python——json数据清洗(1)
数据集来源于某个比赛,文件是.json格式,内部嵌套了多个字典:json文件中的每一项的键是论文id,值是一个字典,该字典又包含键authors(作者)、title(论文题目)、abstract(摘要)、keywords(关键字)、venue(期刊)、year(年份)、id(论文编号)。第一步数据清洗的关键是从json文件中提取有用成分,这里只提取了作者名、作者所在机构和作者论文的关键字,由于文件
·
数据集来源于某个比赛,文件是.json格式,内部嵌套了多个字典: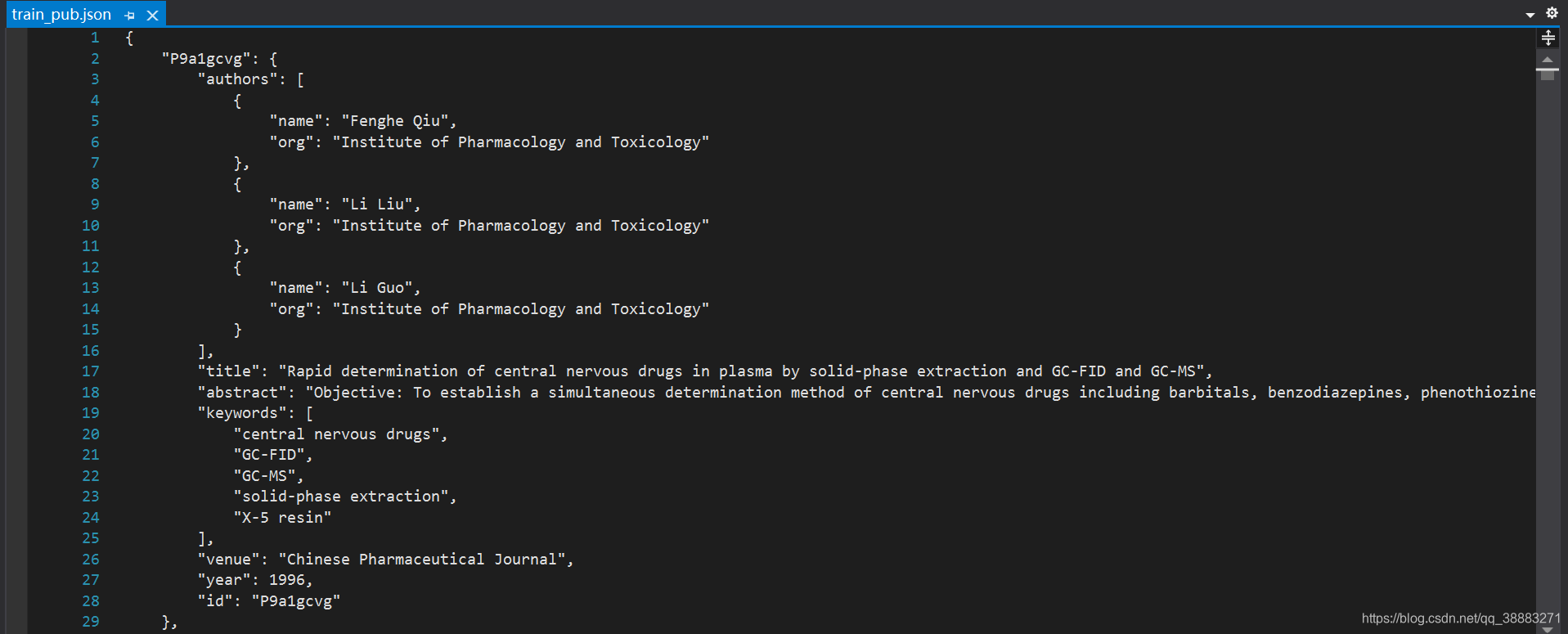
json文件中的每一项的键是论文id,值是一个字典,该字典又包含键authors(作者)、title(论文题目)、abstract(摘要)、keywords(关键字)、venue(期刊)、year(年份)、id(论文编号)。
第一步数据清洗的关键是从json文件中提取有用成分,这里只提取了作者名、作者所在机构和作者论文的关键字,由于文件中含有大量的缺失值,这里对不存在的键的值设置为空格,并追加到列表中。
import json
def loadJsonData(filename):
with open(filename) as f:
paper_data = json.load(f)
return paper_data
def author(paper_data):
author_name = []
author_org = []
paper_keywords = []
for id in paper_data.keys():
authors = paper_data[id]["authors"]
if "keywords" in paper_data[id].keys():
for i in range(len(authors)):
paper_keywords.append(paper_data[id]["keywords"])
else:
for i in range(len(authors)):
paper_keywords.append(" ")
for each in authors:
temp = list(each.values())
if len(temp) == 1:
author_name.append(temp[0])
author_org.append(" ")
else:
author_name.append(temp[0])
author_org.append(temp[1])
return author_name, author_org, paper_keywords
author_dict = loadJsonData("train_pub.json")
author_name, author_org, author_keywords = author(author_dict)
with open("author.txt", 'w', encoding="utf-8") as f:
for i in range(len(author_name)):
f.write('{:}\t{:}\n'.format(author_name[i], author_org[i]))
f.close()
with open("keywords.txt", 'w', encoding="utf-8") as f:
for i in range(len(author_keywords)):
for j in range(len(author_keywords[i])):
f.write('{:}\t'.format(author_keywords[i][j]))
f.write('\n')
f.close()
作者和机构文件: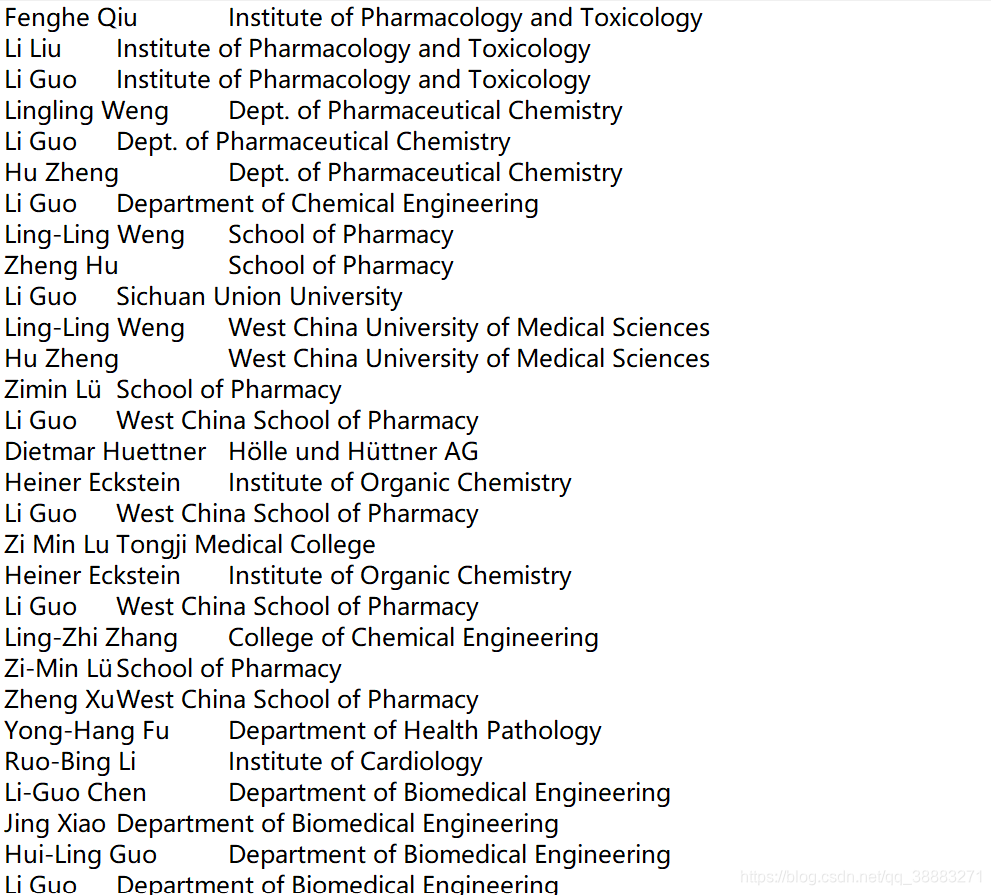
关键字文件:
每一行对应一个作者,同一份论文的不同作者所对应的论文关键字都是一样的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)