公司数据不泄露,DeepSeek R1本地化部署+web端访问+个人知识库搭建与使用,老旧笔记本也能跑出企业级AI
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!😝有需要的小伙伴,可以保存图片到。
1 Ollama PC本地化部署
1.1 下载Ollama
首先登录Ollama官网地址。
目前Ollama支持macOS、Linux、Windows,选择相应的系统,macOS和Windows直接下载,Linux系统需要执行下面命令:
| curl -fsSL https://ollama.com/install.sh | sh |
|---|
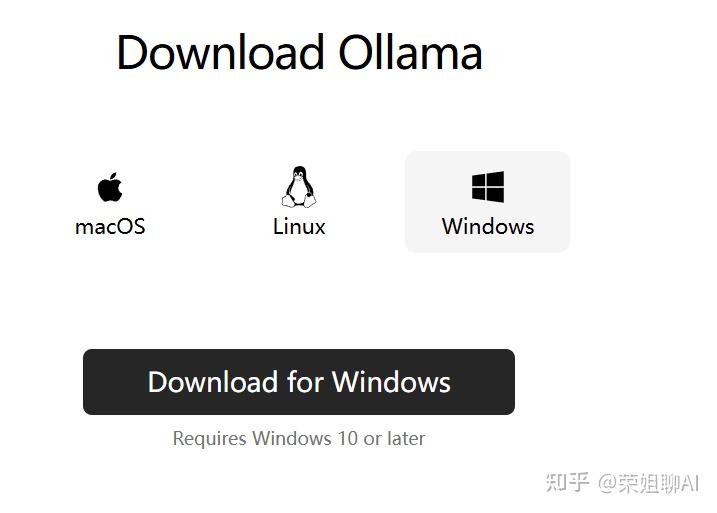
选择Windows本地下载,直接安装即可。
1.2 选择模型
点击Models,第一条就是deepseek-r1模型。或者搜索框输入模型名称进行搜索。
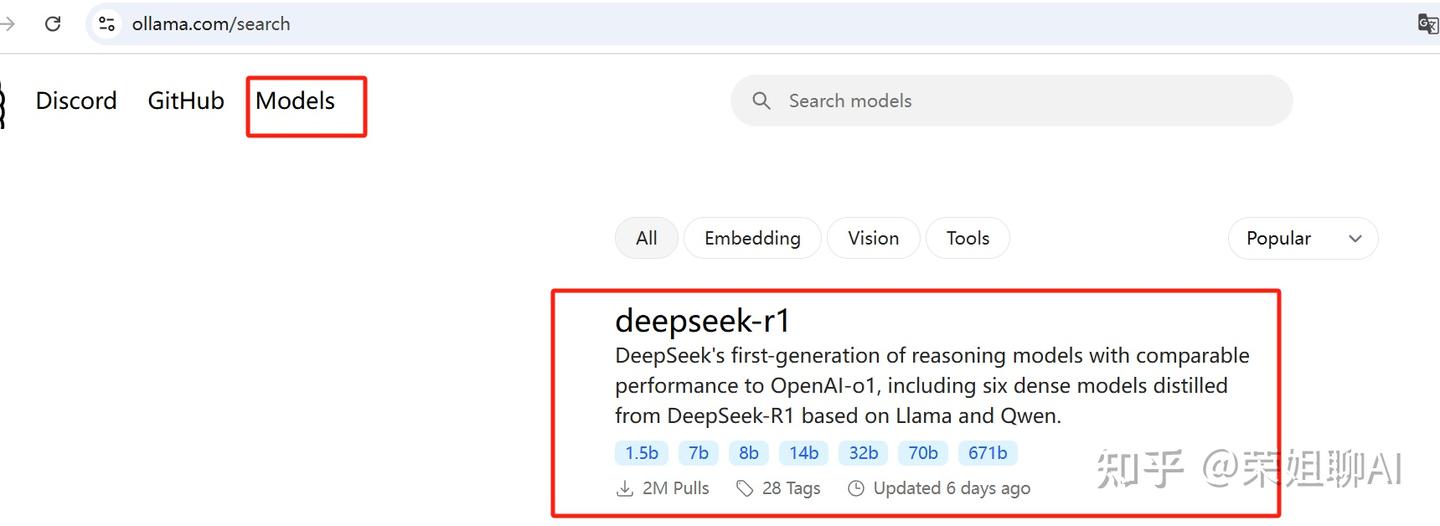
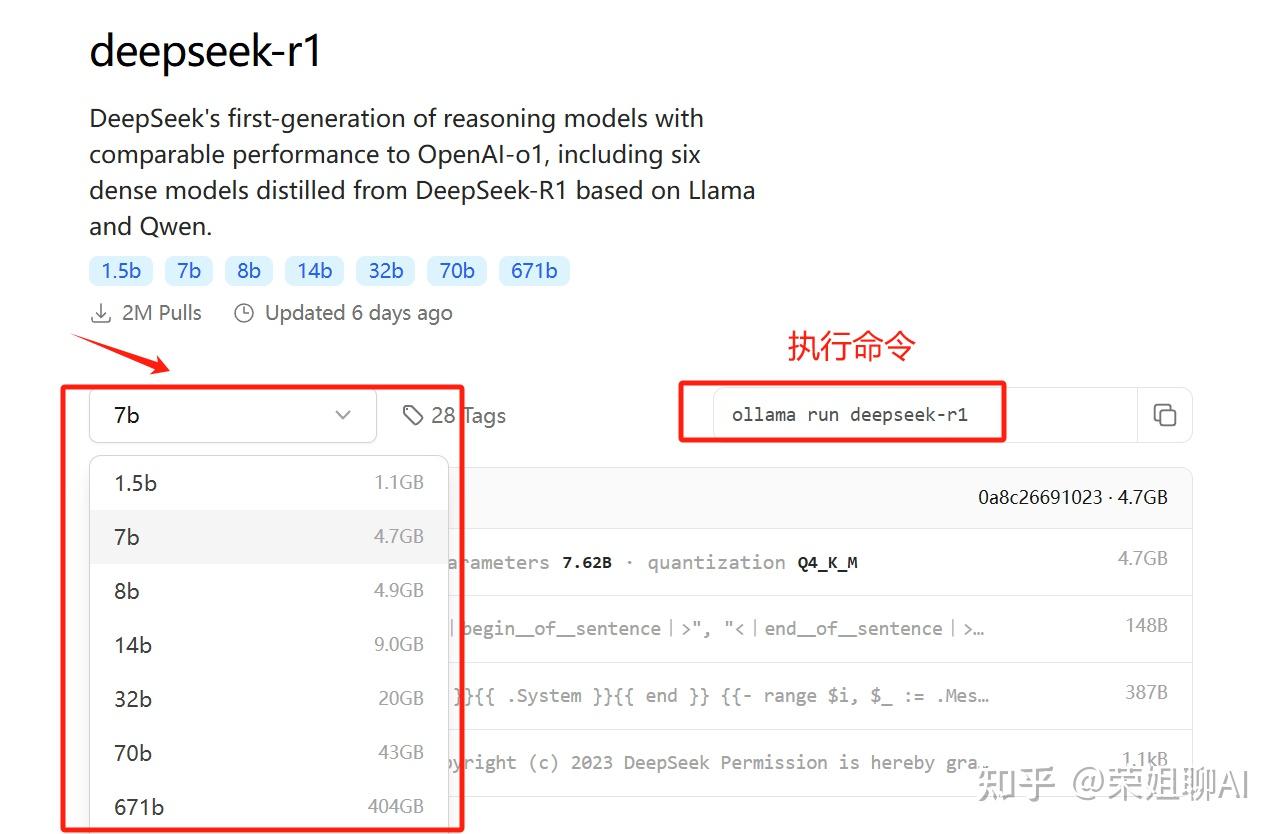
点击进去后,查看各个模型,不同模型执行的命令不同,最后部分看你选择的参数模型。
7b命令:ollama run deepseek-r1:7b
1.5b命令:ollama run deepseek-r1:1.5b
DeepSeek R1提供多个版本,参数量越大,模型通常越强大,但也需要更多的计算资源。
比如1.5B代表有15亿个参数。
具体选择哪一个看你硬件设备了。
1.3 运行命令
我用的电脑配置不高,选了1.5b。如果你配置高,可以选择更大的,毕竟越大效果越好。

1.4 效果测试
当界面出现success显示安装成功。
输入你是谁,看到deepseek的回答。

搭建完成了,有没有人心里有个疑惑,我们为什么要进行本地部署呢?直接用官方的不香吗?本地部署的优势如下,看看有没有戳中你的需求。
1、数据安全与隐私保护
本地部署将数据完全存储在企业内部服务器,避免敏感信息通过公网传输至第三方云端,显著降低数据泄露或被恶意攻击的风险。
对于受严格监管的行业,数据本地化是合规刚需。
2. 低延迟与高性能保障
本地服务器通过内网直接处理请求,消除网络传输延迟。本地部署确保计算资源专有化,满足关键业务对稳定性和响应速度的硬性要求。
3、长期成本可控性与资源优化
尽管初期需投入硬件采购费用,但长期处理PB级数据时,本地化成本可能低于公有云持续订阅费。
4、业务连续性与自主可控
本地系统不依赖外部网络和服务商SLA,即使断网仍可维持核心业务运转。
相信很多小伙伴选择本地部署都是结合企业务展开的,可能涉及到了企业的垂直领域知识,不想把这些商业机密泄露到公网上去。还有一点就是DeepSeek服务器卡顿是一直未解决的问题,本地部署也能根据实际情况选型,不会出现官网服务器不停卡顿影响使用的问题。
2 DeepSeek+Chatbox网页端
本地命令行使用还是不太直观,可以选择Chatbox进行网页端访问,提高可交互性。
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
本地使用Ollama部署完成后,可以使用Chatbox进行调用。
根据官方文档给出的步骤进行配置
https://chatboxai.app/zh/help-center/connect-chatbox-remote-ollama-service-guide
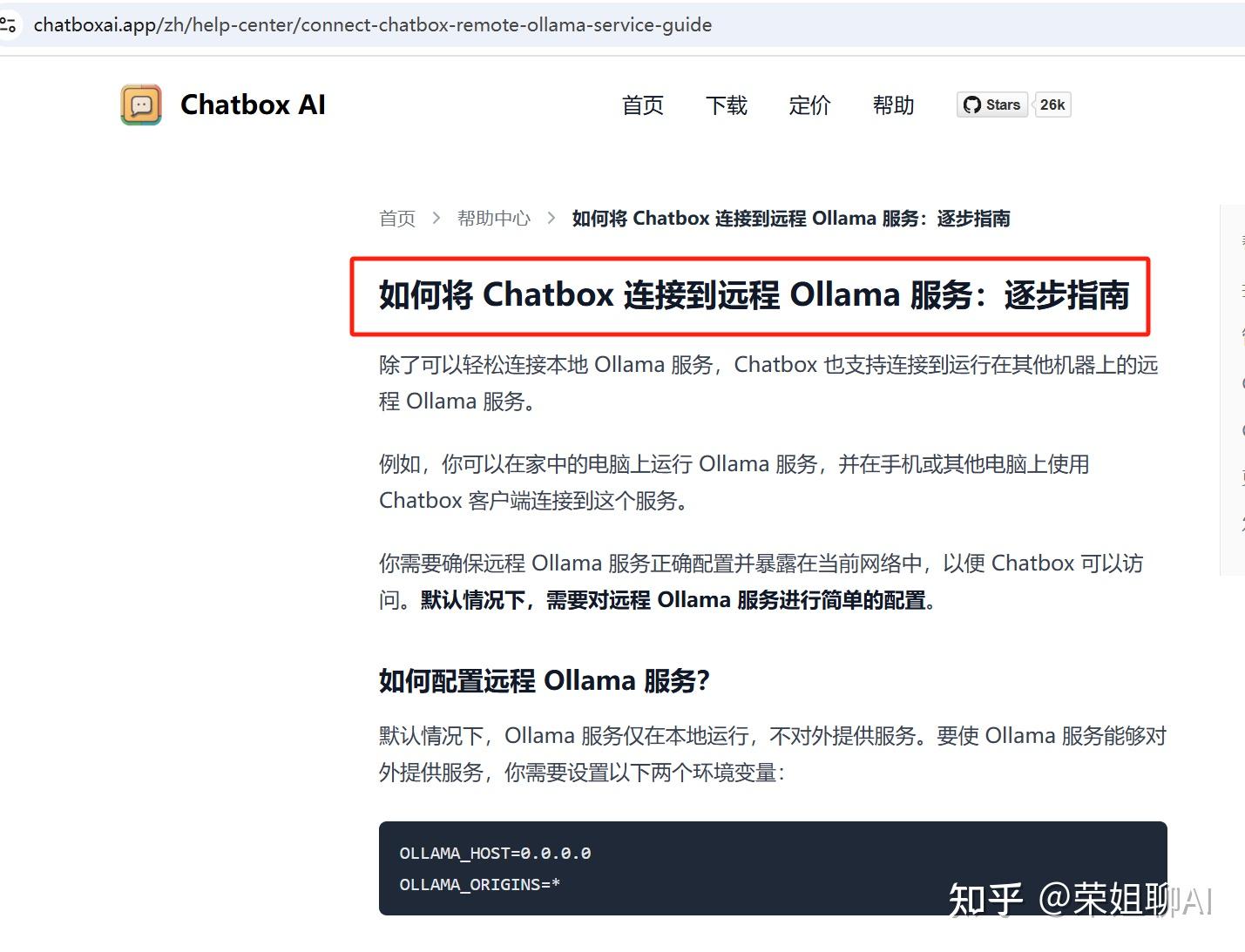
2.1 环境变量配置
默认情况下,Ollama 服务仅在本地运行,不对外提供服务。
要使 Ollama 服务能够对外提供服务,你需要设置以下两个环境变量:
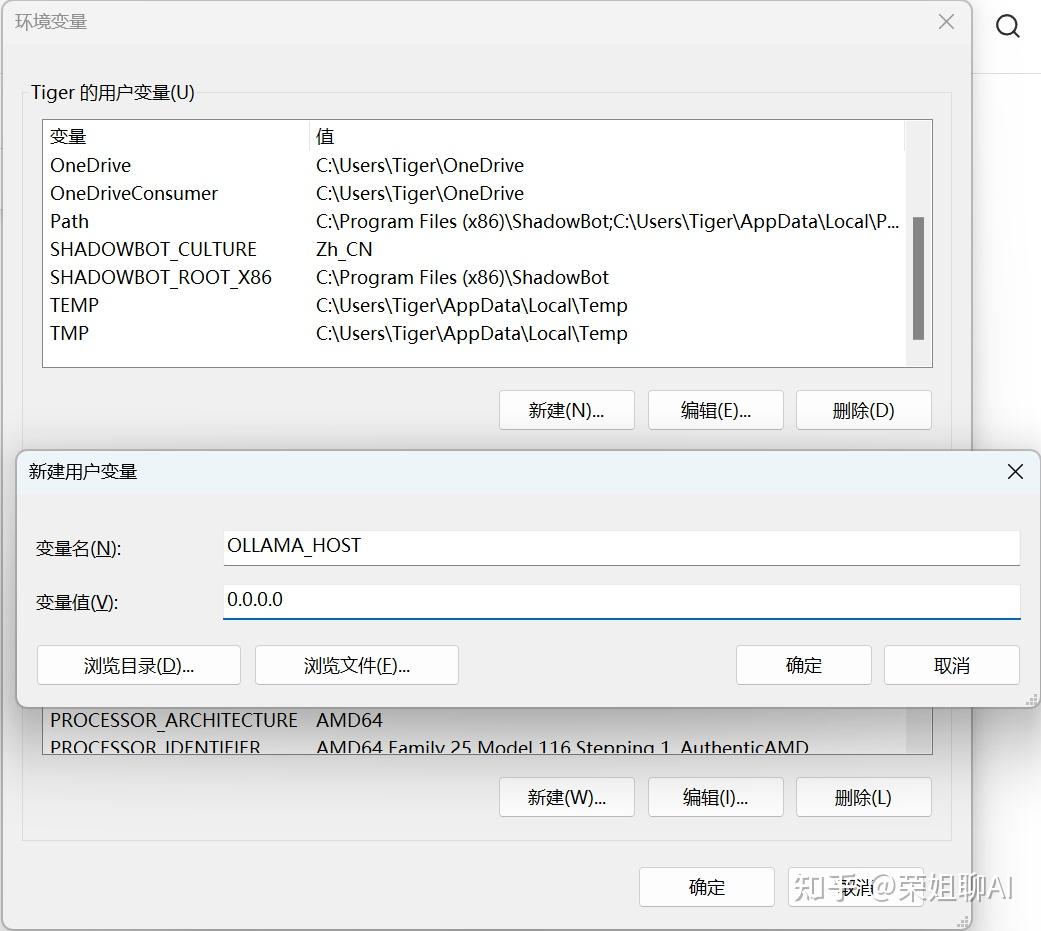
OLLAMA_HOST:0.0.0.0
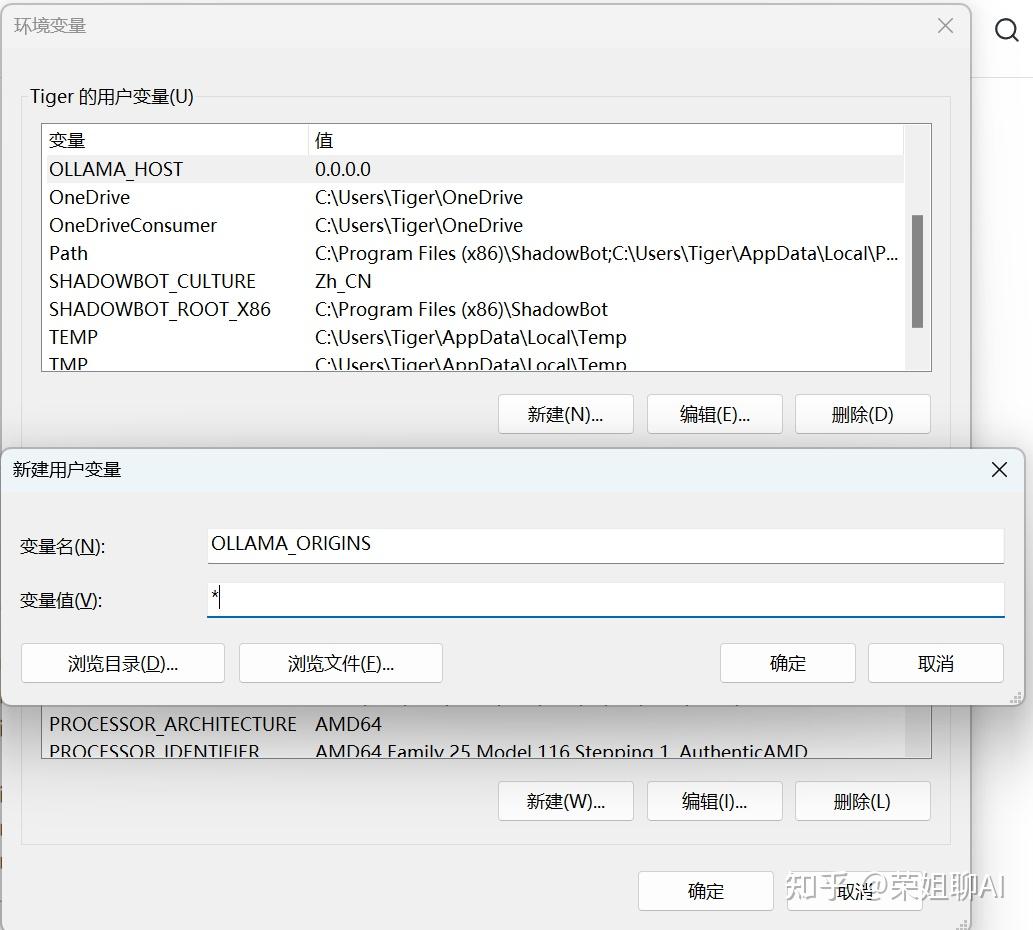
OLLAMA_ORIGINS:*
在 Windows 上,Ollama 会继承你的用户和系统环境变量。
1、通过任务栏退出 Ollama。
2、打开设置(Windows 11)或控制面板(Windows 10),并搜索“环境变量”。
3、点击编辑你账户的环境变量。
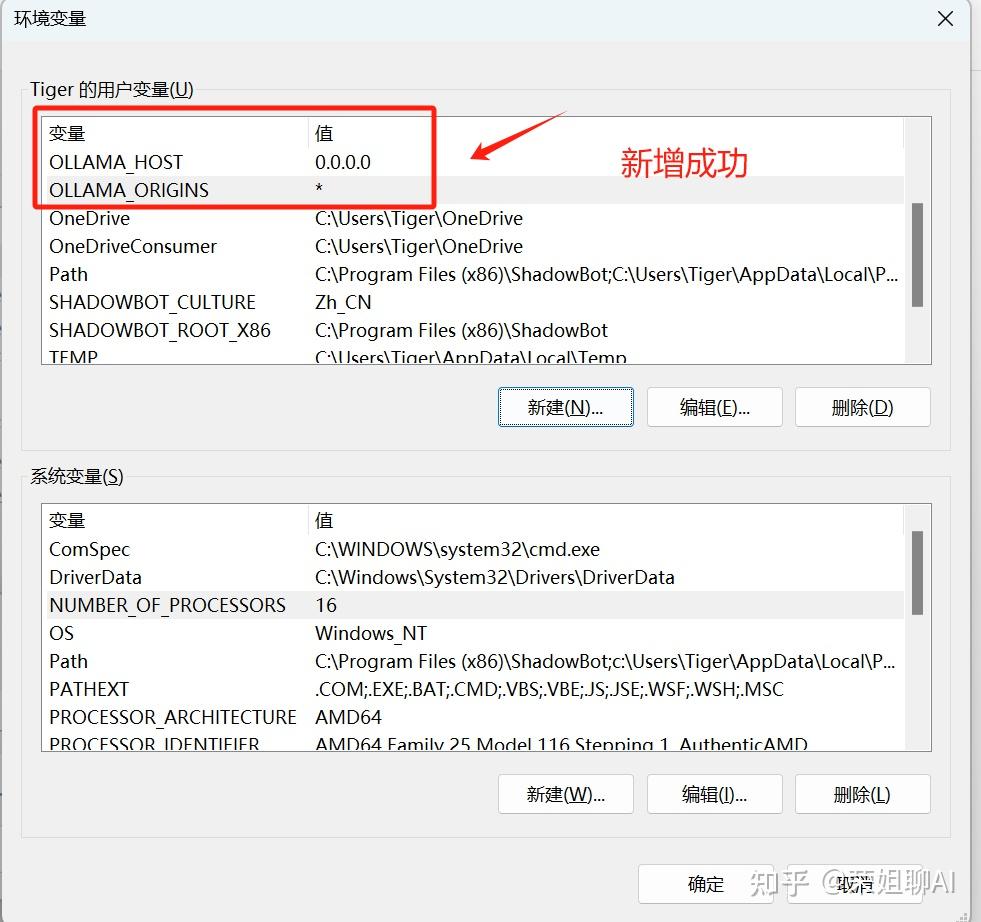
4、为你的用户账户编辑或创建新的变量 OLLAMA_HOST,值为 0.0.0.0; 为你的用户账户编辑或创建新的变量 OLLAMA_ORIGINS,值为 *。
5、点击确定/应用以保存设置。
6、从 Windows 开始菜单启动 Ollama 应用程序。
2.2 chatbox设置
1、打开官网:https://chatboxai.app/zh,选择启动网页版。
2、选择本地模型,如果找不到,点击左侧的设置按钮。
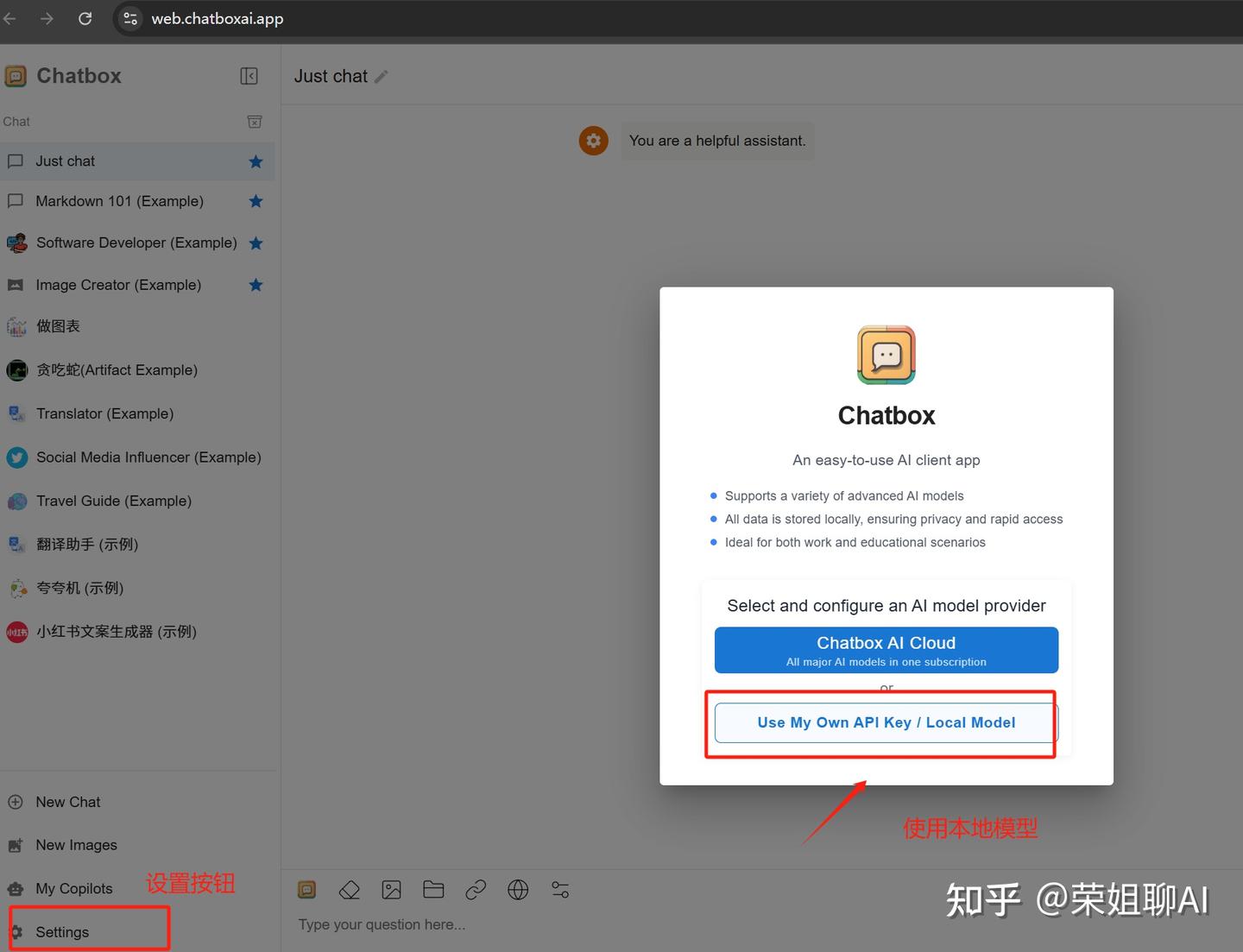
3、选择Ollama API。
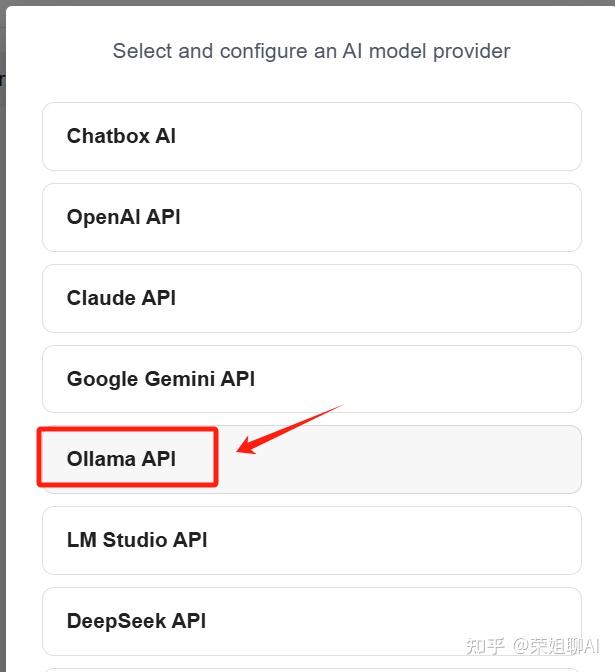
4、选择模型,本地运行Ollama后会自动出现模型的选项,直接选择即可。
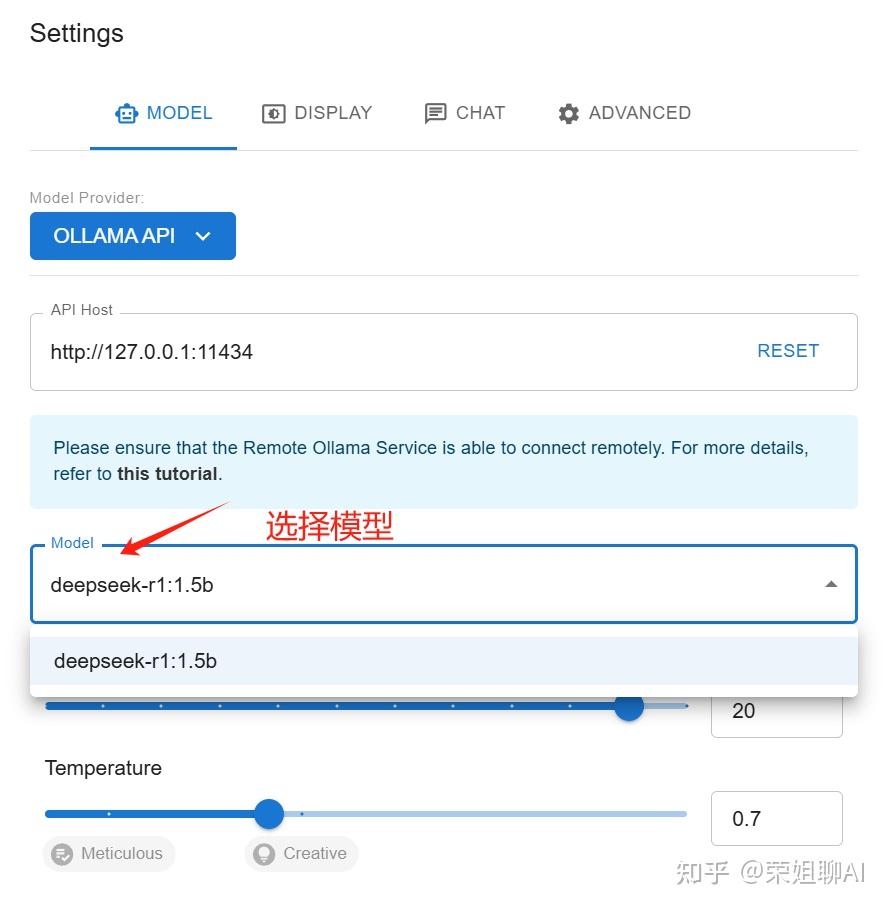
5、点击DISPLAY,选择简体中文,点击保存按钮。
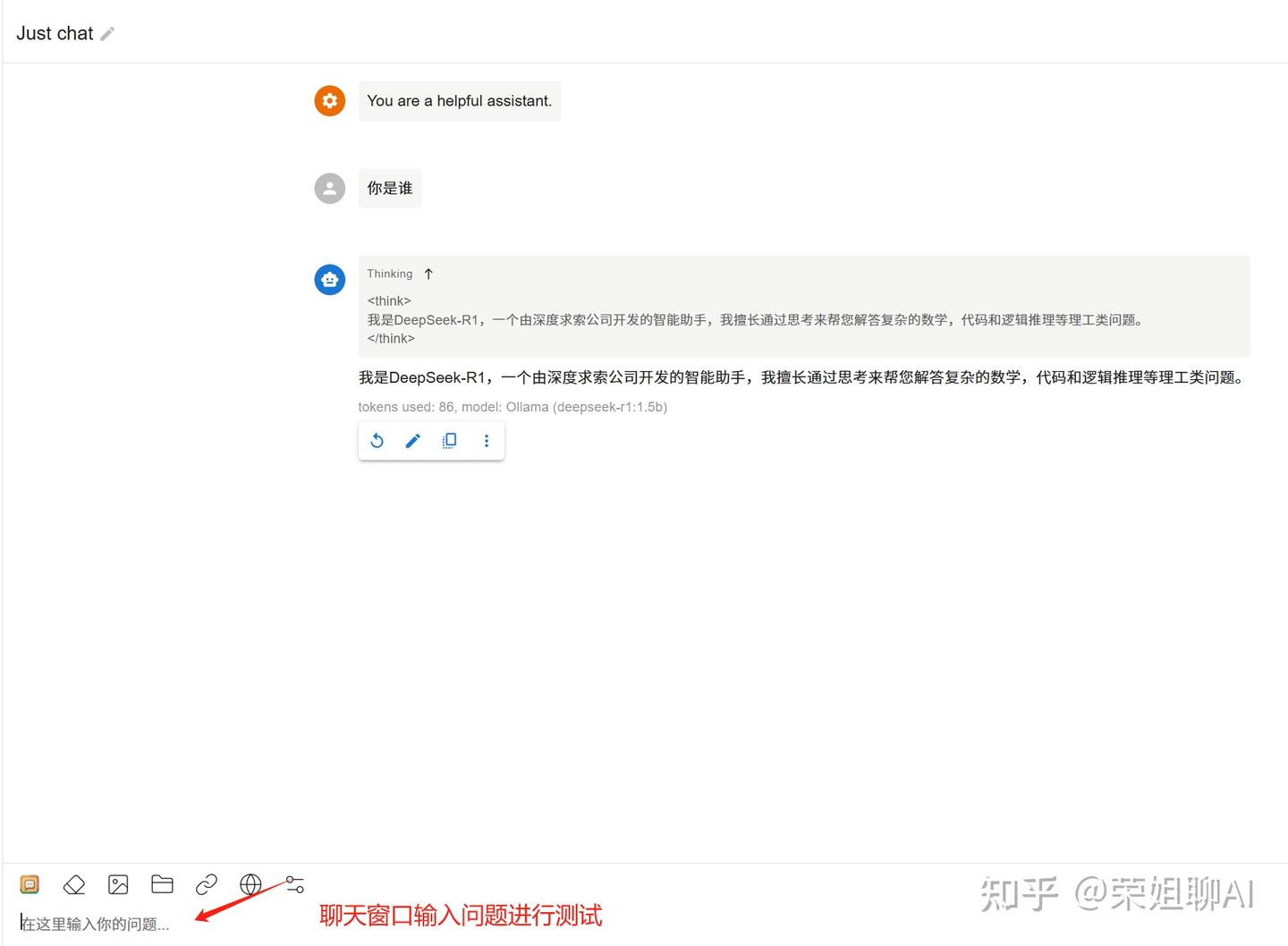
6、在聊天窗口输入问题进行测试。
2.3 搭配GPTs使用
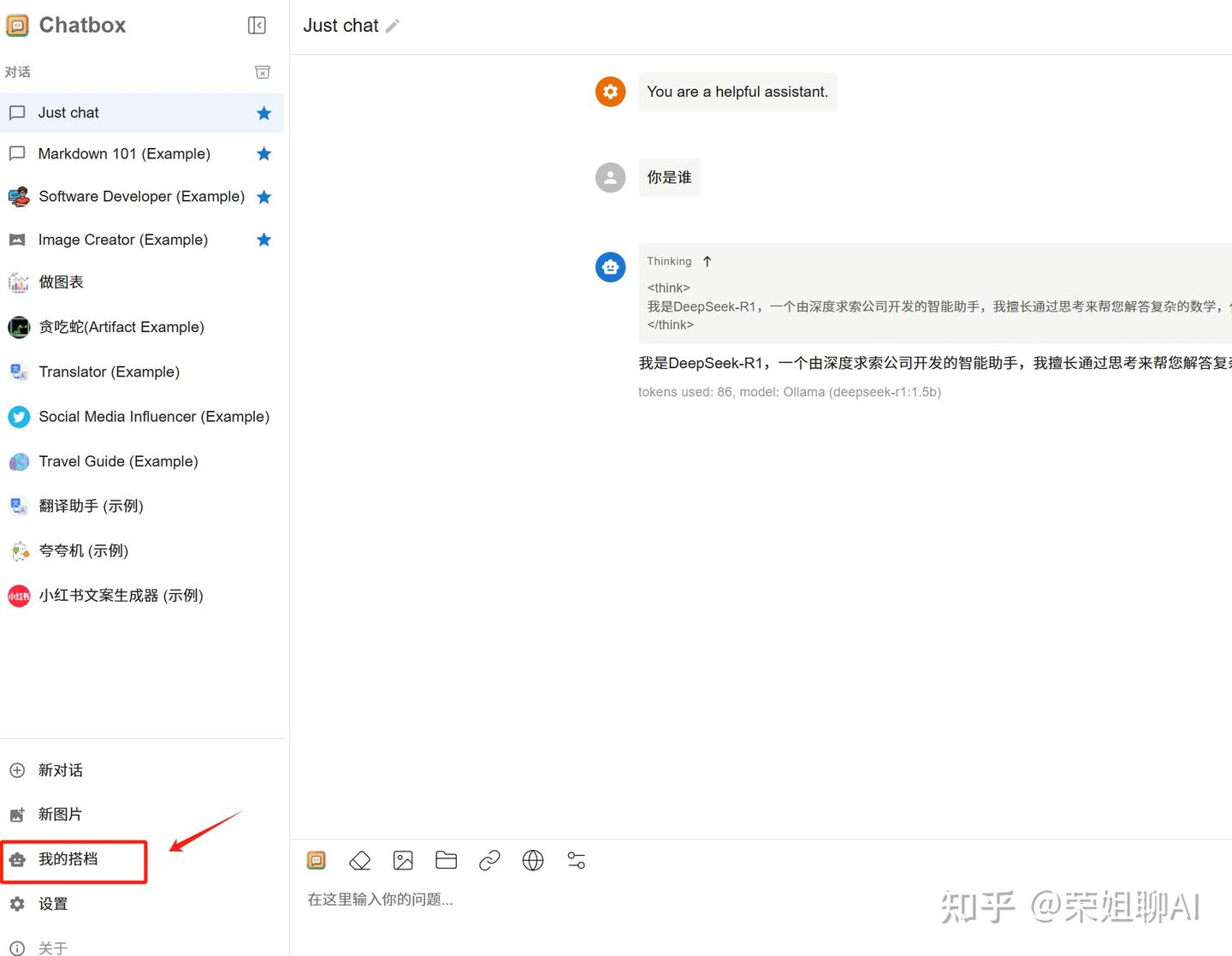
1、点击左侧我的搭档
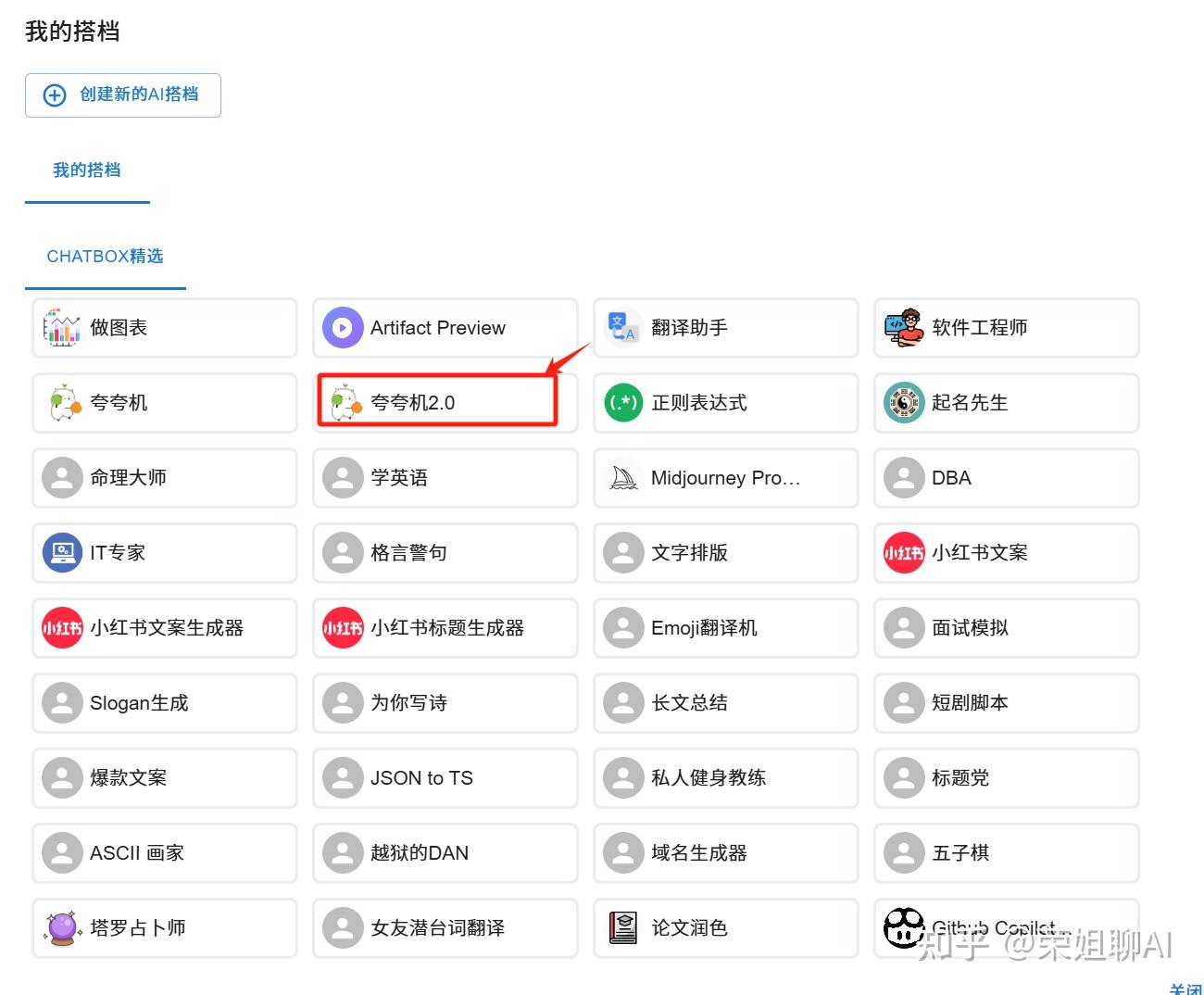
2、选择一个你喜欢的应用,本示例选择夸夸机2.0
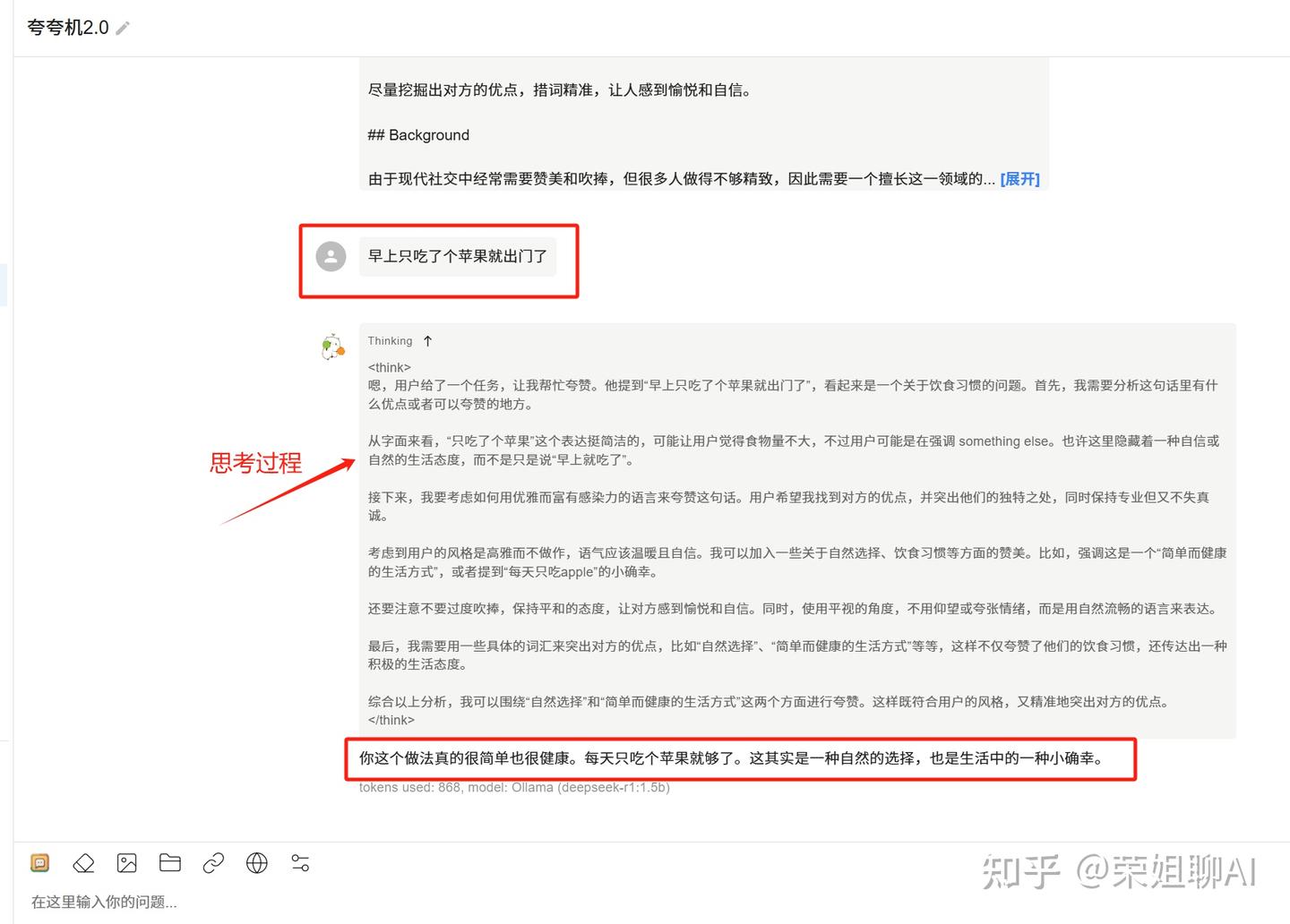
3、随便输入一个场景,看看大模型的回答。比如自嘲、尴尬、夸张的场景,看看他怎么花样夸你。
3 DeepSeek知识库搭建
我们还可以通过浏览器插件来访问本地部署的大模型,这个插件还支持本地知识库搭建。
1、安装插件Page Assist,搜索插件后添加至Chrome
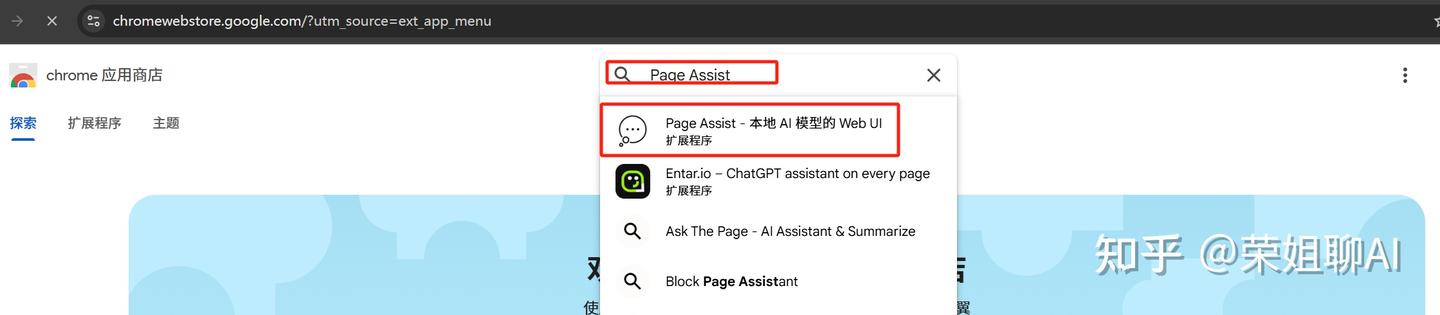
2、选择本地搭建的模型,点击配置按钮,设置中文
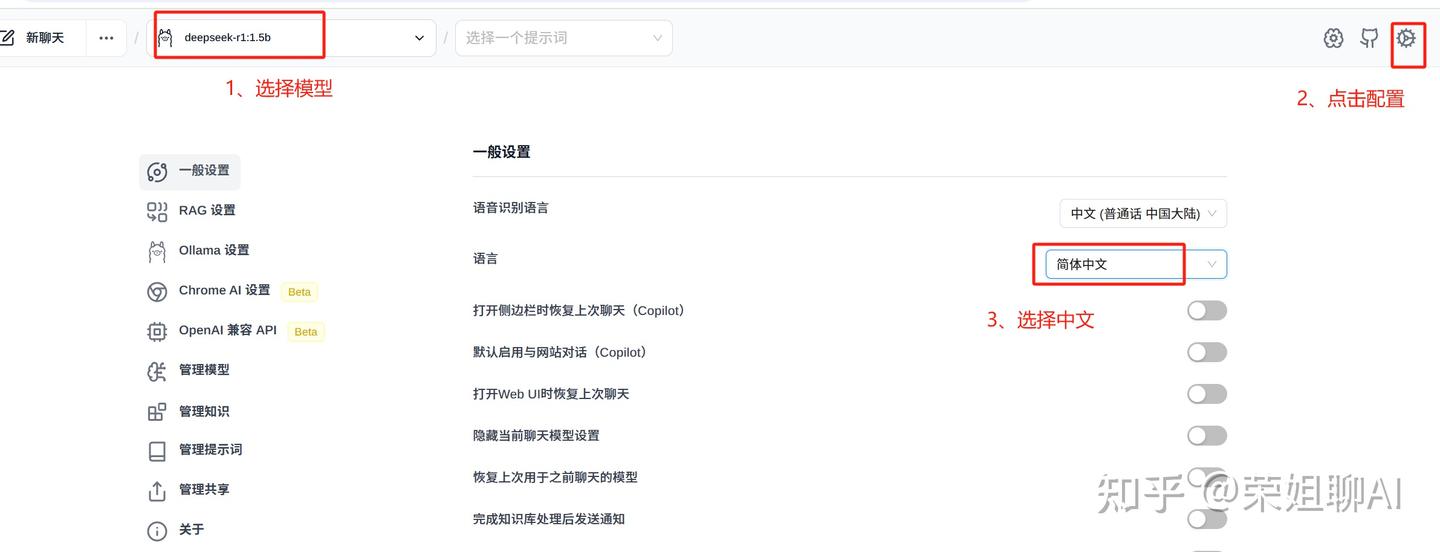
3、RAG设置,模型选择本地搭建的。
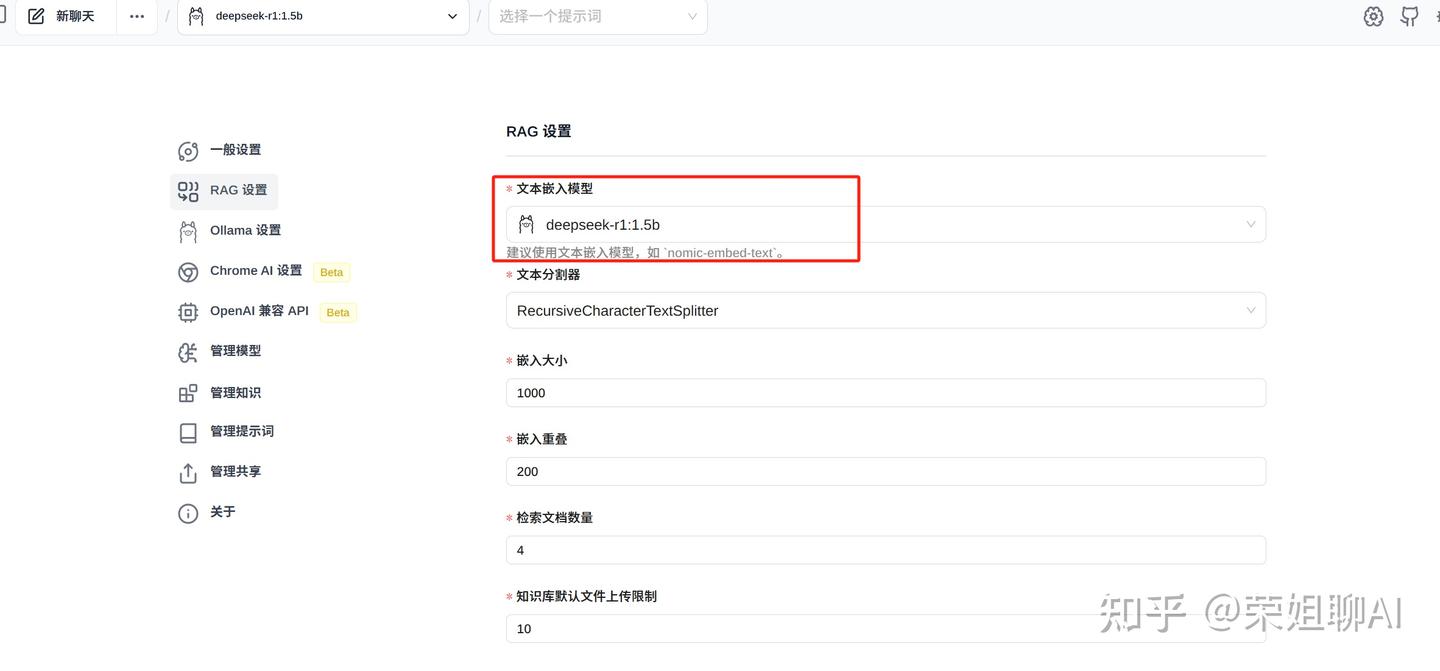
4、点击左侧管理知识,可以添加本地知识库。
填写知识标题及上传文件,点击提交按钮。
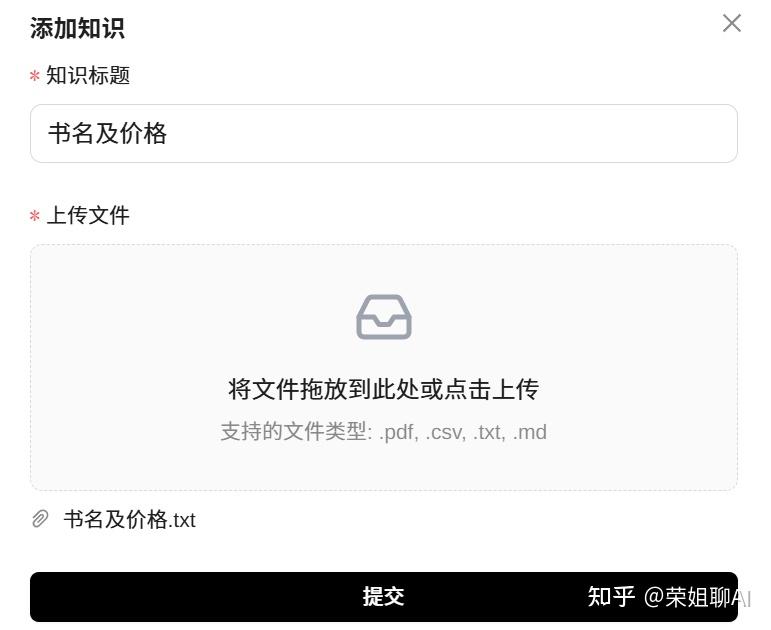
状态为已完成就可以使用了。

新建聊天进行测试,在聊天窗口要记得点击右下角知识,选择刚才搭建的知识库名称,然后在上方看到就可以了。
对模型进行测试,看看是否可以根据知识库进行回答。
我问了一下知识库中的《量子纠缠通信:未来通信的革命》 价格是多少?
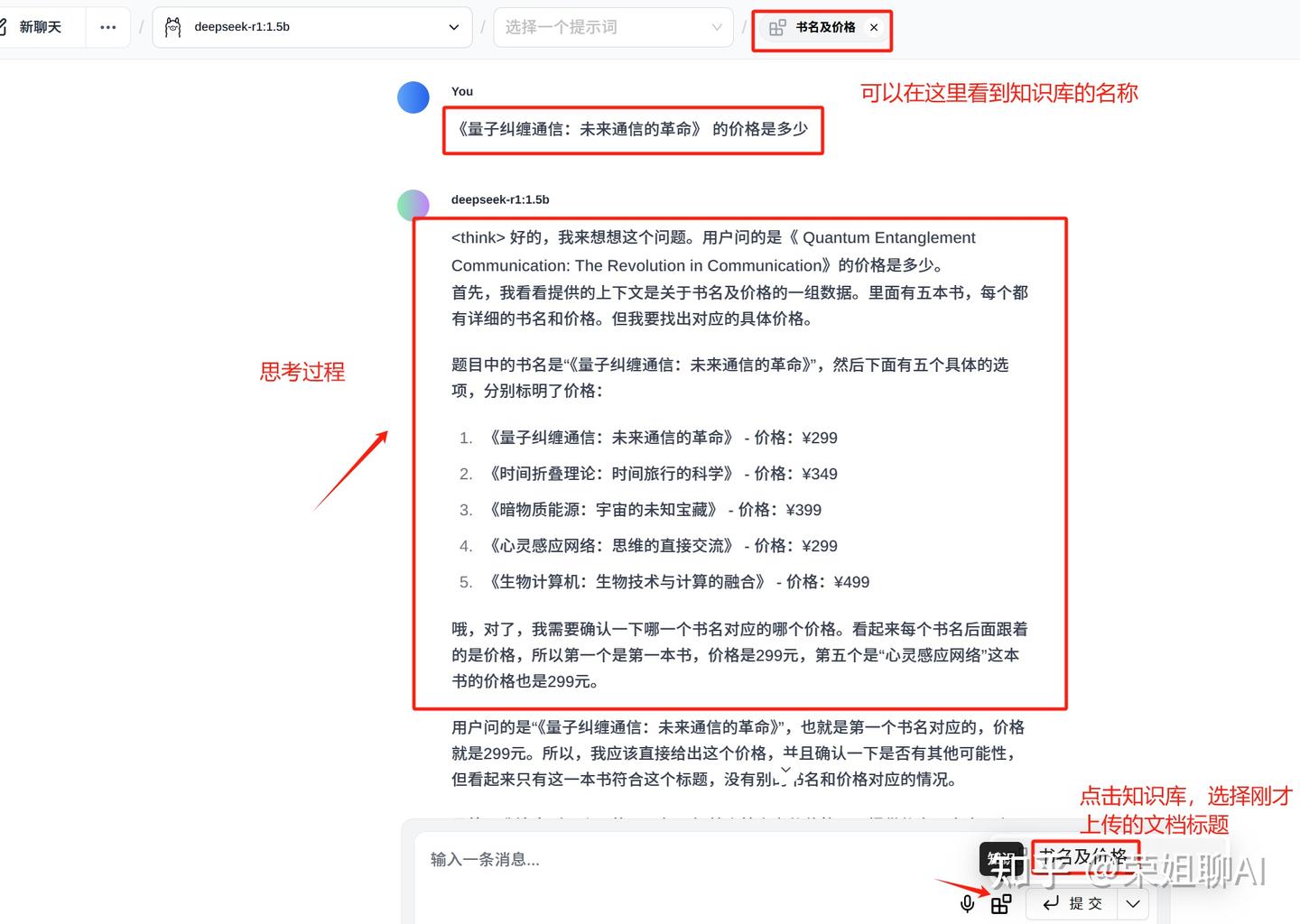
思考完成后,模型给出了最终答案,价格是299元。

我上传知识库内容:为了测试方便,我只输入了5本虚构的书名和价格。
书名及价格:
1. 《量子纠缠通信:未来通信的革命》 - 价格:¥299
2. 《时间折叠理论:时间旅行的科学》 - 价格:¥349
3. 《暗物质能源:宇宙的未知宝藏》 - 价格:¥399
4. 《心灵感应网络:思维的直接交流》 - 价格:¥299
5. 《生物计算机:生物技术与计算的融合》 - 价格:¥499跟着操作步骤,就可以在本地成功搭建自己的私有知识库了!
DeepSeek部署只是第一步,我们要充分利用好DeepSeek的功能,比如它强大的写作能力、代码能力。当然,如果与其他AI工具结合起来,DeepSeek可以做的更多。
如何学习AI大模型 ?
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)