使用R语言和GlobalBurdenR分析GBD数据:特殊年龄段绘图(GBD系列第十五集)
GBD数据库提供了全球范围内的健康数据,研究人员可以利用这些数据分析疾病负担在不同年龄组、性别和地区中的变化情况。我们的教学代码专注于从多个CSV文件合并GBD数据,并通过多种图表直观展示特定年龄组(尤其是20岁以下)的发病率数据,帮助理解儿童和青少年人群的疾病负担趋势。使用R语言和GlobalBurdenR工具包绘制特殊年龄段的多种图表,可以帮助我们深入理解儿童和青少年人群的疾病负担趋势。希望这
在公共卫生研究中,通过多种图表可视化全球疾病负担(GBD)数据对于展示特定年龄组的疾病负担变化趋势至关重要。今天,我们将介绍如何使用R语言和GlobalBurdenR工具包处理GBD数据,绘制特殊年龄段的多种图表,以展示全球范围内特定年龄组的发病率数据,包括折线图、柱状图、性别对比图、性别比例图、地区对比图和EAPC柱状
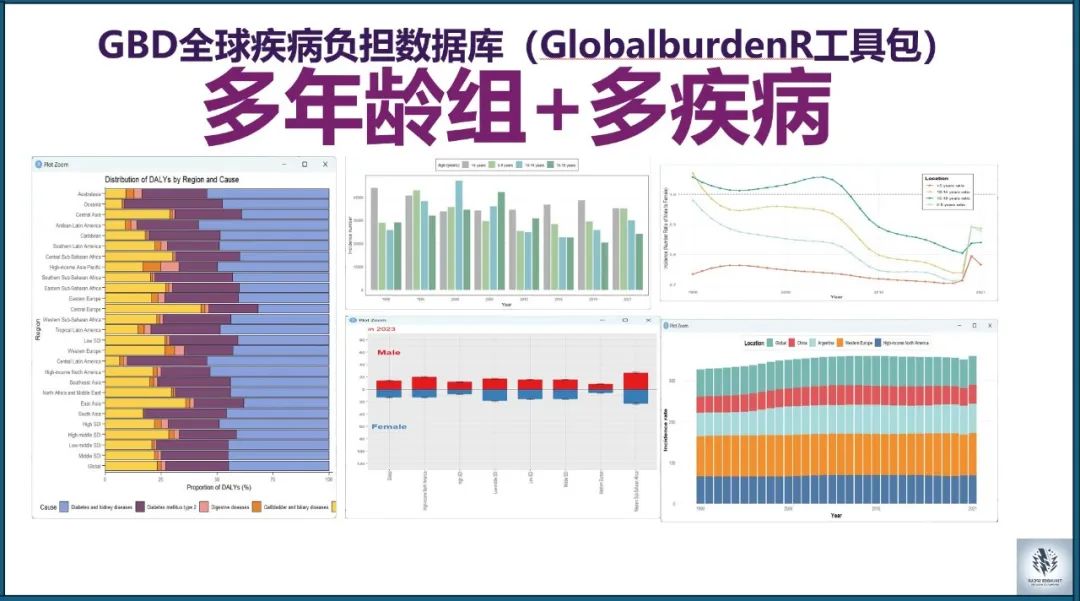
图。
背景介绍
GBD数据库提供了全球范围内的健康数据,研究人员可以利用这些数据分析疾病负担在不同年龄组、性别和地区中的变化情况。我们的教学代码专注于从多个CSV文件合并GBD数据,并通过多种图表直观展示特定年龄组(尤其是20岁以下)的发病率数据,帮助理解儿童和青少年人群的疾病负担趋势。
代码功能解析
这段R代码主要完成了以下几个步骤:
-
设置工作目录和数据合并:设置数据存储目录并合并多个CSV文件中的GBD数据。
-
数据预处理:使用
gbd_filter函数筛选出符合条件的发病率数据,并进行格式化处理。 -
可视化绘制:使用多种可视化函数绘制特殊年龄段的图表,包括折线图、柱状图、性别对比图、性别比例图、地区对比图和EAPC柱状图。
-
表格生成:使用
GBD_table_special_age函数生成特殊年龄段的表格数据。
代码详细解读
以下是代码的详细解读,帮助您理解每个步骤的具体实现:
# 设置工作目录setwd('D:\\GlobalBurdenR\\肿瘤\\肿瘤')# 合并多个CSV文件中的GBD数据data=merge_csv_files_vroom_progress('X:/GBD数据库示例数据/datas')# 检查数据data=debug_gbd_data_check(data)# 筛选20岁以下年龄组的数据并保存datas=gbd_filter(data, age=='<20 years')write.csv(datas, 'cancer.csv')# 获取唯一地区列表并定义排序location=unique(datas$location)order=c("Overall", "Female", "Male", "China", "High-income North America", "Western Europe")# 生成特殊年龄段表格t2<-GBD_table_special_age( input_path="cancer.csv", measure="Incidence", locations=location, regions_order=order, year1=1990, year2=2021, age_group="<20 years", output_path='222.docx')t2
# 绘制折线图(10-14岁,中国,发病率)datas=gbd_filter(data, age=='10-14 years', measure=='Incidence', location=='China', metric=='Rate')plot_data<-datas%>% filter(sex%in%c("Male", "Female", "Both"))visual_special_age_line(datas, x_var="year", y_var="val", group_var="sex", y_scaling=100000, title="", x_label="Year", y_label="Incidence rate (per 100,000 population)", legend_title="Gender groups", colors=c("Male"="#3E9BD2", "Female"="#D9896A", "Both"="#78BFA5"), point_size=1, x_breaks=seq(1990, 2021, 5), legend_position="top", legend_title_size=10, show_grid=FALSE, show_axis_lines=TRUE)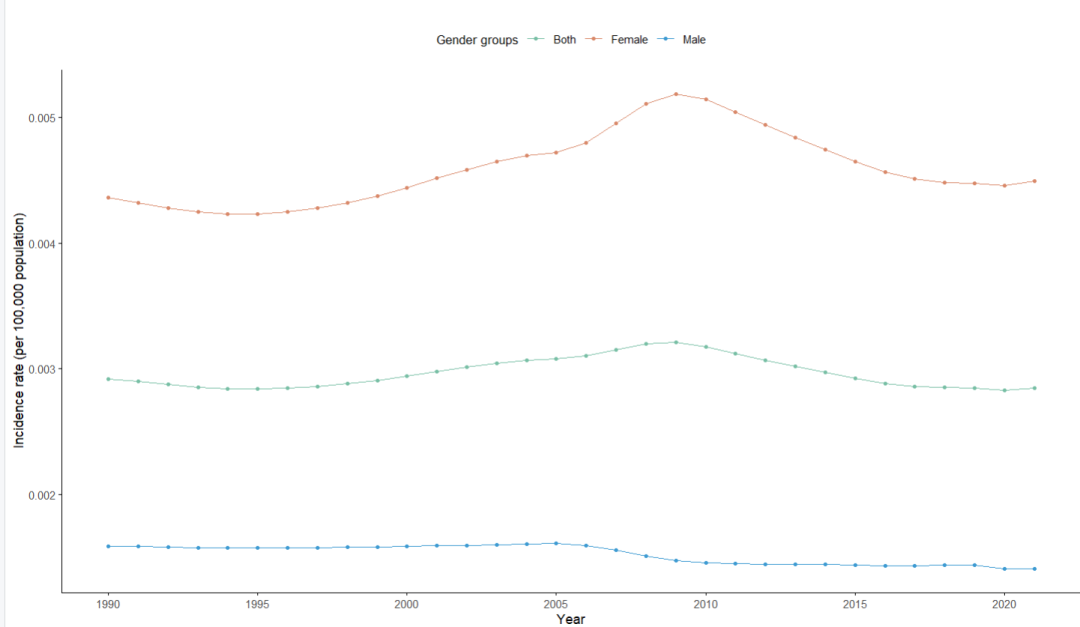
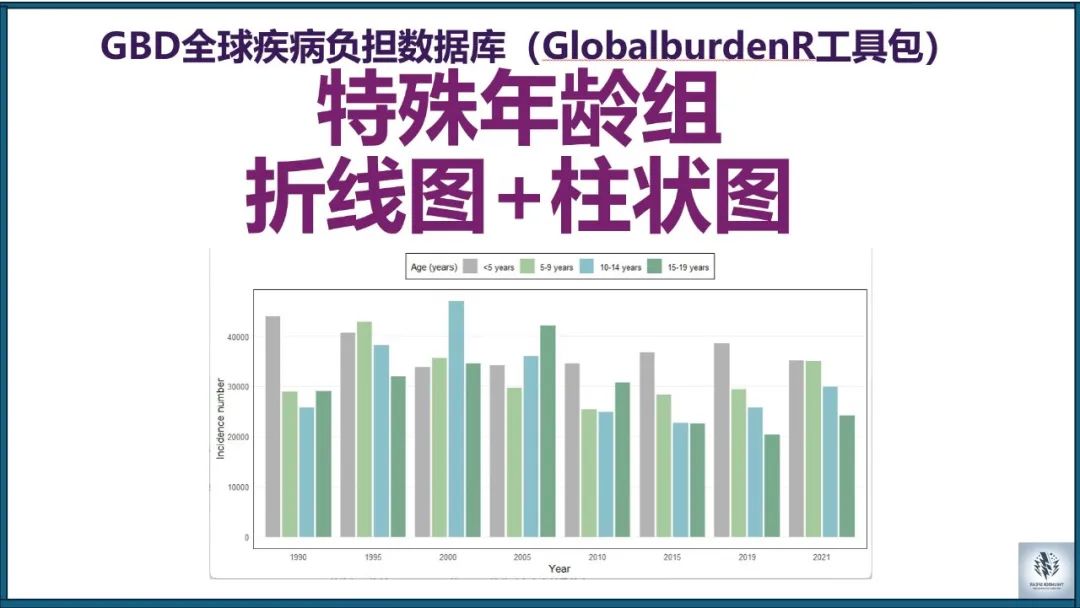
# 绘制柱状图(多个年龄组,中国,发病数量)datas=gbd_filter(data, age%in%c('<5 years', "5-9 years", "10-14 years", "15-19 years"), measure=='Incidence', year%in%c(1990, 1995, 2000, 2005, 2010, 2015, 2019, 2021), location=='China', metric=='Number')datas$age=factor(datas$age, levels=c("<5 years", "5-9 years", "10-14 years", "15-19 years"))visual_special_age_bar(datas, x_var="year", y_var="val", fill_var="age", colors=c("<5 years"="#B3B3B3", "5-9 years"="#A6C99D", "10-14 years"="#89C0C9", "15-19 years"="#7AAA8E"), title="", x_label="Year", y_label="Incidence number", legend_title="Age (years)", bar_width=0.8, dodge_width=0.9, x_breaks=c("1990", "1995", "2000", "2005", "2010", "2015", "2019", "2021"), legend_position="top", legend_title_size=10, show_major_x_grid=FALSE, show_minor_grid=FALSE, border_color="black")
# 绘制性别对比折线图(多个年龄组,中国,2021年发病率)datas=gbd_filter(data, age%in%c("<5 years", "5-9 years", "10-14 years", "15-19 years"), measure=='Incidence', year%in%c(2021), location=='China', metric=='Rate', sex!='Both')datas$age=factor(datas$age, levels=c("<5 years", "5-9 years", "10-14 years", "15-19 years"))visual_special_age_sex_compare_line(datas, x_var="age", y_var="val", color_var="sex", line_size=1, point_size=2.5, colors=c("Male"="#6BAED6", "Female"="#F4A582", "Both"="#78C679"), x_lab="Age (years)", y_lab="Incidence rate\n(per 100 000 population)", legend_position="none", legend_title="", base_size=12, show_minor_grid=FALSE, show_major_x_grid=FALSE, axis_line_color="black")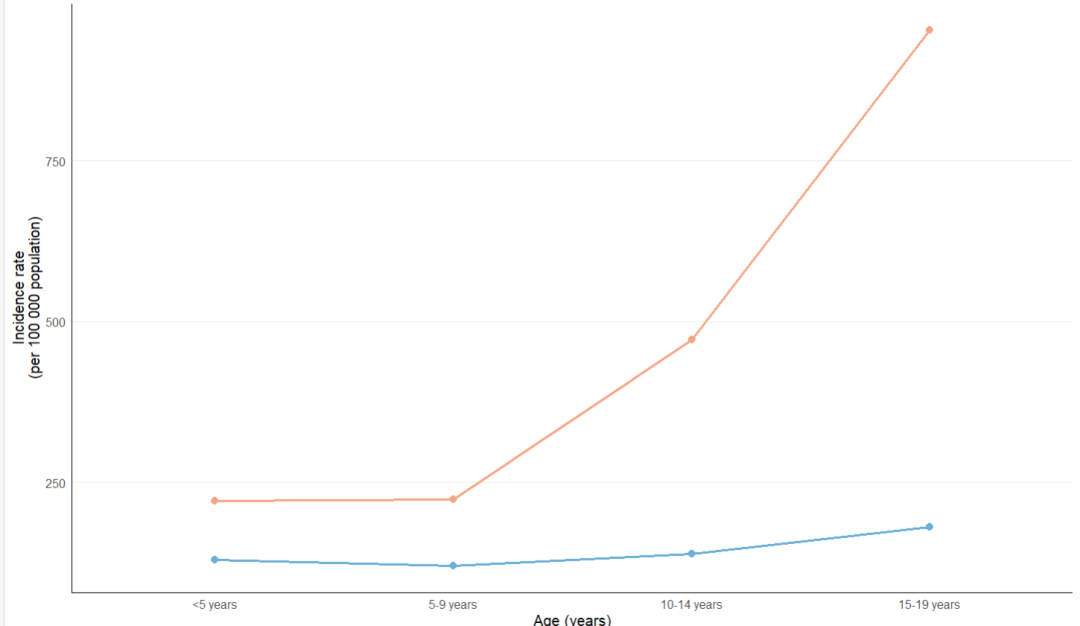
# 绘制性别比例图(多个年龄组,中国,发病数量)datas=gbd_filter(data, age%in%c("<5 years", "5-9 years", "10-14 years", "15-19 years"), measure=='Incidence', location=='China', metric=='Number', sex!='Both')visual_special_age_sex_ratio(datas, x_breaks=c(1990, 2000, 2010, 2021), x_limits=c(1990, 2021), custom_colors=c( "<5 years ratio"="#E76F51", "5-9 years ratio"="#A8DADC", "10-14 years ratio"="#E9C46A", "15-19 years ratio"="#2A9D8F" ), legend_title="Location", legend_position=c(0.85, 0.8))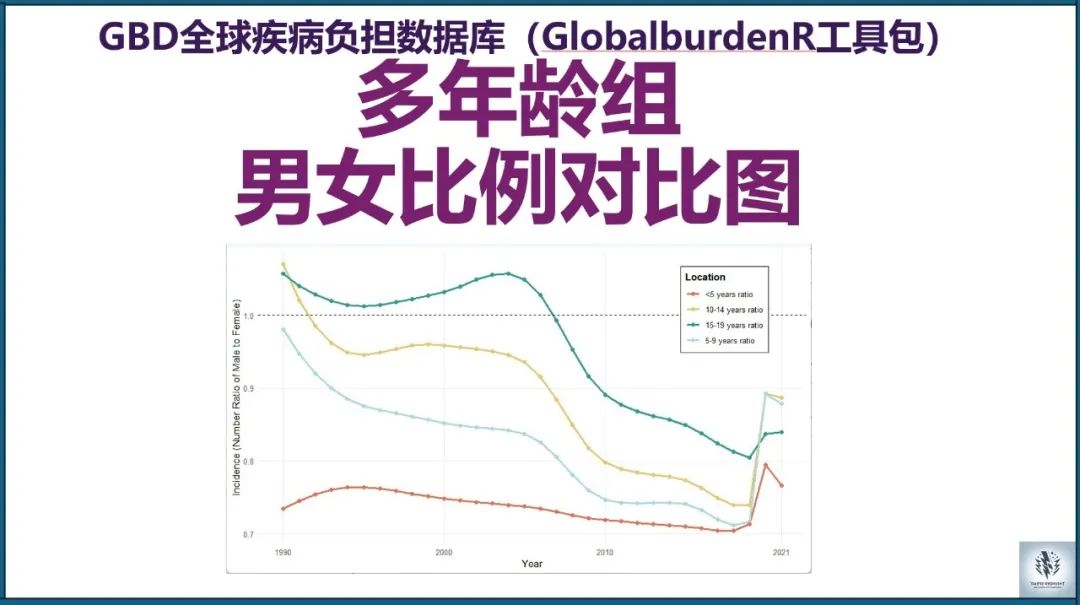
# 绘制地区对比柱状图(<5 years,发病率,多个地区)datas=gbd_filter(data, age%in%c('<5 years'), measure=='Incidence', metric=='Rate', sex=='Both', location%in%c("Global", "China", "Western Europe", "High-income North America"))visual_special_age_locationbar(datas, location_order=c("Global", "China", "Western Europe", "High-income North America"), colors=c("High-income North America"="#4e79a7", "Western Europe"="#f28e2b", "China"="#e15759", "Global"="#76b7b2"), x_breaks=c(1990, 2000, 2010, 2021), x_limits=c(1989, 2022), y_label="Incidence rate", x_label="Year", legend_title="Location", font_size=12)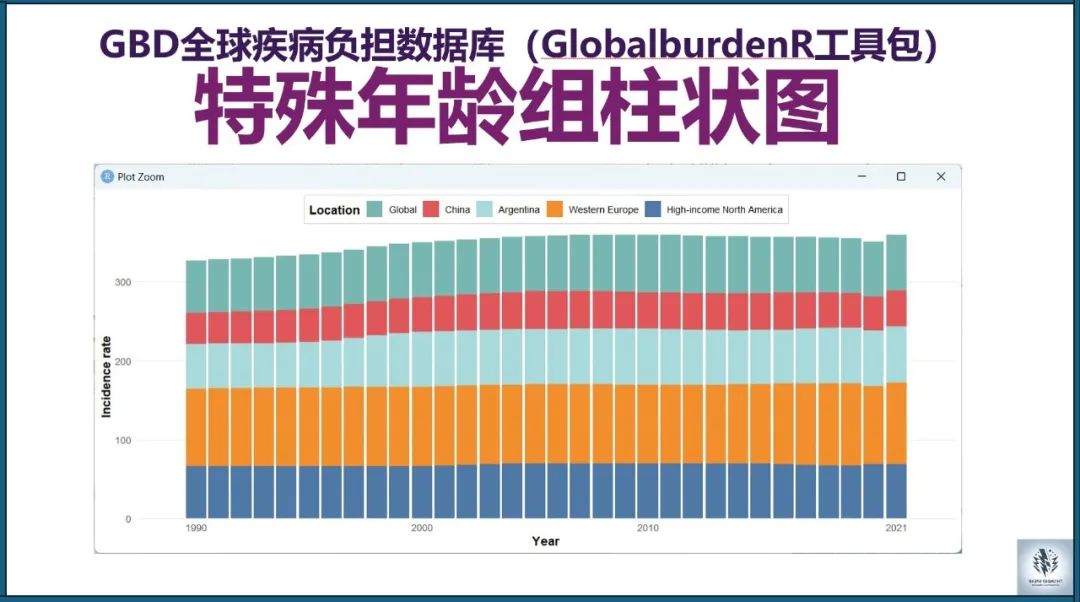
解读说明:
-
设置工作目录和数据合并:代码将工作目录设置为数据存储位置,并使用
merge_csv_files_vroom_progress函数合并多个CSV文件中的GBD数据。 -
数据预处理:
gbd_filter函数筛选出符合条件的数据,针对不同年龄组、年份、地区和性别进行筛选,并对数据进行格式化处理(如将年龄组转换为因子型)。 -
可视化绘制:代码使用多种可视化函数绘制图表,包括
visual_special_age_line(折线图)、visual_special_age_bar(柱状图)、visual_special_age_sex_compare_line(性别对比折线图)、visual_special_age_sex_ratio(性别比例图)、visual_special_age_locationbar(地区对比柱状图)和自定义ggplot代码绘制EAPC柱状图。每个函数都设置了特定的参数,如颜色、标签、图例位置等。 -
表格生成:
GBD_table_special_age函数用于生成特殊年龄段的表格数据,参数设置了输入路径、指标、地区、年份和输出路径。
应用场景
通过这段代码,研究人员可以直观地分析全球范围内特定年龄组(尤其是20岁以下)的发病率数据变化趋势,并通过多种图表清晰展示性别、地区和时间差异。这对于理解儿童和青少年人群的疾病负担、识别高风险群体以及制定针对性的公共卫生干预措施具有重要意义。
总结
使用R语言和GlobalBurdenR工具包绘制特殊年龄段的多种图表,可以帮助我们深入理解儿童和青少年人群的疾病负担趋势。希望这段代码和详细解读能为您的研究提供启发,如果您有任何问题或需要进一步的指导,欢迎留言交流。
关注我们的公众号,获取更多数据分析和可视化的实用教程!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)