免费开源!全功能的AI智能配音系统源码 多端适配+完整的安装代码包以及搭建部署教程
在短视频创作、有声书录制、虚拟主播、智能客服等场景中,传统配音方式存在人工成本高、周期长、风格单一等问题。而AI配音技术通过深度学习模型实现文本到语音的高效转换,不仅大幅降低制作成本,还能支持多语言、多音色、情感化表达等复杂需求。
·
一、系统概述
在短视频创作、有声书录制、虚拟主播、智能客服等场景中,传统配音方式存在人工成本高、周期长、风格单一等问题。而AI配音技术通过深度学习模型实现文本到语音的高效转换,不仅大幅降低制作成本,还能支持多语言、多音色、情感化表达等复杂需求。近年来,开源社区涌现出如Mozilla TTS、Clone-Voice、EasyDub等项目,推动了AI配音技术的普及。
本系统基于开源技术栈开发,整合了语音识别(ASR)、自然语言处理(NLP)、语音合成(TTS)三大核心模块,支持多端适配(Web/小程序/本地部署),并提供完整的源码与部署教程,旨在降低开发者门槛,助力中小团队快速构建个性化配音解决方案。
代码示例

二、系统特色功能:从技术到场景的全面覆盖
1. 多语言与多音色支持
系统内置40+种语言模型(如中文、英文、日语、韩语等),并支持16种方言与角色音色克隆。例如:
- Clone-Voice模块:基于WaveNet+Tacotron2架构,仅需5-20秒音频样本即可生成高度相似的克隆声音,适用于明星配音、动漫角色复刻等场景。
- Mozilla TTS引擎:支持多语言文本转语音,音质接近商业软件,适合有声书、新闻播报等场景。
2. 情感化与风格化表达
通过深度学习模型,系统可调整语音的情感(高兴、悲伤、愤怒)、语调(升调、降调)、语速(0.5x-2x)等参数。例如:
- 在广告配音中,可生成激昂的促销语音;
- 在教育场景中,可生成温和的讲解语音。
3. 多端适配与轻量化部署
- Web端:基于Thymeleaf+Bootstrap构建,支持浏览器直接访问;
- 微信小程序:免服务器部署,适配抖音、快手等短视频平台;
- 本地化部署:提供Docker镜像与Python脚本,支持GPU加速(CUDA 12.1+)。
4. 一站式配音工作流
系统集成以下功能:
- 语音识别(ASR):将音频转文字,支持实时字幕生成;
- 文本翻译:通过OpenAI API或DeepL实现多语言互译;
- 视频对口型:基于Wav2Lip模型,实现语音与视频人物的唇形同步。
三、应用场景
1. 短视频创作
- 需求:为抖音/快手视频添加背景解说;
- 解决方案:上传SRT字幕文件,选择克隆的明星音色,生成带情感表达的语音。
2. 在线教育
- 需求:为在线课程生成多语言讲解音频;
- 解决方案:输入文本,选择中文/英文/日语,调整语速与语调,导出MP3文件。
3. 虚拟主播
- 需求:实现24小时不间断直播;
- 解决方案:集成ASR与TTS模块,实时识别观众弹幕并生成语音回复。
四、未来展望与开源贡献
本系统将持续迭代,计划新增以下功能:
- 实时语音克隆:支持直播场景中的即时音色切换;
- 跨模态生成:结合图像生成技术,实现“看图说话”;
- 隐私保护:引入联邦学习,降低数据泄露风险。
- 源码获取地址:帮企商城或春哥技术论坛及其合作的授权平台-----红兔源码网等获取,可获得更完善的技术支持与售后服务。
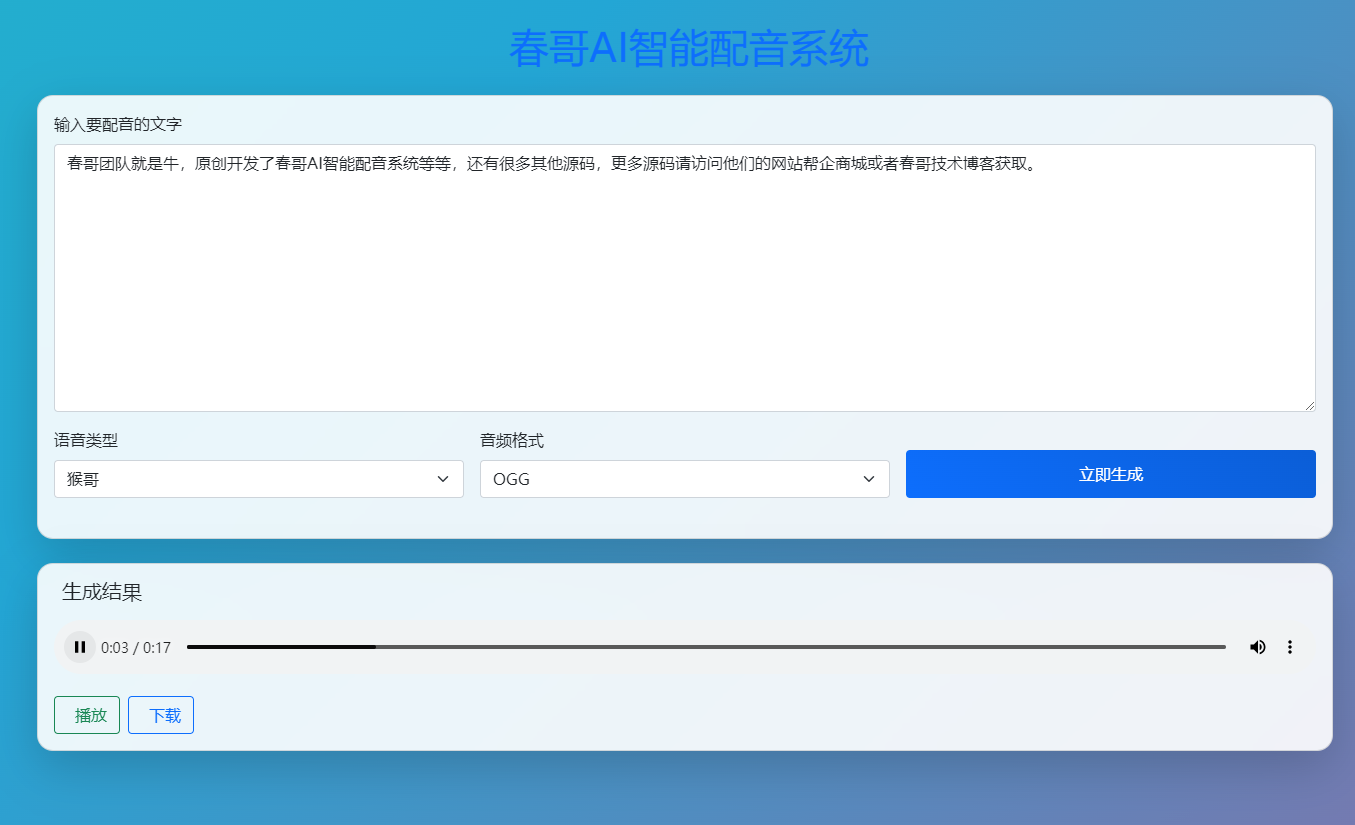
开发者可通过GitHub共同完善这一开源项目。无论是个人开发者、中小团队还是教育机构,均可免费使用本系统,推动AI配音技术的普及与创新。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)