深入解析 Apache Spark:从架构设计到万亿级数据处理实战
Apache Spark 起源于 2009 年加州大学伯克利分校的 AMP 实验室,最初作为 Hadoop MapReduce 的替代方案,旨在解决其 “批处理效率低”“迭代计算性能差” 的问题。2013 年开源后,Spark 凭借内存计算优势,在数据处理速度上较 MapReduce 提升 10-100 倍,逐渐成为大数据生态的核心引擎。:Spark 通过 “批流一体” 的设计,在一个引擎中支持多
一、Spark 概述:大数据处理的 “闪电引擎”
1.1 Spark 的诞生与发展历程
Apache Spark 起源于 2009 年加州大学伯克利分校的 AMP 实验室,最初作为 Hadoop MapReduce 的替代方案,旨在解决其 “批处理效率低”“迭代计算性能差” 的问题。2013 年开源后,Spark 凭借内存计算优势,在数据处理速度上较 MapReduce 提升 10-100 倍,逐渐成为大数据生态的核心引擎。
1.2 Spark vs 其他大数据框架对比
| 框架 | 核心优势 | 适用场景 | 处理速度 |
|---|---|---|---|
| Spark | 内存计算、多范式支持 | 批处理、流处理、机器学习 | 秒级至分钟级 |
| Hadoop MapReduce | 高容错性、大规模数据存储 | 离线批处理 | 小时级 |
| Flink | 精确一次语义、毫秒级流处理 | 实时流处理 | 毫秒级 |
| Storm | 纯流式处理 | 实时事件处理 | 亚秒级 |
图表 1:大数据框架核心能力对比
二、Spark 架构与核心组件深度解析
2.1 分布式架构:Master-Slave 模型
Spark 采用经典的分布式架构,由Master 节点(负责资源调度)和Worker 节点(负责任务执行)组成。其核心组件包括:
- Driver:程序入口,负责创建 SparkContext、调度 Task 并监控执行过程。
- Executor:Worker 节点上的进程,负责执行 Task 并缓存数据。
- Cluster Manager:资源管理器(支持 Standalone、YARN、Kubernetes)。
Spark 分布式架构图
2.2 核心数据结构:从 RDD 到 Dataset/DataFrame
2.2.1 RDD(Resilient Distributed Dataset)
RDD 是 Spark 的基础数据结构,具有以下特性:
- 不可变性:数据分区后分布式存储,修改会生成新 RDD;
- 容错性:通过血统(Lineage)机制恢复数据,无需全量重算;
- 算子支持:分为转换算子(如 map、filter)和行动算子(如 count、collect)。
RDD 基础操作
from pyspark import SparkContext
# 初始化SparkContext
sc = SparkContext("local[*]", "RDD Example")
# 创建RDD
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 转换算子:map
squared_rdd = rdd.map(lambda x: x * x)
# 行动算子:collect
result = squared_rdd.collect()
print(result) # 输出: [1, 4, 9, 16, 25]2.2.2 DataFrame 与 Dataset:结构化数据处理
DataFrame 基于 RDD 扩展,引入了 Schema 元数据,类似关系型数据库的表结构,支持 SQL 查询与列式存储。Dataset 则结合了 DataFrame 的结构化能力和 RDD 的类型安全特性,在 Spark 2.0 后成为推荐的数据结构。
表格 2:RDD、DataFrame、Dataset 对比
| 数据结构 | 类型安全 | 性能 | 适用场景 |
|---|---|---|---|
| RDD | 否 | 基础性能 | 非结构化数据、底层开发 |
| DataFrame | 部分 | 优化性能 | 结构化数据、SQL 查询 |
| Dataset | 是 | 最高性能 | 强类型数据、API 开发 |
三、Spark 核心模块实战:从批处理到 AI 应用
3.1 Spark SQL:结构化数据处理
Spark SQL 支持将 DataFrame 作为 SQL 表操作,同时兼容 Hive 语法,实现 “一次编写,多源执行”。
Spark SQL 实战
from pyspark.sql import SparkSession
# 初始化SparkSession
spark = SparkSession.builder \
.appName("Spark SQL Example") \
.config("spark.sql.warehouse.dir", "/user/hive/warehouse") \
.enableHiveSupport() \
.getOrCreate()
# 读取CSV文件创建DataFrame
df = spark.read.csv("sales_data.csv", header=True, inferSchema=True)
# 注册为临时视图
df.createOrReplaceTempView("sales")
# SQL查询:统计各地区销售额
result = spark.sql("""
SELECT region, SUM(amount) AS total_sales
FROM sales
GROUP BY region
ORDER BY total_sales DESC
""")
# 显示结果
result.show()各地区销售额分布柱状图
3.2 Spark Streaming:实时流处理
Spark Streaming 将流数据分割为微小批次(如 500ms),通过 DStream(离散流)抽象实现准实时处理,支持 Kafka、Flume 等数据源。
Spark Streaming 工作流程
3.3 MLlib:机器学习库
MLlib 提供标准化的机器学习 API,支持分类、回归、聚类等算法,且内置 Pipeline 流水线机制简化模型部署。
基于 MLlib 的鸢尾花分类
from pyspark.ml import Pipeline
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
# 加载数据集
data = spark.read.format("libsvm").load("iris_libsvm.txt")
# 特征工程:将多列特征合并为向量
assembler = VectorAssembler(inputCols=data.columns[:-1], outputCol="features")
assembled_data = assembler.transform(data)
# 划分训练集与测试集
train, test = assembled_data.randomSplit([0.8, 0.2], seed=42)
# 构建随机森林模型
rf = RandomForestClassifier(
featuresCol="features",
labelCol="label",
numTrees=10,
maxDepth=5
)
# 定义Pipeline
pipeline = Pipeline(stages=[rf])
# 训练模型
model = pipeline.fit(train)
# 预测与评估
predictions = model.transform(test)
evaluator = MulticlassClassificationEvaluator(
labelCol="label",
predictionCol="prediction",
metricName="accuracy"
)
accuracy = evaluator.evaluate(predictions)
print(f"模型准确率: {accuracy}")四、Spark 性能优化:从参数调优到架构设计
4.1 内存管理优化
Spark 的内存管理分为执行内存(Executor 执行 Task)和存储内存(缓存 RDD/Dataset),合理配置两者比例可提升性能:
spark.executor.memory:Executor 总内存,建议 8GB-64GB;spark.memory.fraction:执行与存储内存占比,默认 0.6;spark.memory.storageFraction:存储内存占比,默认 0.5。
4.2 并行度调优
并行度不足会导致任务积压,可通过以下参数调整:
spark.default.parallelism:默认并行度,建议设为集群 CPU 核心数的 2-3 倍;repartition/coalesce:手动调整 RDD 分区数,避免数据倾斜。
表格 3:Spark 关键优化参数对照表
| 参数名称 | 作用 | 推荐值 |
|---|---|---|
| spark.executor.cores | 每个 Executor 的 CPU 核心数 | 4-8(根据节点配置调整) |
| spark.executor.instances | Executor 数量 | 集群节点数 ×2-3 |
| spark.sql.shuffle.partitions | Shuffle 阶段分区数 | 200-400(根据数据量调整) |
| spark.driver.memory | Driver 内存 | 4GB-16GB |
五、Spark 实战案例:电商用户行为分析
5.1 场景描述
某电商平台需分析用户点击、购买、加购等行为数据,识别高价值用户群体,优化推荐系统。数据集包含:
- 点击日志:用户 ID、商品 ID、点击时间、页面路径;
- 交易数据:订单 ID、用户 ID、商品 ID、金额、时间。
5.2 数据处理流程
- 数据接入:通过 Spark Streaming 消费 Kafka 中的实时日志;
- 特征工程:提取用户点击频次、购买金额、停留时间等特征;
- 模型构建:使用 KMeans 聚类划分用户群体,结合 ALS 算法生成推荐列表;
- 结果输出:将分析结果写入 HBase 供前端展示。
电商用户行为分析架构图
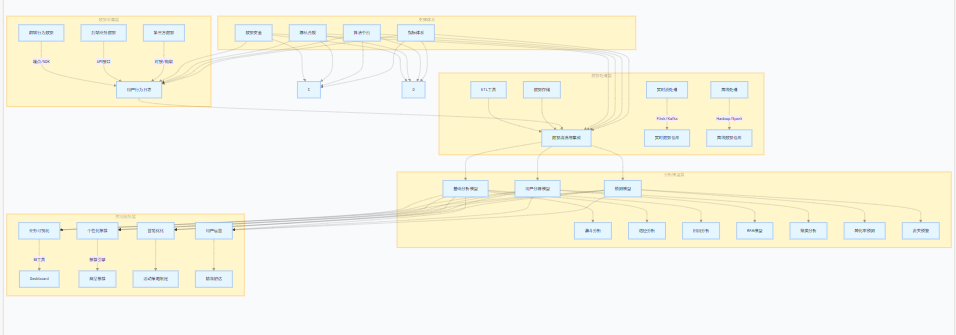
graph TD
subgraph "数据采集层"
A1[前端行为数据] -->|埋点/SDK| A[用户行为日志]
A2[后端业务数据] -->|API接口| A
A3[第三方数据] -->|对接/爬取| A
end
subgraph "数据处理层"
B1[ETL工具] --> B[数据清洗与集成]
B2[数据存储] --> B
B3[实时流处理] -->|Flink/Kafka| B4[实时数据仓库]
B5[离线处理] -->|Hadoop/Spark| B6[离线数据仓库]
end
subgraph "分析模型层"
C1[基础分析模型] --> C11[漏斗分析]
C1 --> C12[路径分析]
C1 --> C13[归因分析]
C2[用户分群模型] --> C21[RFM模型]
C2 --> C22[聚类分析]
C3[预测模型] --> C31[转化率预测]
C3 --> C32[流失预警]
end
subgraph "应用服务层"
D1[业务可视化] -->|BI工具| D11[Dashboard]
D2[个性化推荐] -->|推荐引擎| D21[商品推荐]
D3[营销优化] --> D31[活动策略制定]
D4[用户运营] --> D41[精准触达]
end
subgraph "支撑体系"
E1[数据安全]
E2[隐私合规]
E3[算法中台]
E4[指标体系]
end
A --> B
B --> C1 & C2 & C3
C1 & C2 & C3 --> D1 & D2 & D3 & D4
E1 & E2 & E3 & E4 --> A & B & C & D六、Spark 生态与未来发展
Spark 已形成完整生态体系,包括:
- 数据源层:支持 HDFS、S3、Kafka 等;
- 计算引擎层:Spark Core、Spark SQL、Spark Streaming;
- 应用层:MLlib(机器学习)、GraphX(图计算);
- 部署层:支持 YARN、Kubernetes、Standalone。
未来 Spark 将向以下方向发展:
- 流批一体:强化 Structured Streaming 实时性,对标 Flink;
- AI 融合:深度集成 TensorFlow/PyTorch,支持端到端 AI 工作流;
- 存储计算分离:适配云原生架构,降低资源成本。
七、Spark 的起源与定位
Apache Spark 是一个开源的分布式大数据处理引擎,由加州大学伯克利分校 AMP 实验室于 2009 年开发,2013 年捐赠给 Apache 基金会并正式开源。其核心设计目标是解决传统大数据框架(如 Hadoop MapReduce)在迭代计算、内存计算和多范式处理场景下的性能瓶颈。
- 核心优势:通过内存计算技术,Spark 将数据处理速度提升至 MapReduce 的 10-100 倍,同时支持批处理、流处理、机器学习、图计算等多种计算范式,成为大数据生态中的 “全能型” 引擎。
- 应用场景:从离线数据分析(如电商用户行为挖掘)到实时流处理(如金融交易监控),再到 AI 模型训练(如推荐系统),Spark 已被 Google、亚马逊、阿里巴巴等企业广泛应用。
二、Spark 的核心特性与架构解析
2.1 四大核心特性
| 特性 | 说明 |
|---|---|
| 内存计算 | 数据可驻留在内存中进行计算,避免频繁读写磁盘,大幅提升迭代任务性能。 |
| 多范式支持 | 统一支持批处理(Spark Core)、流处理(Spark Streaming)、SQL 查询(Spark SQL)、机器学习(MLlib)和图计算(GraphX)。 |
| 易用性与兼容性 | 提供 Python/Java/Scala/R 等多语言 API,兼容 Hadoop 生态(如 HDFS、YARN)。 |
| 高容错性 | 通过 “血统(Lineage)” 机制记录数据转换历史,部分节点故障时可快速恢复数据,无需全量重算。 |
2.2 分布式架构:Master-Slave 模型
Spark 采用经典的分布式架构,由 Master 节点(负责资源调度)和 Worker 节点(负责任务执行)组成,核心组件包括:
- Driver:程序入口,创建 SparkContext 并调度任务;
- Executor:Worker 节点上的进程,执行具体计算任务并缓存数据;
- Cluster Manager:资源管理器(支持 Standalone、YARN、Kubernetes 等)。
三、Spark 的数据处理核心:从 RDD 到 DataFrame/Dataset
3.1 RDD(Resilient Distributed Dataset)
RDD 是 Spark 的基础数据结构,本质是不可变的分布式数据集合,具有以下关键特性:
- 分区存储:数据分散在集群节点中,支持并行计算;
- 算子操作:分为转换算子(如
map、filter、join)和行动算子(如count、collect、saveAsTextFile); - 容错机制:通过 Lineage 记录 RDD 转换关系,例如
A → B → C,当 C 部分数据丢失时,可通过 A 和 B 重新计算恢复。
3.2 DataFrame 与 Dataset:结构化数据处理升级
- DataFrame:在 RDD 基础上引入 Schema(模式),类似关系型数据库的表结构,支持 SQL 查询和列式存储,适合处理结构化数据(如 CSV、JSON、数据库表)。
- Dataset:Spark 2.0 后推出的强类型数据结构,结合了 DataFrame 的结构化能力和 RDD 的类型安全特性,性能更优且代码可读性更强。
对比表格:RDD、DataFrame、Dataset 的核心差异
| 数据结构 | 类型安全 | 性能 | 适用场景 |
|---|---|---|---|
| RDD | 否 | 基础性能 | 非结构化数据、底层开发 |
| DataFrame | 部分 | 优化性能 | 结构化数据、SQL 查询、ETL |
| Dataset | 是 | 最高性能 | 强类型数据、API 开发、机器学习 |
四、Spark 生态模块:一站式大数据解决方案
Spark 并非单一引擎,而是由多个紧密集成的模块组成的生态体系:
- Spark Core:核心计算引擎,提供 RDD、任务调度、内存管理等基础能力。
- Spark SQL:支持结构化数据处理与 SQL/HiveQL 查询,可将 DataFrame 作为表操作,兼容 Hive 元数据。
- Spark Streaming:基于微批次(Micro-Batch)的流处理引擎,将实时数据流分割为小批次处理,支持 Kafka、Flume 等数据源。
- MLlib:机器学习库,内置分类、回归、聚类、协同过滤等算法,提供 Pipeline 流水线简化模型部署。
- GraphX:图计算框架,支持大规模图数据处理,如社交网络分析、推荐系统中的图遍历。
五、Spark 与其他大数据框架的对比
| 框架 | 核心优势 | 处理速度 | 典型场景 |
|---|---|---|---|
| Spark | 内存计算、多范式统一 | 秒级 - 分钟级 | 批处理、流处理、机器学习 |
| Hadoop MapReduce | 高容错性、大规模数据存储 | 小时级 | 离线批处理、日志归档 |
| Flink | 精确一次语义、毫秒级流处理 | 毫秒级 | 实时监控、金融交易 |
| Storm | 纯流式处理、低延迟 | 亚秒级 | 实时事件响应、广告投放 |
关键差异:Spark 通过 “批流一体” 的设计,在一个引擎中支持多种计算场景,而 Flink 和 Storm 更专注于实时流处理,MapReduce 则侧重离线批处理。
六、Spark 的应用案例与行业实践
- 电商领域:阿里巴巴使用 Spark 处理双 11 期间的用户行为数据,实时分析点击、加购、支付等行为,优化推荐系统和促销策略。
- 金融领域:摩根大通利用 Spark 构建风控模型,实时监控交易数据,识别欺诈行为;同时通过 MLlib 预测市场趋势。
- 社交领域:Twitter 使用 Spark Streaming 处理每秒数百万条推文,实时分析热点话题并推荐内容。
- 医疗领域:梅奥诊所通过 Spark 分析患者医疗记录和基因组数据,辅助疾病诊断和个性化治疗方案生成。
七、Spark 的未来发展趋势
- 流批一体深化:Spark 3.0 推出的 Structured Streaming 已实现流处理与批处理的统一 API,未来将进一步提升实时性,对标 Flink。
- AI 与大数据融合:强化与 TensorFlow、PyTorch 的集成,支持端到端的 AI 工作流(如数据预处理、特征工程、模型训练)。
- 云原生适配:优化在 Kubernetes 上的部署与资源管理,支持存储与计算分离架构,降低云计算成本。
- 性能与稳定性提升:通过动态资源分配、自适应查询优化(AQO)等技术,进一步提升大规模数据处理的效率和可靠性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)