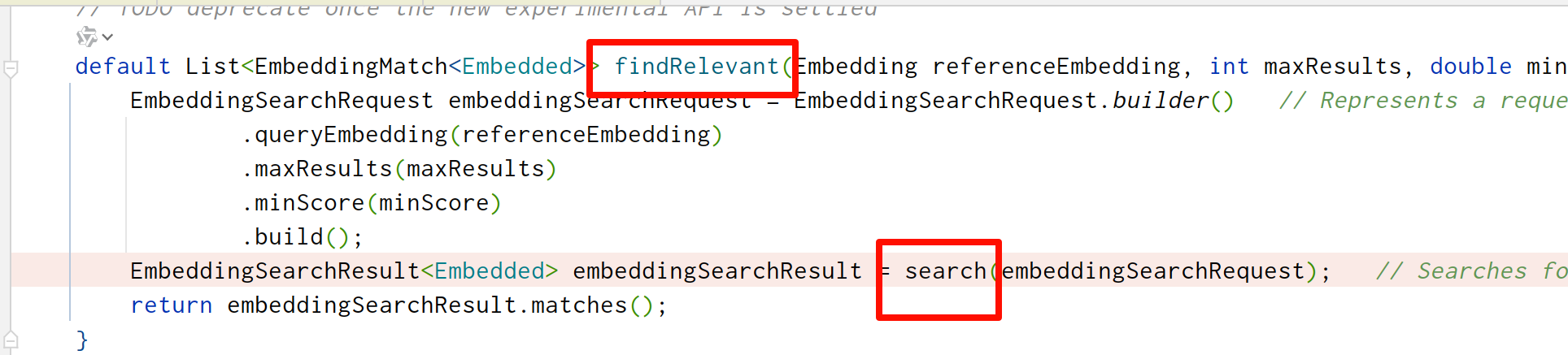
终于进入到核心代码里了,我们能看到参数已经封装进去了。很好,我们就照着你抄了
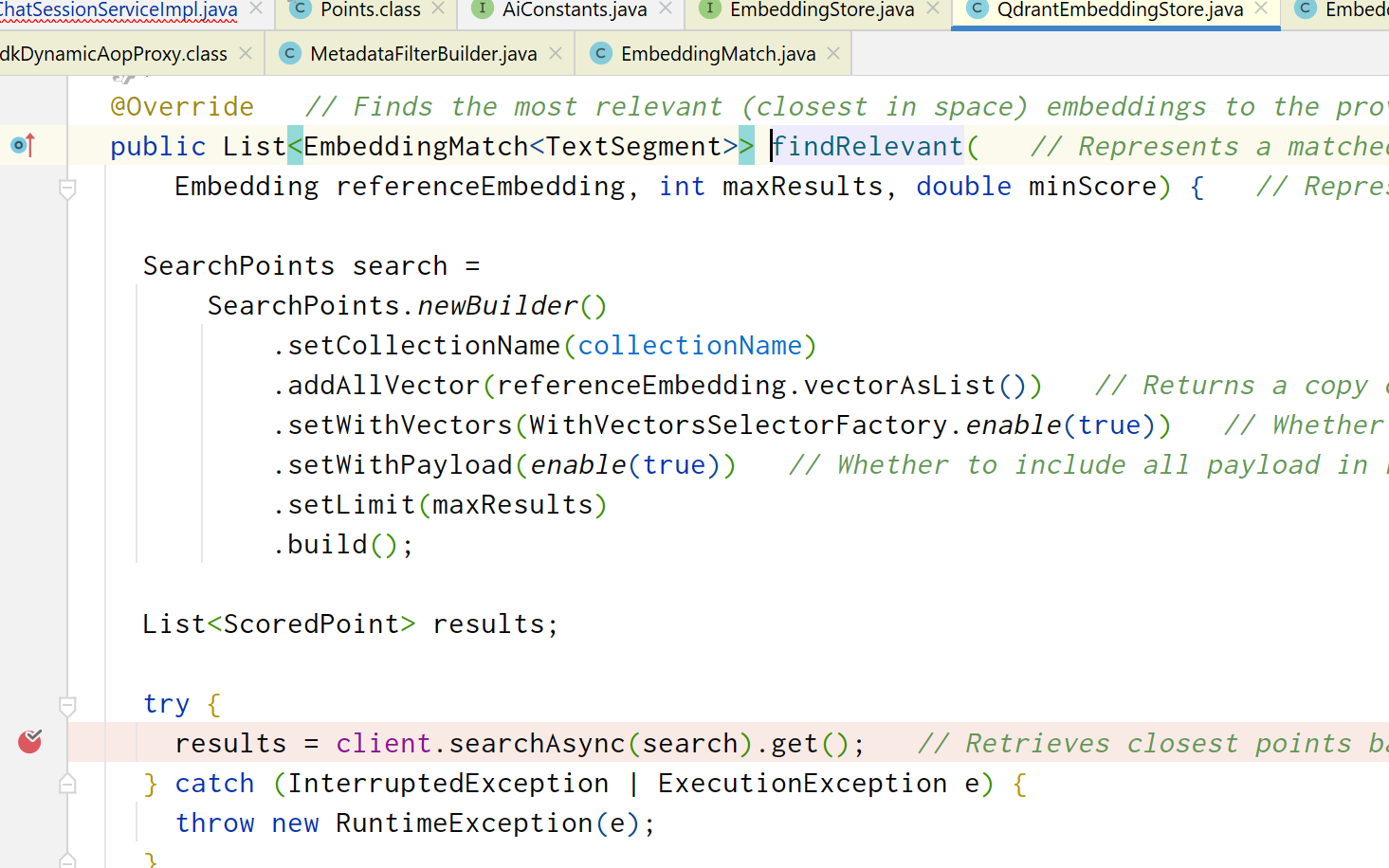
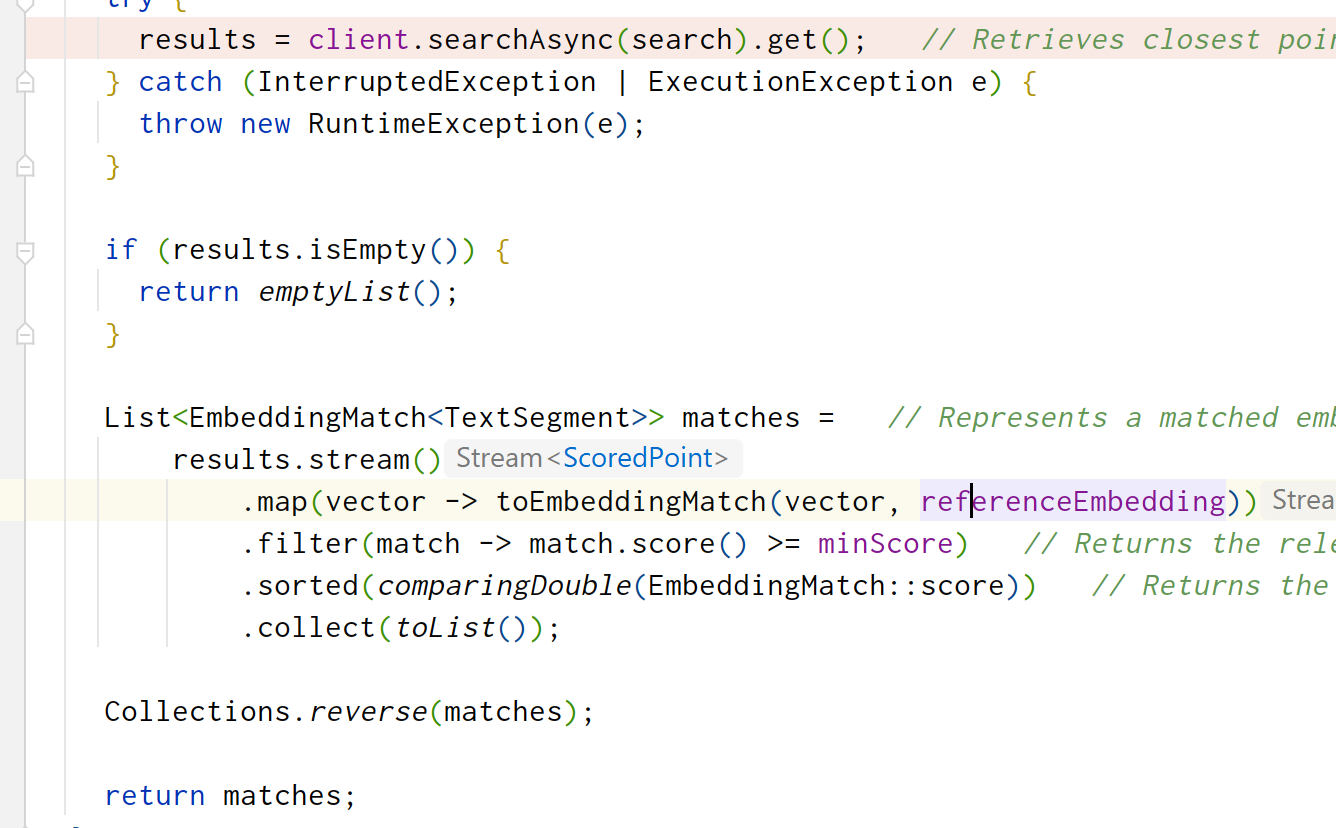
改一改,直接照着他的方法抄就行,但是我发现最后List收尾工作中的toEmbeddingMatch方法是一个私有方法!而且里面方法还不少!
我一开始想用反射去调用私有方法,但是我觉得他不太安全,于是我就把他在的对应源码文件复制给了AI让他帮我抽出一个util类,这是AI总结的util类:
package com.tianji.chat.utils;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.CosineSimilarity;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.RelevanceScore;
import io.qdrant.client.grpc.JsonWithInt;
import io.qdrant.client.grpc.Points;
import java.util.Map;
import java.util.stream.Collectors;
public class QdrantEmbeddingUtils {
public static EmbeddingMatch<TextSegment> toEmbeddingMatch(
Points.ScoredPoint scoredPoint,
Embedding referenceEmbedding,
String payloadTextKey
) {
Map<String, JsonWithInt.Value> payload = scoredPoint.getPayloadMap();
JsonWithInt.Value textSegmentValue = payload.getOrDefault(payloadTextKey, null);
Map<String, String> metadata = payload.entrySet().stream()
.filter(entry -> !entry.getKey().equals(payloadTextKey))
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue().getStringValue()
));
Embedding embedding = Embedding.from(scoredPoint.getVectors().getVector().getDataList());
double cosineSimilarity = CosineSimilarity.between(embedding, referenceEmbedding);
return new EmbeddingMatch<>(
RelevanceScore.fromCosineSimilarity(cosineSimilarity),
scoredPoint.getId().getUuid(),
embedding,
textSegmentValue == null
? null
: TextSegment.from(textSegmentValue.getStringValue(), new Metadata(metadata))
);
}
}
很好,那就完善一下我们的方法。
// 1. 向量化问题
Embedding queryEmbedding = embeddingModel.embed(message).content();
// 2. 查询向量数据库
Points.Filter filter = Points.Filter.newBuilder().addMust(matchKeyword("user_id", userId.toString())).build();
List<Points.ScoredPoint> results = qdrantClient.searchAsync(Points.SearchPoints.newBuilder()
.setCollectionName(QDRANT_COLLECTION)
.addAllVector(queryEmbedding.vectorAsList())
.setLimit(3)
.setWithPayload(enable(true))
.setWithVectors(WithVectorsSelectorFactory.enable(true))
.setFilter(filter)
.build()).get();
List<EmbeddingMatch<TextSegment>> matches = results.stream()
.map(point -> QdrantEmbeddingUtils.toEmbeddingMatch(point, queryEmbedding, "text_segment"))
.collect(Collectors.toList());
项目启动,然后进行测试,成功,的确他能筛选到我们的知识库内容。(这两张图是不同的两个用户的对比,第一张图用户没有知识库,第二张图用户有知识库)

解决完不得不感叹一句,自己踩坑时多抓狂,不过解决完问题能学到很多新东西,在解决这个棘手问题中也能“被迫”去看文档、源码,能了解底层原理实现,也许这就是学习的乐趣吧。
参考官方文章:Query points | Qdrant | API Reference
项目代码:https://github.com/finch04/online-mooc ,在这里面的tj-chat模块中的com/tianji/chat/service/impl/MarkdownDocsServiceImpl.java里的chatByMarkdownDoc方法。
欢迎给项目点star哦~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)