python 数据分析笔记——销售数据的预测
reset_index:可以保留多级索引信息,将其转换为普通列,同时能通过设置 drop=True 只保留原数据索引,从而正确赋值给 df 的新列。values:直接将计算结果转换为 NumPy 数组,丢弃所有索引信息,当原 DataFrame 索引是默认整数索引且顺序一致时,可直接赋值给新列。通过差分操作,可以消除数据中的季节性波动和周期性变化,从而更清晰地观察到潜在的长期趋势。—— 值越小越好
https://www.kaggle.com/competitions/tabular-playground-series-jan-2022
1.将 DataFrame 格式的数据以制表符分隔的文本形式在控制台输出
# 写法一:使用print配合to_csv
print(train.to_csv(sep='\t', na_rep='nan'))
# 写法二:直接指定to_csv的输出目标为标准输出
import sys
train.to_csv(sys.stdout, sep='\t', na_rep='nan')2.分组计算每月平均值的两种方式
monthly_avg = df.groupby(['product', 'month'])['num_sold'].mean().reset_index()agg聚合操作,返回的是分组后的统计结果(行数远少于原数据),输出仅包含product month num_sold三列
df['monthly_avg'] = df.groupby(['month', 'product'])['num_sold'].transform('mean')transform转换操作,返回的是与原数据行数相同的新列,
将该平均值 "广播" 到原 DataFrame 中对应分组的每一行
3.计算移动平均值
df['rolling_mean_7'] = df.groupby(['store', 'country', 'product'])['num_sold'].rolling(
window=7).mean().values计算窗口内的num_sold平均值
reset_index:可以保留多级索引信息,将其转换为普通列,同时能通过设置 drop=True 只保留原数据索引,从而正确赋值给 df 的新列。
values:直接将计算结果转换为 NumPy 数组,丢弃所有索引信息,当原 DataFrame 索引是默认整数索引且顺序一致时,可直接赋值给新列
4.计算一阶差分
df['trend'] = df.groupby(['store', 'country', 'product'])['num_sold'].diff()
# 对于具有明显季节性的序列(如月度数据的年周期),可使用季节性差分(如 12 步差分):
df['seasonal_diff'] = df['sales'] - df['sales'].shift(12)计算一阶差分(First Difference) 是揭示时间序列趋势的有效方法。通过差分操作,可以消除数据中的季节性波动和周期性变化,从而更清晰地观察到潜在的长期趋势。
二阶差分是一阶差分后再进行一次一阶差分的结果。
5.可视化分析
import matplotlib.pyplot as plt
import seaborn as sns
# 销售数据分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot(train['num_sold'], kde=True)
plt.title('销售数量分布')
# 对数转换后的销售数据分布
plt.subplot(1, 2, 2)
sns.histplot(np.log1p(train['num_sold']), kde=True)
plt.title('对数转换后的销售数量分布')
plt.tight_layout()
plt.savefig('sales_distribution.png')
plt.close()
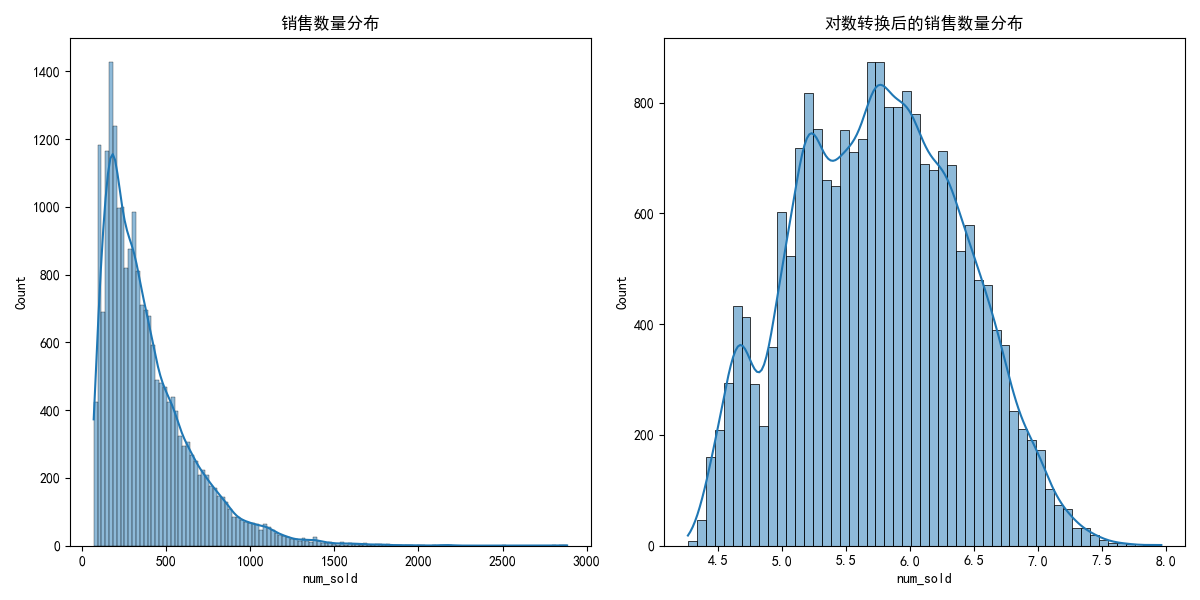
在数据分析和建模中,展示对数转换后的销售数据分布是一种常见且重要的操作,其核心目的是处理数据的偏态分布、压缩极端值影响,并让数据更接近建模所需的假设(如正态分布)。
# 按不同维度分析销售数据
plt.figure(figsize=(15, 10))
# 按店铺分析
plt.subplot(2, 2, 1)
store_sales = train.groupby('store')['num_sold'].sum().reset_index()
sns.barplot(x='store', y='num_sold', data=store_sales)
plt.title('各店铺总销售额')
# 按国家分析
plt.subplot(2, 2, 2)
country_sales = train.groupby('country')['num_sold'].sum().reset_index()
sns.barplot(x='country', y='num_sold', data=country_sales)
plt.title('各国总销售额')
# 按产品分析
plt.subplot(2, 2, 3)
product_sales = train.groupby('product')['num_sold'].sum().reset_index()
sns.barplot(x='product', y='num_sold', data=product_sales)
plt.title('各产品总销售额')
# 按日期分析
plt.subplot(2, 2, 4)
daily_sales = train.groupby('date')['num_sold'].sum().reset_index()
sns.lineplot(x='date', y='num_sold', data=daily_sales)
plt.title('每日总销售额趋势')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('sales_by_dimensions.png')
plt.close()
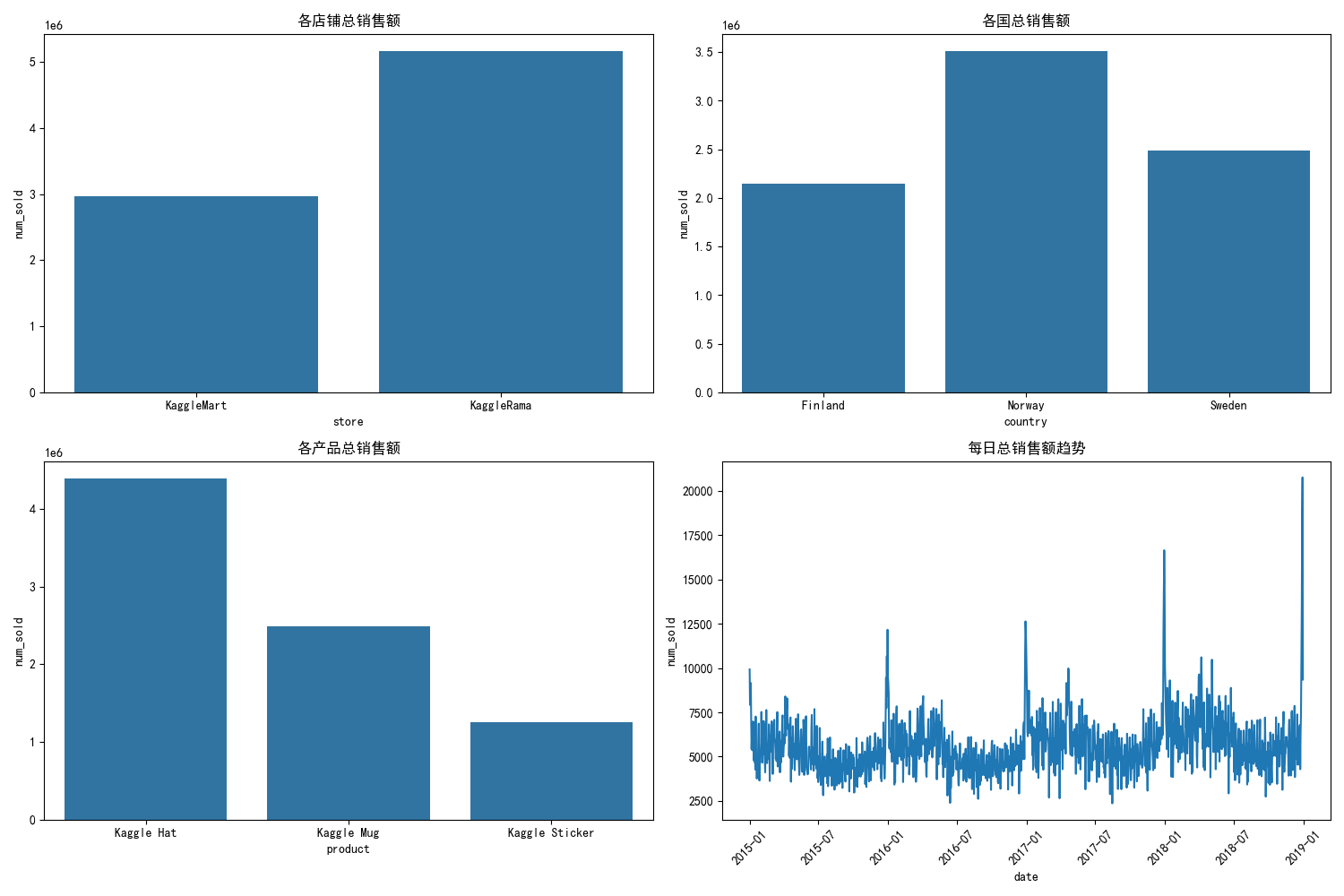
# 季节性分析
plt.figure(figsize=(15, 10))
# 按月分析
plt.subplot(2, 2, 1)
monthly_sales = train.groupby('month')['num_sold'].mean().reset_index()
sns.lineplot(x='month', y='num_sold', data=monthly_sales)
plt.title('月平均销售额')
# 按星期分析
plt.subplot(2, 2, 2)
dayofweek_sales = train.groupby('dayofweek')['num_sold'].mean().reset_index()
sns.lineplot(x='dayofweek', y='num_sold', data=dayofweek_sales)
plt.title('星期平均销售额')
plt.xticks(range(7), ['周一', '周二', '周三', '周四', '周五', '周六', '周日'])
# 按季度分析
plt.subplot(2, 2, 3)
quarterly_sales = train.groupby('quarter')['num_sold'].mean().reset_index()
sns.lineplot(x='quarter', y='num_sold', data=quarterly_sales)
plt.title('季度平均销售额')
# 周末与工作日对比
plt.subplot(2, 2, 4)
weekend_sales = train.groupby('weekend')['num_sold'].mean().reset_index()
sns.barplot(x='weekend', y='num_sold', data=weekend_sales)
plt.title('周末与工作日平均销售额对比')
plt.xticks(range(2), ['工作日', '周末'])
plt.tight_layout()
plt.savefig('seasonal_analysis.png')
plt.close()
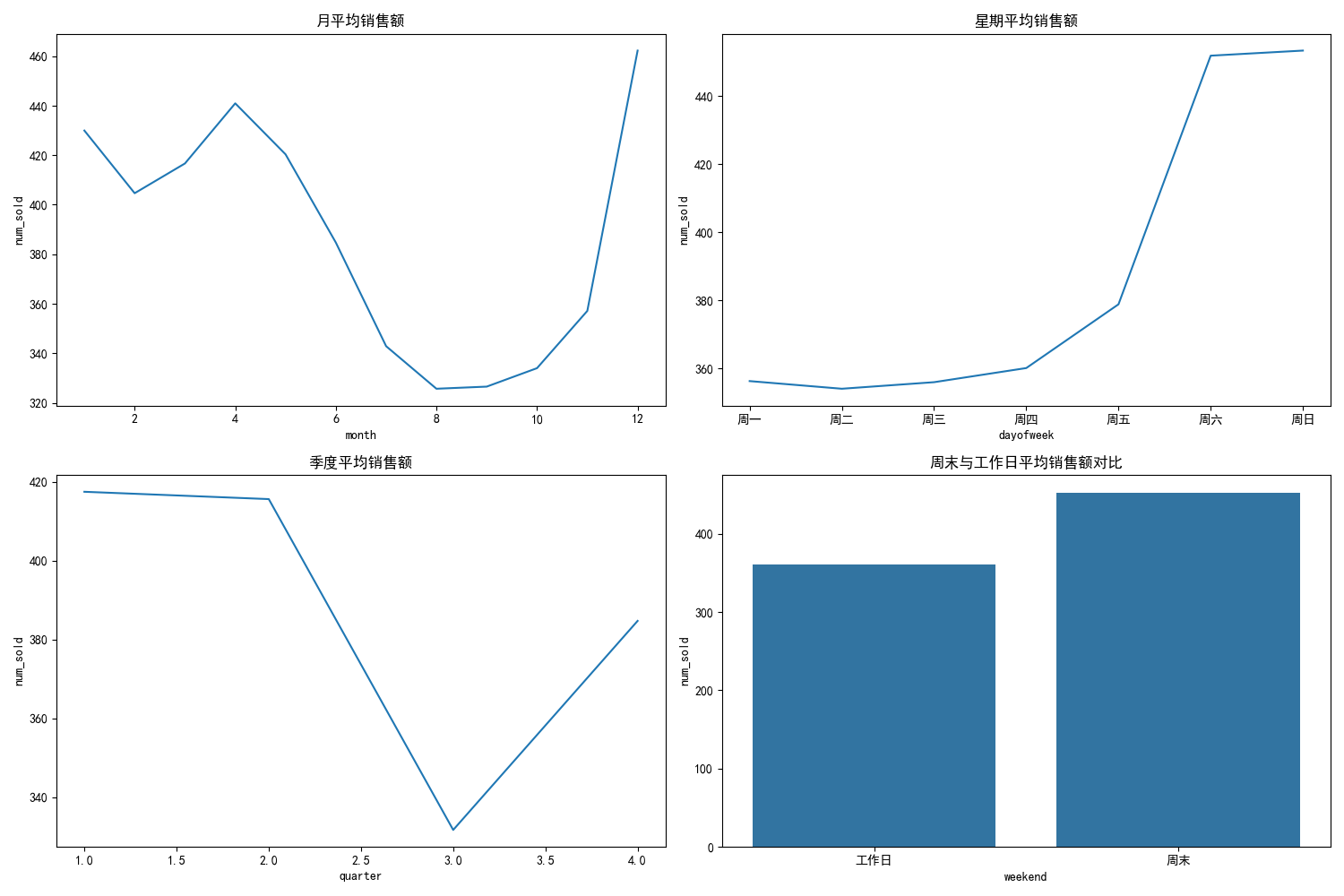
可以看到销售数据和季节还是有很强的关系的
# 相关性分析
plt.figure(figsize=(12, 10))
corr = train.select_dtypes(include=[np.number]).corr()
sns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm')
plt.title('特征相关性分析')
plt.tight_layout()
plt.savefig('correlation_analysis.png')
plt.close()
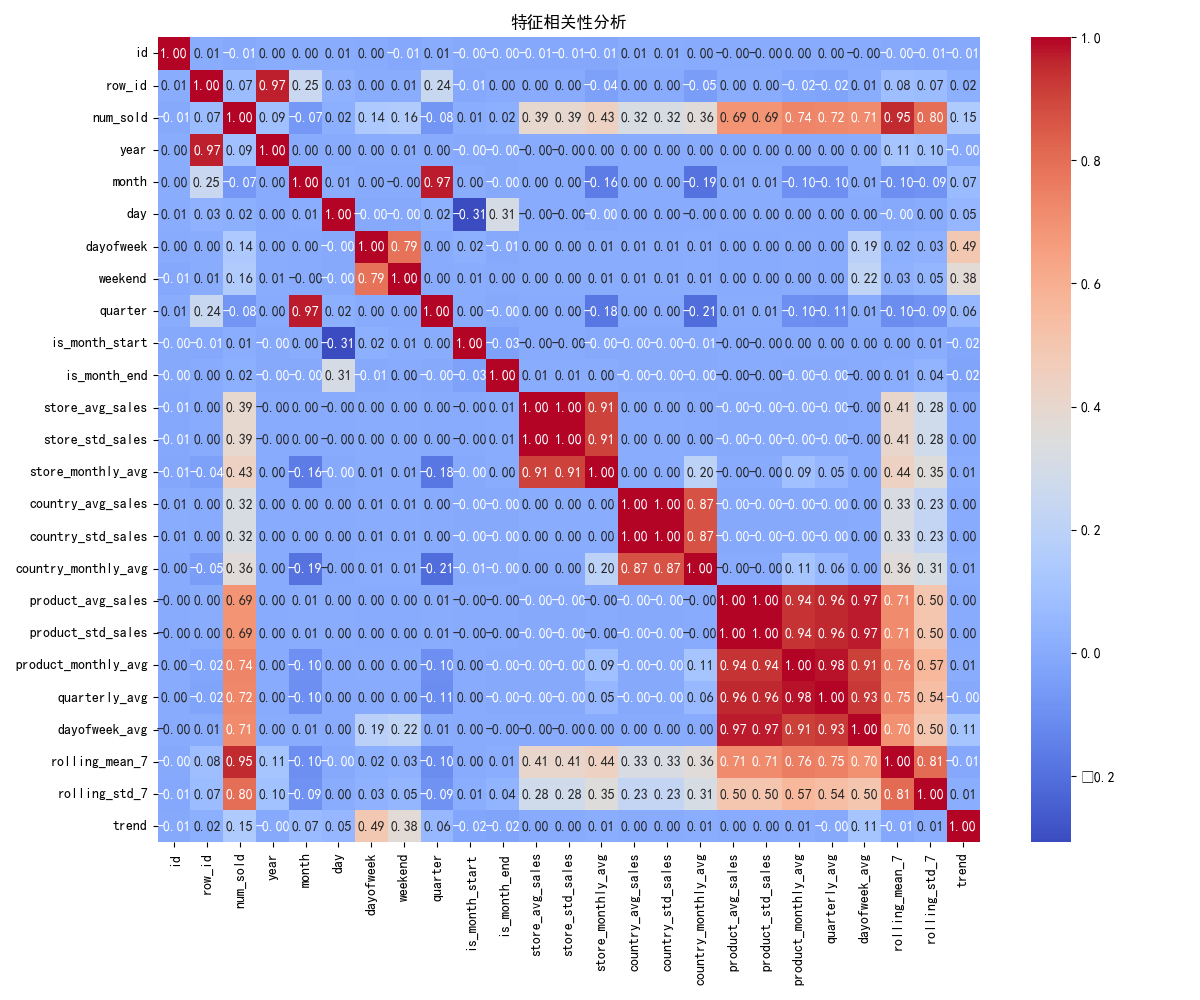
6.特征类型数据预处理
preprocessor = ColumnTransformer(
transformers=[
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features),
('num', StandardScaler(), numerical_features)
])
ColumnTransformer的作用是对不同列应用不同的预处理方法,并将结果合并为一个特征矩阵。在这个例子中,它对分类特征和数值特征分别执行不同的转换:
- 分类特征:使用
OneHotEncoder进行独热编码- 数值特征:使用
StandardScaler进行标准化
ColumnTransformer 可以有多种预处理的方法
一、分类特征预处理
1. 独热编码(One-Hot Encoding)
from sklearn.preprocessing import OneHotEncoder ColumnTransformer(transformers=[ ('cat', OneHotEncoder(handle_unknown='ignore'), ['category', 'country']) ])
- 作用:将分类特征转换为二进制向量,避免模型错误地学习类别间的顺序关系。
- 参数:
handle_unknown='ignore':忽略测试集中出现的未知类别(生成全零向量)。sparse=False:返回密集数组(默认返回稀疏矩阵)。2. 标签编码(Label Encoding)
from sklearn.preprocessing import OrdinalEncoder ColumnTransformer(transformers=[ ('cat', OrdinalEncoder(), ['size', 'rating']) # 适用于有序分类变量 ])
- 作用:将分类变量转换为整数(如 "small"→1, "medium"→2, "large"→3)。
- 注意:仅适用于有序分类变量(如学历、评分),否则可能误导模型。
3. 频率编码(Frequency Encoding)
from category_encoders import CountEncoder ColumnTransformer(transformers=[ ('cat', CountEncoder(), ['product_id', 'customer_id']) ])
- 作用:用类别出现的频率替换原始类别(如某产品出现 100 次→编码为 100)。
- 适用场景:高基数分类变量(如用户 ID、产品 ID)。
4. 目标编码(Target Encoding)
from category_encoders import TargetEncoder ColumnTransformer(transformers=[ ('cat', TargetEncoder(smoothing=1.0), ['country', 'store']) ])
- 作用:用类别对应的目标变量均值替换原始类别(如某国家的平均销量)。
- 参数:
smoothing:平滑参数,防止过拟合(尤其对低频类别)。- 注意:可能导致数据泄露,需配合交叉验证使用。
二、数值特征预处理
1. 标准化(Standardization)
from sklearn.preprocessing import StandardScaler ColumnTransformer(transformers=[ ('num', StandardScaler(), ['age', 'income']) ])
- 公式:
(x - mean) / std,使特征均值为 0,标准差为 1。- 适用场景:
- 依赖距离计算的模型(如 KNN、SVM)。
- 线性模型(如线性回归、逻辑回归)。
2. 归一化(Normalization)
from sklearn.preprocessing import MinMaxScaler ColumnTransformer(transformers=[ ('num', MinMaxScaler(feature_range=(0, 1)), ['height', 'weight']) ])
- 公式:
(x - min) / (max - min),将特征缩放到 [0,1] 区间。- 适用场景:
- 神经网络、深度学习模型。
- 特征范围差异较大的数据。
3. 对数变换(Log Transformation)
from sklearn.preprocessing import FunctionTransformer ColumnTransformer(transformers=[ ('num', FunctionTransformer(np.log1p), ['sales', 'population']) ])
- 作用:处理右偏分布数据(如销售额),压缩极端值。
- 公式:
log(x+1),避免 log (0) 错误。4. 分箱(Binning)
from sklearn.preprocessing import KBinsDiscretizer ColumnTransformer(transformers=[ ('num', KBinsDiscretizer(n_bins=5, encode='onehot-dense'), ['age']) ])
- 作用:将连续数值特征离散化,减少异常值影响。
- 参数:
n_bins:分箱数量。encode:编码方式(如独热编码)。三、缺失值处理
1. 填充缺失值
from sklearn.impute import SimpleImputer ColumnTransformer(transformers=[ ('num', SimpleImputer(strategy='mean'), ['age']), # 数值特征用均值填充 ('cat', SimpleImputer(strategy='most_frequent'), ['gender']) # 分类特征用众数填充 ])
- 策略:
strategy='mean':均值(默认)。strategy='median':中位数(对异常值更稳健)。strategy='constant':常数(需配合fill_value参数)。2. 高级填充
from sklearn.impute import KNNImputer ColumnTransformer(transformers=[ ('num', KNNImputer(n_neighbors=5), ['temperature', 'humidity']) ])
- 作用:基于 K 近邻算法填充缺失值(利用相似样本的特征值)。
四、特征生成与选择
1. 多项式特征
from sklearn.preprocessing import PolynomialFeatures ColumnTransformer(transformers=[ ('poly', PolynomialFeatures(degree=2, include_bias=False), ['x', 'y']) ])
- 作用:生成特征的多项式组合(如
x²,xy,y²)。- 参数:
degree:多项式阶数。include_bias:是否包含常数项(默认为 True)。2. 特征选择
from sklearn.feature_selection import SelectKBest, f_regression ColumnTransformer(transformers=[ ('select', SelectKBest(score_func=f_regression, k=10), slice(0, 20)) # 从20个特征中选10个 ])
- 作用:根据统计检验(如 F 检验)选择最重要的特征。
- 参数:
score_func:评分函数(如f_regression用于回归,chi2用于分类)。k:选择的特征数量。
7.比较不同模型的预测性能
1. 模型定义
models = { '线性回归': LinearRegression(), '随机森林': RandomForestRegressor(n_estimators=100, random_state=42), '梯度提升树': GradientBoostingRegressor(n_estimators=100, random_state=42), 'K近邻': KNeighborsRegressor(n_neighbors=5) }
- 选择多种模型:覆盖线性模型、树模型和基于距离的模型,以找到最适合数据的算法。
- 固定随机种子:确保结果可复现。
2. 时间序列交叉验证(TSCV)
tscv = TimeSeriesSplit(n_splits=3) cv_scores = cross_val_score(pipeline, X_train, y_train, cv=tscv, scoring='neg_root_mean_squared_error')
TimeSeriesSplit:
专门为时间序列设计的交叉验证方法,确保验证集总是在训练集之后。例如,3 折 TSCV 的划分方式为:折1: 训练集=[1-3], 验证集=[4] 折2: 训练集=[1-4], 验证集=[5] 折3: 训练集=[1-5], 验证集=[6]这种划分避免了 “未来数据泄露”,符合真实预测场景。
neg_root_mean_squared_error:
Scikit-learn 默认将评分函数设计为 “越大越好”(如准确率),因此 RMSE 取负值。使用时需转换为正值:cv_rmse = -cv_scores.mean()3. 验证集评估
pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_val) val_rmse = np.sqrt(mean_squared_error(y_val, y_pred))
- 流水线的优势:
预处理(如独热编码、标准化)会在训练时自动应用于训练集,在预测时应用于验证集,确保处理逻辑一致。- 独立验证集:
除交叉验证外,使用独立的验证集(X_val,y_val)进一步评估模型泛化能力,避免过拟合。4. 结果存储
results[name] = { 'cv_rmse': cv_rmse, 'val_rmse': val_rmse, 'model': pipeline }
- 保存每个模型的交叉验证 RMSE、验证集 RMSE和完整流水线(含预处理和模型)。
- 便于后续选择最优模型并进行预测。
在机器学习中,
scoring='neg_root_mean_squared_error'是一种用于模型评估的评分标准,它代表负均方根误差(Negative Root Mean Squared Error, NRMSE)。
Scikit-learn 的评分函数有一个统一约定:
评分越高,表示模型性能越好(例如准确率、F1 分数等)。
但 RMSE 是一个误差指标—— 值越小越好,因此需要转换为负值,使 “负 RMSE” 符合 “越大越好” 的原则。
原始指标 负指标名称 含义 均方误差 (MSE) 'neg_mean_squared_error'预测误差的平方的平均值 均方根误差 (RMSE) 'neg_root_mean_squared_error'MSE 的平方根 平均绝对误差 (MAE) 'neg_mean_absolute_error'预测误差的绝对值的平均
一、分类问题常用策略
1. K 折交叉验证(K-Fold)
将数据随机分为 K 个子集,每次用 K-1 个子集训练,剩余 1 个验证
from sklearn.model_selection import KFold cv = KFold(n_splits=5, shuffle=True, random_state=42)
- 适用场景:数据分布均匀的分类或回归问题。
- 注意:需设置
shuffle=True确保随机划分。2. 分层 K 折(Stratified K-Fold)
保持每个折中各类别的比例与原始数据一致,避免类别不平衡导致的评估偏差。
from sklearn.model_selection import StratifiedKFold cv = StratifiedKFold(n_splits=5)
- 适用场景:分类问题(尤其是类别不平衡时)。
- 对比:普通 KFold 可能导致某些折中某类别样本极少。
3. 留一法(Leave-One-Out, LOO)
每次只留一个样本作为验证集,其余作为训练集。
from sklearn.model_selection import LeaveOneOut cv = LeaveOneOut() # 等价于 KFold(n_splits=len(X))
- 适用场景:数据量极少时(如医学研究)。
- 缺点:计算成本极高(需训练 n 次模型)。
二、回归问题常用策略
1. K 折交叉验证
同分类问题,但无需分层(因目标变量是连续值)。
cv = KFold(n_splits=5, shuffle=True)2. 分组 K 折(Group K-Fold)
当数据存在自然分组(如同一用户的多次行为)时,确保同一组的数据不在训练集和验证集中同时出现。
from sklearn.model_selection import GroupKFold groups = df['user_id'] # 用户ID作为分组依据 cv = GroupKFold(n_splits=5)
- 应用场景:用户行为分析、医学随访数据等。
三、时间序列专用策略
1. 时间序列分割(TimeSeriesSplit)
确保验证集在训练集之后,避免未来数据泄露。
from sklearn.model_selection import TimeSeriesSplit cv = TimeSeriesSplit(n_splits=5)
- 分割方式:
plaintext
折1: 训练集=[1-3], 验证集=[4] 折2: 训练集=[1-4], 验证集=[5] 折3: 训练集=[1-5], 验证集=[6] ...2. 滑动窗口(Rolling Window)
固定训练集大小,滑动验证集。
cv = TimeSeriesSplit(n_splits=5, test_size=10, gap=5)
- 参数:
test_size:验证集大小。gap:训练集与验证集之间的间隔(可选)。四、特殊场景策略
1. 打乱重复 K 折(Repeated K-Fold)
多次重复 KFold 过程,每次随机种子不同,增加评估稳定性
from sklearn.model_selection import RepeatedKFold cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=42)
- 适用场景:数据量有限且模型方差较高时。
2. 基于时间分组的验证
当数据有明确时间分组(如按周 / 月)时使用。
from sklearn.model_selection import GroupTimeSeriesSplit groups = pd.to_datetime(df['date']).dt.to_period('M') # 按月分组 cv = GroupTimeSeriesSplit(n_splits=3)如何选择验证策略
数据类型 推荐方法 示例场景 分类(平衡) StratifiedKFold 垃圾邮件检测(正负样本比 1:10) 分类(不平衡) StratifiedKFold + 分层抽样 疾病诊断(健康:患者 = 99:1) 回归 KFold 或 GroupKFold(有分组时) 房价预测 时间序列 TimeSeriesSplit 或 GroupTimeSeriesSplit 股票价格预测、天气预报 小样本 LeaveOneOut 或 RepeatedKFold 罕见病治疗效果分析
完整代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split, cross_val_score, TimeSeriesSplit
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
import warnings
import os
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
warnings.filterwarnings('ignore')
# 1. 数据加载与预处理
def load_and_preprocess_data():
"""加载数据并进行预处理"""
# 检查文件是否存在
if not all(os.path.exists(f) for f in ['train.csv', 'test.csv', 'submission.csv']):
raise FileNotFoundError("请确保train.csv、test.csv和submission.csv文件在当前目录下")
# 加载数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submission = pd.read_csv('submission.csv')
# 转换日期格式
train['date'] = pd.to_datetime(train['date'])
test['date'] = pd.to_datetime(test['date'])
# 提取日期特征
for df in [train, test]:
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['weekend'] = df['dayofweek'].isin([5, 6]).astype(int)
df['quarter'] = df['date'].dt.quarter
df['is_month_start'] = df['date'].dt.is_month_start.astype(int)
df['is_month_end'] = df['date'].dt.is_month_end.astype(int)
# 提取时间序列特征
train = add_time_features(train)
test = add_time_features(test, is_train=False)
return train, test, submission
def add_time_features(df, is_train=True):
"""添加时间序列特征"""
# 按店铺、国家和商品分组计算滚动统计量
if is_train:
# 对训练集计算完整的统计量
group_cols = ['store', 'country', 'product']
for col in group_cols:
# 计算每个分组的历史平均销量和标准差
stats = df.groupby(col)['num_sold'].agg(['mean', 'std']).reset_index()
stats.columns = [col, f'{col}_avg_sales', f'{col}_std_sales']
df = pd.merge(df, stats, on=col, how='left')
# 计算每个月的平均销量
monthly_avg = df.groupby([col, 'month'])['num_sold'].mean().reset_index()
monthly_avg.columns = [col, 'month', f'{col}_monthly_avg']
df = pd.merge(df, monthly_avg, on=[col, 'month'], how='left')
# 计算季节性特征
df['quarterly_avg'] = df.groupby(['quarter', 'product'])['num_sold'].transform('mean')
df['dayofweek_avg'] = df.groupby(['dayofweek', 'product'])['num_sold'].transform('mean')
# 计算移动平均和趋势
df = df.sort_values(['store', 'country', 'product', 'date'])
df['rolling_mean_7'] = df.groupby(['store', 'country', 'product'])['num_sold'].rolling(
window=7).mean().values
df['rolling_std_7'] = df.groupby(['store', 'country', 'product'])['num_sold'].rolling(
window=7).std().values
df['trend'] = df.groupby(['store', 'country', 'product'])['num_sold'].diff()
# 填充NaN值
df.fillna(0, inplace=True)
else:
# 测试集需要使用训练集的统计量
# 这里简化处理,实际应用中应使用训练集计算的统计量
for col in ['store', 'country', 'product']:
df[f'{col}_avg_sales'] = 0
df[f'{col}_std_sales'] = 0
df[f'{col}_monthly_avg'] = 0
df['quarterly_avg'] = 0
df['dayofweek_avg'] = 0
df['rolling_mean_7'] = 0
df['rolling_std_7'] = 0
df['trend'] = 0
return df
# 2. 数据探索与可视化
def exploratory_data_analysis(train):
"""执行探索性数据分析并可视化"""
print("数据基本信息:")
train.info()
# 数据集行数和列数
rows, columns = train.shape
if rows < 100000:
# 小数据集(行数少于10万)查看全量数据信息
print("数据全部内容信息:")
print(train.to_csv(sep='\t', na_rep='nan'))
else:
# 大数据集查看数据前几行信息
print("数据前几行内容信息:")
print(train.head().to_csv(sep='\t', na_rep='nan'))
# 描述性统计
print("\n数值特征描述性统计:")
print(train.select_dtypes(include=[np.number]).describe().round(2))
# 销售数据分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot(train['num_sold'], kde=True)
plt.title('销售数量分布')
# 对数转换后的销售数据分布
plt.subplot(1, 2, 2)
sns.histplot(np.log1p(train['num_sold']), kde=True)
plt.title('对数转换后的销售数量分布')
plt.tight_layout()
plt.savefig('sales_distribution.png')
plt.close()
# 按不同维度分析销售数据
plt.figure(figsize=(15, 10))
# 按店铺分析
plt.subplot(2, 2, 1)
store_sales = train.groupby('store')['num_sold'].sum().reset_index()
sns.barplot(x='store', y='num_sold', data=store_sales)
plt.title('各店铺总销售额')
# 按国家分析
plt.subplot(2, 2, 2)
country_sales = train.groupby('country')['num_sold'].sum().reset_index()
sns.barplot(x='country', y='num_sold', data=country_sales)
plt.title('各国总销售额')
# 按产品分析
plt.subplot(2, 2, 3)
product_sales = train.groupby('product')['num_sold'].sum().reset_index()
sns.barplot(x='product', y='num_sold', data=product_sales)
plt.title('各产品总销售额')
# 按日期分析
plt.subplot(2, 2, 4)
daily_sales = train.groupby('date')['num_sold'].sum().reset_index()
sns.lineplot(x='date', y='num_sold', data=daily_sales)
plt.title('每日总销售额趋势')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('sales_by_dimensions.png')
plt.close()
# 季节性分析
plt.figure(figsize=(15, 10))
# 按月分析
plt.subplot(2, 2, 1)
monthly_sales = train.groupby('month')['num_sold'].mean().reset_index()
sns.lineplot(x='month', y='num_sold', data=monthly_sales)
plt.title('月平均销售额')
# 按星期分析
plt.subplot(2, 2, 2)
dayofweek_sales = train.groupby('dayofweek')['num_sold'].mean().reset_index()
sns.lineplot(x='dayofweek', y='num_sold', data=dayofweek_sales)
plt.title('星期平均销售额')
plt.xticks(range(7), ['周一', '周二', '周三', '周四', '周五', '周六', '周日'])
# 按季度分析
plt.subplot(2, 2, 3)
quarterly_sales = train.groupby('quarter')['num_sold'].mean().reset_index()
sns.lineplot(x='quarter', y='num_sold', data=quarterly_sales)
plt.title('季度平均销售额')
# 周末与工作日对比
plt.subplot(2, 2, 4)
weekend_sales = train.groupby('weekend')['num_sold'].mean().reset_index()
sns.barplot(x='weekend', y='num_sold', data=weekend_sales)
plt.title('周末与工作日平均销售额对比')
plt.xticks(range(2), ['工作日', '周末'])
plt.tight_layout()
plt.savefig('seasonal_analysis.png')
plt.close()
# 相关性分析
plt.figure(figsize=(12, 10))
corr = train.select_dtypes(include=[np.number]).corr()
sns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm')
plt.title('特征相关性分析')
plt.tight_layout()
plt.savefig('correlation_analysis.png')
plt.close()
print("数据探索与可视化完成,图表已保存")
# 3. 特征工程与模型准备
def prepare_data_for_modeling(train, test):
"""准备建模数据"""
# 选择特征和目标变量
categorical_features = ['store', 'country', 'product', 'month', 'dayofweek', 'quarter']
numerical_features = ['year', 'day', 'weekend', 'is_month_start', 'is_month_end',
'store_avg_sales', 'store_std_sales', 'store_monthly_avg',
'country_avg_sales', 'country_std_sales', 'country_monthly_avg',
'product_avg_sales', 'product_std_sales', 'product_monthly_avg',
'quarterly_avg', 'dayofweek_avg']
# 添加时间序列特征(如果有)
if 'rolling_mean_7' in train.columns:
numerical_features.extend(['rolling_mean_7', 'rolling_std_7', 'trend'])
# 定义预处理流水线
preprocessor = ColumnTransformer(
transformers=[
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features),
('num', StandardScaler(), numerical_features)
])
# 准备训练数据
X = train[categorical_features + numerical_features]
y = train['num_sold']
# 准备测试数据
X_test = test[categorical_features + numerical_features]
return X, y, X_test, preprocessor, categorical_features, numerical_features
# 4. 模型训练与评估
def train_and_evaluate_models(X, y, preprocessor):
"""训练并评估多个模型"""
# 分割数据为训练集和验证集
# 由于是时间序列数据,我们使用最后一部分作为验证集
train_size = int(len(X) * 0.8)
X_train, X_val = X.iloc[:train_size], X.iloc[train_size:]
y_train, y_val = y.iloc[:train_size], y.iloc[train_size:]
# 定义要评估的模型
models = {
'线性回归': LinearRegression(),
'随机森林': RandomForestRegressor(n_estimators=100, random_state=42),
'梯度提升树': GradientBoostingRegressor(n_estimators=100, random_state=42),
'K近邻': KNeighborsRegressor(n_neighbors=5)
}
results = {}
# 训练和评估每个模型
for name, model in models.items():
# 创建完整的流水线
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)])
# 使用时间序列交叉验证
tscv = TimeSeriesSplit(n_splits=3)
cv_scores = cross_val_score(pipeline, X_train, y_train,
cv=tscv, scoring='neg_root_mean_squared_error')
# 转换为正值(因为cross_val_score返回负值)
cv_rmse = -cv_scores.mean()
# 在验证集上评估
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_val)
val_rmse = np.sqrt(mean_squared_error(y_val, y_pred))
results[name] = {
'cv_rmse': cv_rmse,
'val_rmse': val_rmse,
'model': pipeline
}
print(f"{name} 模型评估结果:")
print(f"交叉验证 RMSE: {cv_rmse:.4f}")
print(f"验证集 RMSE: {val_rmse:.4f}")
print("-" * 50)
# 选择表现最好的模型
best_model_name = min(results, key=lambda k: results[k]['val_rmse'])
best_model = results[best_model_name]['model']
print(f"\n最佳模型: {best_model_name}")
print(f"验证集 RMSE: {results[best_model_name]['val_rmse']:.4f}")
return best_model, results
# 5. 特征重要性分析
def analyze_feature_importance(best_model, categorical_features, numerical_features):
"""分析特征重要性"""
# 检查模型是否支持特征重要性
if hasattr(best_model.named_steps['model'], 'feature_importances_'):
# 获取特征重要性
feature_importances = best_model.named_steps['model'].feature_importances_
# 获取经过OneHotEncoder处理后的特征名称
ohe = best_model.named_steps['preprocessor'].named_transformers_['cat']
ohe_features = ohe.get_feature_names_out(categorical_features)
# 组合所有特征名称
all_features = list(ohe_features) + numerical_features
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({
'Feature': all_features,
'Importance': feature_importances
}).sort_values('Importance', ascending=False)
# 可视化前20个重要特征
plt.figure(figsize=(12, 8))
sns.barplot(x='Importance', y='Feature', data=importance_df.head(20))
plt.title('特征重要性分析')
plt.tight_layout()
plt.savefig('feature_importance.png')
plt.close()
print("特征重要性分析完成,图表已保存")
return importance_df
else:
print("所选模型不支持特征重要性分析")
return None
# 6. 生成预测并保存结果
def generate_predictions(best_model, test, submission):
"""生成预测并保存到CSV文件"""
# 生成预测
predictions = best_model.predict(test)
# 确保预测值为正数
predictions = np.maximum(0, predictions)
# 只保留 submission 的列名
predict = pd.DataFrame(columns=submission.columns)
# 将预测结果填充到 num_sold 列
predict['num_sold'] = predictions
# 添加从 0 开始的自然数作为 id 列
predict['id'] = range(len(predict))
# 保存预测结果
predict.to_csv('predict.csv', index=False)
print("预测结果已保存为predict.csv")
return predict
# 主函数
def main():
"""主函数,执行完整的机器学习流程"""
print("开始执行销售预测模型...")
# 步骤1: 数据加载与预处理
print("\n步骤1: 数据加载与预处理...")
train, test, submission = load_and_preprocess_data()
# 步骤2: 数据探索与可视化
print("\n步骤2: 数据探索与可视化...")
exploratory_data_analysis(train)
# 步骤3: 特征工程与模型准备
print("\n步骤3: 特征工程与模型准备...")
X, y, X_test, preprocessor, categorical_features, numerical_features = prepare_data_for_modeling(train, test)
# 步骤4: 模型训练与评估
print("\n步骤4: 模型训练与评估...")
best_model, results = train_and_evaluate_models(X, y, preprocessor)
# 步骤5: 特征重要性分析
print("\n步骤5: 特征重要性分析...")
analyze_feature_importance(best_model, categorical_features, numerical_features)
# 步骤6: 生成预测并保存结果
print("\n步骤6: 生成预测并保存结果...")
generate_predictions(best_model, X_test, submission)
print("\n销售预测模型执行完成!")
if __name__ == "__main__":
main()

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)