超详细配置YOLOv8教程(毕设必看)(训练自己数据集)(Pycharm保姆级安装教程)(lablme的使用)(GPU版)
本篇文章从最基础的标注数据集开始教学,直到最终成功调用GPU训练本人标注数据集,整个过程超级详细,基本都可以成功复现,同时也希望能对大家有所启发。
目录
1.Pycharm的安装和虚拟环境调用(已经安装好的可以跳过此步骤)
1.1 下载pycharm软件
1.2 调用已创建虚拟环境(调用上一篇教程中创建好的虚拟环境)
2.标注自己数据集(已有数据集的这部分可跳过)
2.1配置标注软件labelme
2.2 标注自己数据集
2.3 制作自己数据集
- 用YOLOv8训练自己数据集
3.1 部署YOLOv8代码
3.2 训练自己数据集
3.3 推理数据集
- 总结
————————————————
文章主要详细介绍如何标注自己数据集,然后从0开始利用YOLOv8训练自己数据集,推理数据集等,本文的相关torch环境主要基于上一篇文章,如果还没配置torch环境的可以阅读上篇文章配置。
1.Pycharm的安装和虚拟环境调用(已经安装好的可以跳过此步骤)
1.1 下载pycharm软件
大家直接进入pycharm官网下载:Pycharm官网下载
大家进入官网后记得选择和自己相关系统的版本,然后我这边用的是专业版(Professional),专业版前30天是免费的,后续要收费(如果大家是在读学生的话可以申请自己学校的教育邮箱,然后教育邮箱可以免费使用Pycharm专业版),不过社区版也是可以的
压缩包下载好之后,大家下载好之后直接双击运行安装程序即可
下一步
设置好自己的安装路径,然后点击下一步
在这一步的时候,我推荐是把这几个都选中,特别是添加将文件夹打开为项目,本人觉得还是很好用的,都选择完毕后点击下一步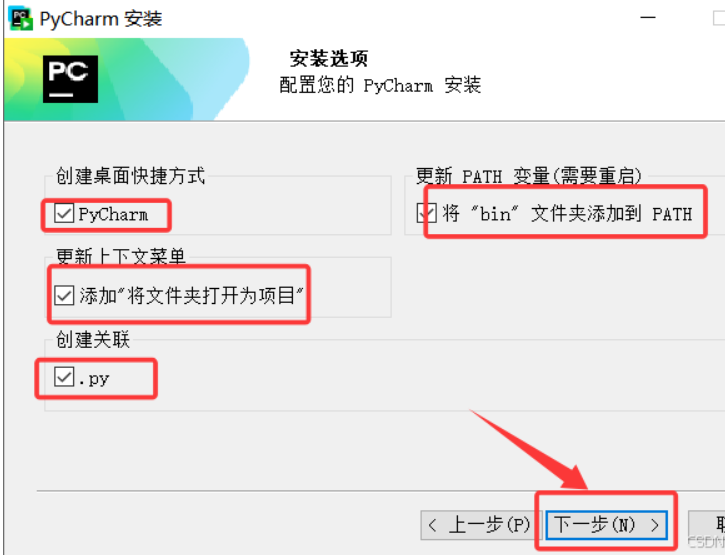
然后继续点击下一步
点击安装,最后成功安装就可以了,安装完成后桌面上就会有pycharm界面了,大家可以先创建一个文件夹(文件夹名称不要带中文),然后将该文件夹在pychram打开
打开后就是以下页面
1.2 调用已创建虚拟环境(调用上一篇教程中创建好的虚拟环境)
首先,点击右下角的这个环境配置器部分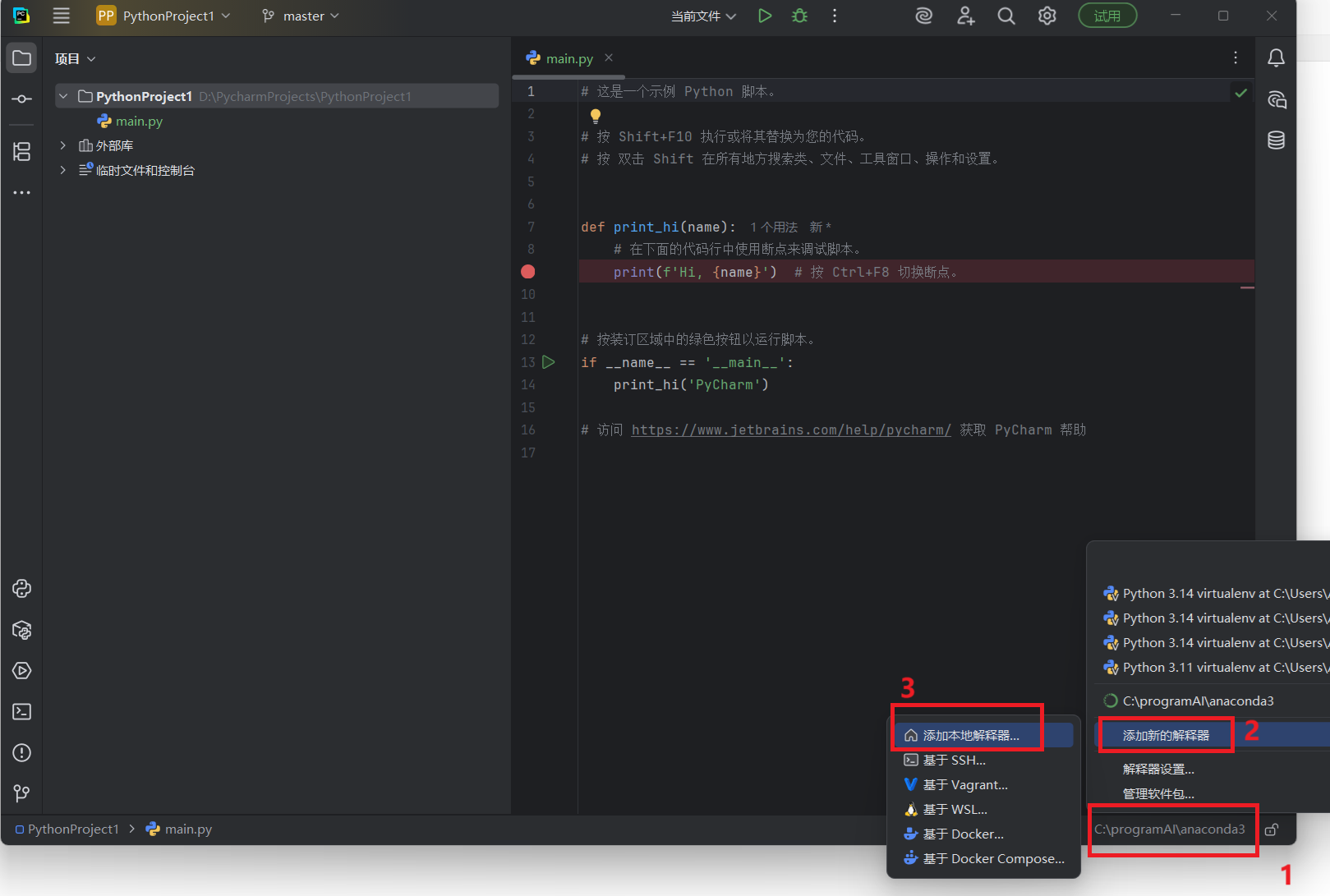
大家打开之后,依次进行选择现有,conda,然后环境的下拉键,就可以显示出自己所建的虚拟环境,大家选择自己在上一篇教程中建立的虚拟环境,然后点击确定就可以进入所建环境了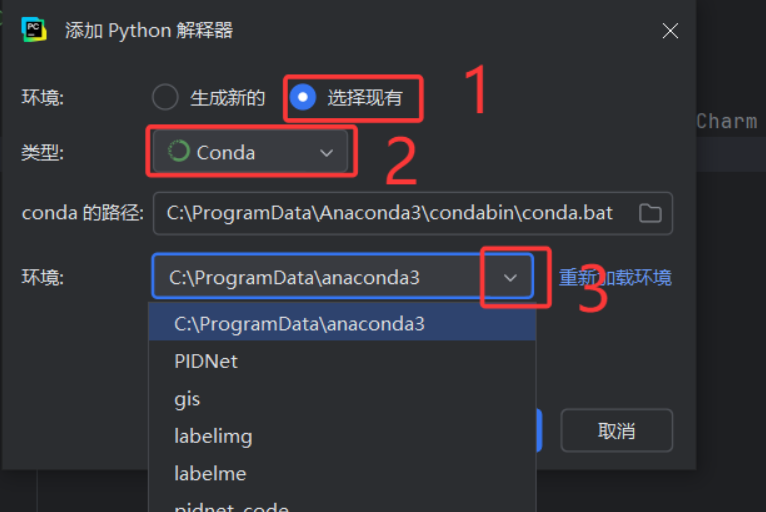 选择确认之后,右下角出现自己所选择环境名称后,则表示成功进入虚拟环境(我的虚拟环境名称是yolov8)
选择确认之后,右下角出现自己所选择环境名称后,则表示成功进入虚拟环境(我的虚拟环境名称是yolov8)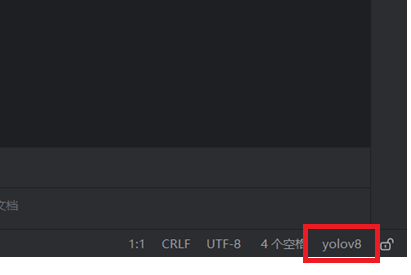
2.标注自己数据集(已有数据集的这部分可跳过)
2.1配置标注软件labelme
点击 Windows 开始菜单(左下角的 Windows 图标)。
在搜索栏中输入 Anaconda Prompt ,选择对应的应用程序图标打开anaconda的终端,依次输入以下指令,即可创建一个名为labelme的标注环境
先搜索一下安装的Python版本号
python -V
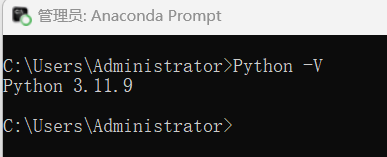
搜到Python的版本号为3.11.9
再输入以下指令创建一个名为labelme的标注环境
conda create -n labelme python=3.11.9
然后输入y ,回车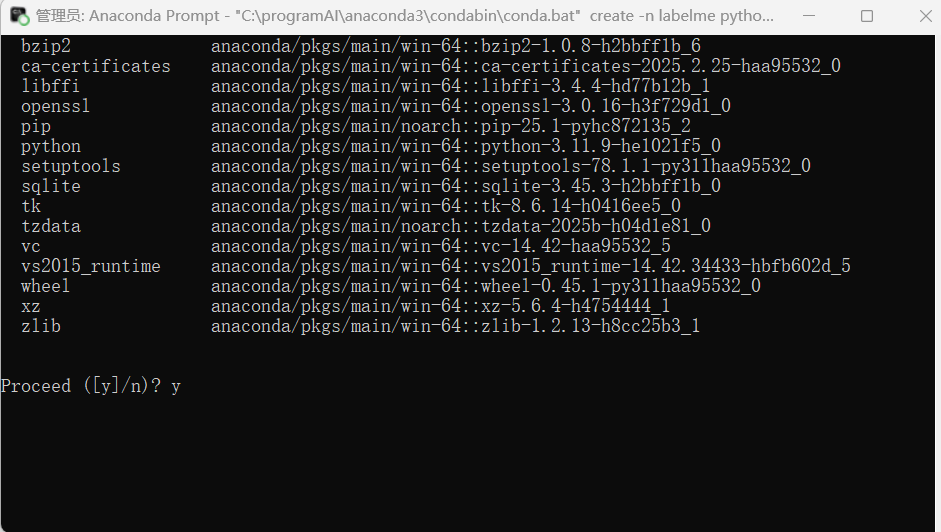
紧接着输入以下指令激活环境
conda activate labelme
输出下面这样则表述环境创建并激活成功
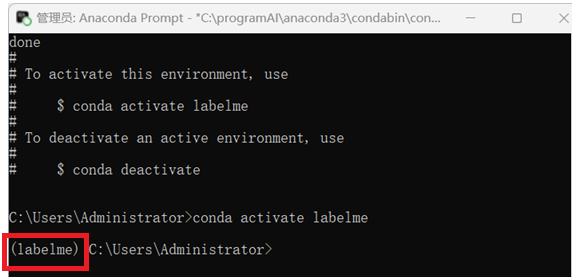
然后执行以下指令,安装标注软件
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple
这个的配置有时候加镜像也会很慢,会容易报错,大家多试几次,直到配置成功就行
出现以下界面就表示配置成功
然后就在当前界面输入以下指令,然后自动跳转至标注界面
labelme
出现下面这个界面表明已经打开了标注软件
2.2 标注自己数据集
紧接着我们开始标注自己的数据集,首先我们点击打开目录,然后将自己存放图片的文件夹打开(最好是路径和文件夹都不要带中文),具体操作步骤如下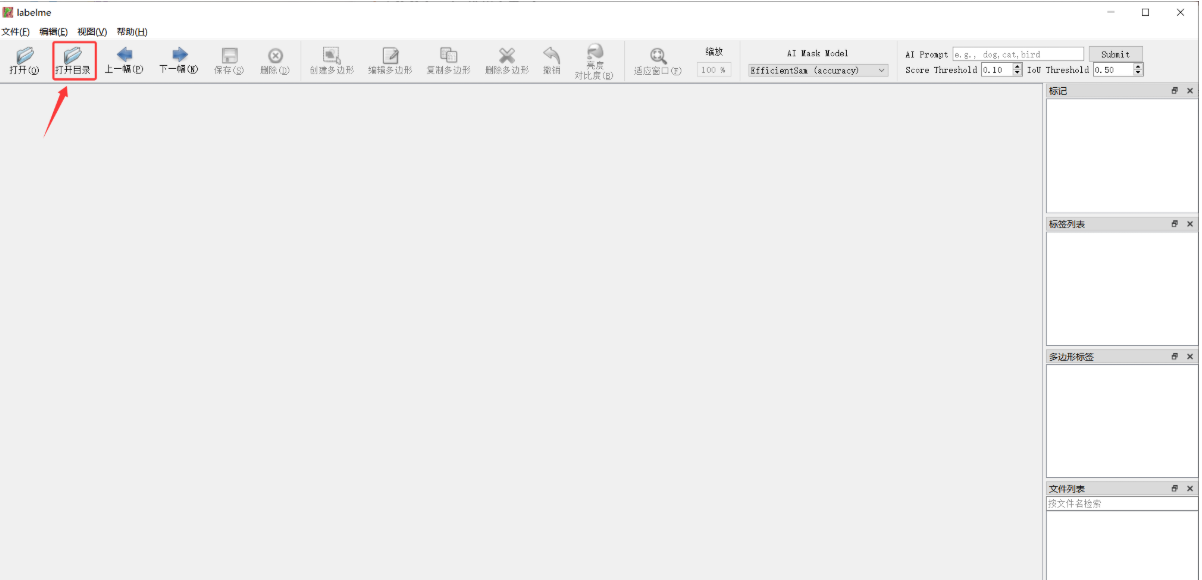
选择好自己的图片所在文件夹路径之后点击下面的选择文件夹即可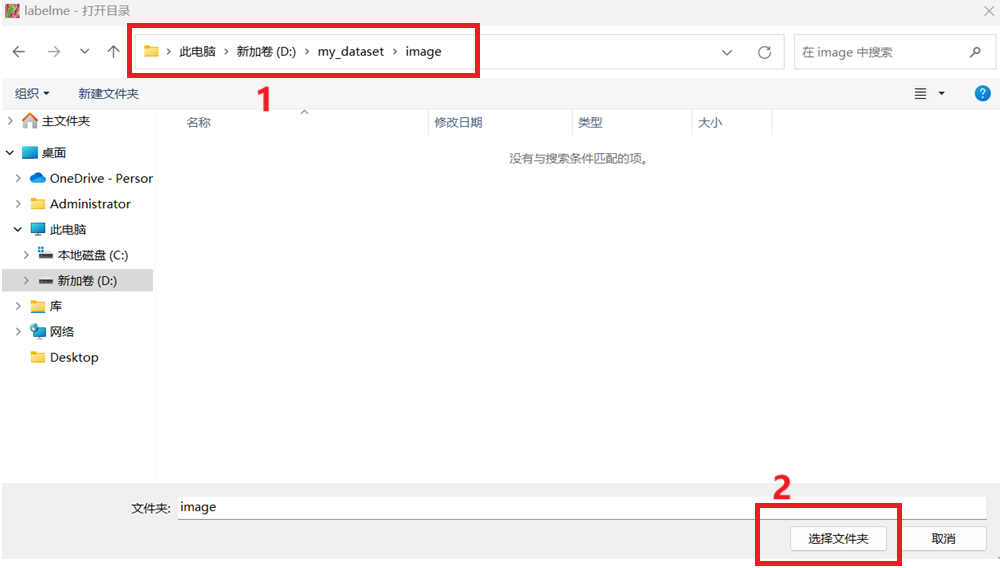
点击之后文件夹内图片就会导入labelme标注软件,然后右下方会显示已导入图片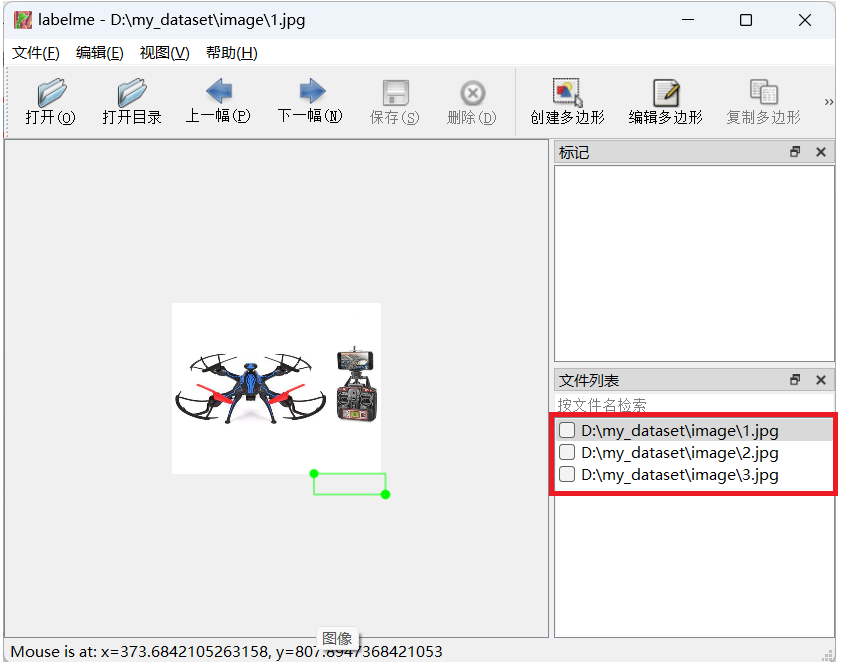
接下来大家可以点击上方的编辑,选择创建矩形,然后大家就可以利用这个矩形框对相应目标进行框选标注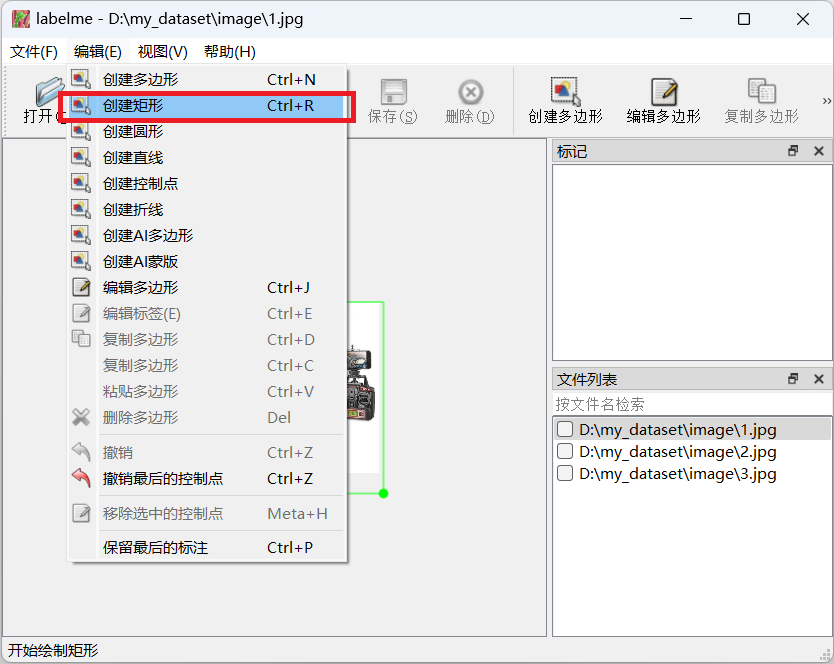
大家框选完自己想标注的目标之后,就可以给目标定义一个名称,然后点击ok即可保存,下面是我标注了人(Drone)这个目标的示例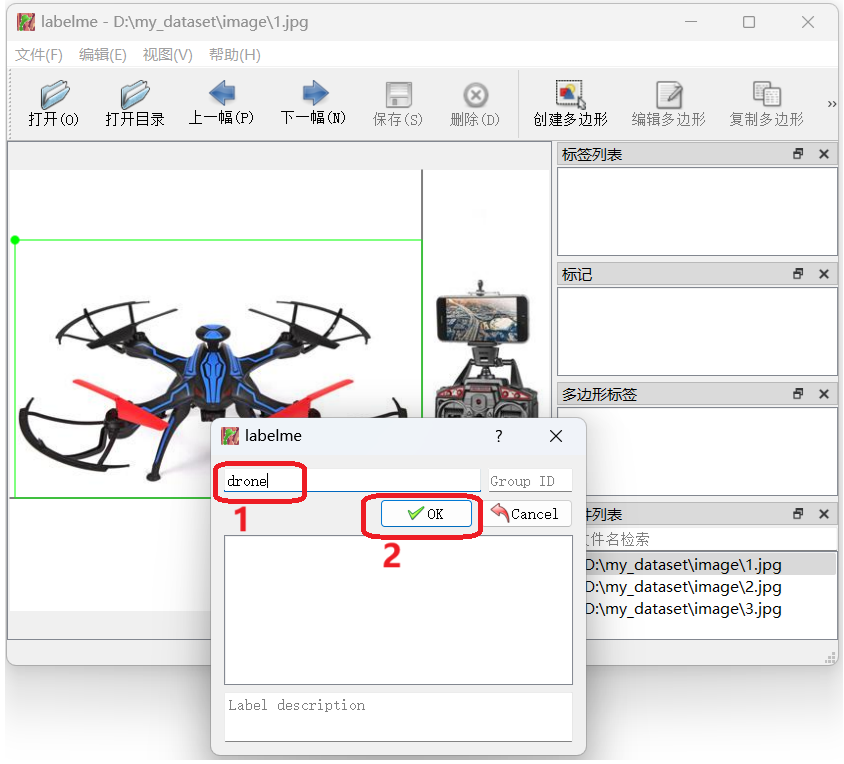
下面是我标注的所有目标,然后右边会显示标注的数量和目标名称,大家标注不同目标的话,只需定义不同目标名称即可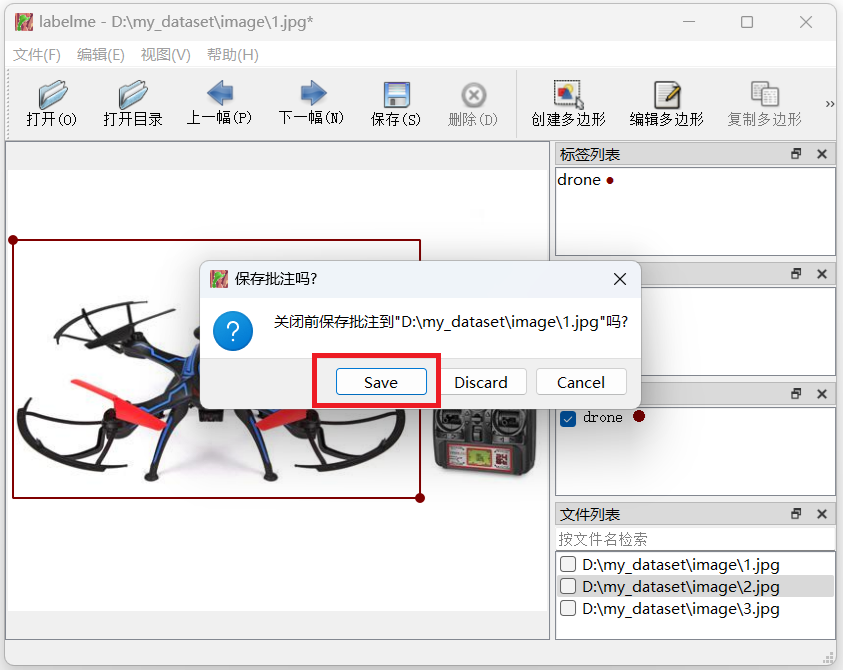
点击下一张后会在右下角显示是否已经标注且保存,已保存会有对号,大家可以检查一下,然后第二张、第三张的标注和第一张同理,后面的都按照这个方法标注保存即可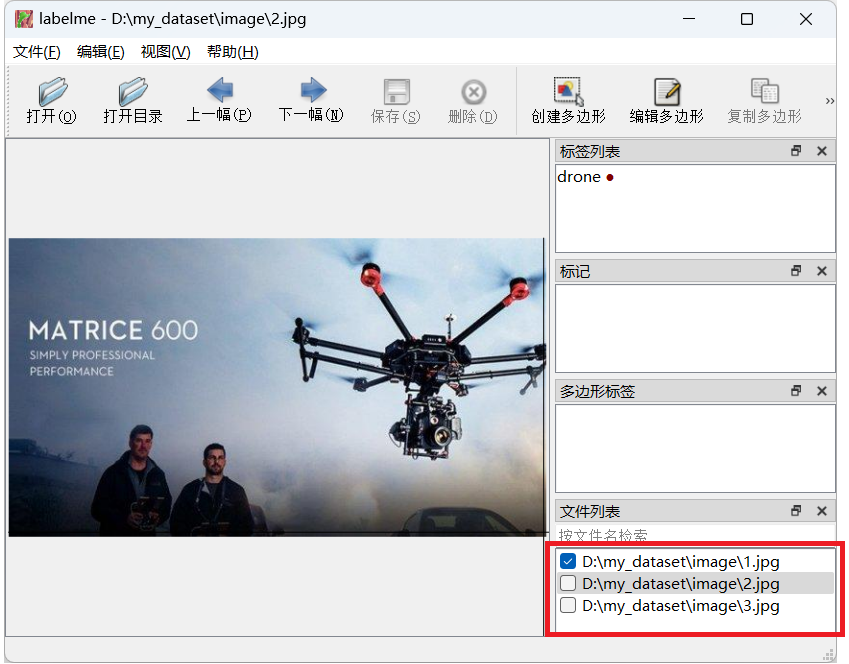
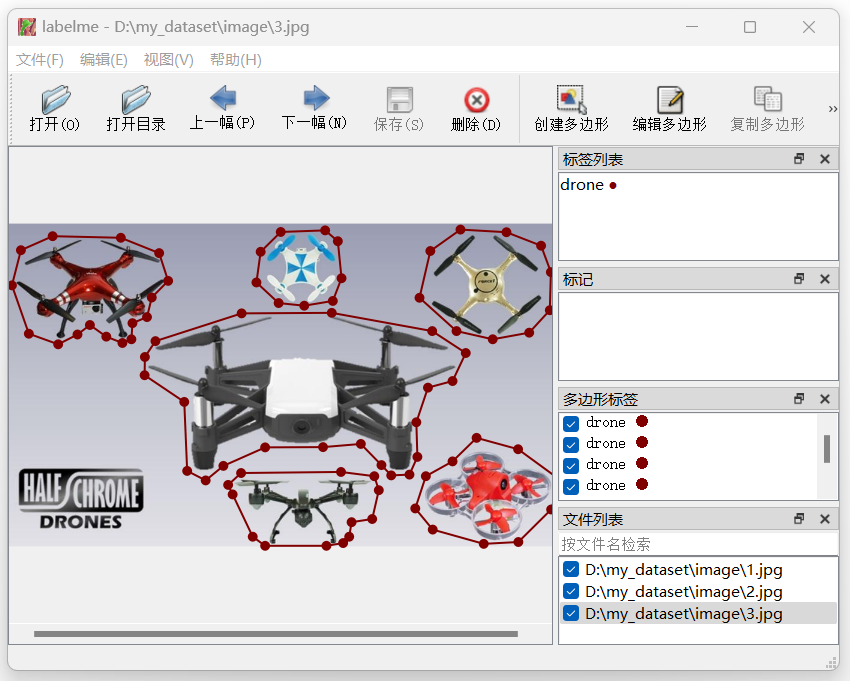
将自己数据集全部标注完成之后,会得到以下的内容,分别是图片和与其名称对应的.json标注文件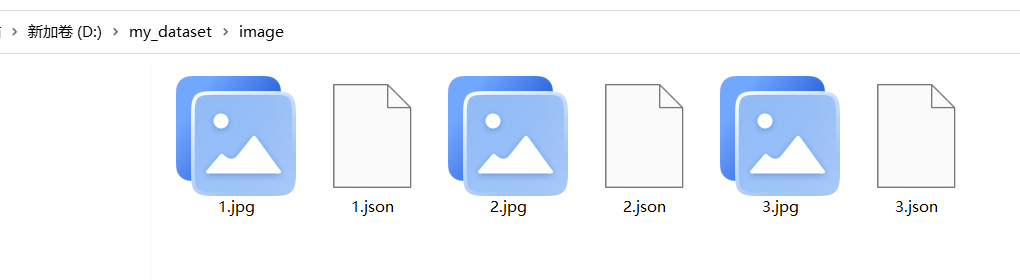
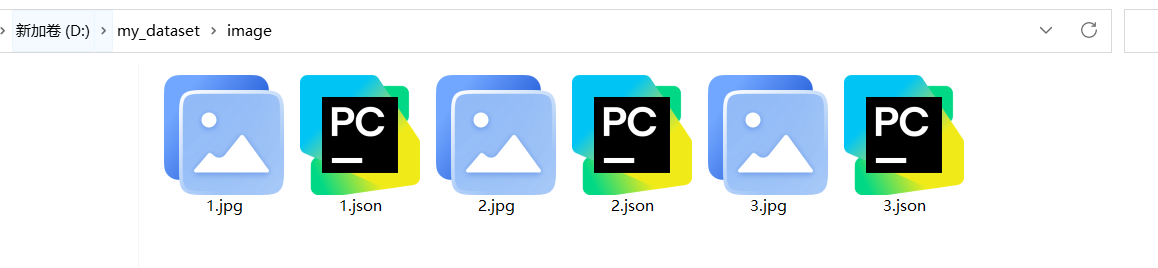
然后我们需要利用一个转换脚本代码,将这个.json文件转换为yolo格式的.txt文件
首先,我们在第一步的文件夹内右键点击建立一个新的.py格式文件, 自定义好,py文件的名称后回车就可以新建一个名为drone_to_txt的py文件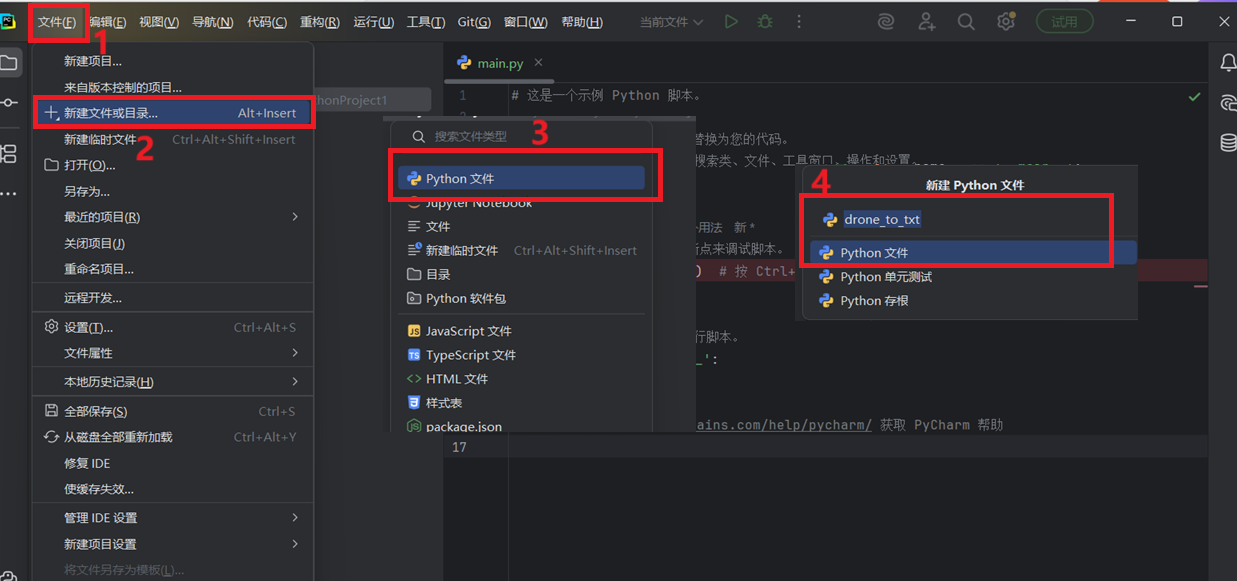
将以下转换代码粘贴到该文件
import json
import os
from tqdm import tqdm
def convert_label(drone_dir, save_dir, classes):
# 确保保存目录存在
os.makedirs(save_dir, exist_ok=True)
# 支持的编码列表
encodings = ['utf-8', 'utf-16', 'gbk', 'latin-1']
class_list = classes.split(',')
for filename in tqdm(os.listdir(drone_dir)):
# 只处理 JSON 文件
if not filename.lower().endswith('.json'):
continue
json_path = os.path.join(drone_dir, filename)
json_data = None
# 尝试多种编码解析 JSON
for encoding in encodings:
try:
with open(json_path, 'r', encoding=encoding) as f:
json_data = json.load(f)
break
except (UnicodeDecodeError, json.JSONDecodeError):
continue
# 如果无法解析,跳过当前文件
if json_data is None:
print(f"警告: 无法解析文件 {filename},跳过")
continue
# 获取图像尺寸
try:
img_height = json_data['imageHeight']
img_width = json_data['imageWidth']
except KeyError:
print(f"警告: 文件 {filename} 缺少尺寸信息,跳过")
continue
# 构建输出文件路径
base_name = os.path.splitext(filename)[0]
txt_path = os.path.join(save_dir, f"{base_name}.txt")
# 写入 YOLO 格式标签
with open(txt_path, 'w', encoding='utf-8') as txt_file:
for shape in json_data.get('shapes', []):
try:
label = shape['label']
label_id = class_list.index(label)
# 归一化坐标
normalized_points = []
for x, y in shape['points']:
normalized_points.extend([x / img_width, y / img_height])
# 写入一行标签
point_str = ' '.join(map(lambda p: f"{p:.6f}", normalized_points))
txt_file.write(f"{label_id} {point_str}\n")
except (KeyError, ValueError, IndexError) as e:
print(f"警告: 处理文件 {filename} 时出错: {e}")
if __name__ == "__main__":
drone_dir = r'D:\my_dataset\drone'
save_dir = r'D:\my_dataset\txt'
classes = 'drone'
convert_label(drone_dir, save_dir, classes)
然后将最下面的路径根据我的提示进行修改,并且将classes改为自己标注目标的名称即可(ps:json文件夹中只能有.json文件),运行代码后就会在保存路径中生成.txt文件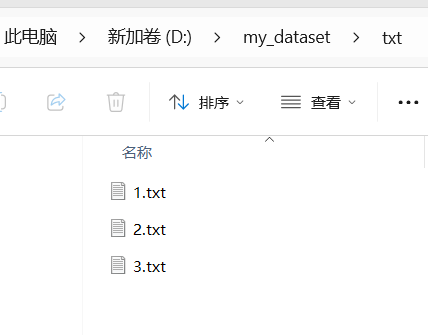
2.3 制作自己数据集
大家把自己的图片数据和txt数据分别放在两个不同文件夹内进行归类,然后再新建一个py代码,复制粘贴下面这些代码后,在最下面根据我的提示更改路径,然后运行(这个代码的主要功能是对训练集,验证集和测试集按照比例进行随机划分)
import shutil
import random
import os
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def split(image_dir, txt_dir, save_dir):
# 创建一级目录
train_dir = os.path.join(save_dir, 'train')
val_dir = os.path.join(save_dir, 'valid')
test_dir = os.path.join(save_dir, 'test')
# 创建二级目录
train_images_dir = os.path.join(train_dir, 'images')
train_labels_dir = os.path.join(train_dir, 'labels')
val_images_dir = os.path.join(val_dir, 'images')
val_labels_dir = os.path.join(val_dir, 'labels')
test_images_dir = os.path.join(test_dir, 'images')
test_labels_dir = os.path.join(test_dir, 'labels')
# 创建所有需要的文件夹
mkdir(train_dir)
mkdir(val_dir)
mkdir(test_dir)
mkdir(train_images_dir)
mkdir(train_labels_dir)
mkdir(val_images_dir)
mkdir(val_labels_dir)
mkdir(test_images_dir)
mkdir(test_labels_dir)
# 数据集划分比例,训练集75%,验证集15%,测试集10%,按需修改
train_percent = 0.75
val_percent = 0.15
test_percent = 0.10
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(train_images_dir, name + '.jpg')
dst_train_Label = os.path.join(train_labels_dir, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(val_images_dir, name + '.jpg')
dst_val_Label = os.path.join(val_labels_dir, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(test_images_dir, name + '.jpg')
dst_test_Label = os.path.join(test_labels_dir, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
image_dir = r'D:\my_dataset\image' ####图片文件夹路径
txt_dir = r'D:\my_dataset\txt' ####txt文件夹路径
save_dir = r'D:\my_dataset\dataset' ####划分后的保存路径
split(image_dir, txt_dir, save_dir)
运行代码后,会按照规定文件夹格式对图片和标签进行存放,格式如下
dataset/
├── train/
│ ├── images/
│ └── labels/
├── valid/
│ ├── images/
│ └── labels/
└── test/
├── images/
└── labels/
3. 用YOLOv8训练自己数据集
3.1 部署YOLOv8代码
大家可以去YOLOv8的官网去下载代码包(尽量利用我的链接下载,我在链接中已经选好版本了,最新版本也可以用,但是有可能会因为python版本报错)
yolov8官方下载链接
大家打不开官网的也可以用csdn链接下载 yolov8
进入链接后,依次点击code和下载安装包进行下载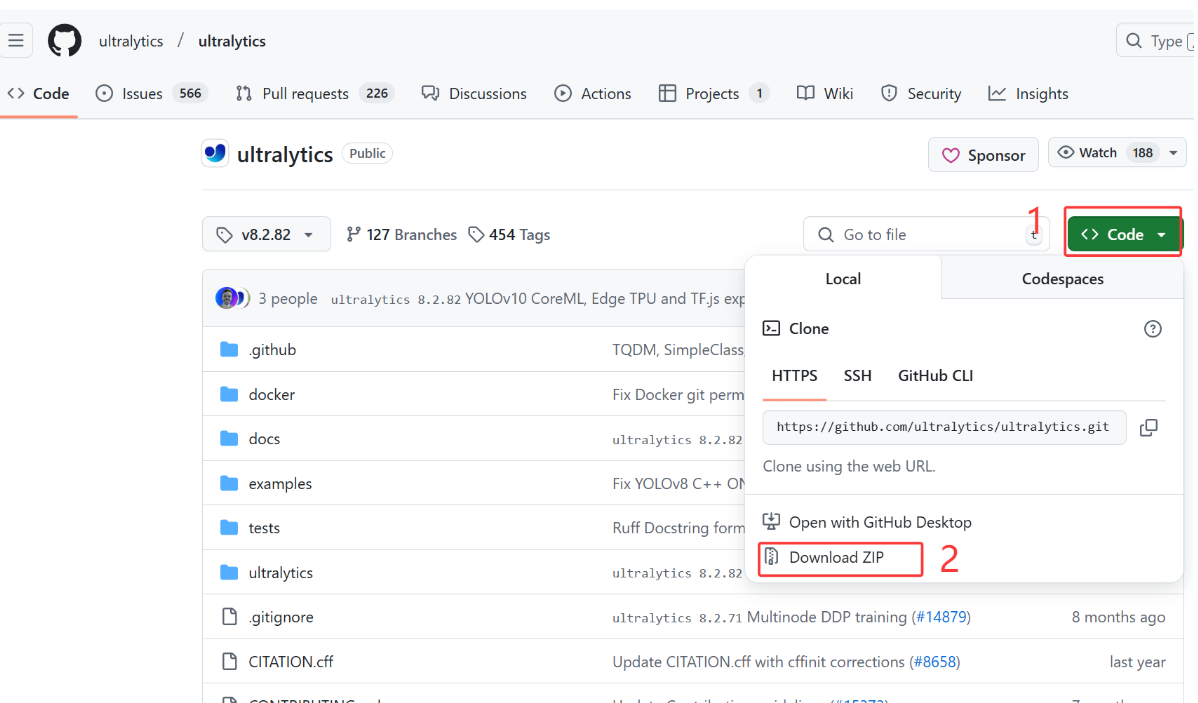 下载好之后解压,然后将解压文件在pycharm中打开,打开后是这样
下载好之后解压,然后将解压文件在pycharm中打开,打开后是这样
打开后继续新建一个训练的drone_training.py文件脚本,以后大家就可以利用这个脚本去训练
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
# 断点续训
#Load a model
#model =#YOLO(r'E:\anzhi\car\3\ultralytics-8.2.82\runs\detect\train27\weights\last.pt') # load a partially trained model
if __name__ == '__main__':
#results = model.train(data=r'E:\anzhi\car\ultralytics\my.yaml', batch=80, epochs=10000, imgsz=640, resume=True,
#workers=8, device=0)
results = model.train(data=r'E:\anzhi\car\3\ultralytics-8.2.82\train.yaml',batch=40,close_mosaic=0,epochs=1000,imgsz=640,resume=True,workers=8,device=1)
然后大家将右下角的环境切换到之前配置的有yolov8包的环境
 打开项目的终端,在终端输入以下命令配置yolov8所需包(一定要确定是在该环境内)
打开项目的终端,在终端输入以下命令配置yolov8所需包(一定要确定是在该环境内)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple

这个里面需要配置的包有点多,大家一定要确定完全配置好了再进行下一步,出现以下界面表示配置成功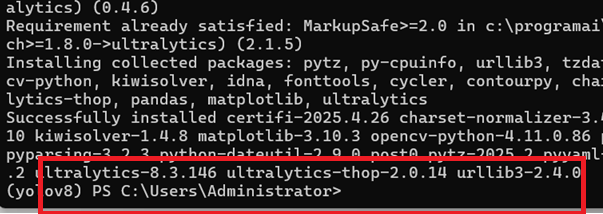
3.2 训练自己数据集
大家依次点击ultralytics—cfg–datasets–voc.yaml, 打开之后是以下页面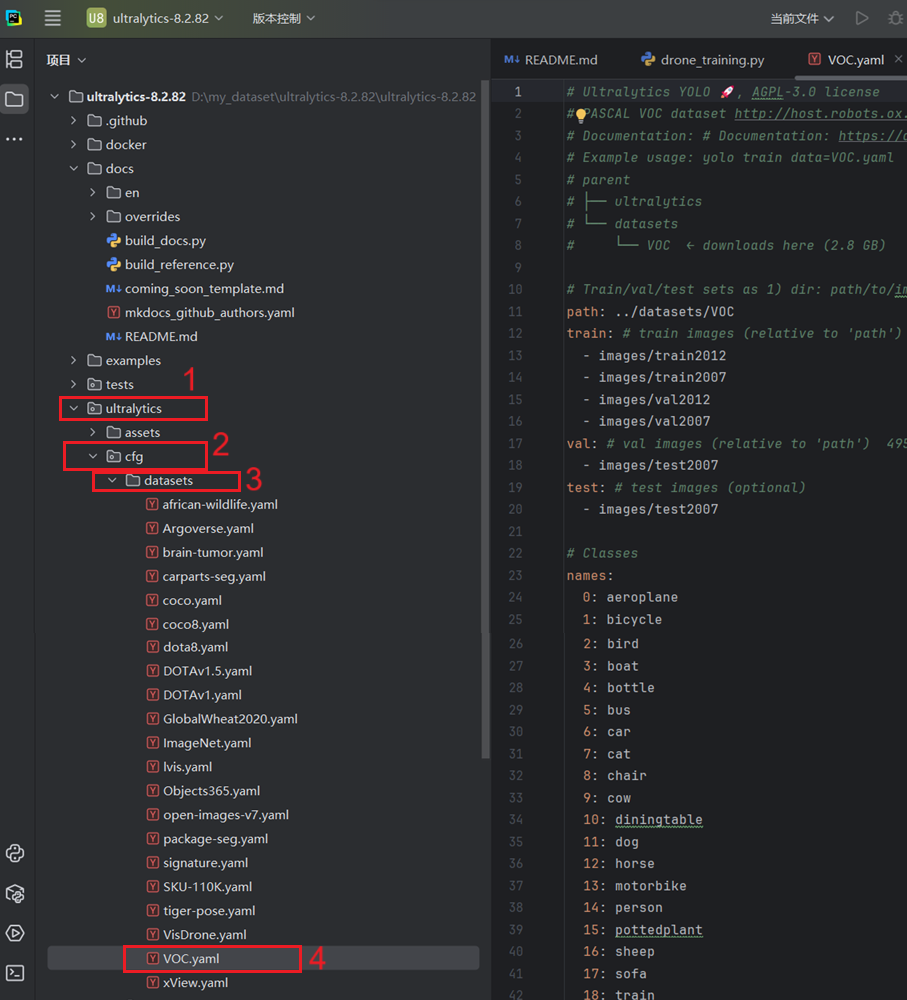
接下来将其中的内容全部替换为以下内容,其中,上面三个都替换为之间建好数据集的训练、验证和测试集的路径,然后names下面将自己标注的目标个数和名称进行替换,如果只有一个目标那就只留下0,有多的就自己加上,切记,目标的名称也得修改(我这个是从voc数据集中截取了一部分,所有就有这些类别)
train: D:\my_dataset\voc\train # train images (relative to 'path') 128 images
val: D:\my_dataset\voc\valid # val images (relative to 'path') 128 images
test: D:\my_dataset\voc\test
# Classes
names:
0: drone
然后在上面找到该yaml文件右键复制该文件绝对路径
点击这个绝对路径就可以直接复制成功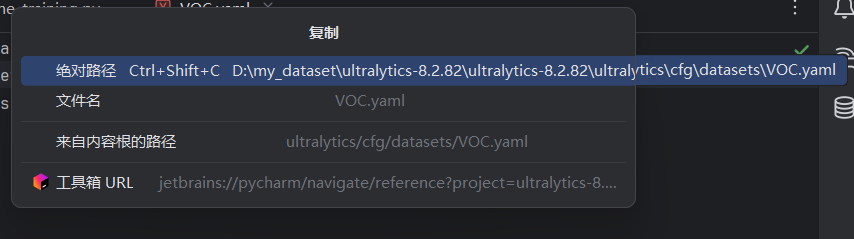
复制成功后将该路径粘贴到我们之间创建的drone_training.py脚本中,就是以下位置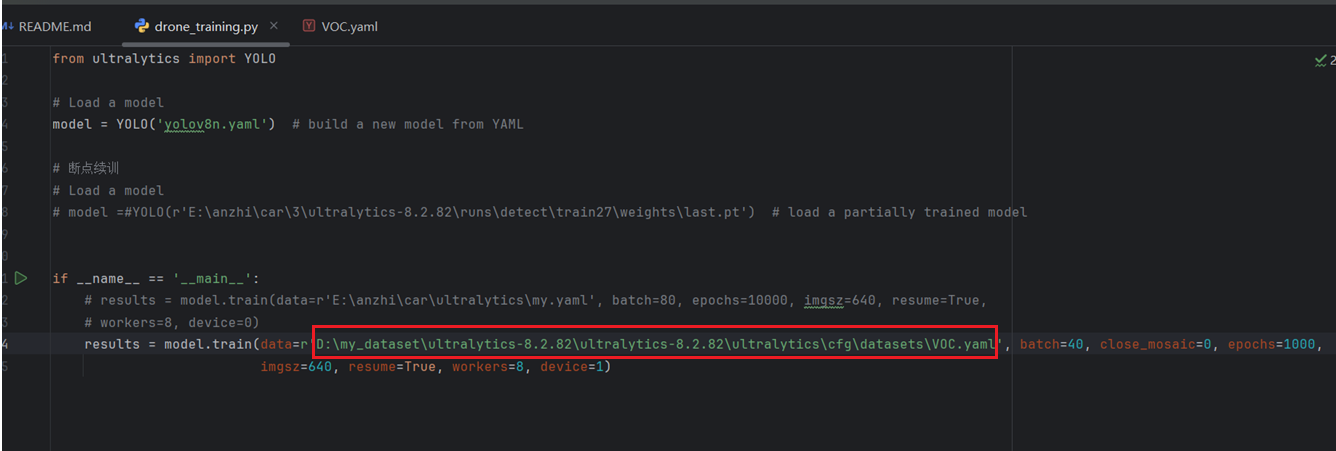
后面的指令可以先修改成我这样,这里面的batch表示批次数,epochs表示训练的轮次,resume表示是否打开中断续训,workers表示线程数,大家先按照我这个设置,等能跑起来没问题之后再自己调参数训练
batch=-1,epochs=10,imgsz=640,resume=True,workers=8
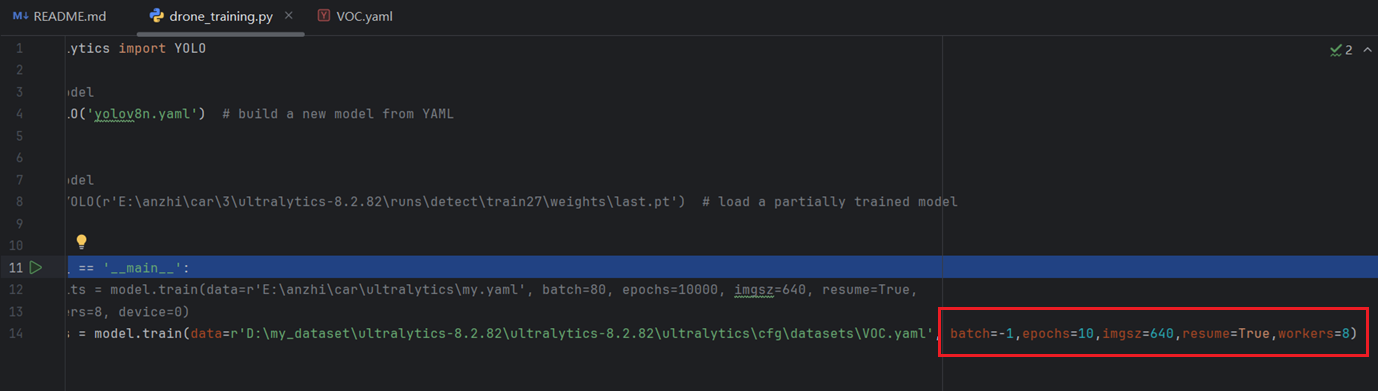
全部修改完成后,在该页面右键直接运行这个python文件即可
出现下面页面表示配置成功,已经开始调用gpu训练了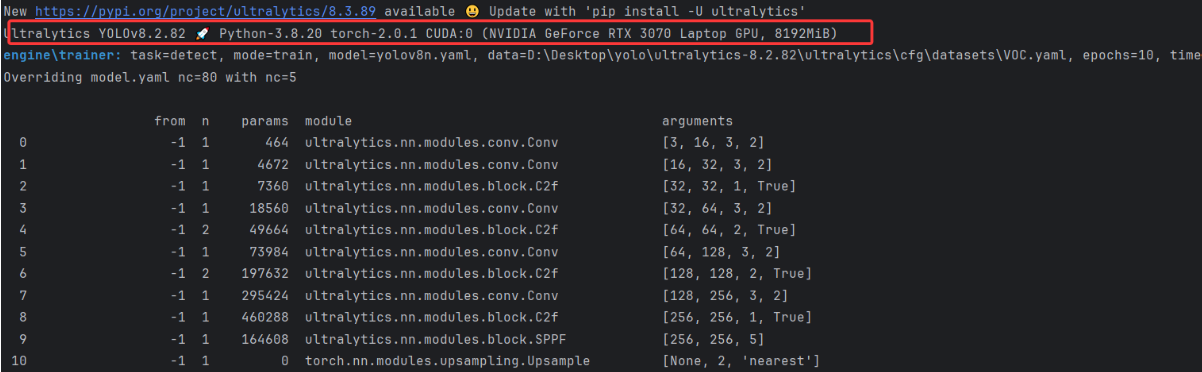
已经开始调用GPU了,速度还是比较快的(然后可以看到,我的训练集共有1012张,验证集有347张,GPU显卡调用了3.6G)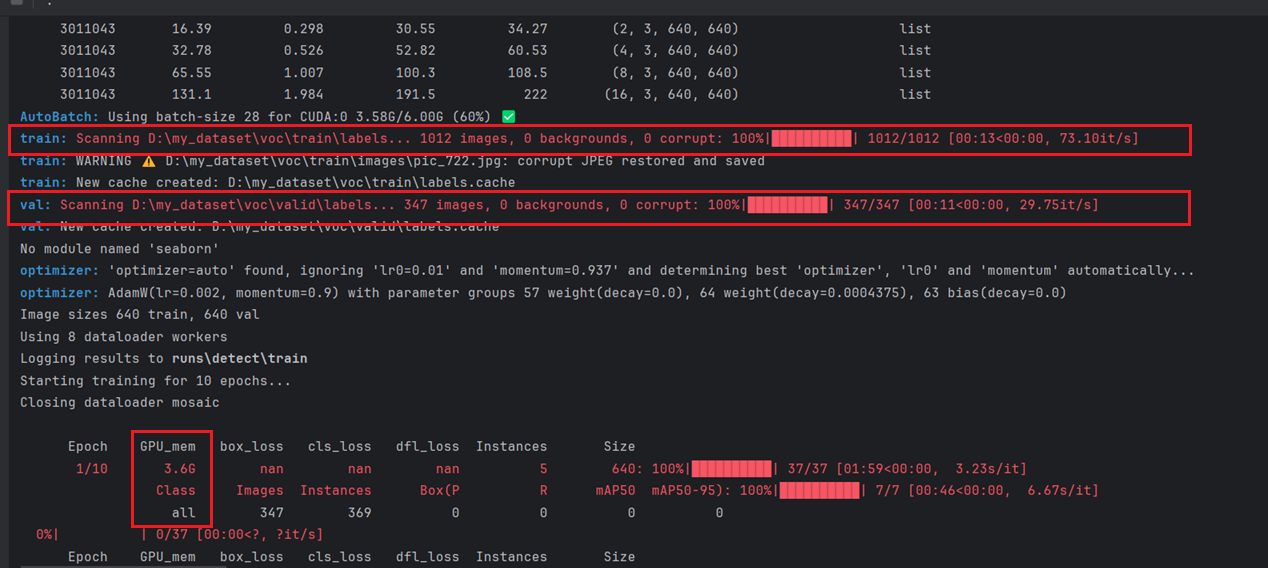
紧接着大家耐心等待一段时间,等训练完成后会出现以下界面
然后最下面是相关结果的保存路径,打开自己的yolov8文件夹,然后按照对应路径打开就行,最终结果如下
这个里面就是所有的训练结果了。
3.3 推理数据集
咱们在训练结果的文件夹中,找到weights文件夹,然后将其中的best.pt的路径进行复制(包括文件名称和后缀) 然后创建一个prediction的推理脚本,并将以下内容复制进去,然后将相应的路径进行修改,运行该脚本
然后创建一个prediction的推理脚本,并将以下内容复制进去,然后将相应的路径进行修改,运行该脚本
from ultralytics import YOLO
if __name__ == '__main__':
# 使用训练好的权重文件加载模型
model = YOLO(r'D:\my_dataset\ultralytics-8.2.82\ultralytics-8.2.82\runs\detect\train\weights\best.pt') # 替换为自己训练好的best.pt文件的绝对路径
# 推理参数设置
results = model.predict(save=True, source=r'D:\my_dataset\voc\valid\images\2008_000026.jpg') # 推理的图片存放路径
得到以下的推理输出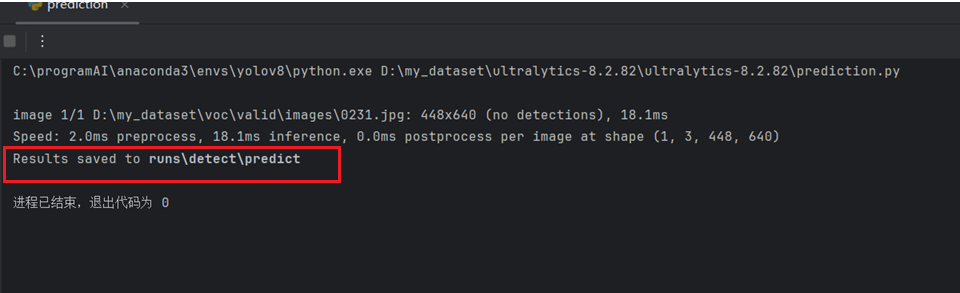
这个是推理结果的保存地址,我们进入地址查看推理结果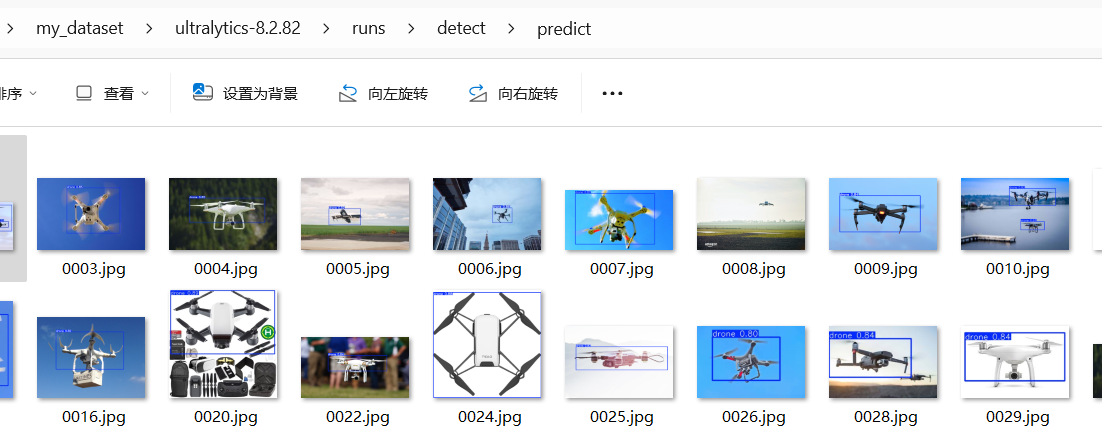

可以看出,结果不错!
4. 总结
本篇文章从最基础的标注数据集开始教学,直到最终成功调用GPU训练本人标注数据集,整个过程超级详细,基本都可以成功复现,同时也希望能对大家有所启发。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)