李宏毅机器学习第七周_Spatial Transformer Layer
目录
一、什么是Spatial Transformer Layer?
二、CNN is not invariant to scaling and rotation
三、How to transform an image/feature map
摘要
自注意力(Self-attention)是一种在深度学习领域的关键技术,其目的在于捕捉序列数据中的长距离依赖关系。自注意力通过计算序列元素间的相互关联,使模型能够关注与当前元素相关的其他元素。主要实现方式包括:将输入序列映射到查询(Query)、键(Key)和值(Value)空间;计算注意力权重;对值进行加权求和;输出序列。自注意力在自然语言处理和计算机视觉等领域有广泛应用。
ABSTRACT
Self-attention is a crucial technique in the field of deep learning, aiming to capture long-range dependencies within sequence data. By calculating the interrelations among sequence elements, self-attention enables the model to focus on other elements related to the current element. The primary implementation includes: mapping the input sequence to Query, Key, and Value spaces; computing attention weights; taking the weighted sum of values; and outputting the sequence. Self-attention has been widely applied in areas such as natural language processing and computer vision.
一、Spatial Transformer Layer
一、什么是Spatial Transformer Layer?
Spatial Transformer Layer 的主要目的是为了使神经网络能够学习到对输入数据进行空间变换的能力,从而提高模型的表达能力和泛化性能。Spatial Transformer Layer 的主要目的是为了使神经网络能够学习到对输入数据进行空间变换的能力,从而提高模型的表达能力和泛化性能。
二、CNN is not invariant to scaling and rotation
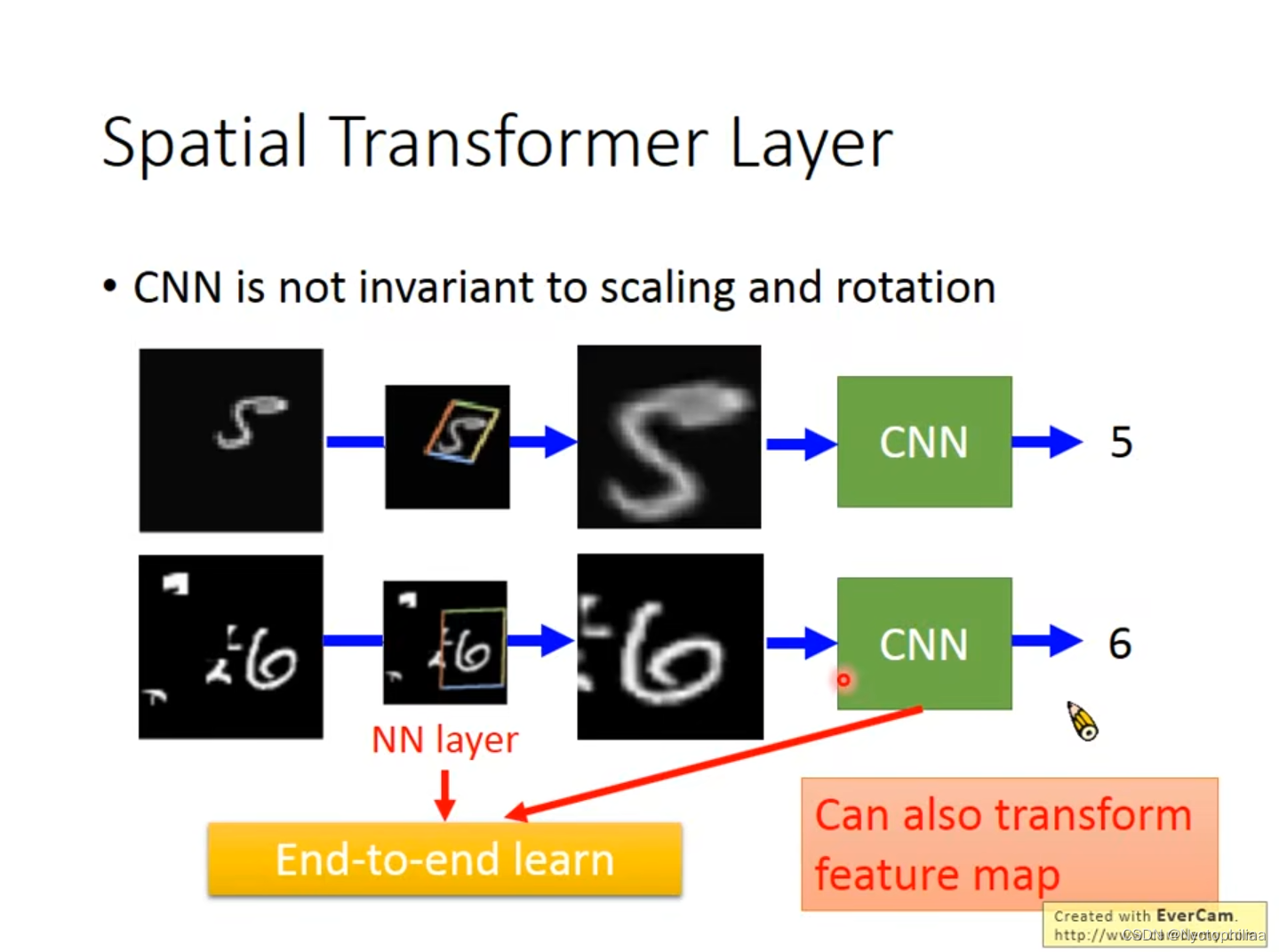
Spatial Transformer Layer是Neural Network,而它的作用是多学习一层layer,对左边的图片做scaling和rotation后,能够被CNN识别出来。如果只把第一张和第三张图片丢给CNN的话,他可能认出来图片中的数字是多少。
三、How to transform an image/feature map
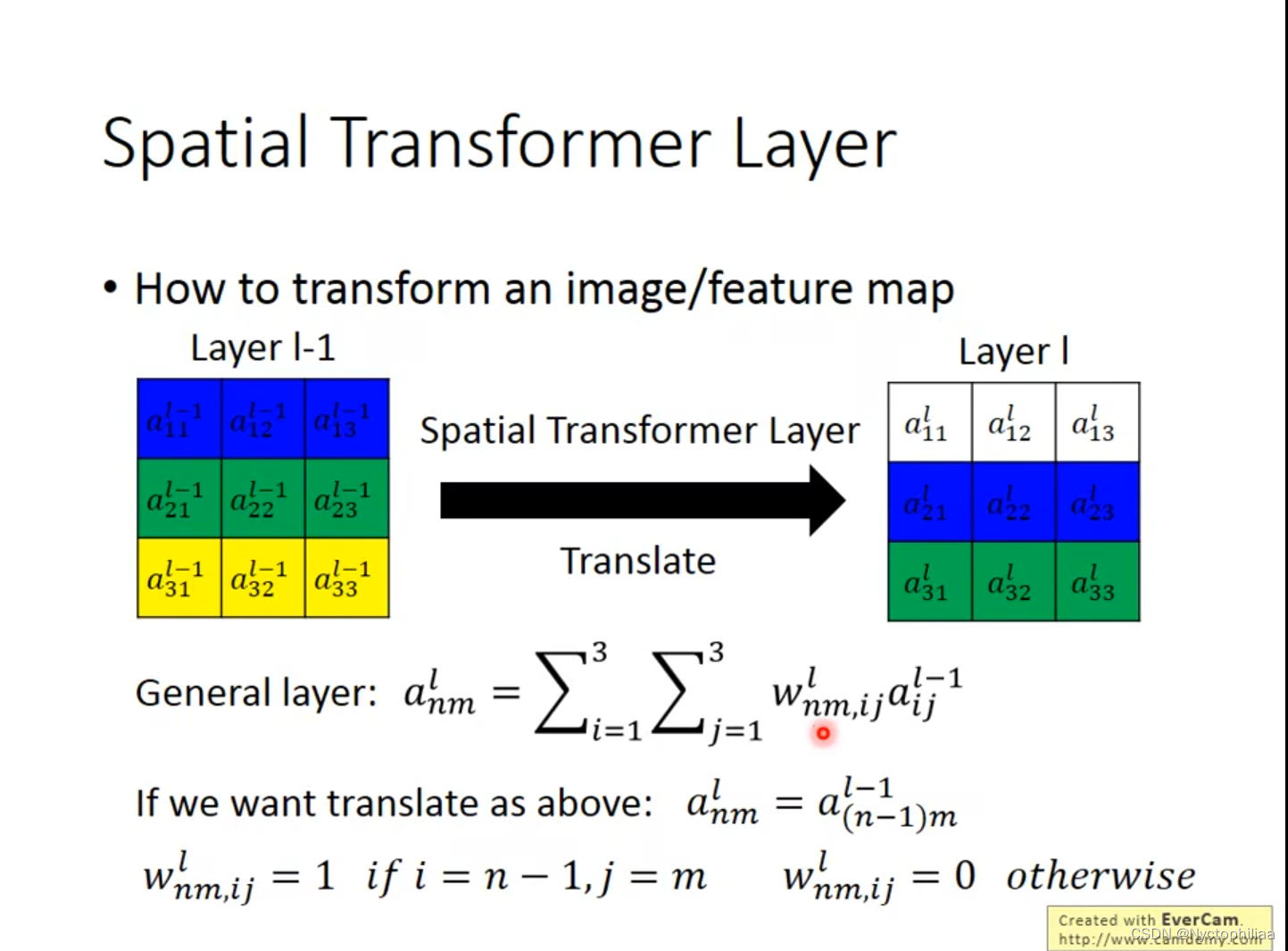
1、平移其实就是一个调整参数的过程,在下图中就是把Layer I-1整体向下平移了一个单位。
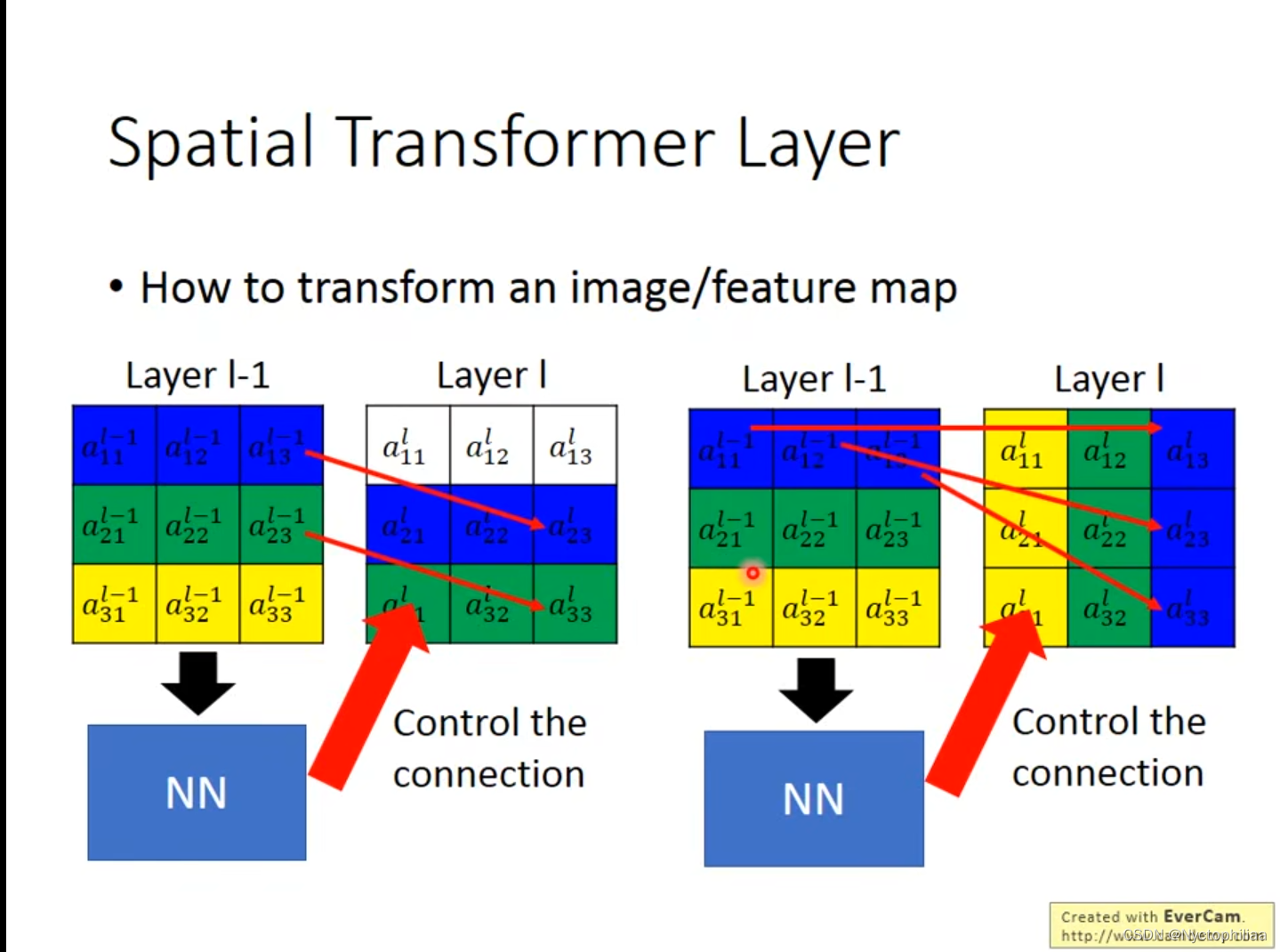
2、在下图中,第一个和第二个图是通过NN来控制联系,向下平移,把移动到
的位置上,
与
相对应,
与第一个图的其他位置的连接为0;在第三个和第四个图中,是向右旋转,通过控制参数,然后把
旋转到
的位置上,
与左图中的其他位置的连接为0。
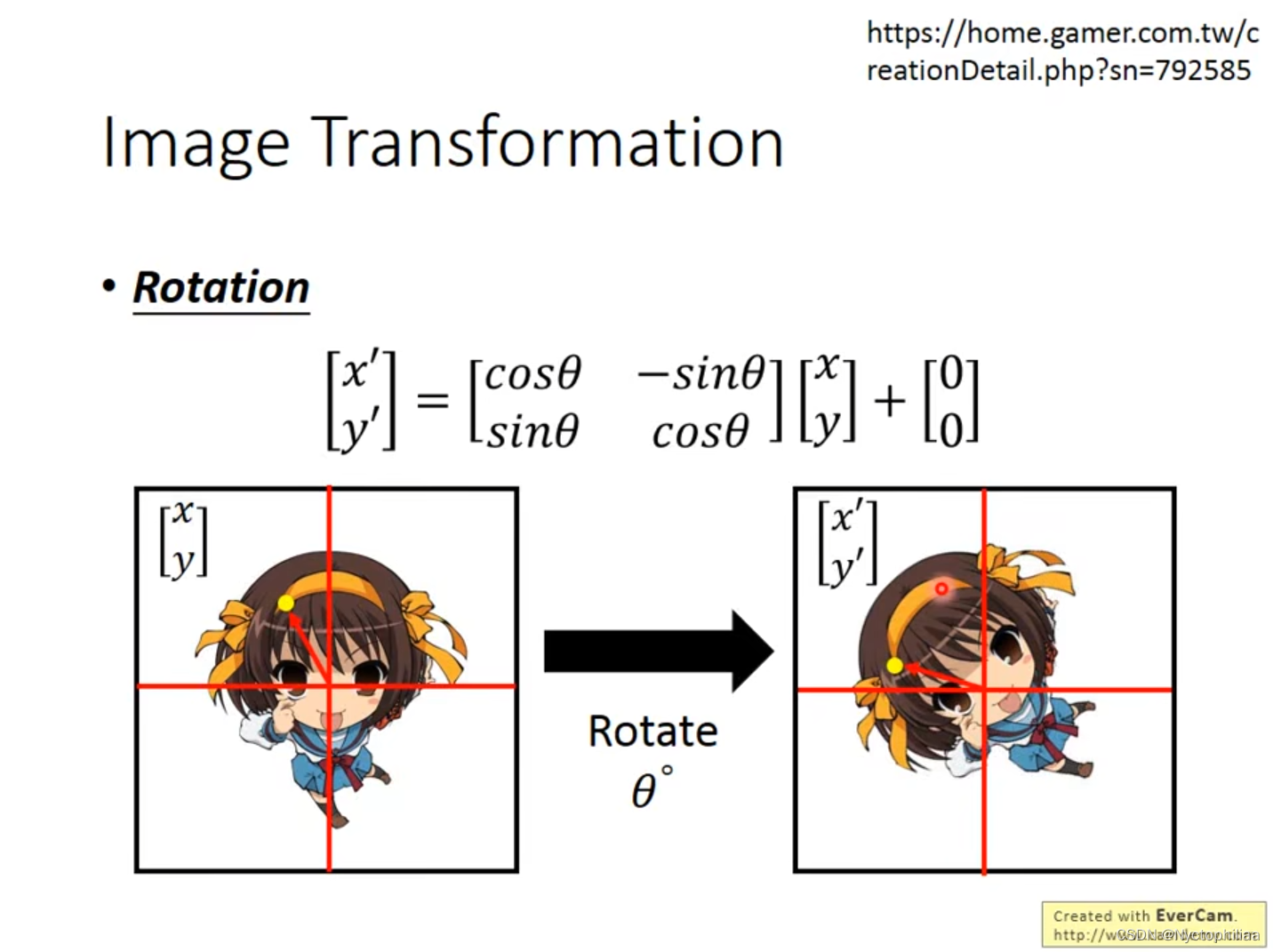
二、Image Transformation
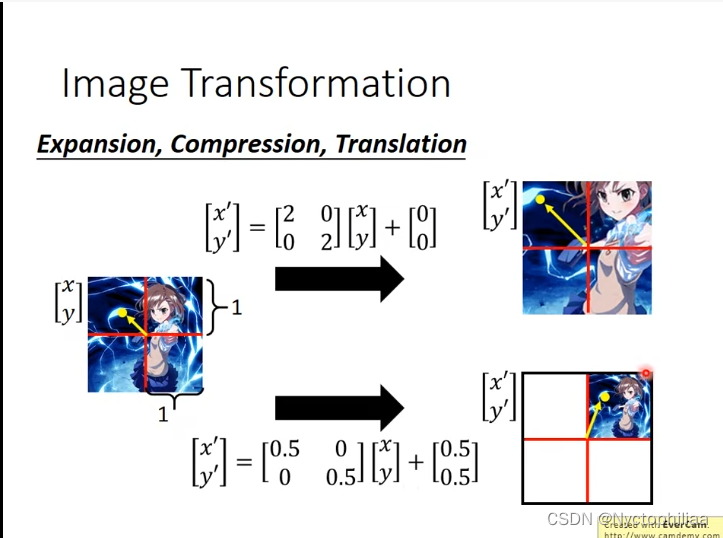
在下图中,假设一个window的单位长度是1,第一个箭头是把图片放大两倍,不进行移动,从而得到箭头指向的照片。第二个箭头是先把图像缩小成原来的一半,然后将图片向右上方移动。
在下图中,是把图片向左进行旋转,旋转多少度由自己决定,然后在原来的图像上乘上一个矩阵即可。
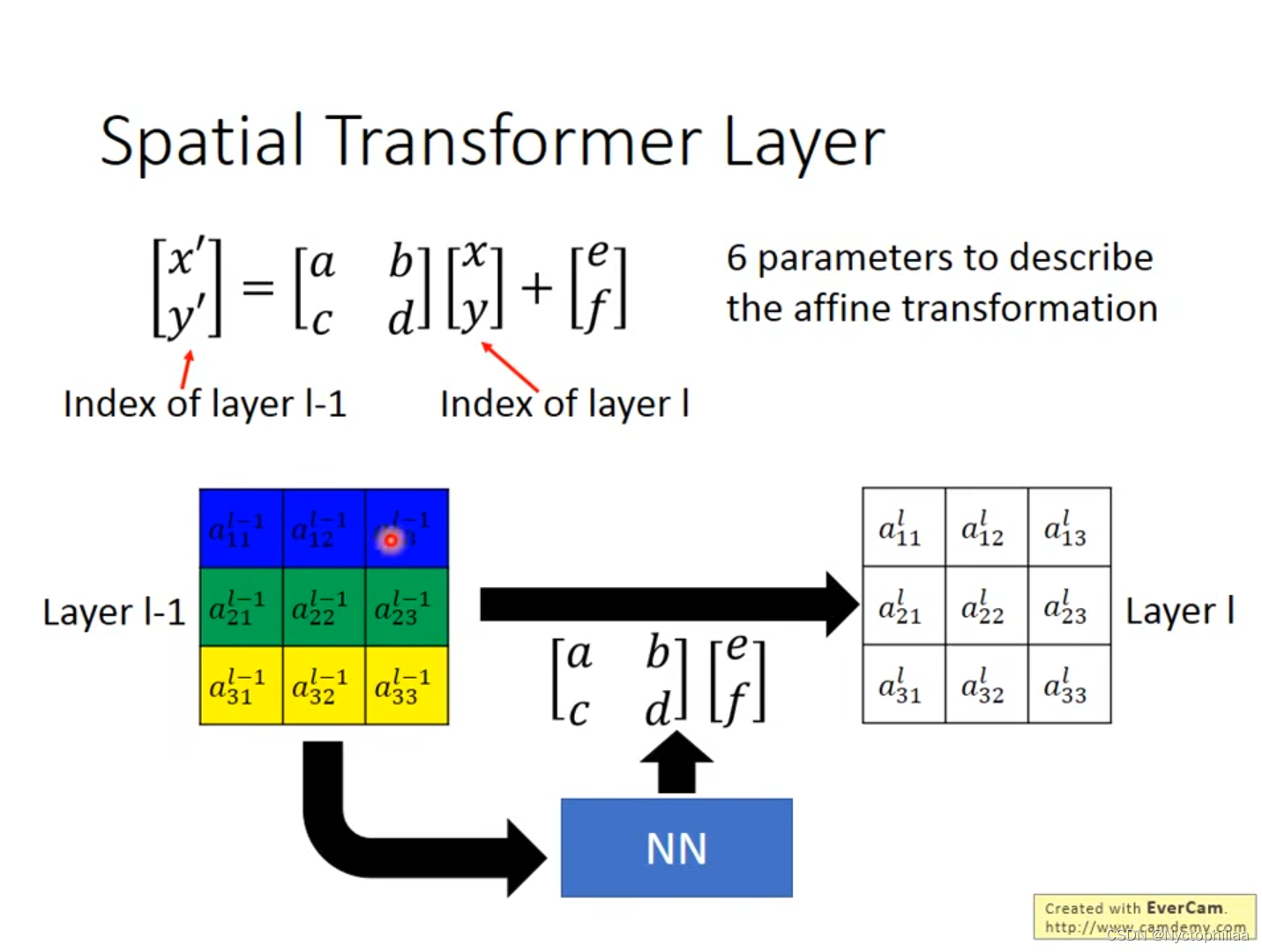
综上所述,Spatial Transformer Layer只需要6个参数,通过调整参数便可进行移动和旋转。但在实际计算中,当a、b、c、d、e、f的值为小数时,这个时候是不能进行Gradient Descent的,因为Gradient是一直为0的。
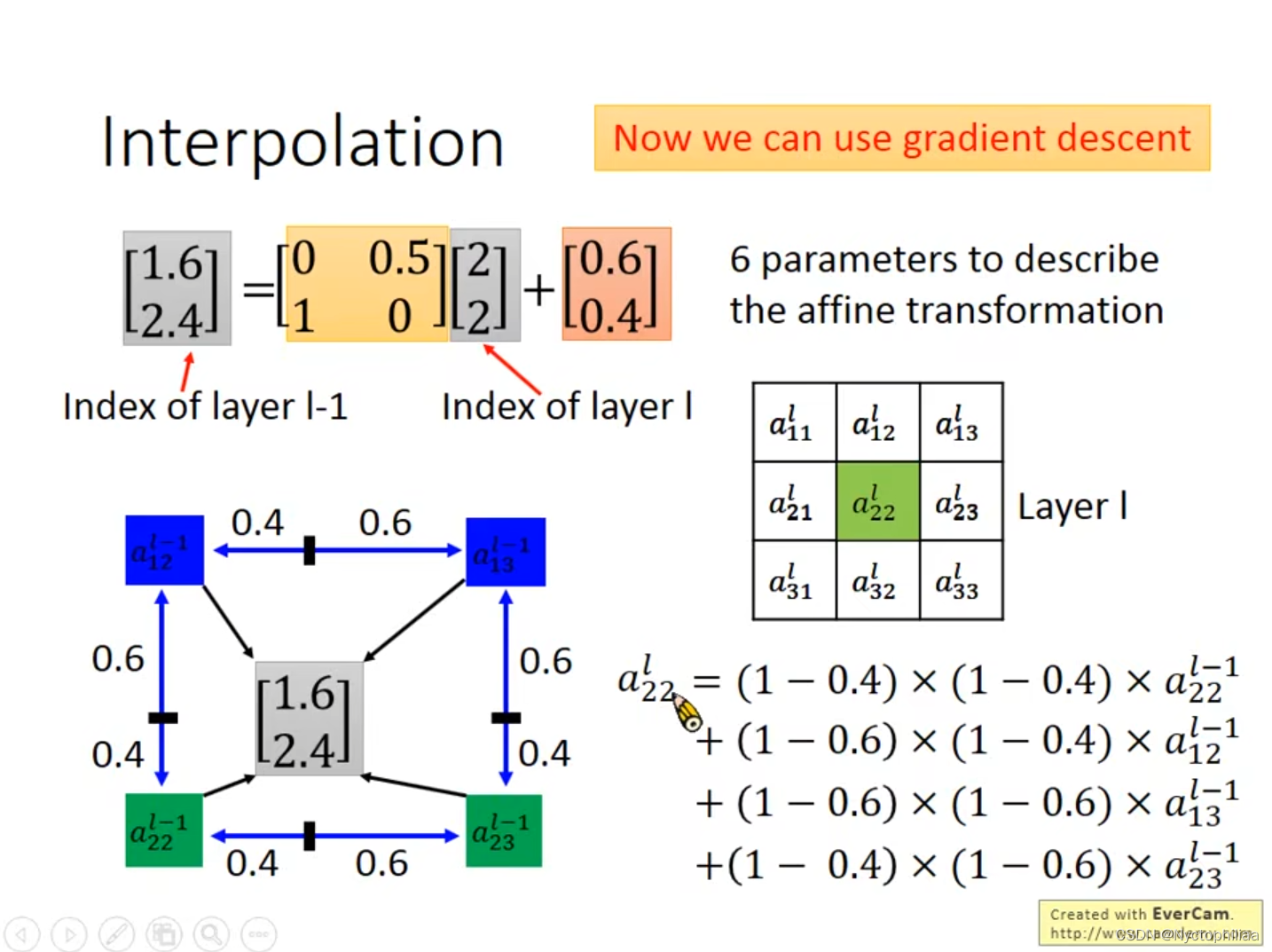
三、Interpolation
对于如果参数给的是小数的情况,我们不能进行Grandient descent,但是如果我们按照计算出来的结果直接去四舍五入估算的话,往往会有误差,所以我们可以用Interpolation来解决这个问题。
比如说我们已知平移后的坐标是[2,2],现在我们想知道它与谁相对应,通过给定的6个参数,我们得出[1.6,2.4],这时,我们不能用估算法去四舍五入说他与[2,2]相对应,而是应该找出它周围的4个点,然后分别计算出与这4个点的距离,之后便可以用Gradient descent的方法来得出结果。
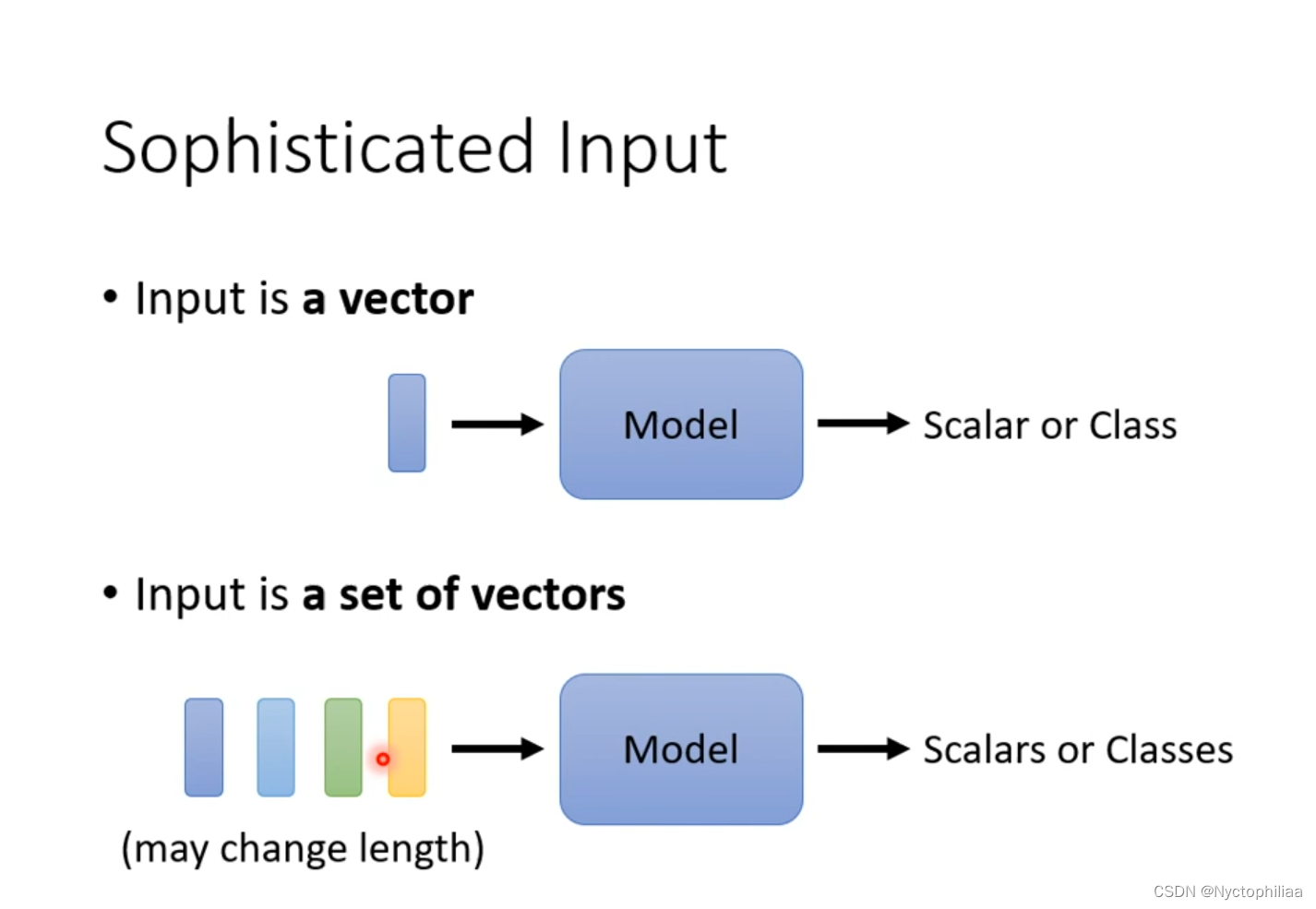
四、Sophisticated Input
到目前为止,我们network的input是一个向量,output是一个数值或者类别。或者输入是一组向量,而且这组向量的大小可以变,不一定都是同样大小的向量,output是一个数值或者类别。
五、Vector Set as Input
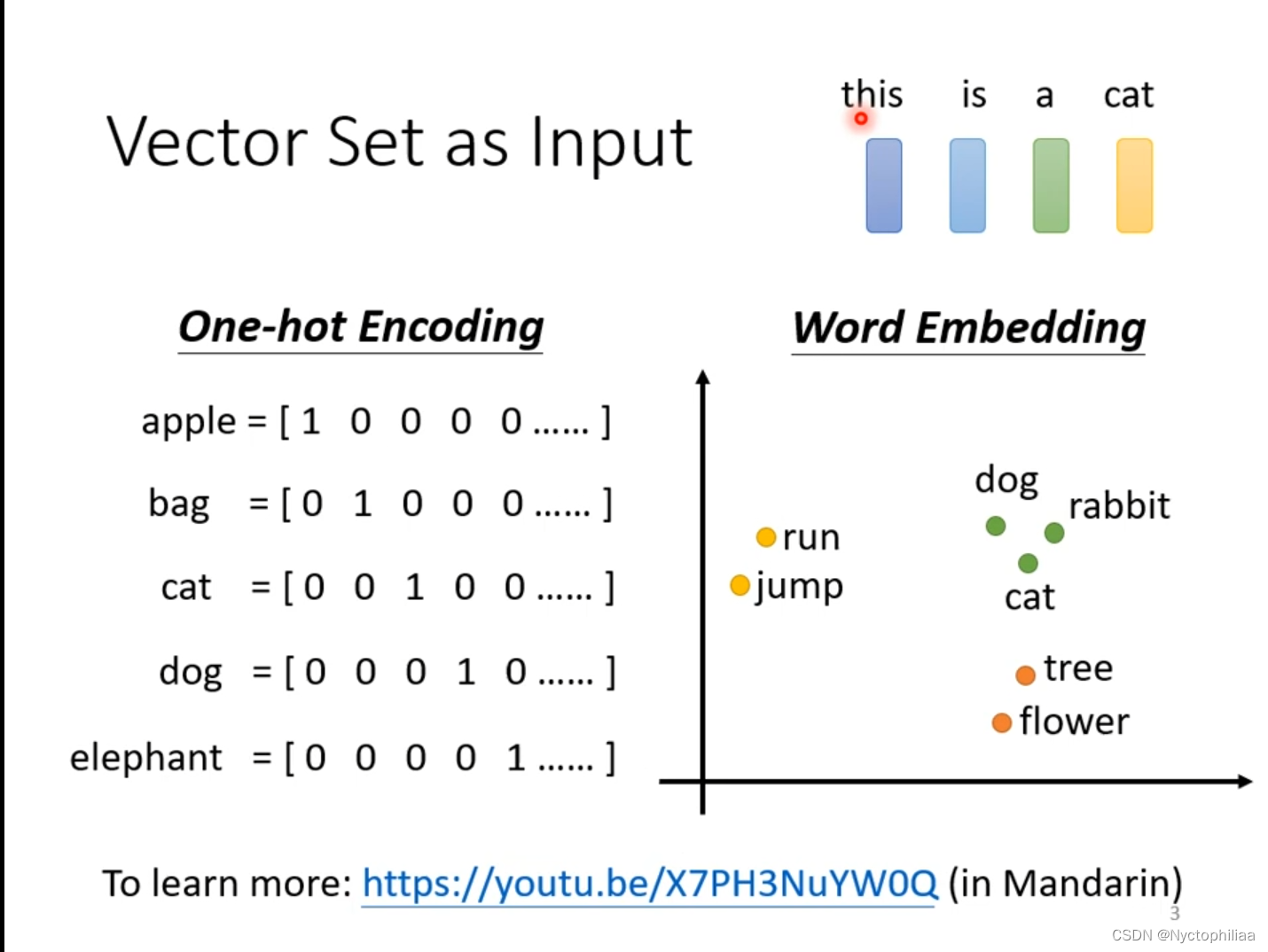
文字处理,输入是一个句子,然后把句子中的每一个词汇用向量表示。一种方法是用One-hot Encoding把词汇表示成向量,但是这个方法存在严重问题,它假设每个词汇之间没有关系。另一种方法是用Word Embedding,在图中我们可以发现所有动物聚在一起,所有植物聚在一起,所有动词聚在一起。
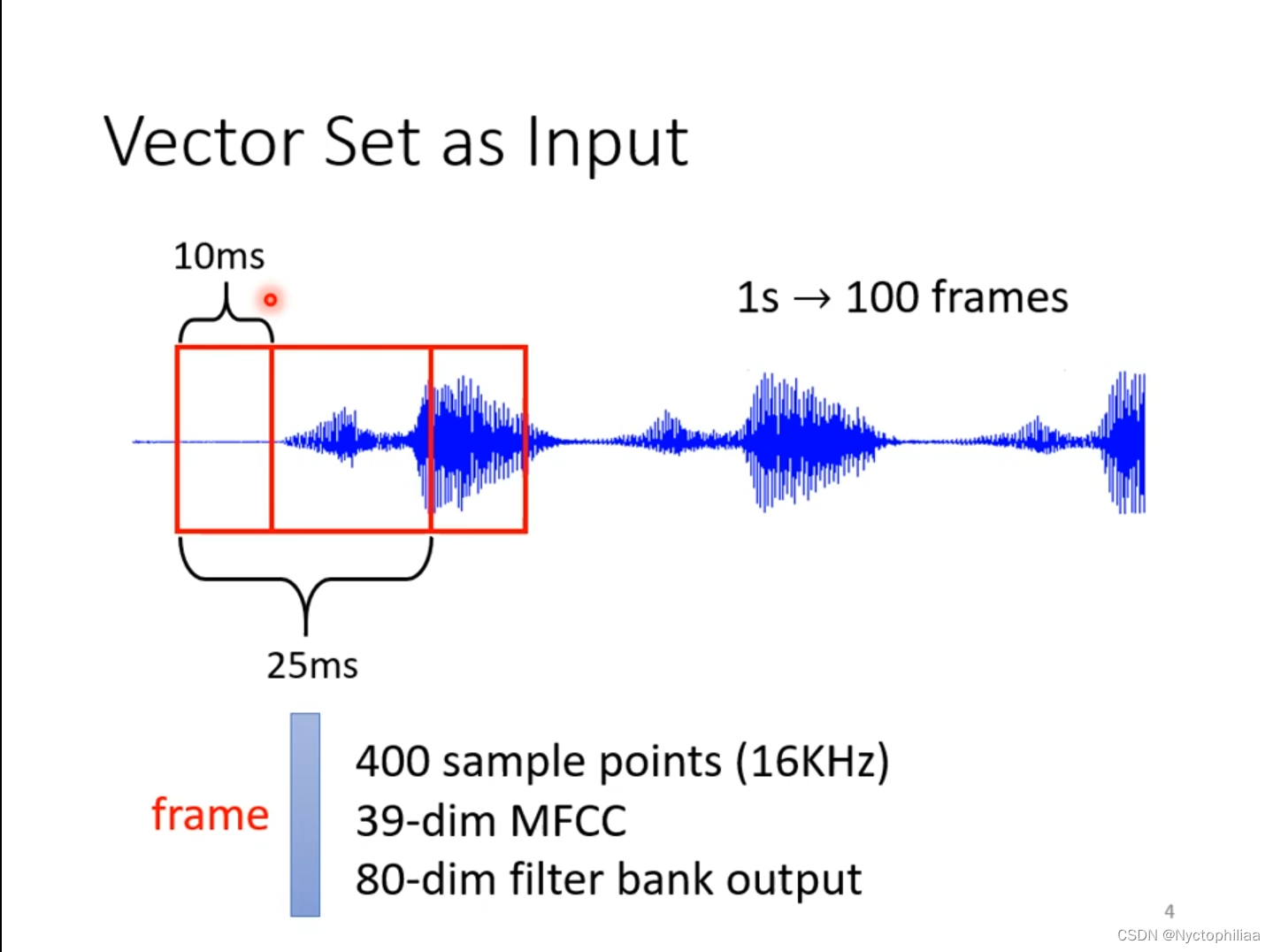
声音讯号,其实是一串向量,取其中一个范围window,把里面的咨询描述成一个向量frame
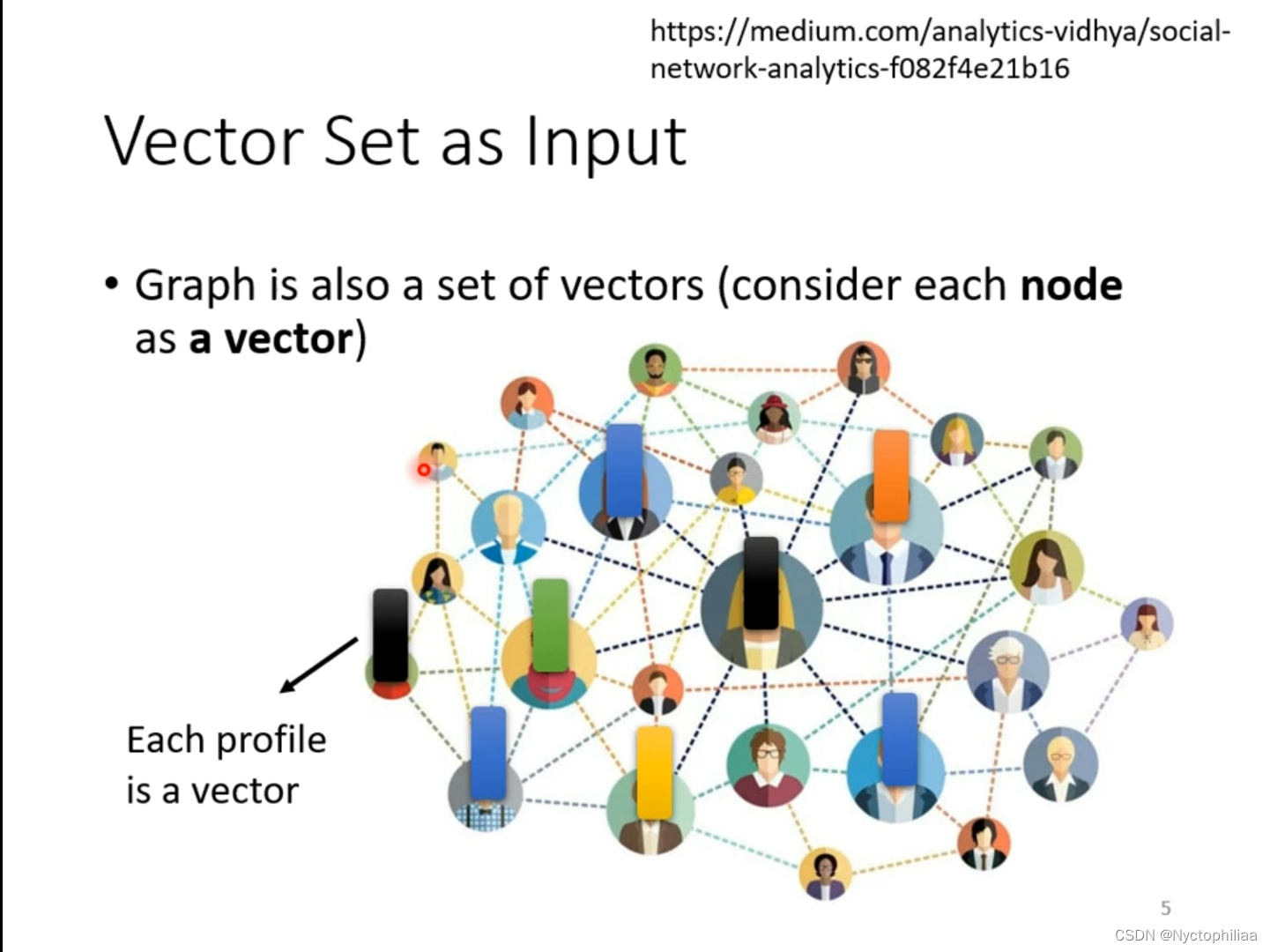
一个图也是一堆向量,如下图所示,每一个结点(图中的人头)可以用一个向量表示。
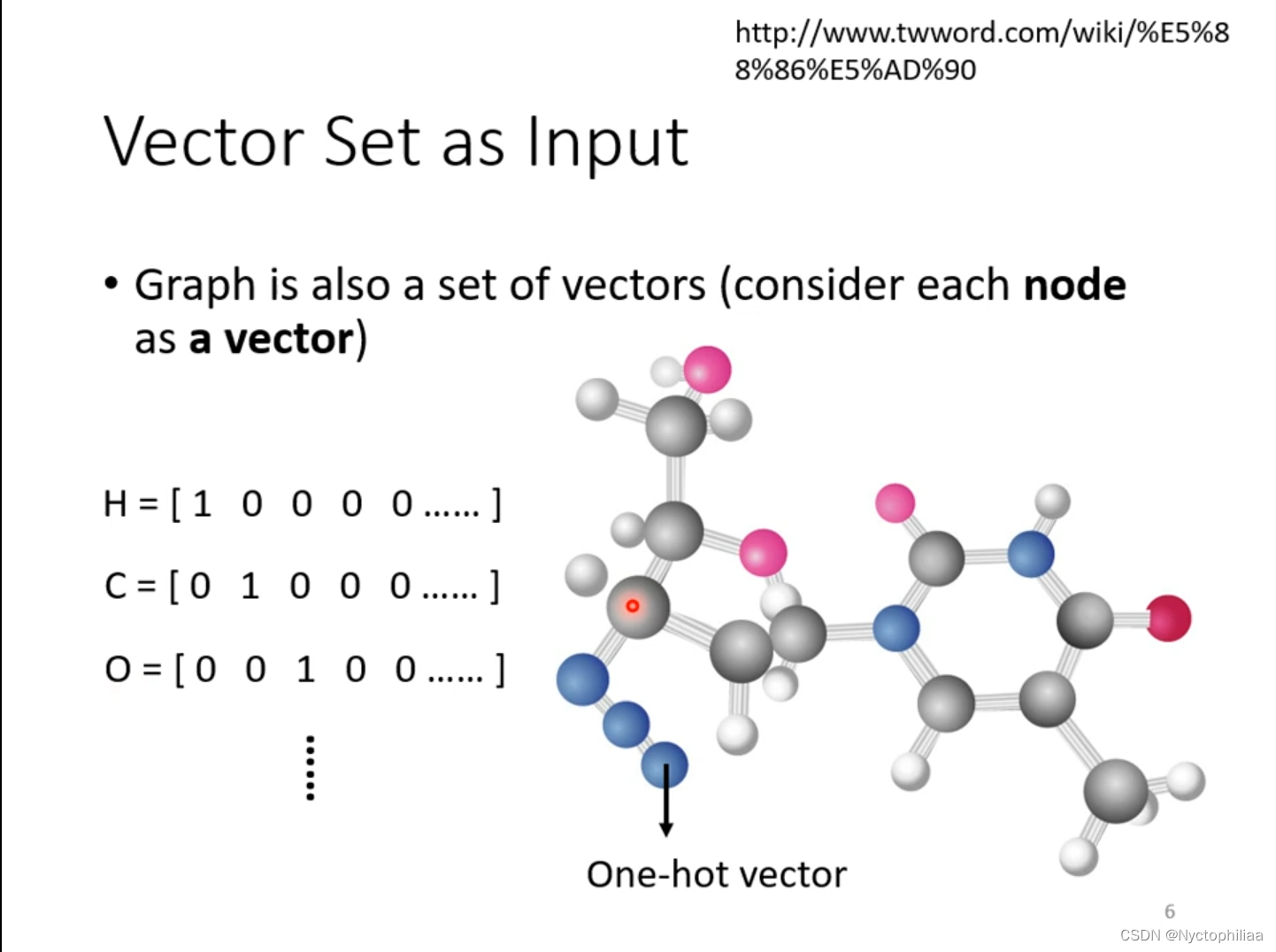
一个分子也可以看成图片,把分子当成模型的输入,分子上的原子(图中的球状体)就是一个向量,用One-hot vector来把原子表示成向量。
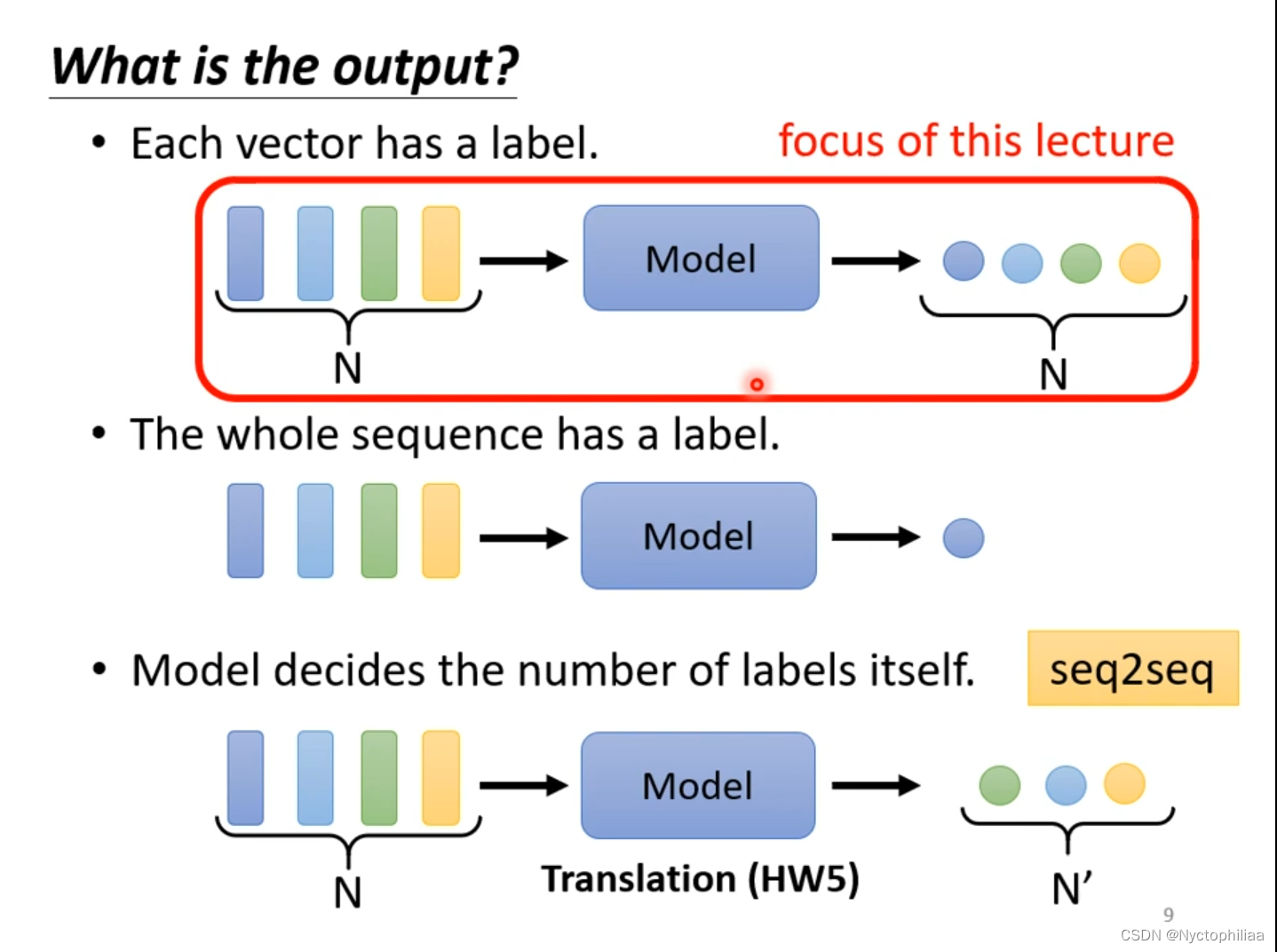
六、What is the output?
1、每一个向量都有一个label,也就是模型输入有n个向量,输出就有n个label。文字处理,现在要做POS tagging,它主要是得到词汇的词性。在图中有两个saw,一个是动词,另一个是名词,这个就是文字处理的难点。语音辨识,图中的每一个向量得到对应的音标。
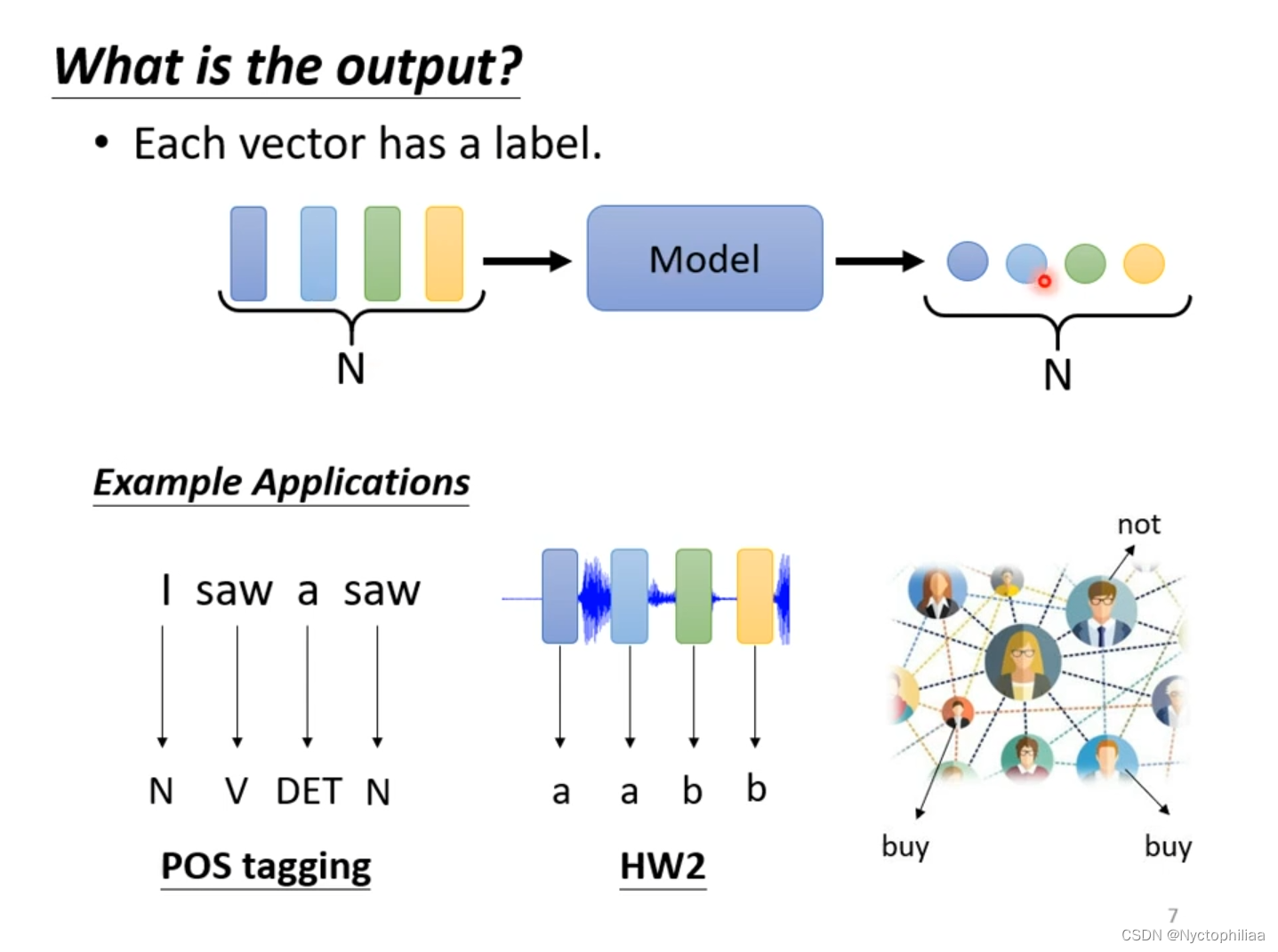
2、整个sequence只有一个label,比如说给定一句话,然后让机器判断这句话是积极的还是消极的。语者辨认,听一段声音讯号,判断是谁说的。给一个分子,判断它是否带有毒性等特性。
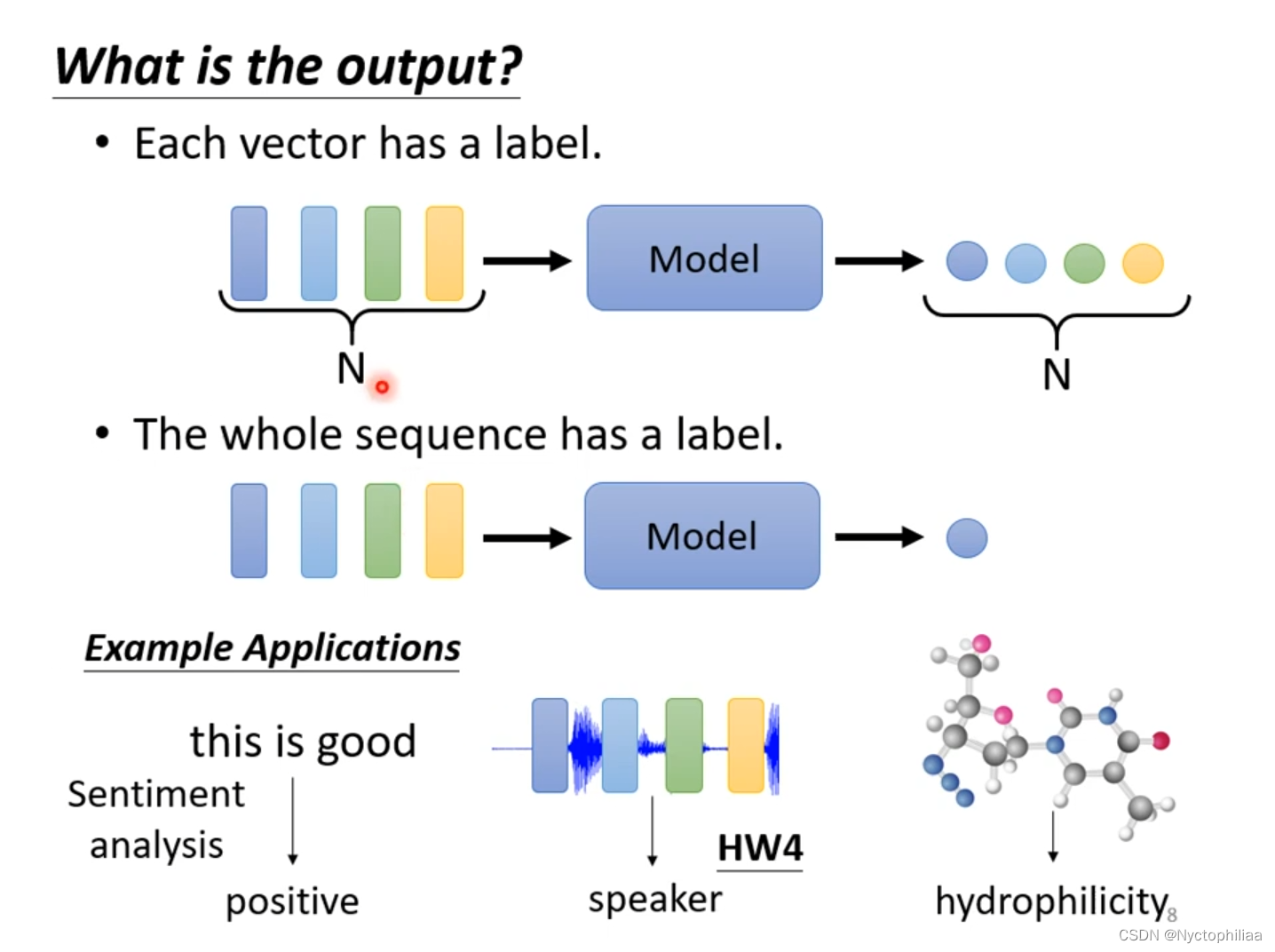
3、 输出label的数目取决于模型自己,例如语言翻译等。
七、Sequence Labeling
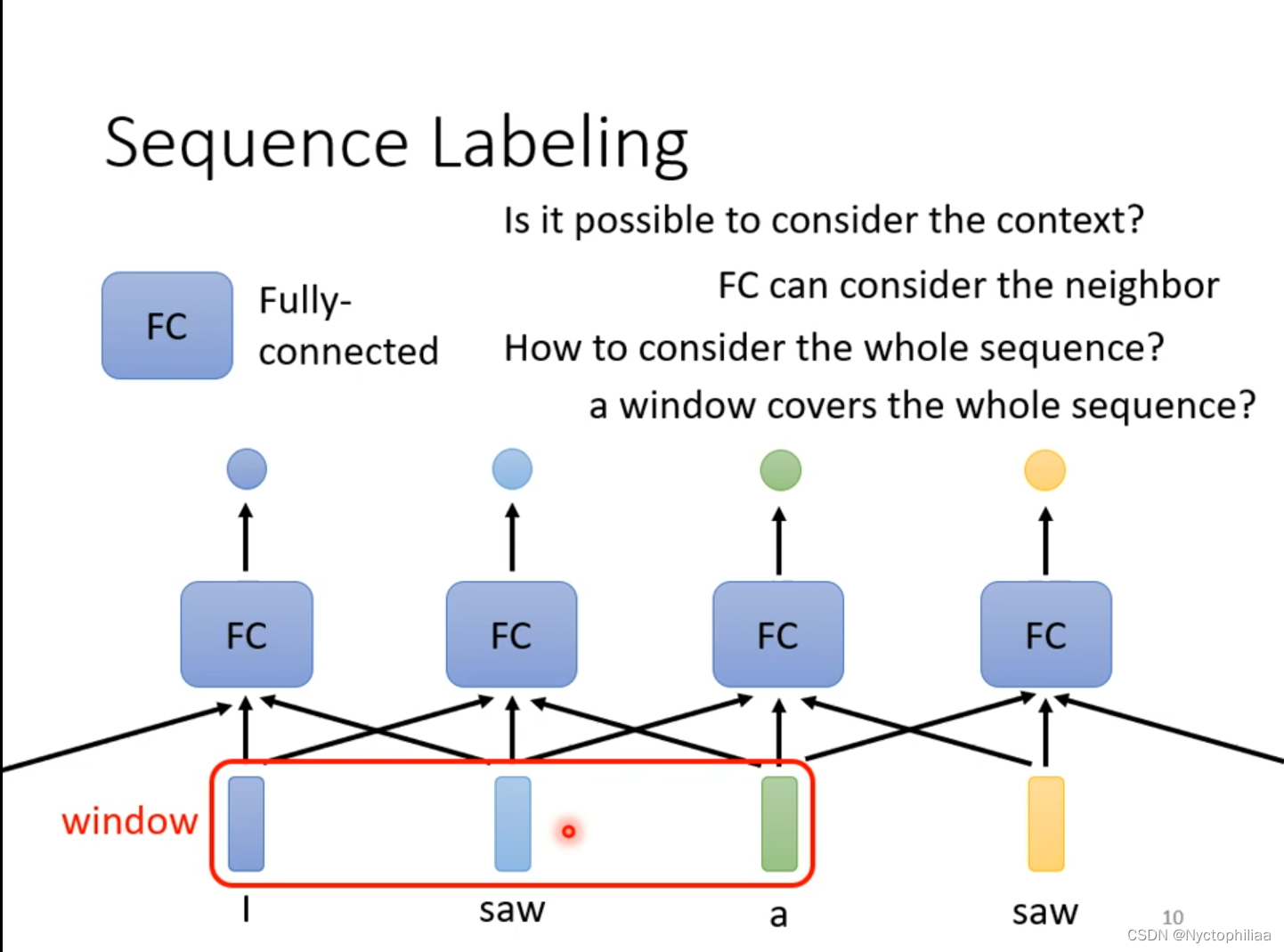
我们用Fully-connected对输入进行处理,得到正确的输出。但是现在存在一个问题,当输入的词汇有两个saw时,输出一个是动词,另一个是名词,但实际上是不可能有同一个输入有两个不同的输出。我们可以联系上下文来解决这个问题,给Fully-connected整个window的咨询。 现在某个任务需要考虑整个sequence,我们就用一个更大的window,但是这样不只是运算量大,还有可能造成overfitting。那我们应该怎么解决这个问题呢?
八、Self-attention
self-attention是一种在深度学习模型中捕捉输入序列中长距离依赖关系的机制。自注意力的核心思想是计算输入序列元素之间的相互关系,从而使模型能够关注到与当前元素有关的其他相关元素。自注意力机制在自然语言处理(NLP)和计算机视觉(CV)等领域具有广泛的应用。
Self-attention就是把整个sequence作为输入,输入多少个向量,输出也就多少个向量。然后把输出放入Fully-connected,得到最后的结果,现在的Fully-connected考虑了整个sequence。
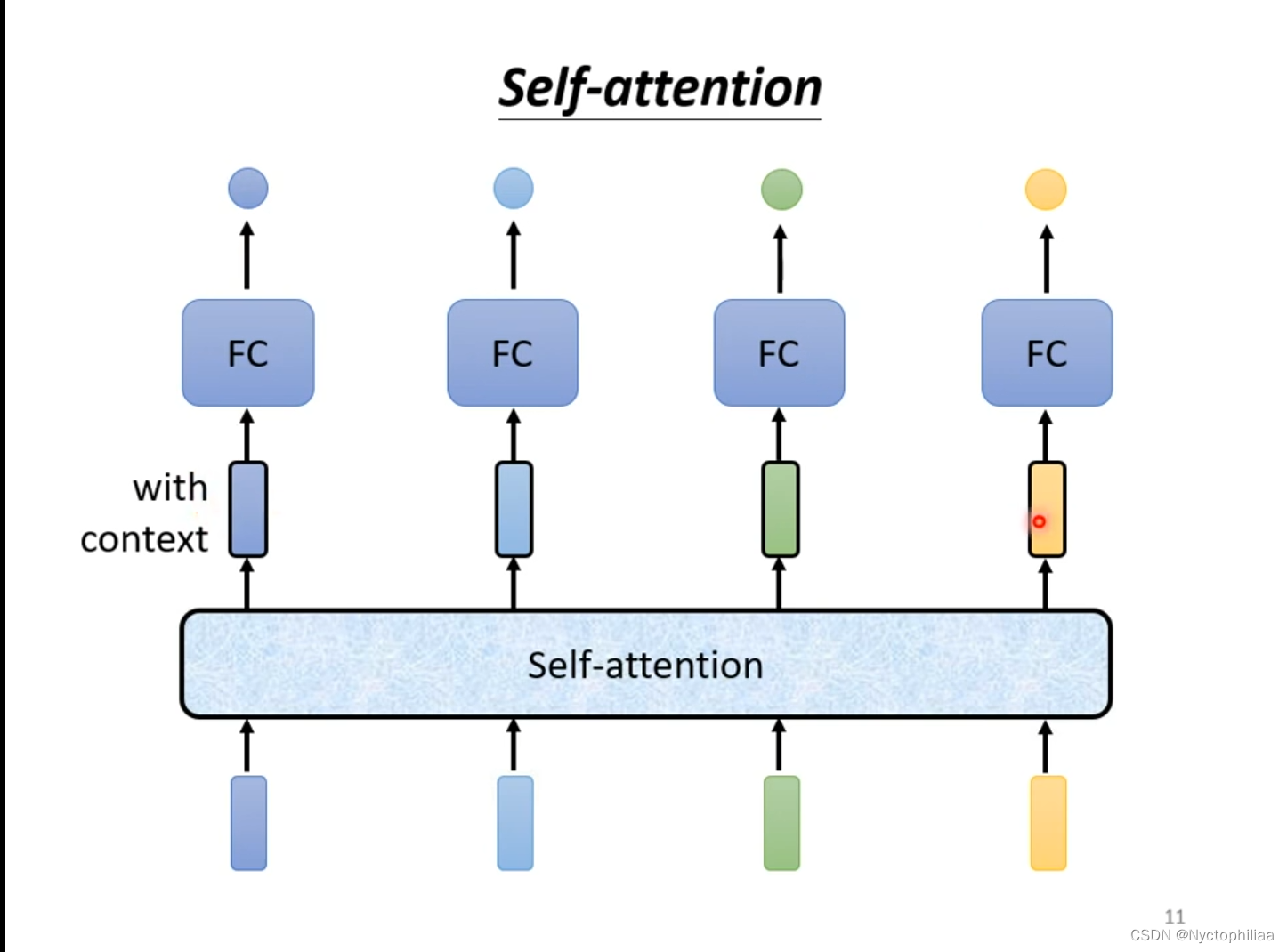
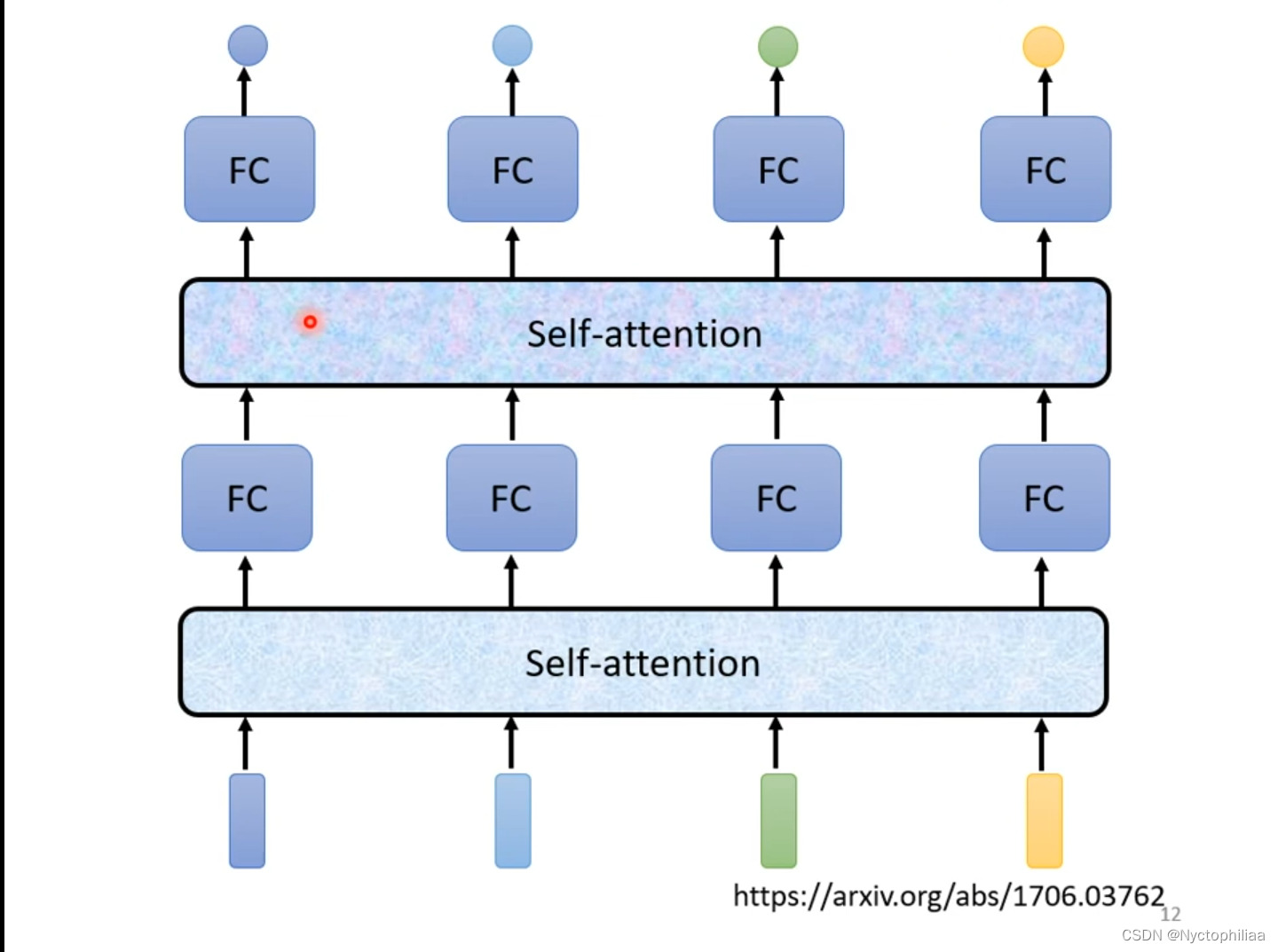
Self-attention也可以叠加多次使用。
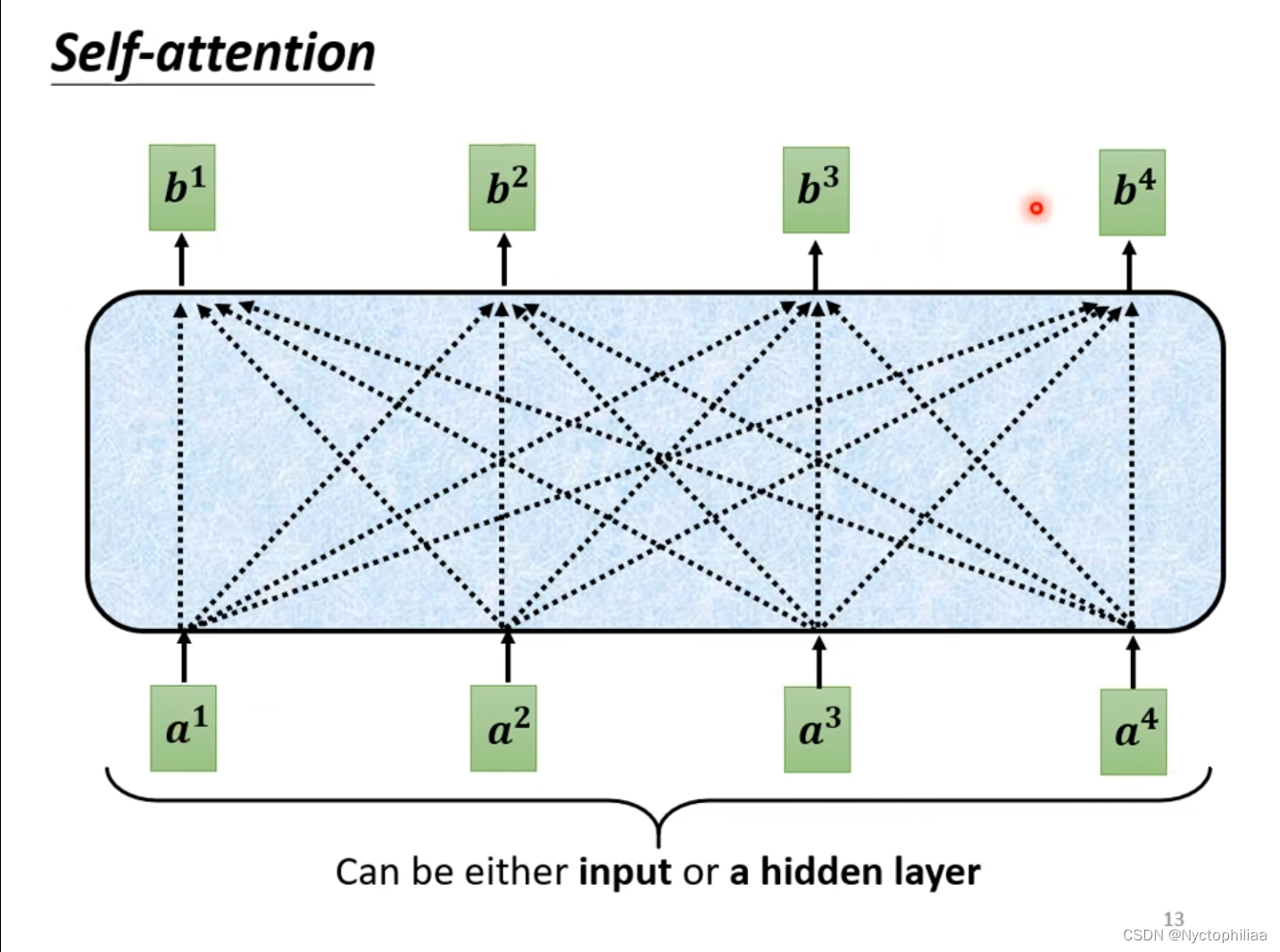
Self-attention的input是一串vector,vector可能是整个network的input,也可能是某个hidden layer的output。如下图所示,图中的b都是考虑了所有a得出的结果。
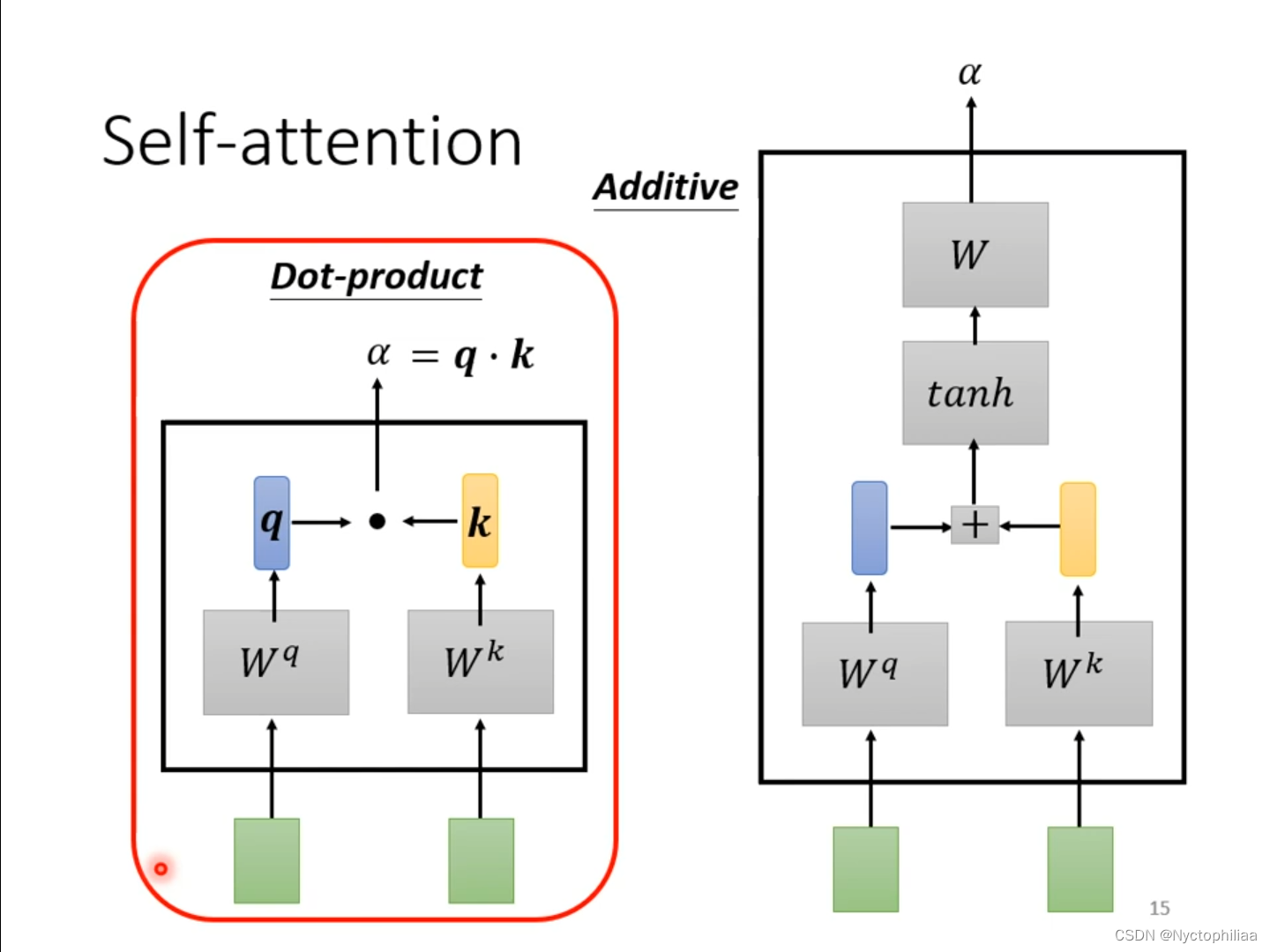
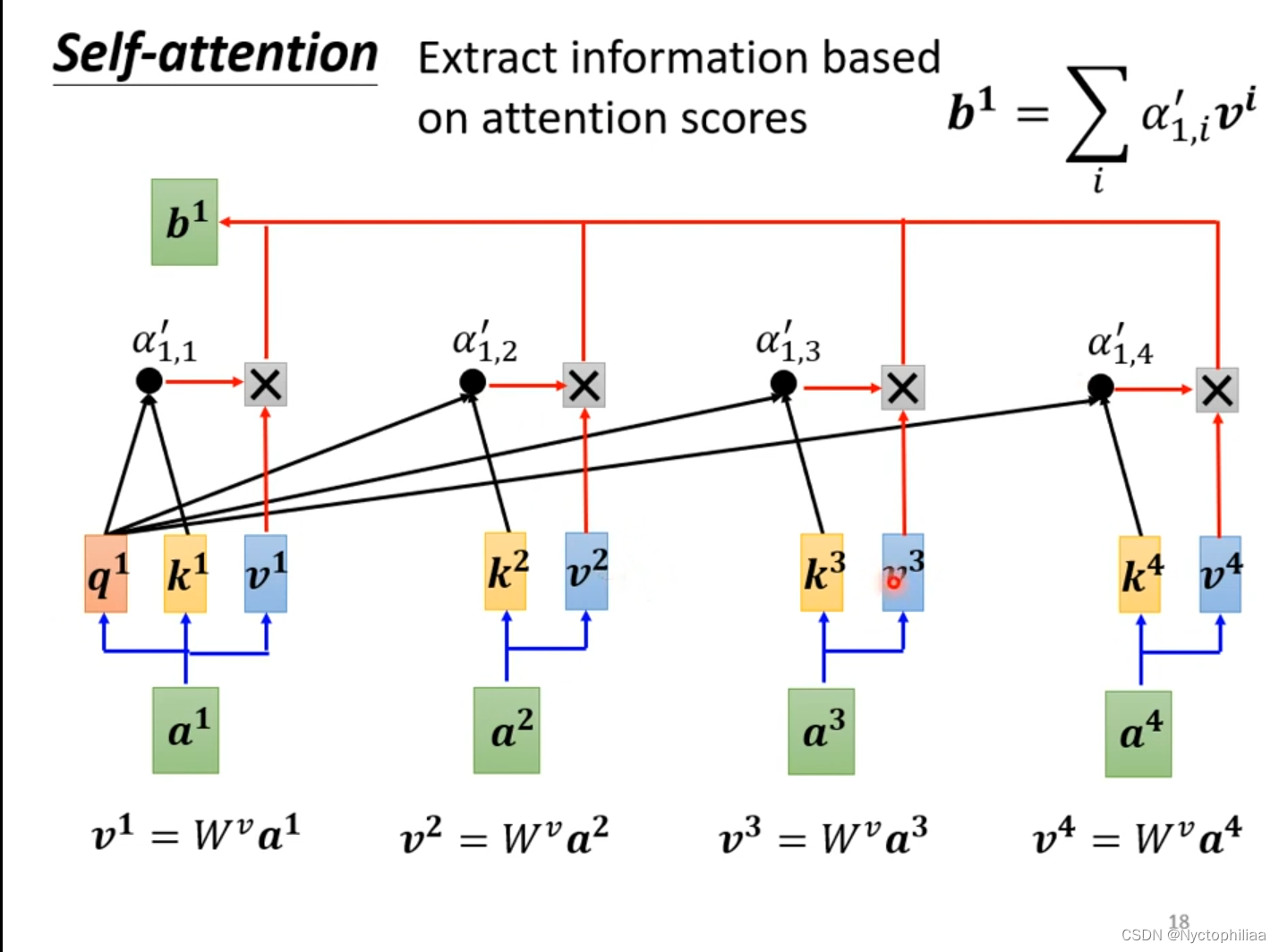
举例说明产生b1向量的过程,其它b向量的产生的过程与之类似。首先找出sequence中与a1相关的其它向量,其它向量与a1相关的程度用α表示。常见的做法是Dot-product,将输入的两个向量分别乘上两个不同的矩阵,得到q和k,q和k相乘并求和后得到相关性α。另外一种做法是Additive,将输入的两个向量分别乘上两个不同的矩阵,然后加起来输入到激活函数tanh,再经过Transform得到相关性α。
如下图所示,不仅要a1和a2、a3、a4求关联性α,还要计算a1与自己的关联性α,然后对α1,1、α1,2、α1,3、α1,4求Soft-max,然后得到输出为一排α。我们需要根据相关性来抽取重要的咨询,把v1、v2、v3、v4分别乘上attention分数,然后加起来得到b1。这里不一定非要用soft-max,用激活函数ReLU也是可以的。
总结
本周学习的内容,让我懂得了在机器翻译和图像识别中,图像的移动和缩放所要用到的新的知识,以及在机器翻译中,不仅要对一个词汇进行翻译,而是要考虑上文和下文的语义,如果sequence过长的话,用self-attenion是一种很好的方式。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)