mysql比较两个数据库表不同的数据
之前写的说法是还是不够简便。创建一个表t1:查询是否有不同数据。select count(*) from (select DISTINCT * fromt1)tunion allselect count(*) from t1;比对这两个值。如果一样就确定这个表无重复数据。只有一条。——————————————————————————————————————比较某一个字段有无重复数据。(比如表t1的
·
之前写的说法是还是不够简便。
创建一个表t1: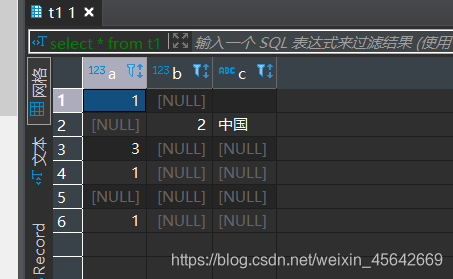
查询是否有不同数据。
select count(*) from (select DISTINCT * from t1)t
union all
select count(*) from t1;
比对这两个值。如果一样就确定这个表无重复数据。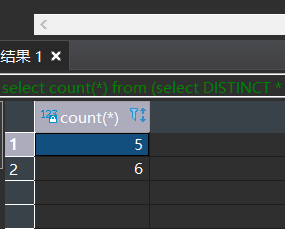
只有一条。
——————————————————————————————————————
比较某一个字段有无重复数据。
(比如表t1的a列有无重复数据)
select a,count(*) from t1 t
group by a
having count(*)>1;
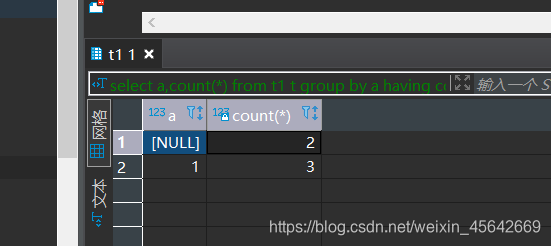
a列相同的有3条重复数据,重复的值分别为:
null重复的3条,1重复的两条。
————————————————————————————————————————
比较两个表不同的数据:
创建一个新表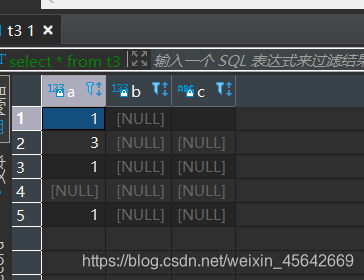
存在A表没有B表有,A表和B表不同、A表有B表没有这几个情况,所以挺难写的。
你得知道A表多了啥,B表多了啥,不然咋处理?
select * from
(select '旧数据' as 表格,t1.* from t1
union all
select '新数据' as 表格,t3.* from t3)t
group by a,b,c
having count(*)=1;
执行结果: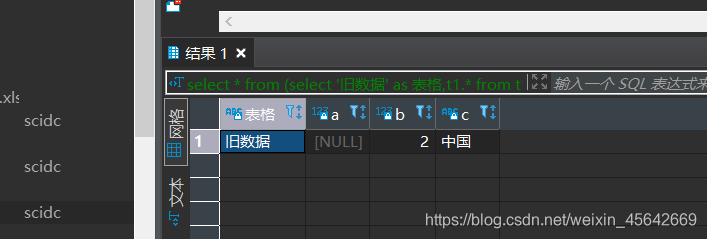

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)