如何在不同版本的 Elasticsearch 集群间迁移数据 ?
快照是将Elasticsearch数据备份到共享存储(例如NFS共享文件系统)中,然后在新集群上恢复这些数据的方法。这种方式通常是最快、最可靠的迁移方式,但只能恢复到相同或高一级的版本,且不能跨超过一个主版本(例如6.x到7.x可以,但不能直接到8.x)。在本地化部署场景中,NFS(网络文件系统)是常用的共享存储解决方案,适合在企业内部网络环境中跨集群共享快照数据。以下是基于NFS的详细操作步骤。
Elasticsearch是一个功能强大的搜索和分析引擎,但当你需要升级 Elasticsearch 版本或在不同集群间迁移数据时,可能会遇到一些挑战。
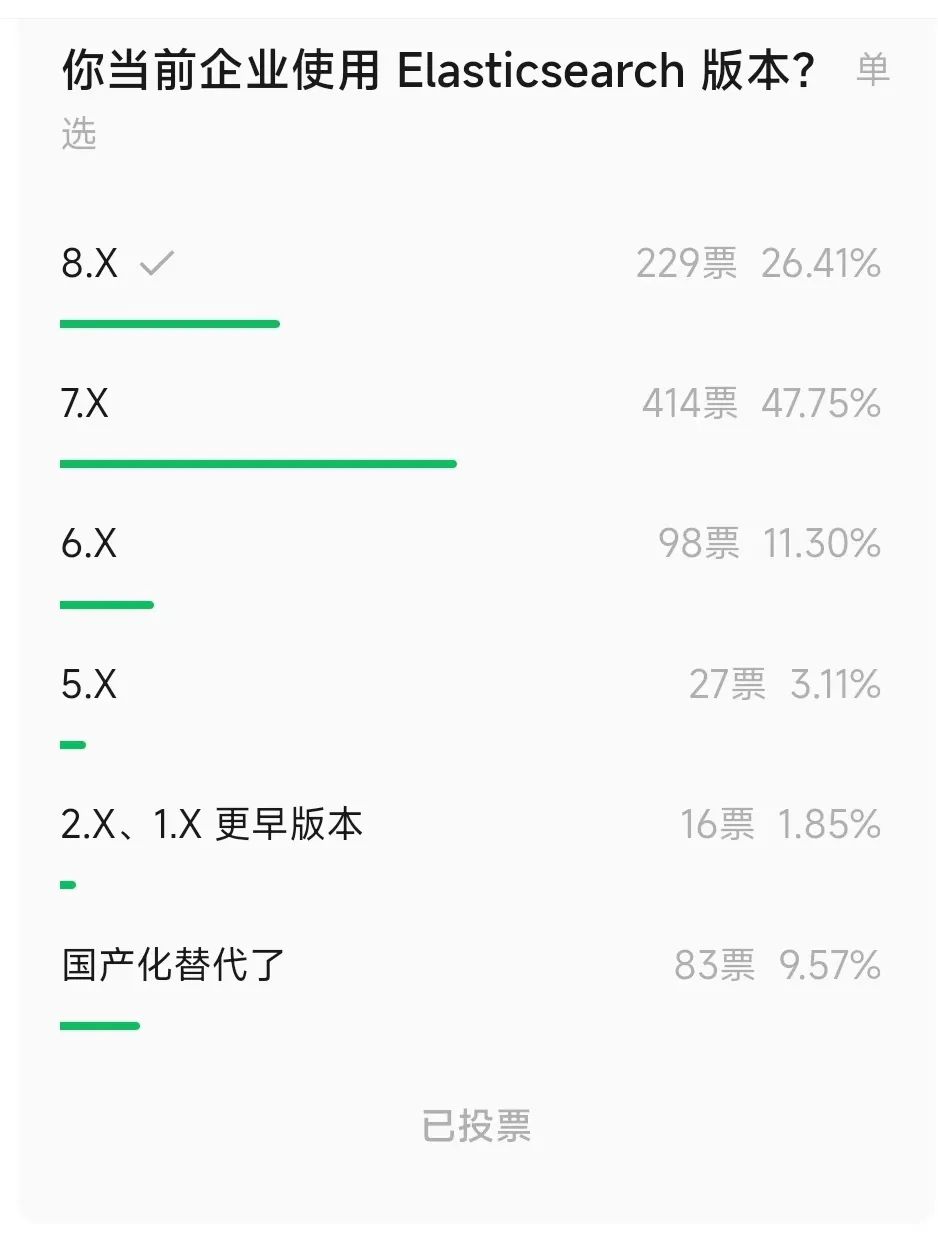
我这边随机统计过近 900 家企业真实使用 Elasticsearch 版本的情况?如下图所示:
直接升级可能有风险,因此创建一个新集群并将数据从旧集群迁移到新集群通常是个更安全的选择。
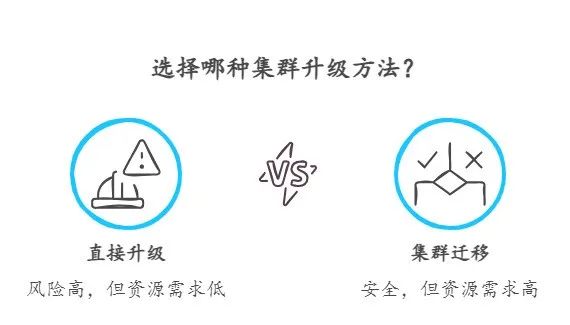
这种方式可以让你在新集群上测试数据和配置,而不会影响现有系统。不过,这种方法也有缺点,比如需要额外的硬件资源,并且数据同步可能会有点复杂。
在这篇博文中,我们将深入探讨三种在 Elasticsearch集群间迁移数据的方法,分别是远程reindex索引、快照传输和使用Logstash,并提供通俗易懂的操作指南和常见问题解决方案。

无论你是想升级版本还是跨数据中心迁移数据,这篇指南都能帮到你!
1、三种迁移数据的方法
以下是迁移 Elasticsearch 数据的三种主要方式:
-
方案一:远程 Reindex 索引
通过直接从旧集群读取数据并写入新集群,适合需要跨多个版本升级的场景。
-
方案二:使用快照(Snapshots)
通过备份和恢复快照来迁移数据,通常是最快、最可靠的方式,但有版本限制。
-
方案三:使用 Logstash
通过 Logstash 作为一个中间工具,将数据从一个集群传输到另一个集群,适合灵活性要求高的场景。
快照方式通常最快,但只能将数据恢复到相同或高一级的版本,且不能跨超过一个主版本(比如6.x到7.x可以,但不能直接到8.x)。
如果需要跨多个主版本升级,你需要使用远程 Reindex 索引或 Logstash。
接下来,我们逐一详细讲解这三种方法的操作步骤和注意事项。
2、方法一:远程 Reindex 索引
2.1 什么是远程 Reindex 索引?
远程 reindex 索引是通过Elasticsearch的_reindex API,从旧集群直接读取数据并写入新集群。
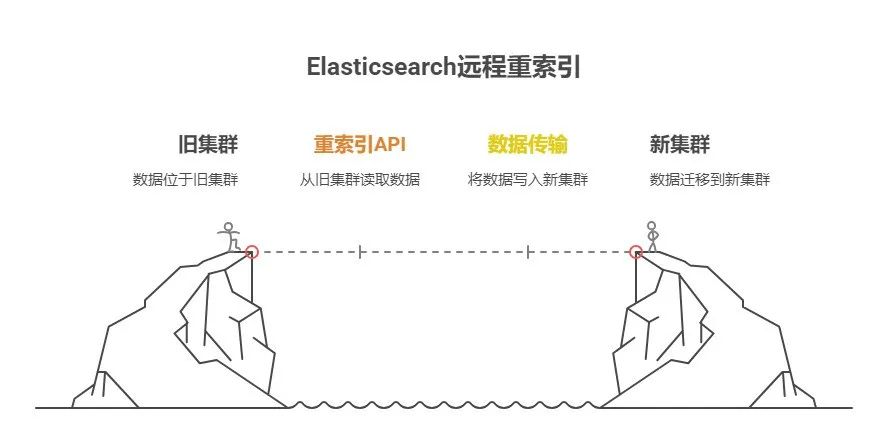
这种方法适合需要跨多个主版本升级或在不同数据中心之间迁移数据的场景。
2.2 操作步骤
-
在新集群上设置索引映射
在新集群上,我们需要先为目标索引创建正确的映射(mappings)。可以通过以下两种方式实现:
-
直接创建索引并定义映射。
-
使用索引模板(index templates)自动应用映射。
-
配置接收数据的集群
在新集群的每个节点上,修改elasticsearch.yml配置文件(通常位于/etc/elasticsearch/elasticsearch.yml),添加以下内容,允许从旧集群的IP和端口读取数据:reindex.remote.whitelist: "192.168.1.11:9200"如果使用SSL,还需配置证书路径:
reindex.ssl.certificate_authorities: "/path/to/ca.pem"或者(不太推荐,安全性较低),可以禁用SSL验证:
reindex.ssl.verification_mode: none配置完成后,需要对每个节点执行滚动重启(rolling restart)。具体步骤可参考Elasticsearch官方文档。
-
执行 reindex 索引命令
配置好后,使用以下API命令开始从旧集群 reindex 索引数据到新集群:POST _reindex { "source": { "remote": { "host": "http://192.168.1.11:9200", "username": "elastic", "password": "123456", "socket_timeout": "1m", "connect_timeout": "1m" }, "index": "companydatabase" }, "dest": { "index": "my-new-index-000001" } }注意:为了避免超时错误,建议设置较长的
socket_timeout和connect_timeout(如1分钟)。 -
验证数据迁移
执行完成后,检查新集群的索引是否包含正确的数据量和内容。 -
2.3 常见问题及解决方法
-
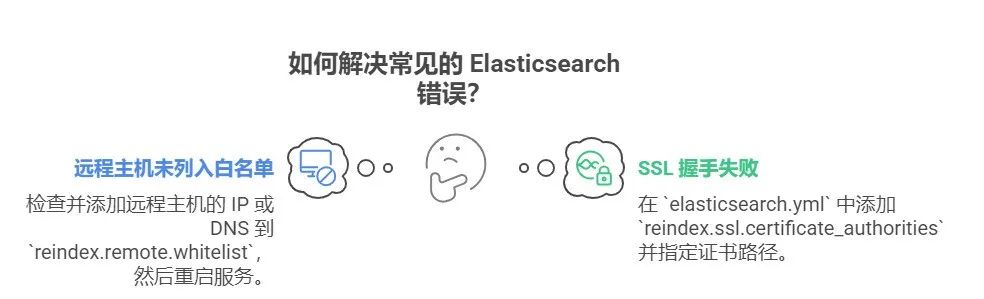
错误1:远程主机未列入白名单
错误信息:{ "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "[192.168.1.11:9200] not whitelisted in reindex.remote.whitelist" } ] } }原因:未在
elasticsearch.yml中添加远程主机的IP或DNS,或者忘记重启Elasticsearch服务。
解决方法:检查并添加reindex.remote.whitelist配置,然后重启服务。 -
错误2:SSL握手失败
错误信息:{ "error": { "root_cause": [ { "type": "s_s_l_handshake_exception", "reason": "PKIX path building failed" } ] } }原因:未正确配置SSL证书路径。
解决方法:在elasticsearch.yml中添加reindex.ssl.certificate_authorities并指定证书路径。
3、方法二:使用快照(Snapshots)
3.1 什么是快照迁移?
快照是将Elasticsearch数据备份到共享存储(例如NFS共享文件系统)中,然后在新集群上恢复这些数据的方法。这种方式通常是最快、最可靠的迁移方式,但只能恢复到相同或高一级的版本,且不能跨超过一个主版本(例如6.x到7.x可以,但不能直接到8.x)。

在本地化部署场景中,NFS(网络文件系统)是常用的共享存储解决方案,适合在企业内部网络环境中跨集群共享快照数据。以下是基于NFS的详细操作步骤。
3.2 操作步骤
-
在旧集群上配置NFS并安装存储库插件
确保旧集群支持快照功能,并配置好NFS共享存储。NFS需要提前在所有节点上挂载,确保每个节点都能访问相同的共享目录。
-
在旧集群的每个节点上,配置NFS挂载点,例如挂载到
/mnt/elasticsearch_snapshots。 -
确保NFS共享目录的权限正确,Elasticsearch进程用户(通常是
elasticsearch用户)需要对该目录有读写权限。
具体配置NFS的步骤可参考系统管理员指南或Elasticsearch官方文档。
-
-
重启旧集群
配置NFS并验证挂载成功后,执行滚动重启以应用更改。滚动重启可以避免集群服务中断,具体步骤参考Elasticsearch官方文档。 -
在旧集群上创建NFS存储库
使用以下API命令在旧集群上创建一个基于NFS的存储库:PUT _snapshot/my_nfs_repository { "type": "fs", "settings": { "location": "/mnt/elasticsearch_snapshots", "compress": true } } -
-
"type": "fs":指定存储库类型为文件系统(NFS)。 -
"location":指向NFS共享目录的路径,确保所有节点都能访问。 -
"compress": true:启用快照压缩以节省存储空间(可选)。
-
-
在新集群上配置NFS并安装存储库插件
在新集群的每个节点上重复步骤1,配置相同的NFS挂载点(例如/mnt/elasticsearch_snapshots),确保新集群也能访问相同的NFS共享目录。同样确认并验证NFS目录的读写权限。
-
在新集群上添加只读NFS存储库
将新集群连接到相同的NFS存储库,但设置为只读模式,以避免版本冲突或误操作覆盖快照数据:PUT _snapshot/my_nfs_repository { "type": "fs", "settings": { "location": "/mnt/elasticsearch_snapshots", "readonly": true } } -
-
设置
"readonly": true非常重要,这可以防止新集群意外写入快照数据,确保旧集群的快照安全。
-
-
恢复数据到新集群
使用快照恢复API将数据从NFS存储库恢复到新集群。例如:POST _snapshot/my_nfs_repository/snapshot_1/_restore { "indices": "index_name", "rename_pattern": "index_name", "rename_replacement": "restored_index_name" } -
-
"indices":指定要恢复的索引名称。 -
"rename_pattern"和"rename_replacement":可选,用于重命名恢复的索引。 -
具体恢复步骤和参数参考Elasticsearch官方快照恢复指南。
3.3 注意事项
-
NFS配置:确保NFS共享目录在所有节点上正确挂载,且网络连接稳定,避免快照过程中出现I/O错误。
-
版本限制:快照只能恢复到相同或高一级的Elasticsearch版本,且不能跨超过一个主版本。
-
权限管理:确保Elasticsearch进程用户对NFS目录有适当权限(通常需要读写权限用于创建快照,只读权限用于恢复)。
-
性能优化:NFS的性能可能受网络带宽和磁盘I/O限制,建议在迁移前测试NFS读写速度。
-
只读模式:在新集群上设置只读存储库可防止版本冲突,尤其当新旧集群版本不同时。
通过以上步骤,你可以使用NFS作为共享存储,在本地化部署的Elasticsearch集群间高效迁移数据。这种方式特别适合企业内部网络环境,能够充分利用现有基础设施。
如果你需要跨云环境迁移,可以考虑使用阿里云、腾讯云登云存储方案。
4、方法三:使用Logstash
4.1 什么是Logstash迁移?
Logstash 是一个数据处理管道工具,是之前咱们一直讲的 Elastic Stack 核心技术栈之一,可以从旧集群读取数据并写入新集群。
这种方法适合需要灵活配置或处理复杂数据转换的场景。
4.2 操作步骤
-
在新集群上设置索引映射
与远程 reindex 索引类似,你需要先在新集群上创建索引或使用索引模板定义映射。 -
安装并配置Logstash
在一台服务器上安装Logstash(内存别太低,实话说)。安装步骤参考Logstash官方文档。 -
配置Logstash管道
创建一个Logstash配置文件(例如transfer.conf),用于从旧集群读取数据并写入新集群。基本配置如下:input { elasticsearch { hosts => ["192.168.1.11:9200"] index => "index_name" docinfo => true } } output { elasticsearch { hosts => "https://192.168.1.12:9200" index => "index_name" } }如果集群启用了SSL安全认证,使用以下配置:
input { elasticsearch { hosts => ["192.168.1.11:9200"] index => "index_name" docinfo => true user => "elastic" password => "elastic_password" ssl => true ssl_certificate_verification => false } } output { elasticsearch { hosts => "https://192.168.1.12:9200" index => "index_name" user => "elastic" password => "elastic_password" ssl => true ssl_certificate_verification => false } } -
保留索引元数据
如果需要迁移多个索引并保留原始索引名称,修改输出配置:index => "%{[@metadata][_index]}"如果需要保留文档的原始ID,添加:
document_id => "%{[@metadata][_id]}"注意:保留文档ID会显著降低传输速度,仅在必要时使用。
-
运行Logstash
执行以下命令启动数据传输:bin/logstash -f transfer.conf
4.3 注意事项
-
Logstash适合需要复杂数据转换的场景,但性能可能不如快照。
-
对于大集群,适当增加Logstash服务器的资源以提高效率。
5、数据同步问题
数据迁移通常需要较长时间,旧集群中的数据可能会在迁移过程中发生更新。为了确保数据一致性,你需要考虑以下问题:
-
如何识别更新的数据?
如果你的数据包含last_update_time字段,可以用它来判断哪些数据在迁移期间发生了更新。 -
如何同步更新的数据?
-
队列系统:如果你的系统使用消息队列,可以“重放”最近的更新操作。
-
远程 reindex 索引:通过在_reindex请求中添加查询,重新索引
last_update_time晚于某个时间的数据。 -
Logstash:在输入配置中添加查询,过滤
last_update_time晚于某个时间的数据(注意可能导致重复)。 -
快照:快照无法只恢复部分索引,需结合其他方法或脚本更新增量数据。
-
-
如何避免数据重复?
除非在 reindex 索引或Logstash中明确设置document_id,否则可能出现重复记录。快照恢复速度快,可以考虑暂停更新以避免同步问题。 -
6、总结与建议
方法
优点
缺点
适用场景
远程 reindex 索引
灵活,适合跨多版本升级
配置复杂,可能有超时问题
跨数据中心迁移,版本差异较大
快照
最快、最可靠
只能恢复到高一级版本
版本差异不超过一个主版本
Logstash
高度可定制,支持复杂转换
性能较低,需额外服务器
需要复杂数据处理
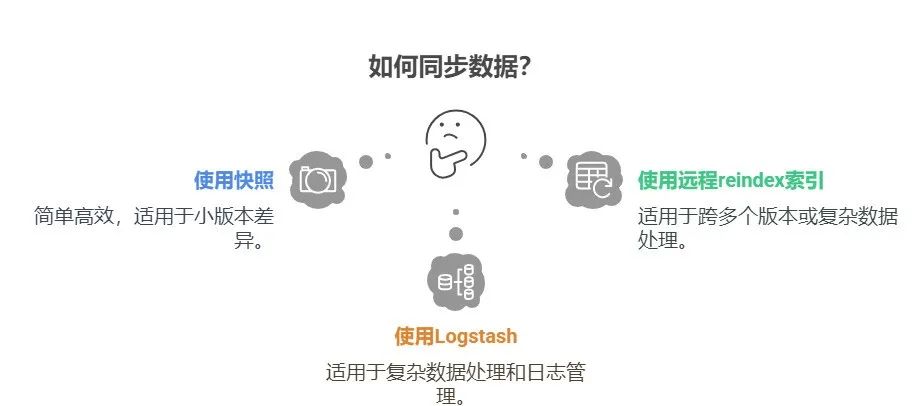
推荐选择:
-
如果版本差异不超过一个主版本,优先使用快照,因为它简单高效。
-
如果需要跨多个版本或有复杂数据处理需求,选择远程reindex索引或Logstash。
-
无论使用哪种方法,都要提前规划数据同步策略,防止数据丢失或重复。
希望这篇指南能帮助你顺利完成Elasticsearch数据迁移!
如果有其他问题,欢迎留言讨论!
干货 | Elasitcsearch7.X集群/索引备份与恢复实战
实战问题:Elasticsearch 2.X 数据如何迁移到 7.X?
数据库同步 Elasticsearch 后数据不一致,怎么办?
-

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)