数据工程 数据科学_什么是数据工程?
数据工程 数据科学This is the first in a series of posts on Data Engineering. If you like this and want to know when the next post in the series is released, you can subscribe at the bottom of the page.这是有关数..
数据工程 数据科学
This is the first in a series of posts on Data Engineering. If you like this and want to know when the next post in the series is released, you can subscribe at the bottom of the page.
这是有关数据工程的系列文章中的第一篇。 如果您喜欢这种方式,并且想知道该系列的下一篇文章何时发布,可以在页面底部进行订阅 。
From helping cars drive themselves to helping Facebook tag you in photos, data science has attracted a lot of buzz recently. Data scientists have become extremely sought after, and for good reason – a skilled data scientist can add incredible value to a business.
从帮助汽车驾驶到帮助Facebook在照片中标记您的身份,数据科学最近吸引了很多关注。 数据科学家受到了极大的追捧 ,并且有充分的理由-熟练的数据科学家可以为企业增加不可思议的价值。

Data scientists and engineers help power self-driving cars.
数据科学家和工程师为自动驾驶汽车提供动力。
But a data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in – they build pipelines that transform that data into formats that data scientists can use. Data engineers are just as important as data scientists, but tend to be less visible because they tend to be further from the end product of the analysis.
但是,数据科学家的素质仅与他们可以访问的数据一样好。 大多数公司在数据库和文本文件中以各种格式存储数据。 这就是数据工程师进来的地方–他们建立了将数据转换成数据科学家可以使用的格式的管道。 数据工程师与数据科学家同等重要,但由于它们离分析的最终产品更远,因此它们的知名度通常较低。
A good analogy is a race car builder vs a race car driver. The driver gets the excitement of speeding along a track, and thrill of victory in front of a crowd. But the builder gets the joy of tuning engines, experimenting with different exhaust setups, and creating a powerful, robust, machine. If you’re the type of person that likes building and tweaking systems, data engineering might be right for you. In this post, we’ll explore the day to day of a data engineer, and discuss the skills required for the role.
一个很好的类比是赛车制造商与赛车手。 驾驶员兴奋地沿着轨道行驶,并在人群面前获得胜利的快感。 但是,制造商可以通过调整引擎,尝试不同的排气设置以及创建功能强大,坚固的机器来获得乐趣。 如果您是喜欢构建和调整系统的人,那么数据工程可能适合您。 在本文中,我们将探讨数据工程师的日常工作,并讨论该角色所需的技能。
数据工程师的角色 (The data engineer role)
The data science field is incredibly broad, encompassing everything from cleaning data to deploying predictive models. However, it’s rare for any single data scientist to be working across the spectrum day to day. Data scientists usually focus on a few areas, and are complemented by a team of other scientists and analysts.
数据科学领域极为广阔,涵盖了从清理数据到部署预测模型的所有内容。 但是,很少有任何数据科学家每天都在整个频谱上工作。 数据科学家通常专注于几个领域,并由其他科学家和分析师团队进行补充。
Data engineering is also a broad field, but any individual data engineer doesn’t need to know the whole spectrum of skills. In this section, we’ll sketch the broad outlines of data engineering, then walk through more specific descriptions that illustrate specific data engineering roles.
数据工程也是一个广阔的领域,但是任何个人数据工程师都不需要了解全部技能。 在本节中,我们将概述数据工程的概述,然后遍历更具体的描述,以说明特定的数据工程角色。
A data engineer transforms data into a useful format for analysis. Imagine that you’re a data engineer working on a simple competitor to Uber called Rebu. Your users have an app on their device through which they access your service. They request a ride to a destination through your app, which gets routed to a driver, who then picks them up and drops them off. After the ride, they’re charged, and have the option to rate their driver.
数据工程师将数据转换成有用的格式进行分析。 想象一下,您是一名数据工程师,正在研究Uber的一个简单竞争对手Rebu。 您的用户在其设备上有一个应用程序,可以通过该应用程序访问您的服务。 他们通过您的应用程序请求到达目的地的路线,然后将其路由到驾驶员,驾驶员随后将其接下来并下车。 骑行之后,他们会被收费,并可以选择对驾驶员评分。
In order to maintain a service like this, you need:
为了维持这样的服务,您需要:
- A mobile app for users
- A mobile app for drivers
- A server that can pass requests from users to drivers, and handle other details like updating payment information
- 面向用户的移动应用
- 面向驾驶员的移动应用
- 服务器可以将用户的请求传递给驾驶员,并处理其他详细信息,例如更新付款信息
Here’s a diagram showing the communication:
这是显示通信的图:
+———–+ | | | Server | +—————–> | | <——————-+ | | | | | +——> | | <——+ | | | +———–+ | | | | | | | | | | | | | | | | | | | | | | v v v v +——+ +——+ +——–+ +——–+ | | | | | | | | | User | | User | | Driver | | Driver | | | | | | | | | | | | | | | | | | | | | | | | | +——+ +——+ +——–+ +——–+
+ ———– + | | | 服务器| + ——————–> | <——————- + | | | | | +-> | | | <-+ | | | + ———– + | | | | | | | | | | | | | | | | | | | | | | vvvv +-+ +-+ + ——– + + ——– + | | | | | | | | | 用户| | 用户| | 驱动程序 | 驱动程序 | | | | | | | | | | | | | | | | | | | | | | | | +-+ +-+ + ——– + + ——– +
As you may expect, this kind of system will generate huge amounts of data. You’ll have a few different data stores:
如您所料,这种系统将生成大量数据。 您将拥有一些不同的数据存储:
- The database that backs your main app. This contains user and driver information.
- Server analytics logs
- Server access logs. These contain one line per request made to the server from the app.
- Server error logs. These contain all the server-side errors generated by your app.
- App analytics logs
- App event logs. These contain information about what actions users and drivers took in the app. For example, you’d log when they clicked a button or updated their payment information.
- App error logs. These contain information about errors in the app.
- Ride database. This contains information about a single ride for user/driver pair, and contains status information on the ride.
- Customer service database. This contains information about customer interactions by customer service agents. It can include voice transcripts and email logs.
- 支持您的主应用程序的数据库。 其中包含用户和驱动程序信息。
- 服务器分析日志
- 服务器访问日志。 这些对应用程序向服务器发出的每个请求包含一行。
- 服务器错误日志。 这些包含您的应用程序生成的所有服务器端错误。
- 应用分析日志
- 应用程序事件日志。 这些包含有关用户和驱动程序在应用程序中采取了哪些操作的信息。 例如,您将在他们单击按钮或更新其付款信息时进行记录。
- 应用错误日志。 这些包含有关应用程序错误的信息。
- 骑数据库。 这包含有关用户/驾驶员对的单次骑行的信息,并包含该骑行的状态信息。
- 客户服务数据库。 这包含有关客户服务代理商进行的客户交互的信息。 它可以包括语音记录和电子邮件日志。
Here’s an updated diagram showing the data sources:
这是显示数据源的更新图表:
+————+ | Main | | Database | | | +———-+ +————+ | | +———–+ | Access | | Ride | ^ +—–> | Logs | | Database | | | +———-+ +—————+ | | <———+ | | | | | | + + + +———-+ | Customer | | | | Error | | Service | +———–+ +———–+ +—> | Logs | | Database | | | | | | | | Server | +———-+ +—————+ +—————–> | | <——————-+ | | | | ^ ^ | +——> | | <——+ | | | | | +———–+ | | | | | | | | | +————————–+ | | | | | | | | | | | | | | | | | | | | | | v + v v v | +—————-+ +——+ +——+ +——–+ +——–+ | | | | +——-+ | | | | | User | | User | | Error | | Driver | | Driver | | | | | +–> | Logs | | | | | +———–+ | | | | | | | | | | | Error | | | | | | | | | | | | Logs | <—–+ +——+ +——+ +——-+ +——–+ +——–+ | | +———–+ + + | | | | v v +———+ +———+ | Access | | Access | | Logs | | Logs | | | | | | | | | +———+ +———+
+ ———— + | 主要| | 数据库| | | + ————- + + ———— + | | + ———– + | 访问| | 骑乘 ^ +-> | 日志| | 数据库| | | + ————- + + —————— + | | <——— + | | | | | | + + + + ———- + | 客户| | | | 错误 | 服务| + ---------- 日志| | 数据库| | | | | | | | 服务器| + ————- + + —————— + + ————-–> | | <——————- + | | | | ^ ^ | +-> | | | <-+ | | | | | + ———– + | | | | | | | | | + —————————— ++ | | | | | | | | | | | | | | | | | | | | | v + vvv | + ——————- ++-++-++ ——– + + ——– + | | | | + ——- + | | | | | 用户| | 用户| | 错误 | 驱动程序 | 驱动程序 | | | | + –> | 日志| | | | | + ———– + | | | | | | | | | | | 错误 | | | | | | | | | | | 日志| <-+ +-+ +-+ + ——- + + ——– + + ——– + | | + ———– ++ + | | | | vv + ———— ++ ———— + | 访问| | 访问| | 日志| | 日志| | | | | | | | | + ———— ++ ————
Let’s say a data scientist wants to analyze a user’s action history with your service, and see what actions correlate with users who spend more. In order to enable them to create this, you’ll need to combine information from the server access logs and the app event logs. You’ll need to:
假设一位数据科学家想通过您的服务来分析用户的操作历史记录,并查看哪些操作与花费更多的用户相关联。 为了使他们能够创建此文件,您需要结合来自服务器访问日志和应用程序事件日志的信息。 您需要:
- Gather app analytics logs from user devices regularly
- Combine the app analytics logs with any server log entries that reference the user
- Create an API endpoint that returns the event history of any user
- 定期从用户设备收集应用程序分析日志
- 将应用程序分析日志与引用该用户的任何服务器日志条目结合在一起
- 创建一个API端点,该端点返回任何用户的事件历史记录
In order to solve this, you’ll need to create a pipeline that can ingest mobile app logs and server logs in real-time, parse them, and attach them to a specific user. You’ll then need to store the parsed logs in a database, so they can easily be queried by the API. You’ll need to spin up several servers behind a load balancer to process the incoming logs.
为了解决这个问题,您需要创建一个管道,该管道可以实时提取移动应用程序日志和服务器日志,解析它们并将它们附加到特定用户。 然后,您需要将已解析的日志存储在数据库中,以便可以通过API轻松查询它们。 您需要在负载均衡器后面启动多台服务器,以处理传入的日志。
Most of the issues that you’ll run into will be around reliability and distributed systems. For example, if you have millions of devices to gather logs from, and variable demand (in the morning, you get a ton of logs, but not as many at midnight), you’ll need a system that can automatically scale your server count up and down.
您将遇到的大多数问题都与可靠性和分布式系统有关。 例如,如果您有数百万台设备用于收集日志,并且需求变化不定(早上,您会收到大量日志,但午夜时则不多),那么您将需要一个能够自动扩展服务器数量的系统上和下。
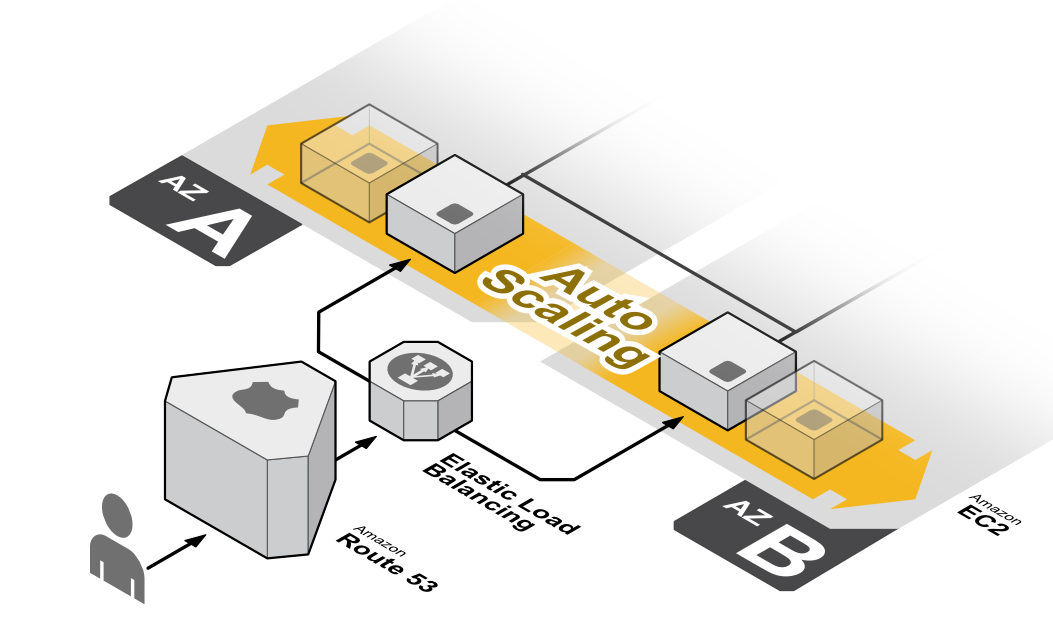
Running servers behind a load balancer. Servers are registered with the load balancer, and the load balancer sends traffic to them based on how busy they are. This means servers can be added or removed as needed.
在负载均衡器后面运行服务器。 服务器已在负载均衡器中注册,并且负载均衡器根据它们的繁忙程度向它们发送流量。 这意味着可以根据需要添加或删除服务器。
Roughly, the operations in a data pipeline consist of the following phases:
大致而言,数据管道中的操作包括以下几个阶段:
- Ingestion – this involves gathering in the needed data.
- Processing – this involves processing the data to get the end results you want.
- Storage – this involves storing the end results for fast retrieval.
- Access – you’ll need to enable a tool or user to access the end results of the pipeline.
- 摄取-这涉及收集所需的数据。
- 处理–这涉及处理数据以获得所需的最终结果。
- 存储–这涉及存储最终结果以便快速检索。
- 访问–您需要启用工具或用户才能访问管道的最终结果。
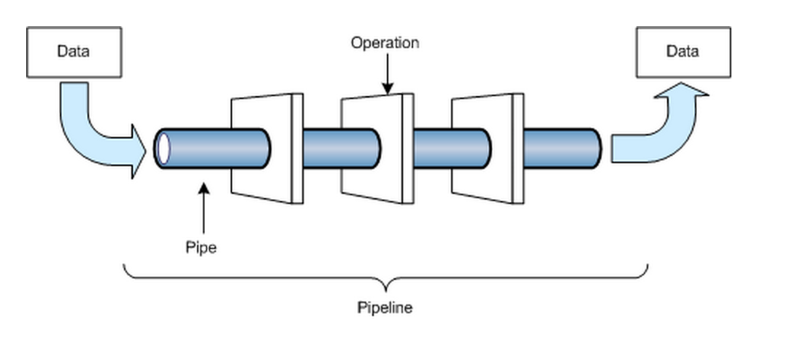
A data pipeline — input data is transformed in a series of phases into output data.
数据管道-输入数据经过一系列阶段转换为输出数据。
寻找质量差的游乐设施 (Finding bad quality rides)
For a more complex example, imagine that a data scientist wants to build a system that finds all rides that ended prematurely due to app or driver issues. One way to do this is to look at the customer service database to see which rides ended with issues, and analyze their language logn with some data about the ride.
对于一个更复杂的示例,假设数据科学家想要构建一个系统来查找所有由于应用程序或驾驶员问题而过早结束的游乐设施。 一种实现方法是查看客户服务数据库,以查看哪些游乐设施以问题结尾,并使用一些有关游乐设施的数据来分析其语言登录。
Before the data scientist can do this, they need a way to match up the logs in the customer service database with specific rides. As a data engineer, you’ll want to create an API endpoint that allows the data scientist to query for all customer service messages related to a particular ride. In order to do this, you’ll need to:
在数据科学家能够做到这一点之前,他们需要一种方法来将客户服务数据库中的日志与特定流程进行匹配。 作为数据工程师,您将需要创建一个API端点,该端点使数据科学家可以查询与特定行程相关的所有客户服务消息。 为此,您需要:
- Create a system that pulls data from the ride database, and figures out information about the ride, such as how long it was, and whether the destination matched the user’s initial request.
- Combine the computed statistics on each ride with user information, such as name and user id.
- Extract error information from the app and server analytics logs pertaining to the user during the time period of the ride.
- Find all customer service queries by a user.
- Create some heuristic to match rides with customer service queries (a simple example is that a customer service query is always about the previous ride)
- Store values as needed to ensure that the API performs quickly, even for future rides.
- Create an API that returns all customer service messages related to a particular ride.
- 创建一个从游乐设施数据库中提取数据的系统,并找出有关游乐设施的信息,例如游乐设施的持续时间以及目的地是否与用户的初始请求相匹配。
- 将每次乘车的计算统计信息与用户信息(例如名称和用户ID)结合起来。
- 在乘车期间从应用程序和服务器分析日志中提取与用户有关的错误信息。
- 查找用户的所有客户服务查询。
- 创建一些启发式方法,以将游乐设施与客户服务查询相匹配(一个简单的示例是,客户服务查询始终与先前的游乐设施有关)
- 根据需要存储值,以确保APISwift执行,甚至在以后的旅程中也是如此。
- 创建一个API,该API返回与特定旅程有关的所有客户服务消息。
A skilled data engineer will be able to build a pipeline that performs each of the above steps every time a new ride is added. This will ensure that the data served by the API is always up to date, and that whatever analysis the data scientist does is valid.
熟练的数据工程师将能够构建每次添加新行程时执行上述每个步骤的管道。 这将确保API提供的数据始终是最新的,并且数据科学家所做的任何分析都是有效的。
喜欢这篇文章吗? 使用Dataquest学习数据科学! (Enjoying this post? Learn data science with Dataquest!)
- Learn from the comfort of your browser.
- Work with real-life data sets.
- Build a portfolio of projects.
- 从舒适的浏览器中学习。
- 处理实际数据集。
- 建立项目组合。
数据工程技能 (Data engineering skills)
A data engineer needs to be good at:
数据工程师需要擅长:
- Architecting distributed systems
- Creating reliable pipelines
- Combining data sources
- Architecting data stores
- Collaborating with data science teams and building the right solutions for them
- 架构分布式系统
- 建立可靠的管道
- 合并数据源
- 架构数据存储
- 与数据科学团队合作,为他们建立正确的解决方案
Note that we didn’t mention any tools above. Although tools like Hadoop and Spark and languages like Scala and Python are important to data engineering, it’s more important to understand the concepts well and know how to build real-world systems. We’ll continue this focus on concepts over tools throughout this series on data engineering.
注意,我们上面没有提到任何工具。 尽管诸如Hadoop和Spark之类的工具以及诸如Scala和Python之类的语言对于数据工程很重要,但更重要的是要理解这些概念并知道如何构建实际系统。 在整个数据工程系列中,我们将继续将重点放在工具概念上。
数据工程角色 (Data engineering roles)
Although data engineers need to have the skills listed above, the day to day of a data engineer will vary depending on the type of company they work for. Broadly, you can classify data engineers into a few categories:
尽管数据工程师需要具备上面列出的技能,但数据工程师的日常工作依其工作的公司类型而异。 大致来说,您可以将数据工程师分为以下几类:
- Generalist
- Pipeline-centric
- Database-centric
- 通才
- 以管道为中心
- 以数据库为中心
Let’s go through each one of these categories.
让我们逐一介绍这些类别。
通才 (Generalist)
A generalist data engineer typically works on a small team. Without a data engineer, data analysts and scientsts don’t have anything to analyze, making a data engineer a critical first member of a data science team.
通才数据工程师通常在一个小型团队中工作。 没有数据工程师,数据分析师和科学家就无法进行任何分析,从而使数据工程师成为数据科学团队中至关重要的第一人。
When a data engineer is the only data-focused person at a company, they usually end up having to do more end-to-end work. For example, a generalist data engineer may have to do everything from ingesting the data to processing it to doing the final analysis. This requires more data science skill than most data engineers have. However, it also requires less systems architecture knowledge – small teams and companies don’t have a ton of users, so engineering for scale isn’t as important. This is a good role for a data scientist who wants to transition into data engineering.
当数据工程师是公司中唯一以数据为中心的人员时,他们通常最终不得不做更多的端到端工作。 例如,通才数据工程师可能必须做所有事情,从摄取数据到处理数据再到进行最终分析。 与大多数数据工程师相比,这需要更多的数据科学技能。 但是,它也需要较少的系统架构知识-小型团队和公司没有大量的用户,因此规模化工程并不那么重要。 对于想要过渡到数据工程的数据科学家来说,这是一个很好的角色。
When our hypothetical Uber competitor, Rebu, is small, a data engineer might be asked to create a dashboard that shows the number of rides taken for each day in the past month, along with a forecast for the next month.
当我们假设的优步竞争对手Rebu很小时,可能会要求数据工程师创建一个仪表板,以显示过去一个月每天的乘车次数以及下个月的预测。
以管道为中心 (Pipeline-centric)
Pipeline-centric data engineers tend to be necessary in mid-sized companies that have complex data science needs. A pipeline-centric data engineer will work with teams of data scientists to transform data into a useful format for analysis. This entails in-depth knowledge of distributed systems and computer science.
在具有复杂数据科学需求的中型公司中,往往需要以管道为中心的数据工程师。 以管道为中心的数据工程师将与数据科学家团队合作,将数据转换为有用的格式进行分析。 这需要对分布式系统和计算机科学有深入的了解。
As Rebu grows, a pipeline-centric data engineer might be asked to create a tool that enables data scientists to query metadata about rides to use in a predictive algorithm.
随着Rebu的发展,可能会要求以管道为中心的数据工程师创建一个工具,该工具使数据科学家能够查询有关在预测算法中使用的行程的元数据。
以数据库为中心 (Database-centric)
A database-centric data engineer is focused on setting up and populating analytics databases. This involves some work with pipelines, but more work with tuning databases for fast analysis and creating table schemas. This involves ETL work to get data into warehouses. This type of data engineer is usually found at larger companies with many data analysts that have their data distributed across databases.
以数据库为中心的数据工程师致力于建立和填充分析数据库。 这涉及一些与管道有关的工作,但涉及与调整数据库有关的工作,以进行快速分析和创建表模式。 这涉及ETL将数据放入仓库的工作 。 这种类型的数据工程师通常在大型公司中找到,这些公司的数据分析师分布在整个数据库中。
After Rebu takes over the world, a database centric data engineer might design an analytics database, then create scripts to pull information from the main app database into the analytics database.
在Rebu接管世界之后,以数据库为中心的数据工程师可能会设计一个分析数据库,然后创建脚本以将信息从主应用程序数据库提取到分析数据库中。
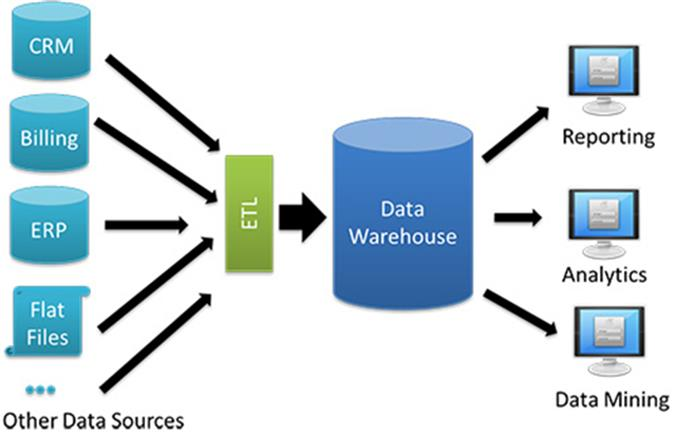
A data warehouse takes in data, then makes it easy for others to query it.
数据仓库接收数据,然后让其他人轻松查询数据。
数据工程技能 (Data engineering skills)
翻译自: https://www.pybloggers.com/2017/01/what-is-data-engineering/
数据工程 数据科学

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)