charlsCMI函数发布,秒提取charls数据心脏代谢指数(CMI)
心脏代谢指数(CMI)是反映肥胖和血脂的新型指标,研究表明其与糖尿病及多种慢性病显著相关。本文介绍了CMI的计算方法,并利用CHARLS数据开发了专用提取函数charlsCMI,通过ggexplore工具快速挖掘CMI与其他变量的关联性。结果显示CMI与TYG、高血压等代谢指标显著相关(P<0.05),为研究者提供了高效的数据分析途径。该工具简化了CMI相关研究流程,有助于发现潜在的健康关联
心脏代谢指数(CMI)这个指标好像最近挺火的,目前是个新的发文指标,就像原来的tyg一样,可以用来抢发一下,在文章(The “cardiometabolic index” as a new marker determined by adiposity and blood lipids for discrimination of diabetes mellitus)介绍CMI 是区分糖尿病的有用新指标,同时反映了肥胖和血脂。

在文章(Cardiometabolic index and the risk of new-onset chronic diseases: results of a national prospective longitudinal study)介绍,心脏代谢指数(CMI)和10多种新发慢性病相关

听到不少人问私信问我心脏代谢指数(CMI),其实计算还是比较简单的,我抽空编写了个charlsCMI函数,顾名思义,这是个专门用于charls的函数,用于提取心脏代谢指数(CMI),下面我演示一下
先生成charls基线数据表
setwd("E:/公众号文章2024年/charls数据库/class2") #设置你放数据文件的地址
library(haven)
library(tidyverse)
library(scitable)
household_roster<-read_dta('household_roster.dta') #家庭户
family<-read_dta('family_information.dta') #大家庭
#############3
demographic<-read_dta('demographic_background.dta') #基线表
health_status_and_functioning<-read_dta('health_status_and_functioning.dta') #健康状况和功能
biomarkers<-read_dta('biomarkers.dta') #体检数据
Blood_20140429<-read_dta('Blood_20140429.dta') #血检数据
weight<-read_dta('weight.dta') #权重
health_care_and_insurance<-read_dta('health_care_and_insurance.dta') #医疗保健
###########
data<-demographic %>% left_join(health_care_and_insurance, by='ID') %>%
left_join(health_status_and_functioning,by='ID') %>%
left_join(biomarkers,by='ID') %>% left_join(Blood_20140429,by='ID') %>% left_join(weight,by='ID')
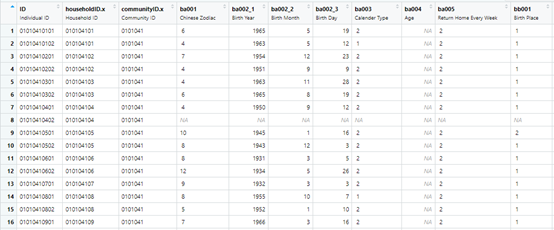
生成好charls的数据直接提取就可以了
charlsCMI(data)
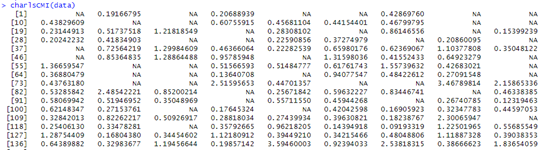
这样CMI指数就轻易提取出来了,还可以使用我既往编写的ggexplore函数对CMI指数进行数据挖掘。就是看下哪个结局和CMI指数相关,先导入一个我自己整理的charls数据,这里只是演示用,没有任何实际意义
####导入我整理好的数据48个变量
library(haven)
library(tidyverse)
library(scitable)
library(ggscitable)
setwd("E:/公众号文章2024年/scitable包配套视频/29.我整理的charls数据/2011年")
data<-read_dta('data2011.dta')
data<-as.data.frame(data)
dput(names(data))
定义要研究的变量
allVars<-c("age", "sex", "edu", "smoking", "married", "drink", "wc", "bmi",
"TC", "HDL", "weight", "memorydisease", "LDL", "FBG", "hba1c",
"TYG", "Hypertension", "CVD", "chd", "work", "insurance", "consumption",
"pension", "frailty2011",
"fuels2011", "PEF2011", "cancer", "liver", "stroke", "kidney",
"stomach", "chronic", "chronic2", "emotional", "memory", "arthritis",
"asthma", "heart", "restriction", "CESD", "activities", "intellectual",
"cognition", "spirit", "CMI")
整理一下数据格式
out<-organizedata2(data = data,allVars = allVars,family=family,username=username,token=token,explore = T)
data<-out[["data"]]
fvars<-out[["factorvarout"]]
allVars<-out[["allVars"]]
使用ggexplore挖掘数据
var<-allVars
ggexplore(data = data,x="CMI",y=var)
生成了很多图片,我随便选几张,P小于0.05表明两者之间有关联
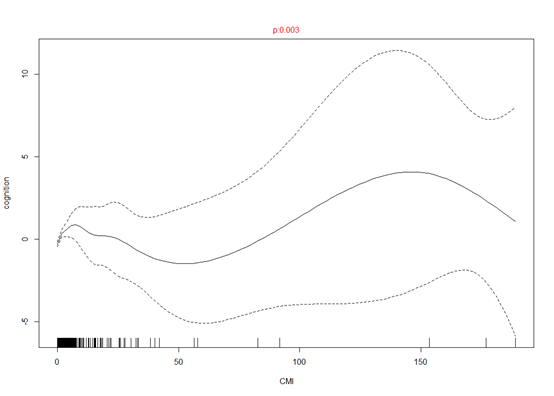
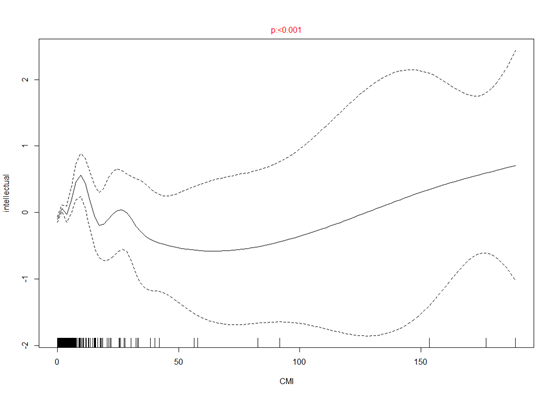
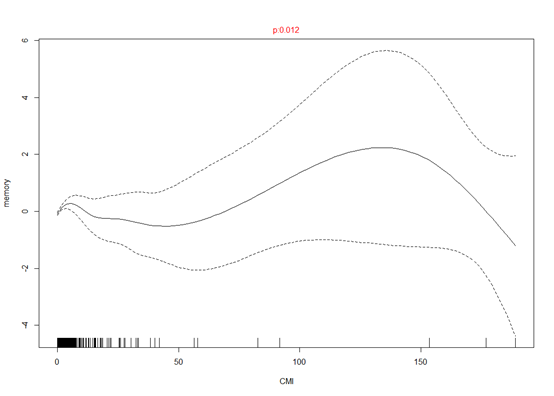
我们可以从中挑选出咱们感兴趣的结局变量来分析。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 5
5 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)