MCP不像想象的那么简单,MCP+数据库,rag之外的另一种解决方案
摘要 MCP(Model Context Protocol)是由Anthropic提出的开放协议,旨在统一大模型与外部数据源的交互标准。该协议通过标准化消息、资源和工具等交互原语,解决数据孤岛问题,使应用只需集成MCP客户端即可调用各类服务。与Function Calling相比,MCP更具通用性和互操作性,支持多数据源和动态发现,形成可复用的工具生态。其核心架构基于客户端-服务器模型,支持多种传
前言
MCP于2024年11月25日由Anthropic官方正式提出,在24年2月份cursor添加mcp功能支持的时候,才一下子被广大开发人员面前。3月份的时候,又看到各种推文,当时就想不就是一个协议么?你这个协议又没有经过各方的认可,无非就是在多了一层标准化。不同公司的标准又不一样,就是多写两行代码的事。随着阿里的入局,我才开始重视,然后国内很多公司都开始支持MCP了。
所以趁着五一假期好好的深入学习下。
什么是MCP
MCP 是一个开放协议,它为应用程序向 LLM 提供上下文的方式进行了标准化。它设计出来的目标,主要是统一模型与外部数据源之间的协议,以解决大模型因数据孤岛限制而无法充分发挥潜力的难题。在这个统一标准下,应用端只要集成了MCP client,就没有了开发成本,通过配置可以调用任何已经发布的 mcp server。因此ai应用有了链接万物的。
而qwen3的发布,直接原生支持MCP。我们只要通过配置mcp server,提交给qwen3,就能调用对应的mcp 服务。见 Qwen3 来了!全面超越 DeepSeek R1,原生支持 MCP 最后的代码调用。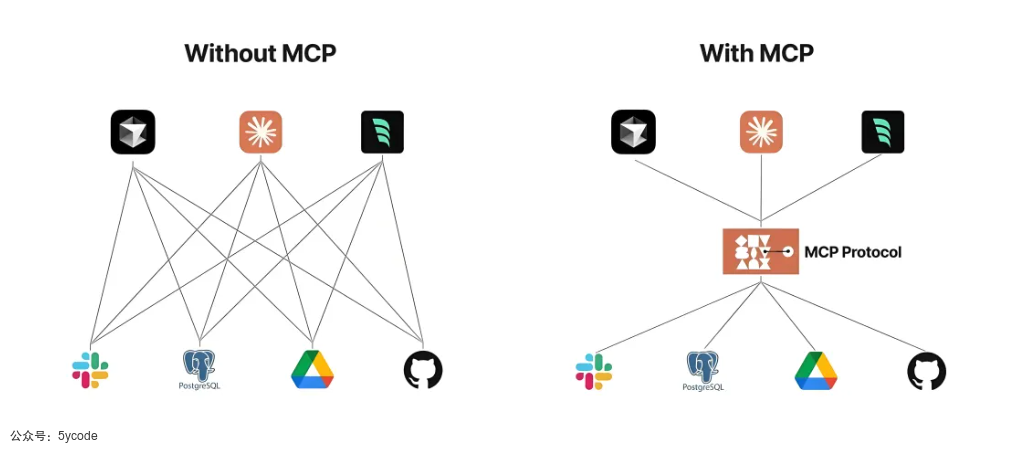
在没有MCP的时候,我们暴露出来的服务api接口,各个应用平台对接都需要进行适配。如左侧图所示。举个例子,在已经经有了高德的api的前提下,各个应用想用高德的api,每个应用都要对接一遍,再有其他的api还要再对接一遍。
而有了MCP以后,底层的各个api只需要将接口适配到MCP协议,我们在各个应用中引入一个MCP client 客户端就ok了,只需要对接一次。对于非开发人员还是非常友好的,解决了调用外部工具的技术门槛问题。
MCP与Function Calling的区别
这里有必要说一下和Function Calling的区别,两者都是为了增强大模型与外部数据的交互。但是MCP 不仅适用于大模型。
| 对比维度 | MCP(Model Context Protocol) | Function Calling |
|---|---|---|
| 性质 | 开放协议,由 Anthropic 发布、社区维护,具备版本管理;标准化定义了消息、资源、工具、提示等多种交互原语 | 功能接口,由 OpenAI(或其他模型厂商)提供,描述函数签名与参数,仅限于该模型家族 |
| 范围 | 通用:支持多数据源(文件、数据库、HTTP API 等)和多功能(Tool、Resource、Prompt、Sampling、Roots、Transports) | 特定场景:侧重“在对话中生成并格式化函数调用 JSON”,主要针对单一函数或工具集合 |
| 目标 | 互操作:通过统一协议接入各种后端,形成可复用、可发现的工具/资源生态 | 扩展模型:让 LLM 在对话中灵活触发外部函数,增强单次交互能力 |
| 实现方式 | 协议驱动:Client 与 Server 按 JSON-RPC over StdIO/HTTP+SSE/WebSocket 进行通信,并支持能力协商与升级 | API 参数:在 Chat Completion 请求中,通过 functions 参数定义函数列表,模型在响应中返回调用指令 |
| 调用发起方 | MCP Client:负责发现工具、封装请求、执行 Server 提供的工具调用,再将结果交给 LLM;模型仅决定调用意图 | LLM:模型直接在对话响应中生成函数调用的 JSON;实际执行需由开发者自己在应用层面接管 |
| 开发复杂度 | 中等:需实现 MCP 客户端或使用 SDK,遵守协议规范;但一次接入后可复用多个 Server 与资源 | 低:只需在 OpenAI API 调用时传入函数定义;但每个新函数都要手动编写签名与解析逻辑 |
| 复用性 | 高:协议化设计,工具/资源可被多种 Client 和 Server 共享;有版本兼容保证 | 中:函数定义与模型绑定,跨项目复用需自行维护相同签名;无协议版本管理 |
| 灵活性 | 高:动态发现、订阅和调用任意工具、资源与提示;支持双向采样(Sampling)与工作流编排 | 有限:仅支持在对话中调用已定义函数;不包含资源订阅、动态提示模板等高级能力 |
| 标准化程度 | 强:官方规范文档+社区演进,多个语言 SDK 与示例;Protocol 版本兼容性规范 | 弱:由单一 API 文档驱动,模型家族更新时可能不兼容;无跨厂商标准 |
| 典型场景示例 | - AI IDE 插件跨项目代码分析 - 企业级 Agent 平台多源数据接入 - 安全合规的资源订阅与实时更新 |
- 调用天气查询 API - 格式化计算函数(加减乘除) - 简单数据库查询辅助回答 |
工作流程
整个工作流程如上图所示。
- 初始化:
MCP Client发送包含协议版本和能力的initialize请求,给MCP ServerMCP Server会返回支持的协议版本和能力MCP Client会发送initialized通知作为确认
- 消息交换:支持Request-Response、双向 Notification
MCP Client根据需求,构建请求消息,并把请求消息发送给MCP ServerMCP Server接收到请求以后,解析请求消息,执行对应的操作,比如调用接口,读取文件,读取数据库等。MCP Server将处理的结果,封装成响应消息,发送给MCP客户端
- 断开连接:
- 双方可以主动关闭连接
- 传输端口、错误终止也会断开
MCP 核心架构
MCP 遵循客户端-服务器架构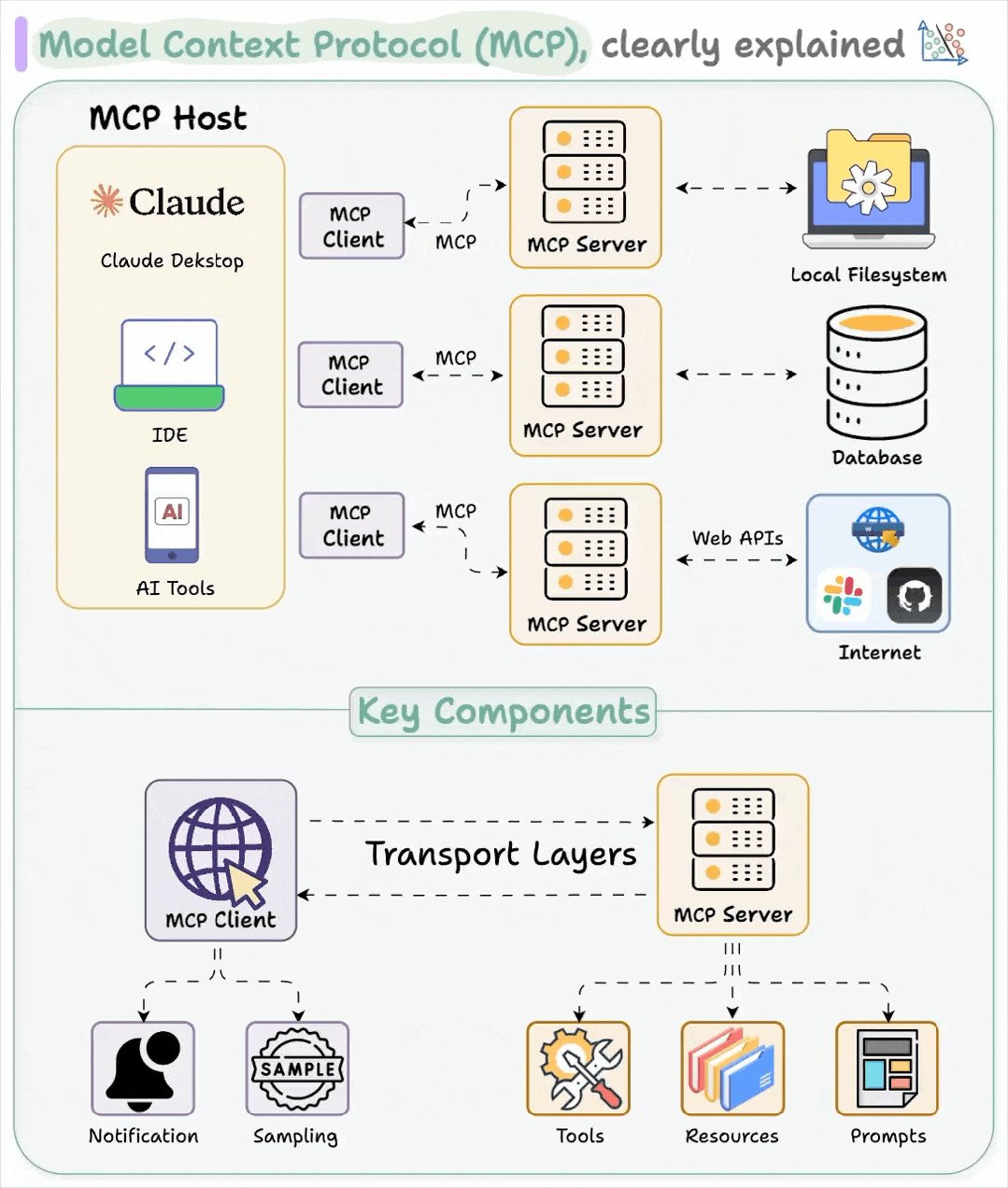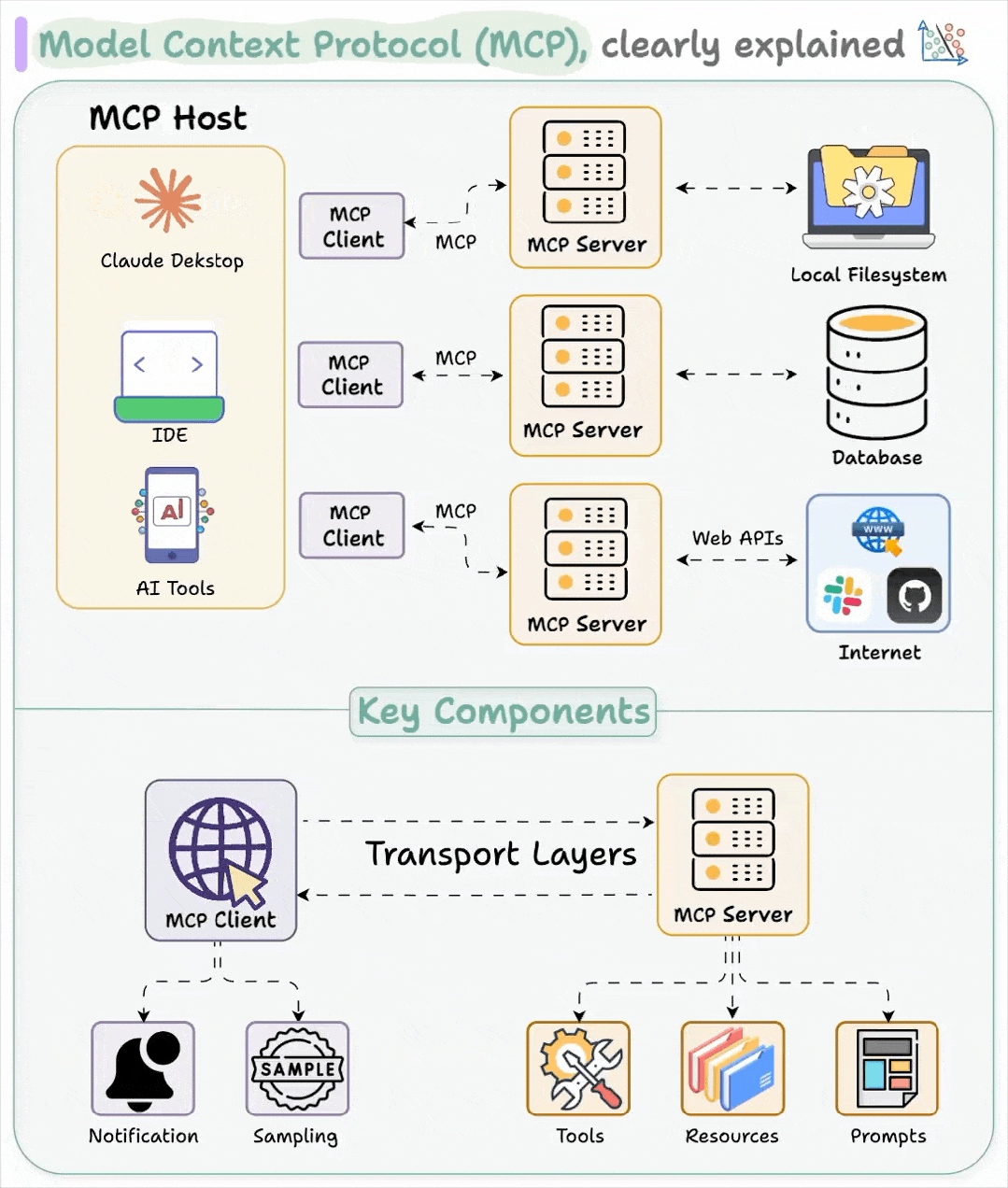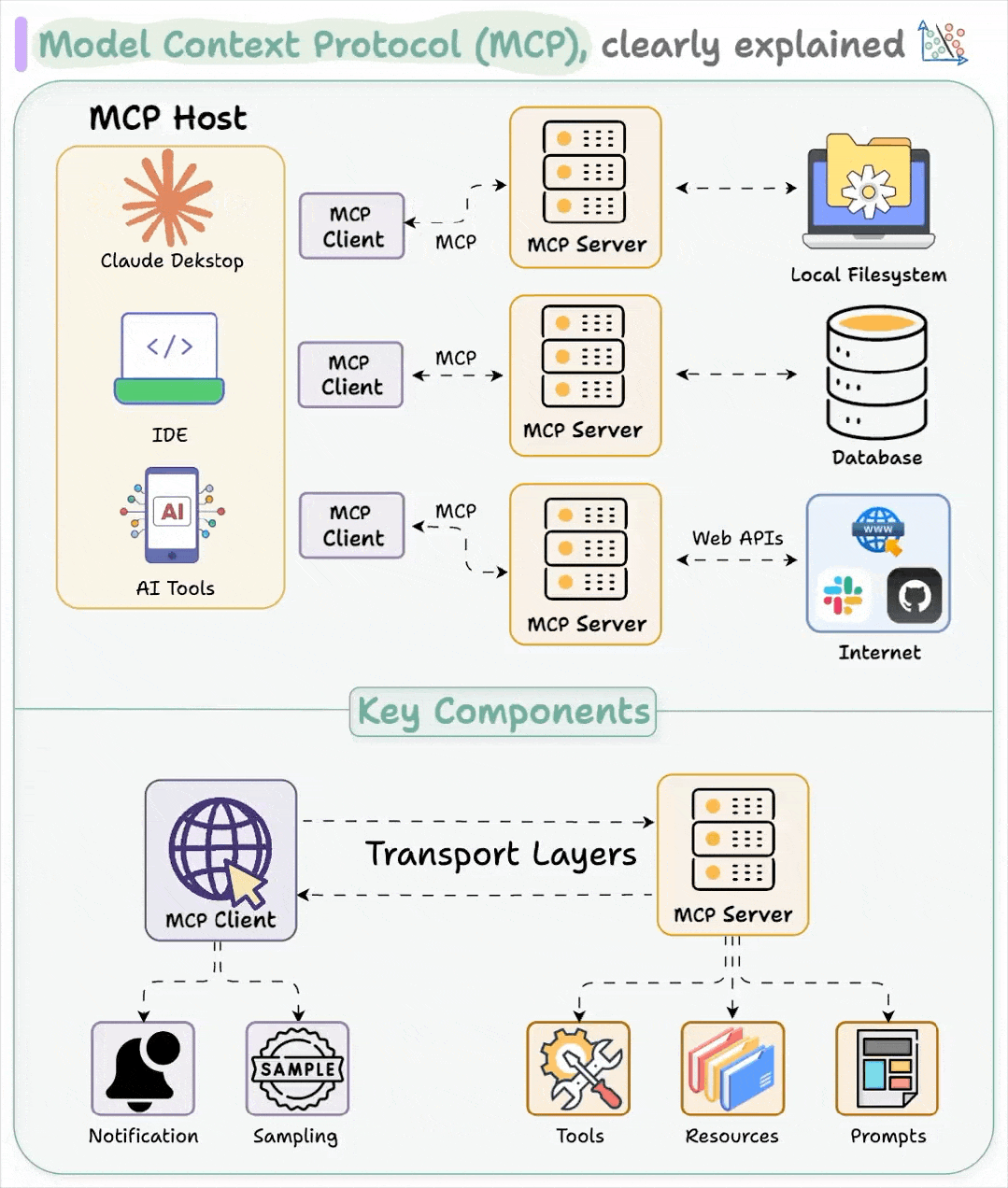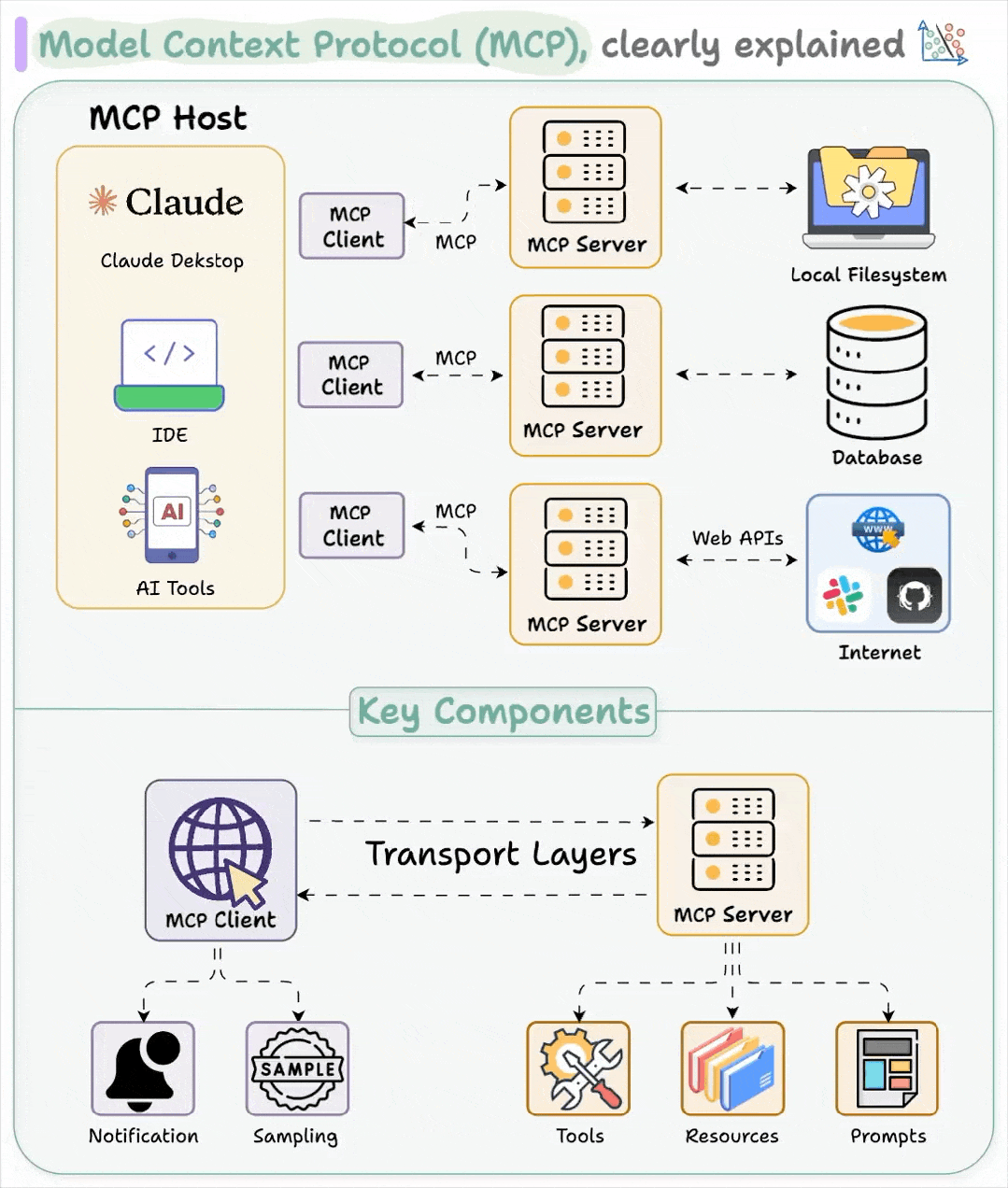
- MCP Hosts :是 LLM 应用, 如上图的 claude,以及我们使用的各种ai工具,内部集成了
MCP client,他们发起链接。 - Clients 在 host 应用中与 servers 保持 1:1 的连接
- 这就是一个长链接,建议在开发的时候,使用池化技术进行优化
- Servers 为 clients 提供上下文、tools 和 prompts
基于MCP的集成架构
协议层
- 负责消息的封装与拆解、请求/响应匹配,以及高层通信模式(消息类型)
传输层
传输层支持多种传输机制,使用 JSON-RPC 2.0 格式。
Stdio传输协议- 基于标准输入输出进行通信
- 适用于本地进程,比如文件系统,在linux中,一切皆进程
- 通过
HTTP+SSE传输协议- 使用 HTTP POST 发送消息,Server-Sent Events 推送通知
- 适合跨网络、需要 HTTP 兼容的场景
- 定义传输
- 可以自定义网络协议,比如可以用WebSocket实现
消息类型
MCP具有以下四种主要的消息类型
Request: 需要对端返回结果的调用Result成功响应 RequestError请求失败时的错误码和信息Notification单向消息,无需响应
Resources
Resources 允许 MCP Server 将文件、数据库记录、API 响应、日志文件、图片等各种数据内容暴露给 Client,为 LLM 提供必要的上下文信息。
资源是 “application-controlled” 的,意味着 Client 决定何时、如何使用资源,包括用户手动选择或自动化策略。
按照定义,一共有两类资源:文本资源和二进制资源
- 文本资源:UTF-8编码
- 源代码
- 配置文件
- 日志文件
- json/xml数据,比如api的响应,数据库记录
- 纯文本
- 二进制资源: base64编码的二进制数据
- 图片
- 音频文件
- 视频发现
- 其他非文本格式
资源发现与读取
- 直接资源
- 服务器通过
resources/list端点公开一系列具体资源,包含uri,name,description,mimeType。
- 服务器通过
- 动态模板
- 对于动态或目录型资源,Server 可提供符合 RFC 6570 的 URI 模板,Client 根据模板构建具体 URI 后再发起读取请求。
- 读取
-
- Client 提交某个资源的 URI,Server 返回包含一组
contents的列表,每项可带text(文本)或blob(Base64 二进制)。
- Client 提交某个资源的 URI,Server 返回包含一组
- 一次读取请求可返回多个资源(如读取目录下所有文件)。
-
资源更新
- 列表变更通知
- 当 Server 的资源集合发生变化时,发送
notifications/resources/list_changed,Client 可重新拉取最新列表。
- 当 Server 的资源集合发生变化时,发送
- 内容变更通知
- Client 可通过
resources/subscribe订阅某个 URI,Server 在内容变化时发送notifications/resources/updated,Client 再用resources/read获取更新后的内容;取消订阅则用resources/unsubscribe。
- Client 可通过
Prompts
在 MCP 中,Prompts 是服务器暴露给客户端的一组可复用的提示模板和工作流,用于统一、标准化与大型语言模型(LLM)的交互。服务器通过 prompts/list 和 prompts/get 两个 JSON-RPC 接口,向客户端公开可用的提示项(包括名称、描述和参数定义),客户端在用户触发时填充参数并向 LLM 发送生成请求。通过参数化、上下文嵌入和多步工作流,Prompts 实现了对复杂操作的封装与复用,并可在客户端以快捷命令、上下文菜单、表单等 UI 形式展现,大大提升了 LLM 应用的一致性与可用性。
发现与使用
发现
客户端通过调用 prompts/list,服务器返回所有可用 Prompt 的元数据列表。
// 请求
{
method: "prompts/list"
}
// 响应
{
prompts: [
{
name: "analyze-code",
description: "Analyze code for potential improvements",
arguments: [
{
name: "language",
description: "Programming language",
required: true
}
]
}
]
}
- name 是提示词的名称
- description 描述提示词的用户
- arguments 描述该提示词有哪些参数,这些参数是否必填
使用
客户端调用 prompts/get,传入 name 与对应的 arguments,服务器返回用于 LLM messages
// 请求获取
{
method: "prompts/get",
params: {
name: "analyze-code",
arguments: {
language: "python"
}
}
}
// 服务器响应
{
description: "Analyze Python code for potential improvements",
messages: [
{
role: "user",
content: {
type: "text",
text: "Please analyze the following Python code for potential improvements:\n\n```python\ndef calculate_sum(numbers):\n total = 0\n for num in numbers:\n total = total + num\n return total\n\nresult = calculate_sum([1, 2, 3, 4, 5])\nprint(result)\n```"
}
}
]
}
Tools
MCP Server 能够将任意可执行操作封装为函数接口,供客户端发现与调用。
- 工具调用意图由LLM决定,客户端根据模型输出执行实际调用
- 从简单计算到复杂 API 集成,Tools 均可覆盖,并可修改系统状态或与外部实体交互。
这里最后一步,没问题,qwen3内置mcp client,目前在模型没有支持mcp协议的时候,都是通过外部应用内置mcp client实现。
结构
每个工具都使用下面的结构定义
{
name: "github_create_issue",
description: "Create a GitHub issue",
inputSchema: {
type: "object",
properties: {
title: { type: "string" },
body: { type: "string" },
labels: { type: "array", items: { type: "string" } }
}
}
}
- name: Tool的唯一标识
- description 描述这个Tool是干嘛的
- inputSchema: 调用这个Tool的输入参数的Schema
- properties: Tool需要的所有参数,定义了参数名和类型
Sampling
在 MCP 中,Sampling 允许 Server 通过 Client 向 LLM 发起补全(completion)请求,形成一种“反向调用”模式,既能支持复杂的多步骤智能代理行为,又通过“人机在环”设计确保安全与隐私控制
- 反向调用机制:Sampling 让 MCP Server 能主动向 Client 请求 LLM 补全,而非仅在 Client 发起时调用,扩大了协议的灵活性与支持多方交互的能力。
- 人机在环设计:通过在请求和补全阶段都引入 Client 审核,确保用户对提示词和生成结果拥有修改或拒绝的权利,强化安全与隐私保护。
- Agentic 行为支持:Sampling 是实现智能代理(agentic workflows)的关键,使 Server 可以动态读取资源、决策、生成结构化数据并执行多步任务。
通过Sampling 让整个流程可人为控制,通过交互式确认,让整个生成过程更可控。
Roots
Roots 是 MCP 中用于限定服务器可操作的上下文边界的机制。客户端在连接时以根 URI(如文件路径、HTTP API 地址等)告知服务器“关注哪些资源”,从而实现对资源范围的清晰划分与组织管理。
举个栗子:当我们开发代码的时候,我们使用一个MCP Server,用于读取项目文件,我们不可能让让MCP Server读取所有的文件,也不可能一个工程开发一个MCP Server,怎么办?我们开发MCP Server的时候,把工程路径给它,它只处理这个工程里的文件即可,这样就限定了边界。
当然MCP Server并不是只能处理当前目录下的文件,它可以处理任何目录,但是没有意义了。
虽然不是一个强制性约束,当时在开发的MCP Server的时候,建议遵循该约束。
使用MCP 查询数据库
server端配置
我使用mysql_mcp_server 作为mcp server。
https://github.com/designcomputer/mysql_mcp_server
要求
uv
python>=3.11
mcp>=1.0.0
mysql-connector-python>=9.1.0
安装uv
#macos或 linux安装,没有curl就用get
curl -LsSf https://astral.sh/uv/install.sh | sh
wget -qO- https://astral.sh/uv/install.sh | sh
# win安装
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# uv验证
uv -V
python环境配置
# 使用uv安装python3.11环境
uv python install 3.11
#创建mcp环境
uv venv mcp
# 激活环境
source mcp/bin/activate
# 验证环境
python -V
# 安装依赖
uv pip install mysql-mcp-server --index-url https://pypi.tuna.tsinghua.edu.cn/simple
Cherry studio
我重度使用cherry studio。使用的v1.2.10版本。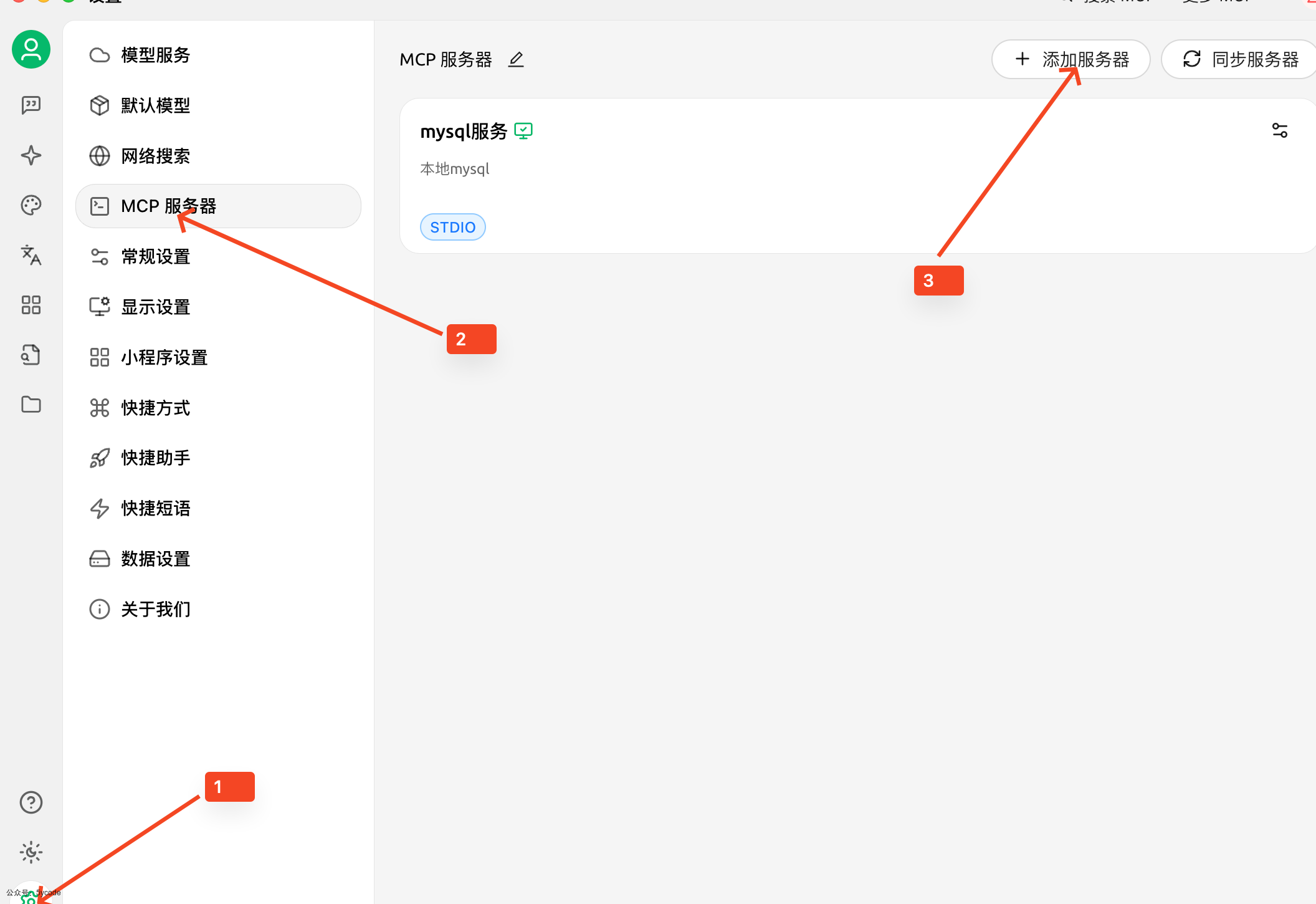
点击1设置,点击2MCP 服务器,点击3添加服务器。
官方给了一个claude和visual studio code两个配置方案。我参考了vs的配置
{
"mcpServers": {
"mysql": {
"type": "stdio",
"command": "uvx",
"args": [
"--from",
"mysql-mcp-server",
"mysql_mcp_server"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "123456",
"MYSQL_DATABASE": "admin"
}
}
}
}
注意官方写的是
servers,其实应该写mcpServers,将对应的配置填写进去
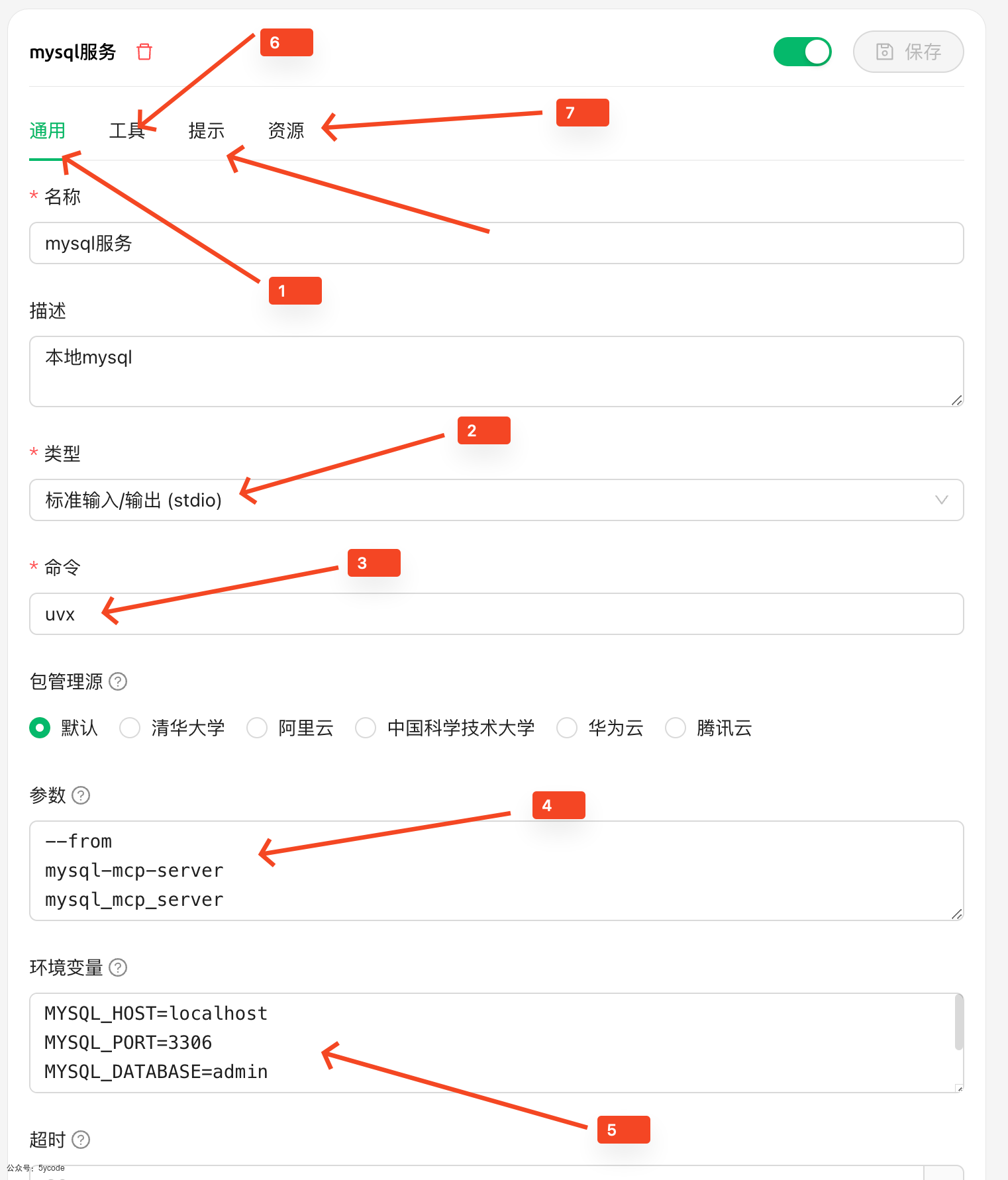
将上面的配置拆解后填进去。注意4参数那里,两个mysql-mcp-server少一个都不行。
通过6可以看该mcp提供了哪些工具,通过7可以看该mcp提供了哪些资源。
资源是这个账户可以查看的表。
使用
在聊天框点击箭头指向的位置,添加mysql的mcp服务。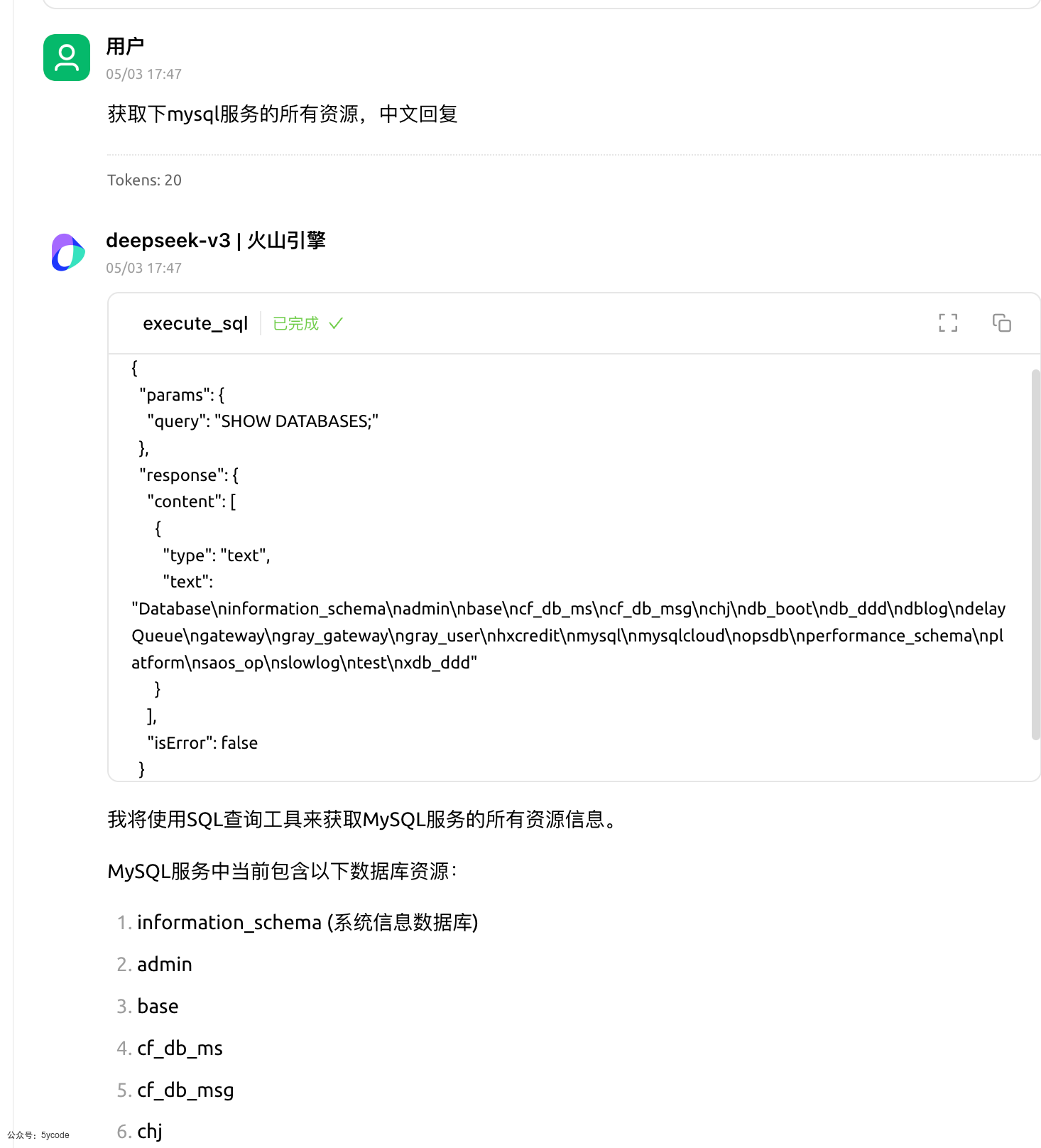
通过cherry studio获取连接的mysql的所有资源。这个时候它会调用mcp的工具执行Show databases,每个模型的能力不一样,最后执行的sql不一样。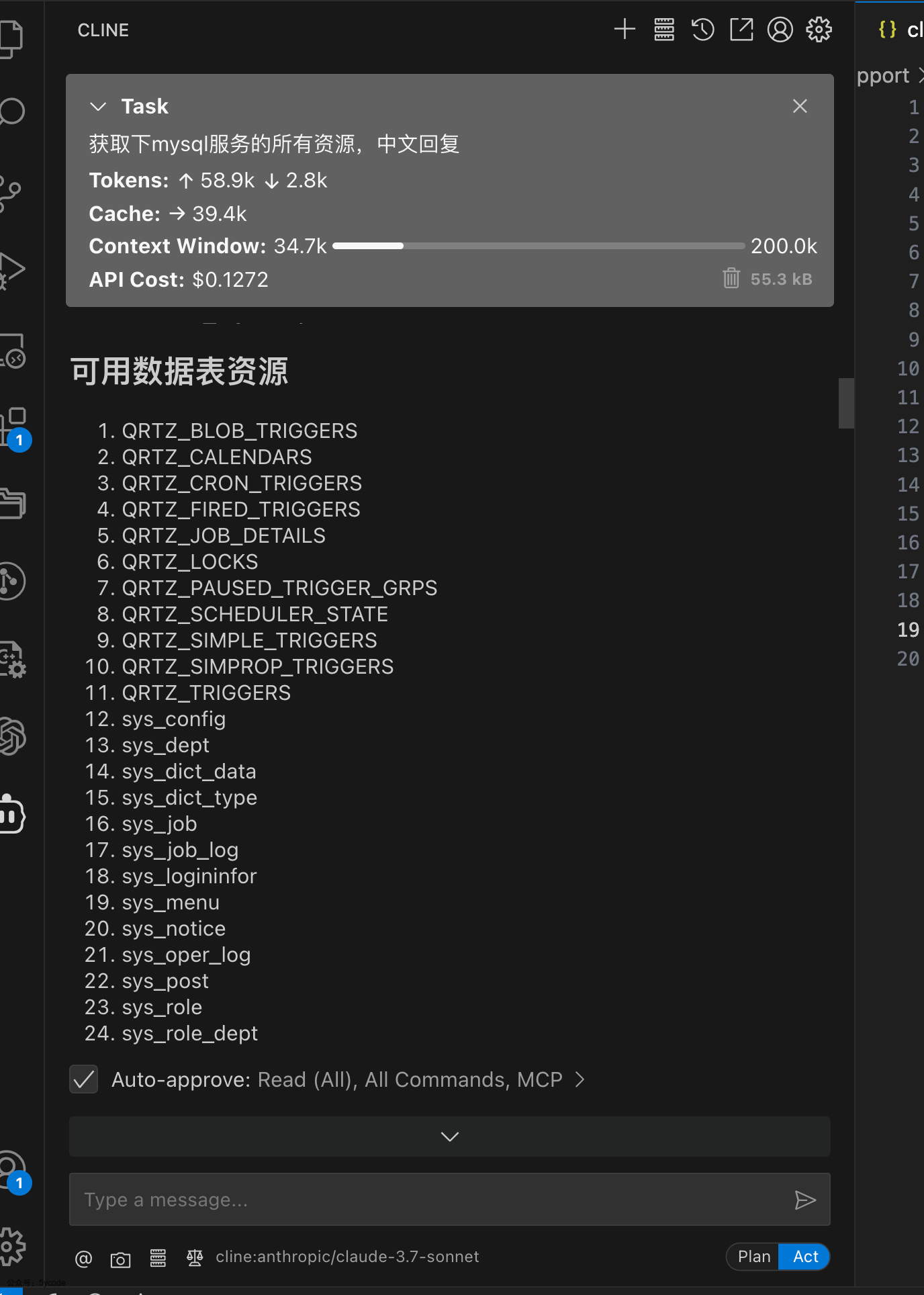
使用cline,就严格处理指定资源内的资源。

我指定数据库让它分析这个库有什么功能,它只是通过表结构进行分析。
当你没有限定它必须依赖查询到的数据的时候,它就开始出现了幻觉。而且瞎掰。
当你限定以后,它完全可以根据你的语义来。
使用同样的提示词,cherry studio中,并没有精准的统计出我想要的信息,不过只花费了560tokens。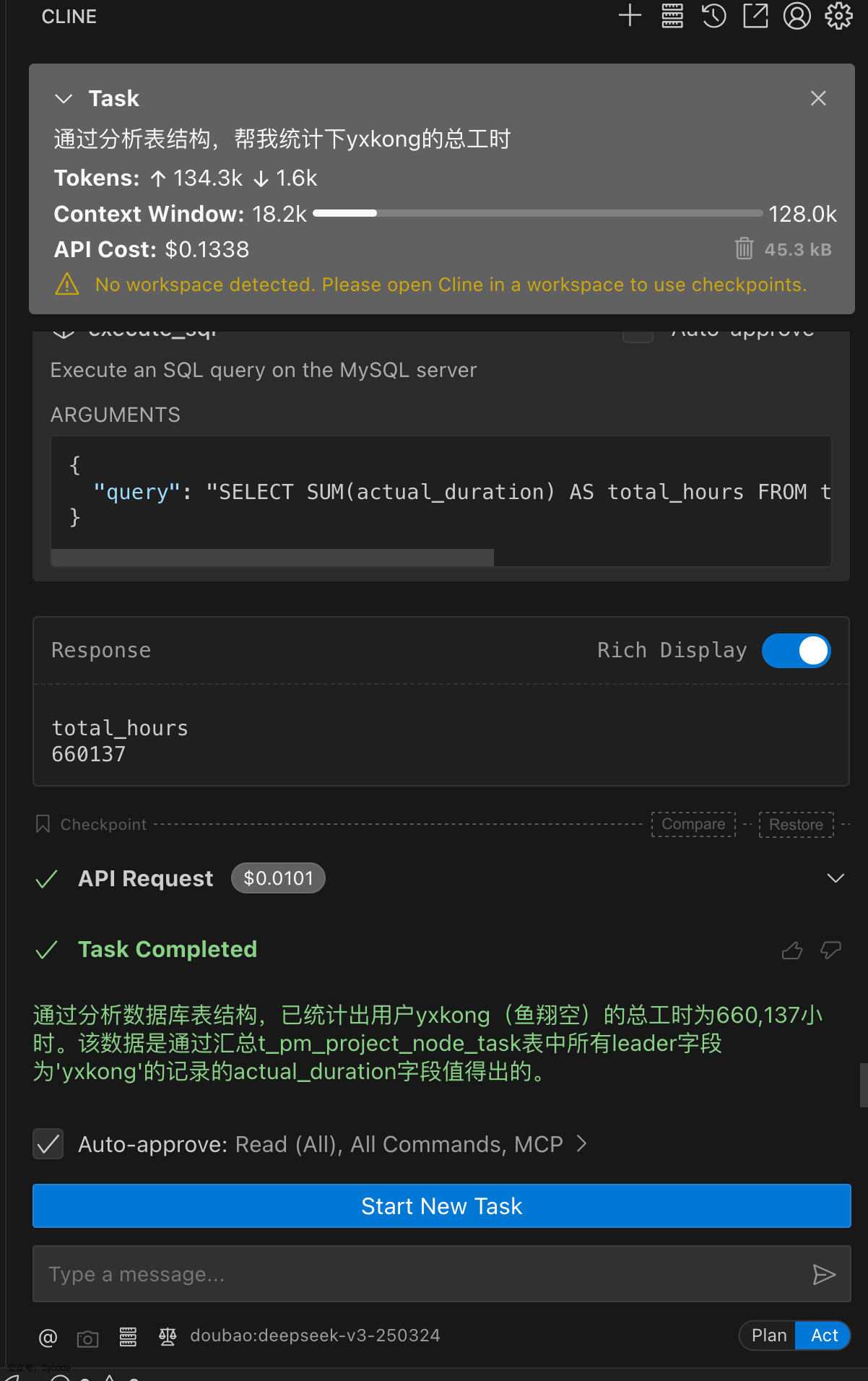
使用cline能完美的查询到我想要的结果。但是一个查询耗费了13万多的tokens。
cline配置
在测试的过程中cline的效果最好,而且支持你修改交互内容。附上cline的配置。
授权
你有哪个账户选哪个。我一般选github
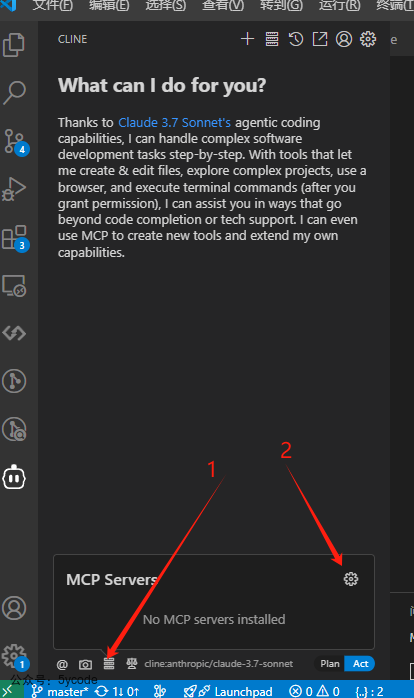
配置mcp服务。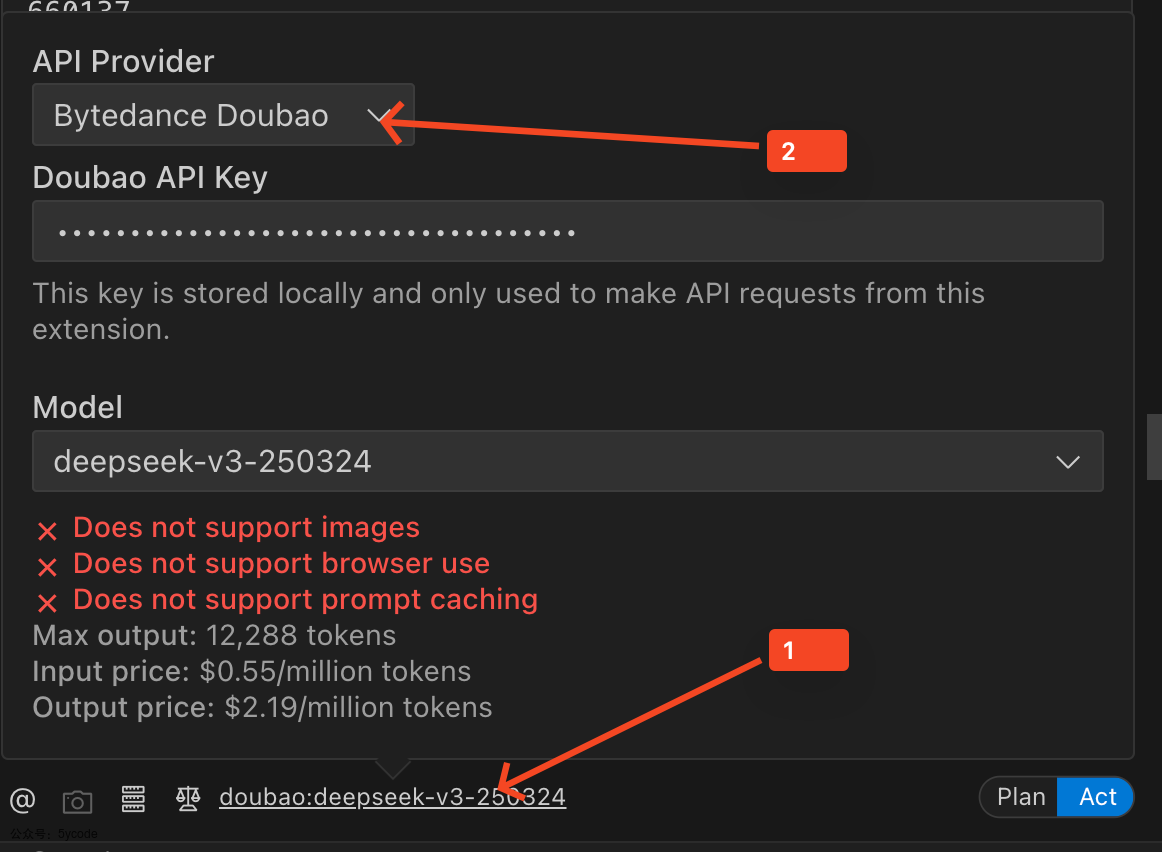
点击1切换模型服务,点击2选择模型供应商,然后根据自己的需求配置。
安全
远程调用,基于http协议,我们可以在请求mcp server之前,先获取一个access_token,然后把access_token作为交互的凭证,等退出以后清空,访问的时候,动态续期。后端可以设置过期时间。
MCP常用地址
文档
- MCP 官网: https://modelcontextprotocol.io/introduction
- 中文版文档地址(机器翻译的,可读性有点差): https://mcp-docs.cn/introduction
综合性网站
- https://mcp.so/
servers 地址
工具
后记
- MCP 不仅仅是一个标准化协议,它提供了一套解决方案。如果大模型实现了它,基本上通过自然语义+MCP Server就能完成各种工作流。
- MCP能提供各种资源,真正好不要,还要看应用或者LLM如何组织
- 在测试的过程
cline消耗的tokens是最多的,基本上一个任务10万左右的tokens,但是效果是真的不错。Cherry Studio消耗的比较少,但是功能比较简单。 - 使用mcp查询数据库,一定要先定,要不然查询的数据太多,会把数据库查崩
系列文章
dify相关
DeepSeek+dify 本地知识库:真的太香了
Deepseek+Dify本地知识库相关问题汇总
dify的sandbox机制,安全隔离限制
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
聊聊dify权限验证的三种方案及实现
dify1.0.0版本升级及新功能预览
Dify 1.1.0史诗级更新!新增"灵魂功能"元数据,实测竟藏致命Bug?手把手教你避坑
【避坑血泪史】80次调试!我用Dify爬虫搭建个人知识库全记录
手撕Dify1.x插件报错!从配置到网络到Pip镜像,一条龙排雷实录
dify1.2.0升级,全新循环节点优化,长文写作案例
dify1.x无网环境安装插件
dify项目结构说明与win11本地部署
Dify 深度拆解(二):后端架构设计与启动流程全景图
dify应用:另类的关键词检索
10分钟搞定企业级登录!Dify无缝集成LDAP实战指南](https://mp.weixin.qq.com/s/qKT80Z9giIB6fZUfW0ZsJQ)
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
RAGFlow爬虫组件使用及ragflow vs dify 组件设计对比
从8550秒到608秒!RAGFlow最新版本让知识图谱生成效率狂飙,终于不用通宵等结果了
以为发现的ragflow的宝藏接口,其实是一个天坑、Chrome/Selenium版本地狱
NLTK三重降噪内幕!RAGFlow检索强悍竟是靠这三板斧
从代码逆向RAGFlow架构:藏在18张表里的AI知识库设计哲学
解剖RAGFlow!全网最硬核源码架构解析
深度拆解RAGFlow分片引擎!3大阶段+视觉增强,全网最硬核架构解析
深度拆解RAGFlow分片引擎之切片实现
RAGFlow核心引擎DeepDoc之PDF解析大起底:黑客级PDF解析术与致命漏洞
RAGFlow 0.18.0 实战解读:从 MCP 支持到插件配置的全流程揭秘
ragflow 0.19.0 图文混排功能支持
mcp
MCP不像想象的那么简单,MCP+数据库,rag之外的另一种解决方案
上线3周:告警减少70%!AI巡检分级报告实战(一)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)