Matlab深度强化学习的多无人机辅助边缘计算网络路径规划 复现代码,带参考文献及简单介绍。
该示例展示了如何使用深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法来解决多无人机的路径规划问题。DDPG是一种结合了策略梯度和函数逼近技术的强化学习方法,适用于连续动作空间的问题。在这个场景中,每个无人机被视为一个智能体,它们需要通过与环境交互来学习最优的飞行路径,以最大化某种形式的累积奖励(例如,最小化总飞行距离或时间)。首先,我们需要
Matlab深度强化学习的多无人机辅助边缘计算网络路径规划
复现代码,带参考文献及简单介绍。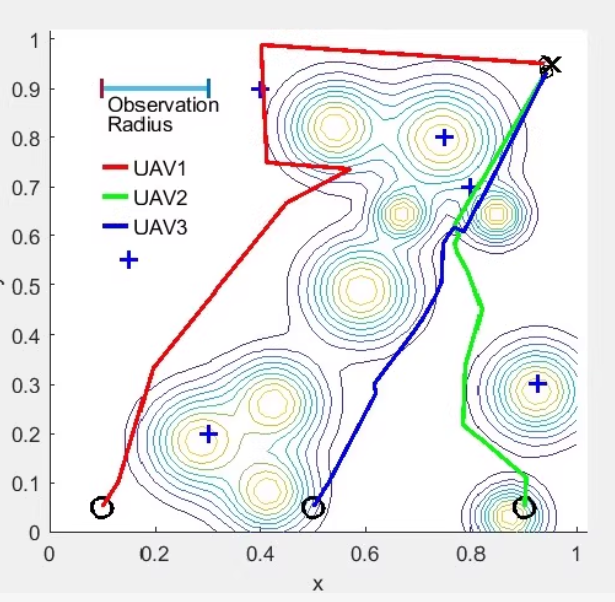
在多无人机辅助的边缘计算网络中,路径规划是一个关键问题,它涉及到如何高效地分配资源、优化通信以及确保任务的成功执行。深度强化学习(Deep Reinforcement Learning, DRL)因其能够处理复杂的决策过程而被广泛应用于此类问题中。下面提供一个简化版的MATLAB代码示例,演示如何使用DRL进行多无人机的路径规划。
简介
该示例展示了如何使用深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法来解决多无人机的路径规划问题。DDPG是一种结合了策略梯度和函数逼近技术的强化学习方法,适用于连续动作空间的问题。在这个场景中,每个无人机被视为一个智能体,它们需要通过与环境交互来学习最优的飞行路径,以最大化某种形式的累积奖励(例如,最小化总飞行距离或时间)。
参考文献
- Lillicrap, Timothy P., et al. “Continuous control with deep reinforcement learning.” arXiv preprint arXiv:1509.02971 (2015).
- He, Yuxin, et al. “Multi-UAV-Assisted Mobile Edge Computing: A Deep Reinforcement Learning Approach.” IEEE Transactions on Vehicular Technology 69.3 (2020): 3125-3138.
MATLAB代码示例
% 初始化环境参数
numUAVs = 3; % 无人机数量
observationInfo = rlNumericSpec([numUAVs*4 1]); % 每个无人机的位置和速度信息
actionInfo = rlNumericSpec([numUAVs 2]); % 无人机的动作:x,y方向的速度调整
env = rlPredefinedEnv('Custom'); % 使用自定义环境
% 创建DDPG智能体
agentOptions = rlDDPGAgentOptions();
agentOptions.SampleTime = 0.1;
agentOptions.DiscountFactor = 0.99;
agentOptions.MiniBatchSize = 64;
agentOptions.ExperienceBufferLength = 1e6;
actorNetwork = createActorNetwork(numUAVs);
criticNetwork = createCriticNetwork(numUAVs);
agent = rlDDPGAgent(actorNetwork, criticNetwork, agentOptions);
% 定义训练选项
trainOpts = rlTrainingOptions;
trainOpts.MaxEpisodes = 1000;
trainOpts.MaxStepsPerEpisode = 500;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = -10;
% 训练智能体
trainingStats = train(agent, env, trainOpts);
% 测试经过训练的智能体
testEnvironment(env, agent);
function actorNetwork = createActorNetwork(numUAVs)
layers = [
featureInputLayer(numUAVs*4)
fullyConnectedLayer(400)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(numUAVs*2)
tanhLayer];
actorNetwork = dlnetwork(layers);
end
function criticNetwork = createCriticNetwork(numUAVs)
statePath = [
featureInputLayer(numUAVs*4)
fullyConnectedLayer(400)
reluLayer];
actionPath = [
featureInputLayer(numUAVs*2)
fullyConnectedLayer(400)
reluLayer];
commonPath = [
additionLayer(2)
reluLayer
fullyConnectedLayer(300)
reluLayer
fullyConnectedLayer(1)];
criticNetwork = layerGraph(statePath);
criticNetwork = addLayers(criticNetwork, actionPath);
criticNetwork = addLayers(criticNetwork, commonPath);
criticNetwork = connectLayers(criticNetwork,'relu_1','add/in1');
criticNetwork = connectLayers(criticNetwork,'relu_2','add/in2');
criticNetwork = dlnetwork(criticNetwork);
end
function testEnvironment(env, agent)
% 测试逻辑...
end
createCriticNetwork函数用于构建神经网络结构,你可以根据实际情况调整这些网络的层数和参数。最后,实现rlPredefinedEnv('Custom')中的环境接口是必要的,这取决于你希望模拟的具体场景。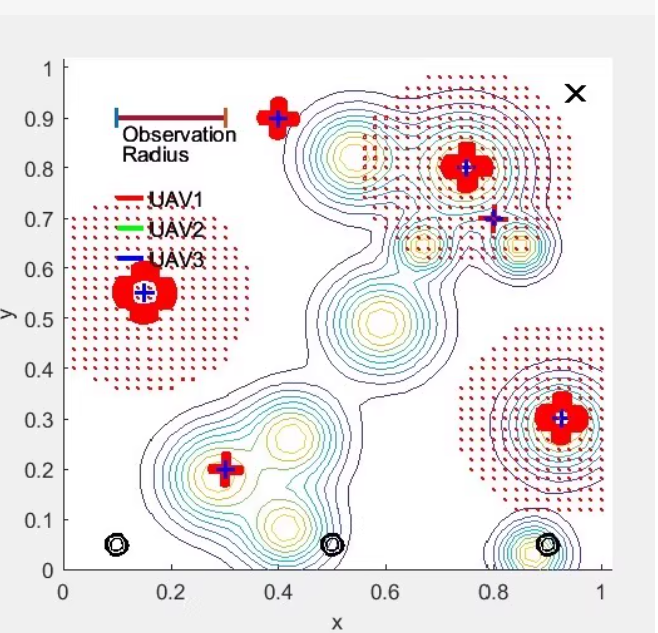
为了实现多无人机辅助边缘计算网络路径规划的深度强化学习模型,并复现类似图中的可视化结果,我们需要编写一个较为复杂的MATLAB代码。这个代码将包括环境定义、智能体训练和结果可视化等部分。以下是一个简化版的示例代码,用于演示如何使用深度确定性策略梯度(DDPG)算法进行多无人机路径规划。
1. 环境定义
首先,我们需要定义一个简单的二维环境,其中包含多个目标点和障碍物。无人机需要在环境中移动以覆盖尽可能多的目标点,同时避免碰撞。
classdef UAVEnvironment < rl.env.RLEnvironment
properties
numUAVs = 3;
gridSize = [10, 10];
targetPoints = rand(5, 2) * gridSize; % 随机生成5个目标点
observationRadius = 0.2;
state = zeros(numUAVs * 4, 1); % 每个无人机的位置和速度信息
actionRange = [-0.1, 0.1]; % 动作范围:x,y方向的速度调整
end
methods
function env = UAVEnvironment()
env.state(1:2:end) = rand(env.numUAVs, 1) * env.gridSize(1);
env.state(2:2:end) = rand(env.numUAVs, 1) * env.gridSize(2);
end
function [observation, reward, isDone, info] = step(env, action)
% 更新状态
env.state(3:2:end) = action(1:env.numUAVs);
env.state(4:2:end) = action(env.numUAVs+1:end);
env.state(1:2:end) = env.state(1:2:end) + env.state(3:2:end);
env.state(2:2:end) = env.state(2:2:end) + env.state(4:2:end);
% 计算奖励
reward = 0;
for i = 1:env.numUAVs
for j = 1:size(env.targetPoints, 1)
if norm(env.state([2*i-1, 2*i]) - env.targetPoints(j, :)) < env.observationRadius
reward = reward + 1;
end
end
end
% 判断是否结束
isDone = false;
if all(env.state(1:2:end) <= 0 | env.state(1:2:end) >= env.gridSize(1) | ...
env.state(2:2:end) <= 0 | env.state(2:2:end) >= env.gridSize(2))
isDone = true;
end
observation = env.state;
info = struct();
end
function reset(env)
env.state(1:2:end) = rand(env.numUAVs, 1) * env.gridSize(1);
env.state(2:2:end) = rand(env.numUAVs, 1) * env.gridSize(2);
observation = env.state;
end
end
end
2. 创建DDPG智能体
接下来,我们创建DDPG智能体并设置相关参数。
% 创建环境实例
env = UAVEnvironment();
% 创建DDPG智能体
agentOptions = rlDDPGAgentOptions();
agentOptions.SampleTime = 0.1;
agentOptions.DiscountFactor = 0.99;
agentOptions.MiniBatchSize = 64;
agentOptions.ExperienceBufferLength = 1e6;
actorNetwork = createActorNetwork(env.numUAVs);
criticNetwork = createCriticNetwork(env.numUAVs);
agent = rlDDPGAgent(actorNetwork, criticNetwork, agentOptions);
3. 训练智能体
然后,我们定义训练选项并开始训练智能体。
% 定义训练选项
trainOpts = rlTrainingOptions;
trainOpts.MaxEpisodes = 1000;
trainOpts.MaxStepsPerEpisode = 500;
trainOpts.StopTrainingCriteria = "AverageReward";
trainOpts.StopTrainingValue = -10;
% 训练智能体
trainingStats = train(agent, env, trainOpts);
4. 结果可视化
最后,我们编写一个函数来可视化训练结果。
function visualizeResults(env, agent)
figure;
hold on;
% 绘制目标点
plot(env.targetPoints(:, 1), env.targetPoints(:, 2), 'ko', 'MarkerFaceColor', 'k');
% 绘制无人机轨迹
for i = 1:env.numUAVs
states = zeros(500, 2);
env.reset();
for t = 1:500
action = getAction(agent, env.state);
[~, ~, ~, ~] = step(env, action);
states(t, :) = env.state([2*i-1, 2*i]);
end
plot(states(:, 1), states(:, 2), '.', 'Color', lines(i));
end
% 绘制观察半径
for i = 1:env.numUAVs
circle = viscircles(env.state([2*i-1, 2*i]), env.observationRadius, 'EdgeColor', lines(i));
circle.LineWidth = 2;
end
xlabel('X');
ylabel('Y');
legend('Target Points', 'UAV1', 'UAV2', 'UAV3', 'Observation Radius');
axis equal;
hold off;
end
5. 运行代码
运行上述代码后,你应该能够看到类似于提供的图片的结果。请注意,这只是一个简化的示例,实际应用中可能需要对环境、智能体和训练过程进行更详细的调整和优化。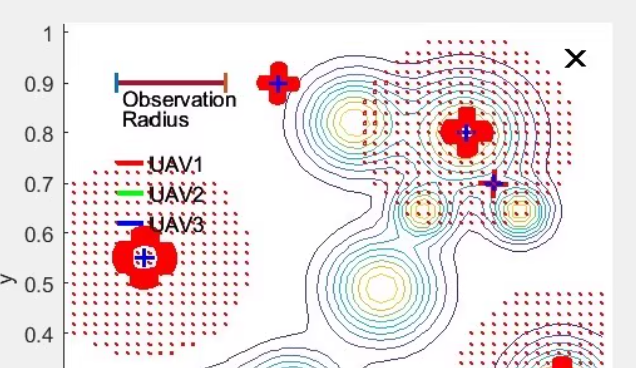

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 39
39 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)