Hadoop计算框架的发展与挑战:从MapReduce到Tez的演变
MapReduce 和 Tez 都是用于大规模数据处理的计算框架,它们都可以将计算任务分布在集群中的多个节点上并行执行。然而,它们在设计理念、编程模型和性能优化方面存在一些区别。特点MapReduceTez数据处理处理静态数据处理静态和流式数据性能迭代计算和交互式处理性能较差供更高的性能和更低的延迟交互式查询不支持支持资源利用率资源利用率较低资源利用率较高DAG不支持支持核心框架独立框架基于Had
大数据计算引擎是处理海量数据的重要工具,随着数据量的不断增长和多样化,传统的数据处理方式已经无法满足人们的需求。近年来,随着分布式计算技术的发展,出现了许多大数据计算引擎,可分为以下四代:MapReduce 、Tez、Spark 和 Flink。
MapReduce 是最早被广泛采用的分布式计算框架之一,由Map和Reduce两个阶段组成。在 Map 阶段,输入数据被拆分成多个小的数据块,并由多个 Mapper 并行处理。每个 Mapper 将输入数据块转换为键值对(key-value pairs),并将其输出作为中间结果。在 Reduce 阶段,中间结果被传递给多个 Reducer 并行处理。Reducer 将相同键的所有值进行合并和聚合,生成最终的输出结果。MapReduce 提供了高可靠性和容错性,并且能够处理大规模数据集。
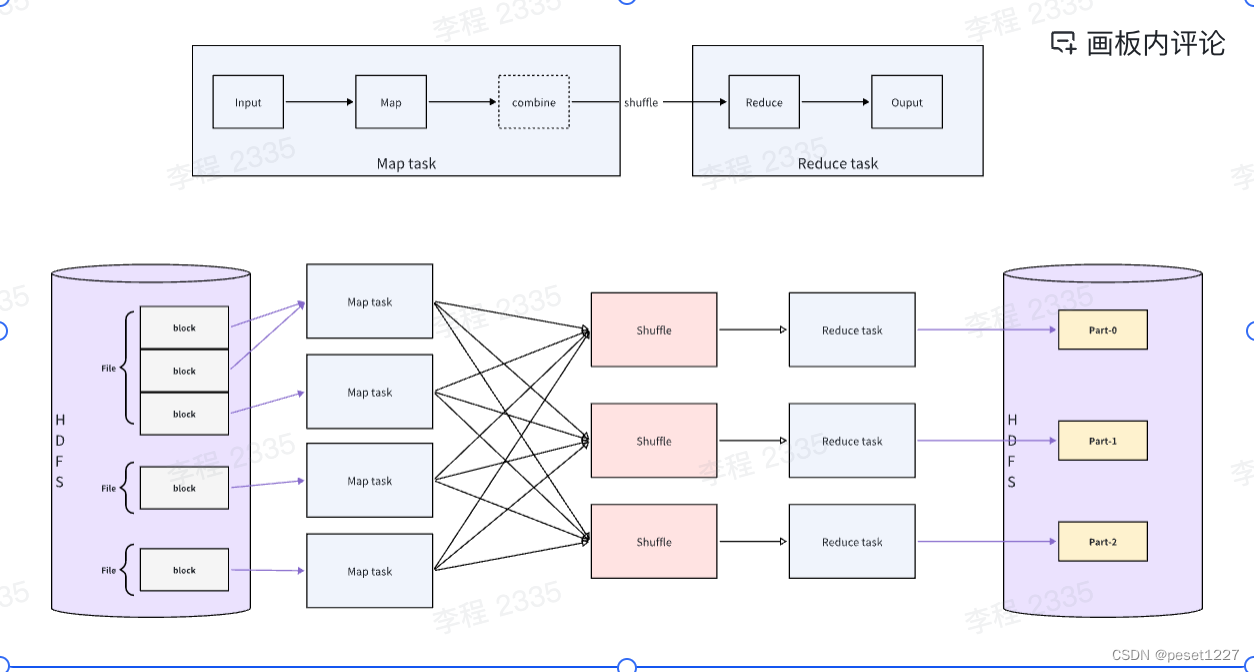
将任务分为两个阶段的主要原因是为了充分利用并行处理的优势,提高数据处理的效率和可扩展性:
-
Map 阶段可以在多个节点上同时进行处理,每个 Mapper 独立处理自己的数据块。这样可以有效地利用集群中的计算资源并加速整体处理速度。
-
Reduce 阶段则将中间结果进行合并和聚合,可以在多个节点上同时进行处理,每个 Reducer 独立处理自己负责的键值对。
-
Map 的原理和运行流程
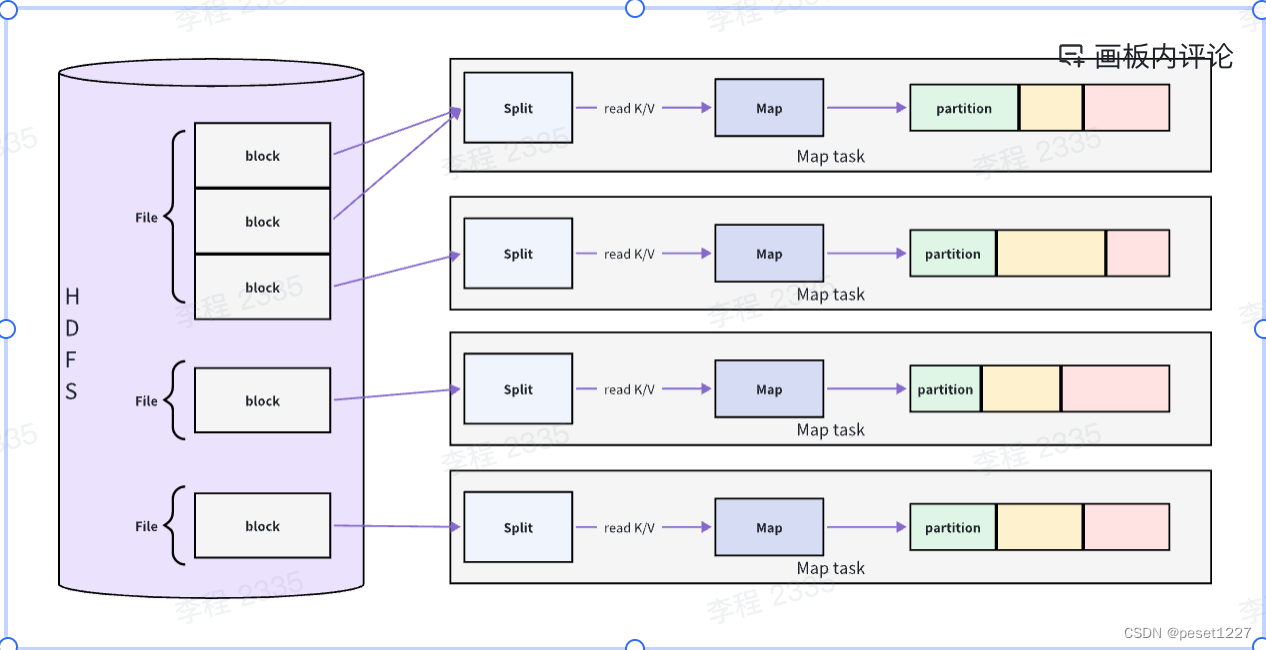
Map 的输入数据源是多种多样的,通常使用 hdfs 作为数据源。文件在 hdfs 上是以 block(块,hdfs上的存储单元)为单位进行存储的。
-
分片
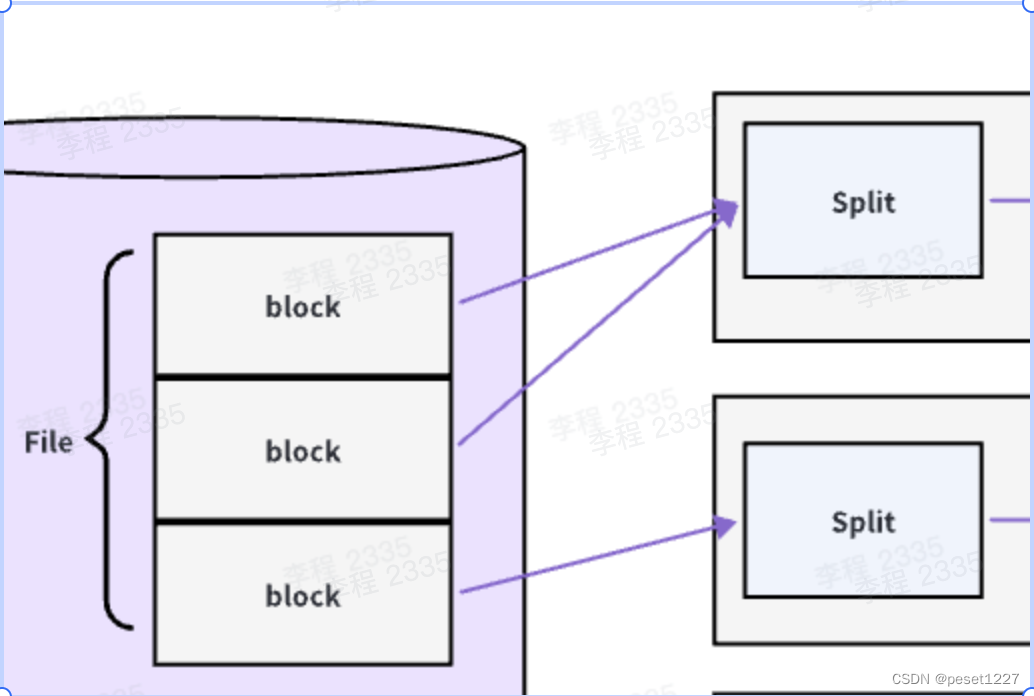
MR 将这一个个 block 划分成数据分片,即 Split(分片,逻辑划分,不包含具体数据,只包含这些数据的位置信息),那么上图中的第一个 Split 则对应两个文件块,第二个 Split 对应一个块。需要注意的是一个 Split 只会包含一个File 的 block,不会跨文件。
-
数据读取和处理

当 MR 把数据块分好的时候,MapReduce 程序将这些分片以 key-value 的形式读取出来,并且将这些数据交给用户自定义的 Map 函数处理。eg: 读取words.txt中第一行(hello mapreduce),输出:(hello,1),(mapreduce,1)。
-
MapReduce 计算框架处理

用户处理完这些数据后同样以 key-value 的形式将这些数据写出来交给 MapReduce 计算框架。MapReduce 框架会对这些数据进行划分,此处用颜色进行表示。不同颜色的 partition 矩形块表示为不同的 partition,同一种颜色的 partition 最后会分配到同一个 reduce 节点上进行处理。eg: 以不同的key可划分为3个 partition:(hello,{1,1}),(mapreduce,1),(world,1)或者以key的hash值分为三个 partition。
一个map指挥处理一个 Split
map 处理完的数据会分成不同的 partition(默认使用的是 hash 算法对 key 值进行划分)
一类 partition 对应一个 reduce
一个 MapReduce 程序中 map 的数量是由 split 的数量决定的,reduce 的数量是由 partiton 的数量决定的
-
Shuffle
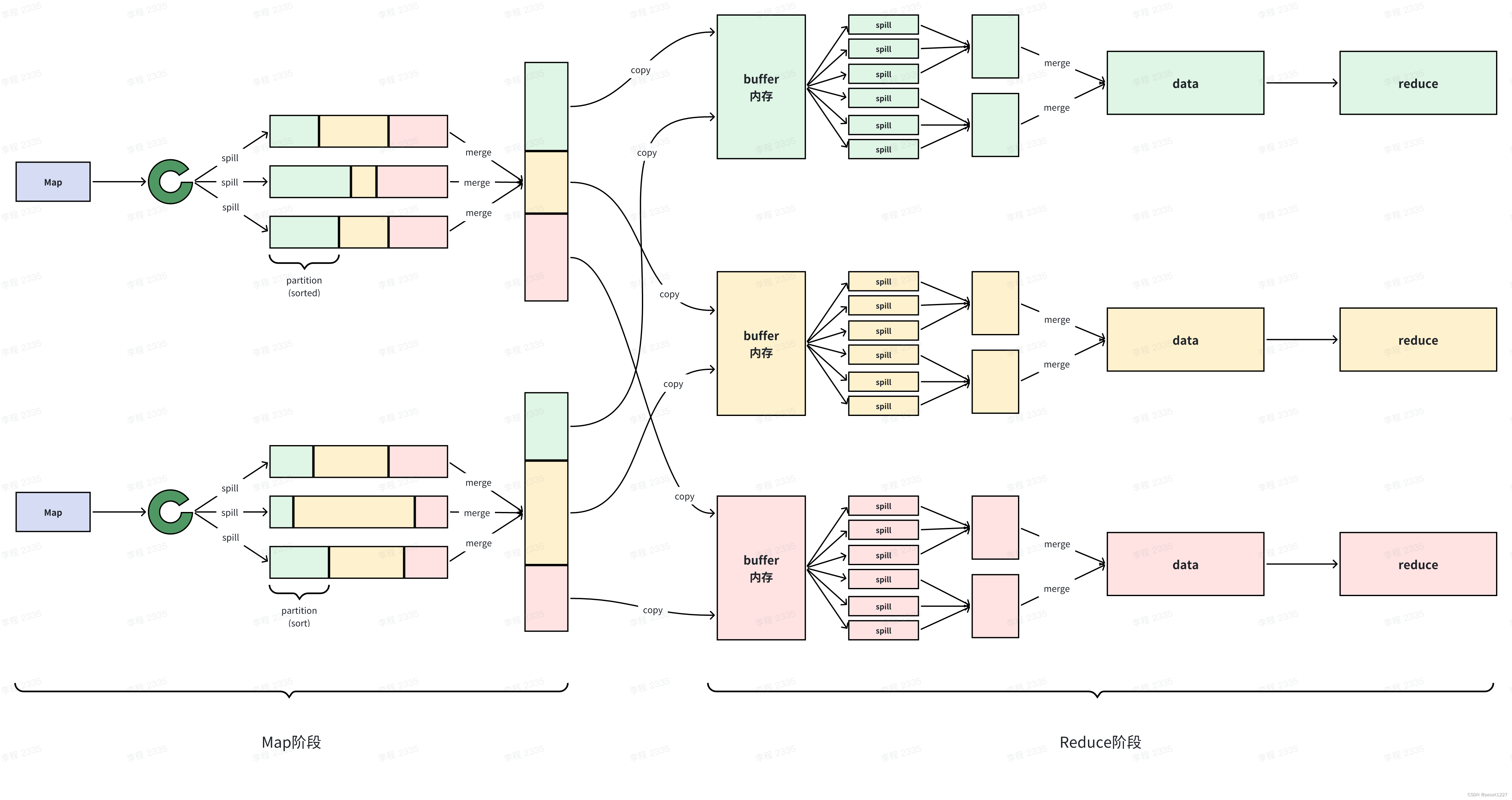
在 MapReduce 中,shuffle 阶段是将 map 端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce 端接收处理。其在 MapReduce 中所处的工作阶段是 map 输出后到 reduce 接收前,具体可以分为 map 端和reduce 端前后两个部分。
-
Map 阶段的 shuffle
数据经过 map 函数处理完成之后,会放入内存中的环形缓冲区进行排序,最终产生一个有序的文件。具体步骤总结为以下四点:
-
Collect 阶段将数据放进环形缓冲区,缓冲区分为数据区和索引区。
-
Sort 阶段对在同一 partition 内的索引按照 key 排序。
-
Spill 阶段根据排好序的索引将数据按照顺序写到文件中。
-
Merge 阶段将 Spill 生成的小文件分批合并排序成一个大文件。
-
Reduce 阶段的 shuffle
reduce 节点会将数据拷贝到自己的 buffer 缓存区中,当缓存区中的数据达到一定的比例的时候,同样会发生溢写成一个有序的文件。与此同时,后台会启一个线程,将这些小文件合并成一个有序大文件(相同的key值对应的value值是挨在一起的)。最后,将这些数据交给 reduce 程序进行聚合处理。具体步骤总结为以下三点:
-
Copy 阶段将 Map 端的数据分批拷贝到 Reduce 的缓冲区。
-
Spill 阶段将内存缓存区的数据按顺序写到文件中。
-
Merge 阶段将溢出的文件合并成一个排序的数据集。
-
Reduce 运行过程
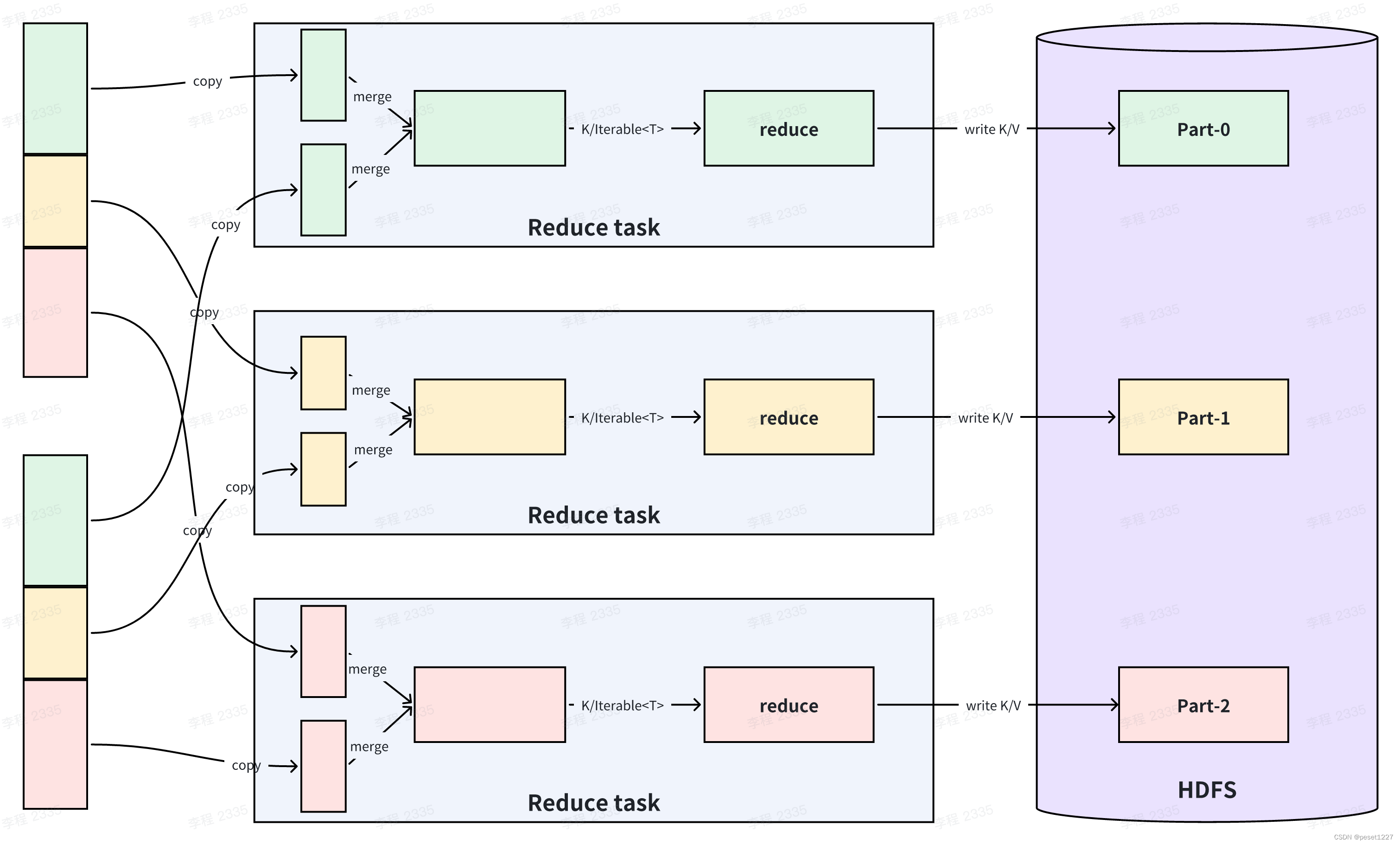
在 map 处理完之后,reduce 节点会将各个 map 节点上属于自己的数据拷贝到内存缓冲区中,最后将数据合并成一个大的数据集,并且按照 key 值进行聚合(shuffle 阶段得到的大数据集),把聚合后的 value 值作为 iterable (迭代器)交给用户使用,这些数据经过用户自定义的 reduce 函数进行处理之后,同样会以 key-value 的形式输出出来,默认输出到 hdfs 上的文件。
-
Combine 优化(可选)
Combiner 是 MapReduce 中的一种优化手段,可以在不改变输出结果的情况下,更快地执行 MapReduce 作业。Combiner 的主要作用是在 Map 任务输出到网络传输之前,对输出结果进行局部汇总和压缩,减少 Map 任务输出的数据量,提高 MapReduce 作业的性能 。
在 Map 端,Combiner 可以将具有相同键值的键值对进行合并,从而减少需要处理的数据量,并且也能够减少shuffle 阶段传输的数据量,从而减少程序执行时间,提升系统性能 。eg: map 端先进行求和再输出,(hello,2),(mapreduce,1),(world,1)。
在 Reduce 端,Combiner 可以对来自不同 Map 任务的相同键值进行合并,从而减少需要处理的数据量,并且也能够减少 shuffle 阶段传输的数据量,从而减少程序执行时间,提升系统性能。
-
从 MapReduce 到 Tez 的演变
MapReduce 作为一个分布式的计算框架可以将计算程序部署到大量廉价的 PC 机器上运行,可以实现上千台服务器集群并发工作,提供数据处理能力。当计算资源不能得到满足时,可简单通过增加机器来扩展计算能力。其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
随着大数据和实时计算的迅速发展,第一代计算引擎 MapReduce 在处理大规模数据时遇到了一些挑战:
-
数据来源只能是静态的,不支持流式数据处理,这意味着在迭代计算、交互式处理和实时处理方面表现不佳。
-
由于多个应用程序存在依赖关系,每个MapReduce作业的输出结果都会写入磁盘中,这会导致大量的磁盘IO,降低性能并延长计算时间。
为了解决这些问题,出现了第二代计算引擎Tez。Tez是一个基于 Hadoop YARN 的资源管理和任务调度框架,它不仅支持批处理模型,还支持流式数据处理。Tez 直接源于 MapReduce 框架,核心思想是将Map 和 Reduce 两个操作进一步拆分,分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的 DAG 作业。从而允许基于有关数据的真实信息以及处理数据所需的资源进行动态性能优化。与 MapReduce 相比,Tez 具有更高的资源利用率和更低的延迟,使其更适合于大规模数据集的处理和实时计算场景。
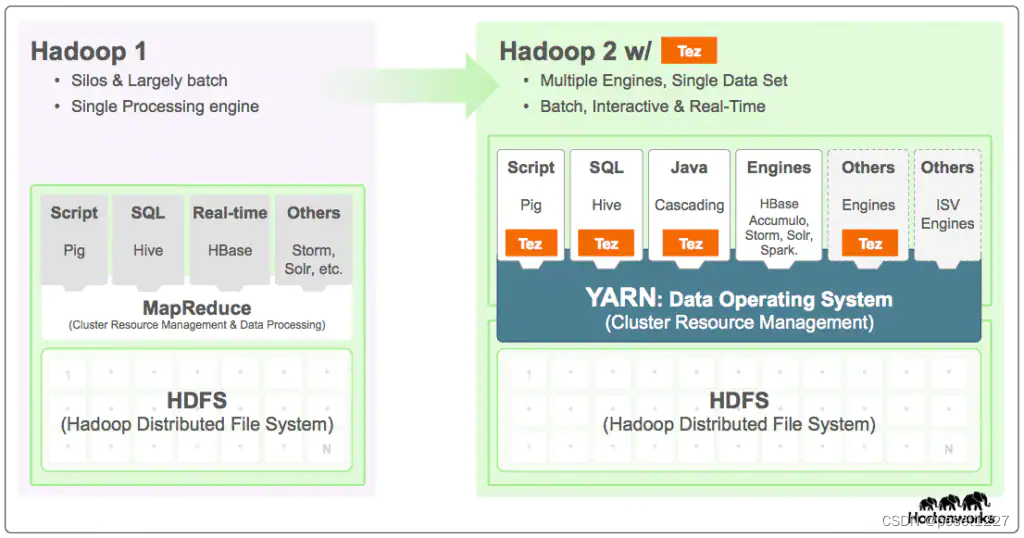
Tez工作特性
通过允许像 Apache Hive 和 Apache Pig 这样的项目运行复杂的 DAG 任务,Tez 可以用来处理数据,以前需要多个 MR 作业,现在在单个 Tez作业中,如下所示可以减少 Map/Reduce 之间的文件存储,合理组合其子过程,减少任务运行时间。
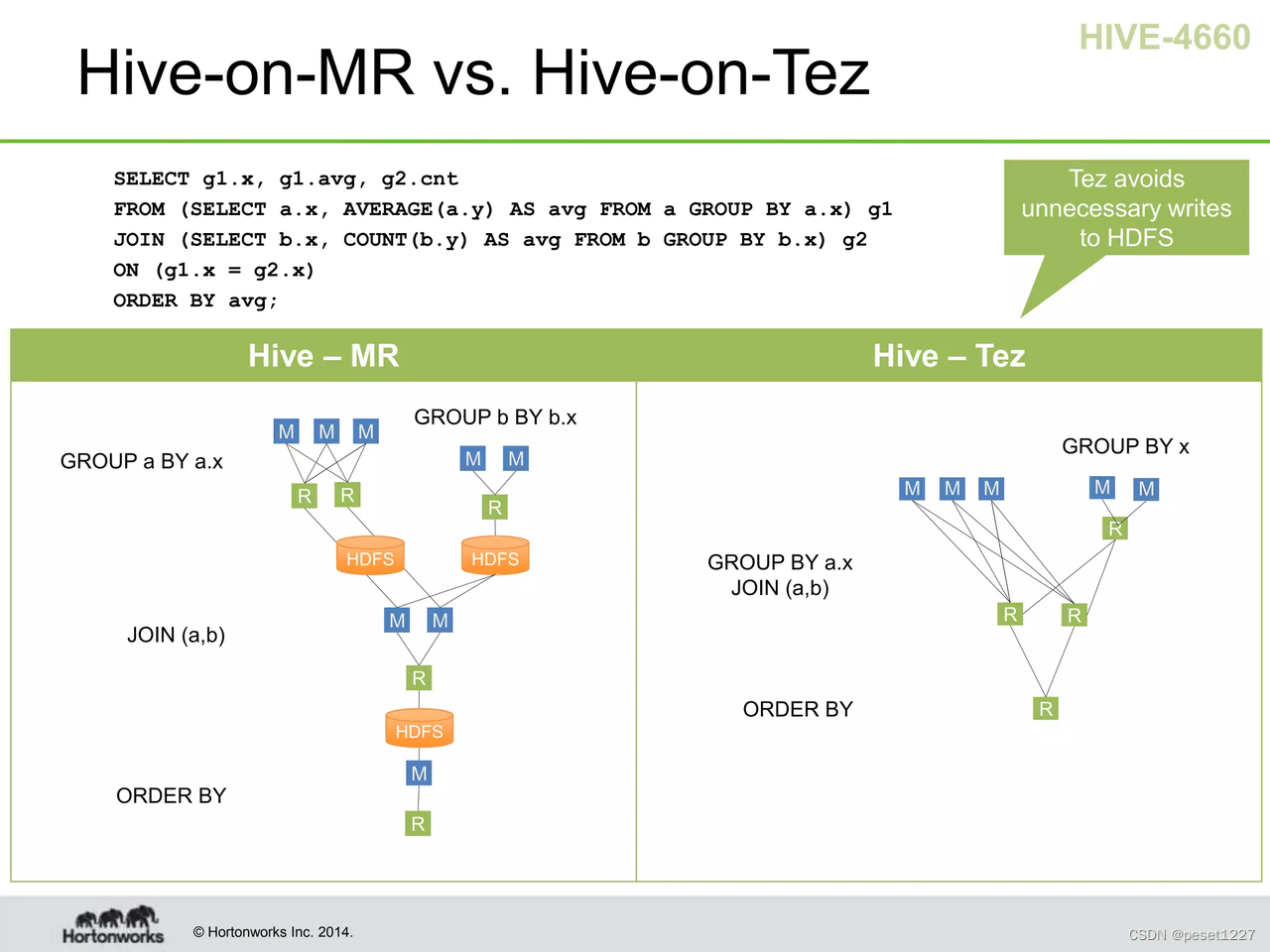
表达、建模和执行处理逻辑
Tez 将数据处理建模为数据流图,其中图顶点表示应用程序逻辑,其连接线表示数据移动。丰富的数据流定义 API 允许用户直观地表达复杂的查询逻辑。该 API 非常适合由更高级别的声明性应用程序(如 Apache Hive 和 Apache Pig)生成的查询计划。
Input、Processor和Output模块之间的交互模型
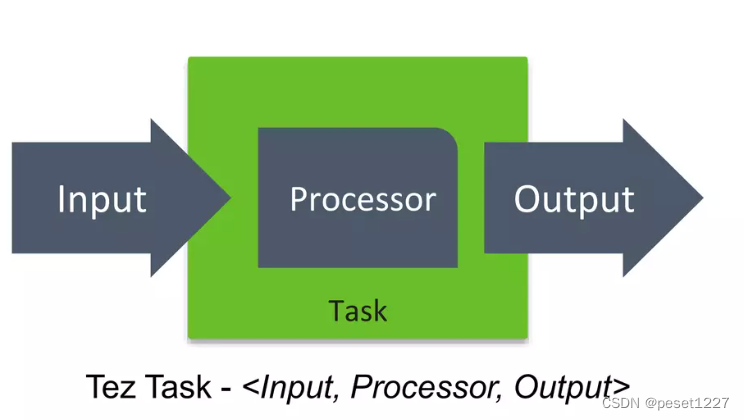
Tez 将数据流图的每个顶点中运行的用户逻辑建模为 Input、Processor 和 Output 模块的组合。Input 和Output决定了数据格式以及读取或写入的方式和位置。Processor 保存数据转换逻辑。Tez 不强加任何数据格式,只要求输入、处理器和输出格式相互兼容。
动态重调整数据流图
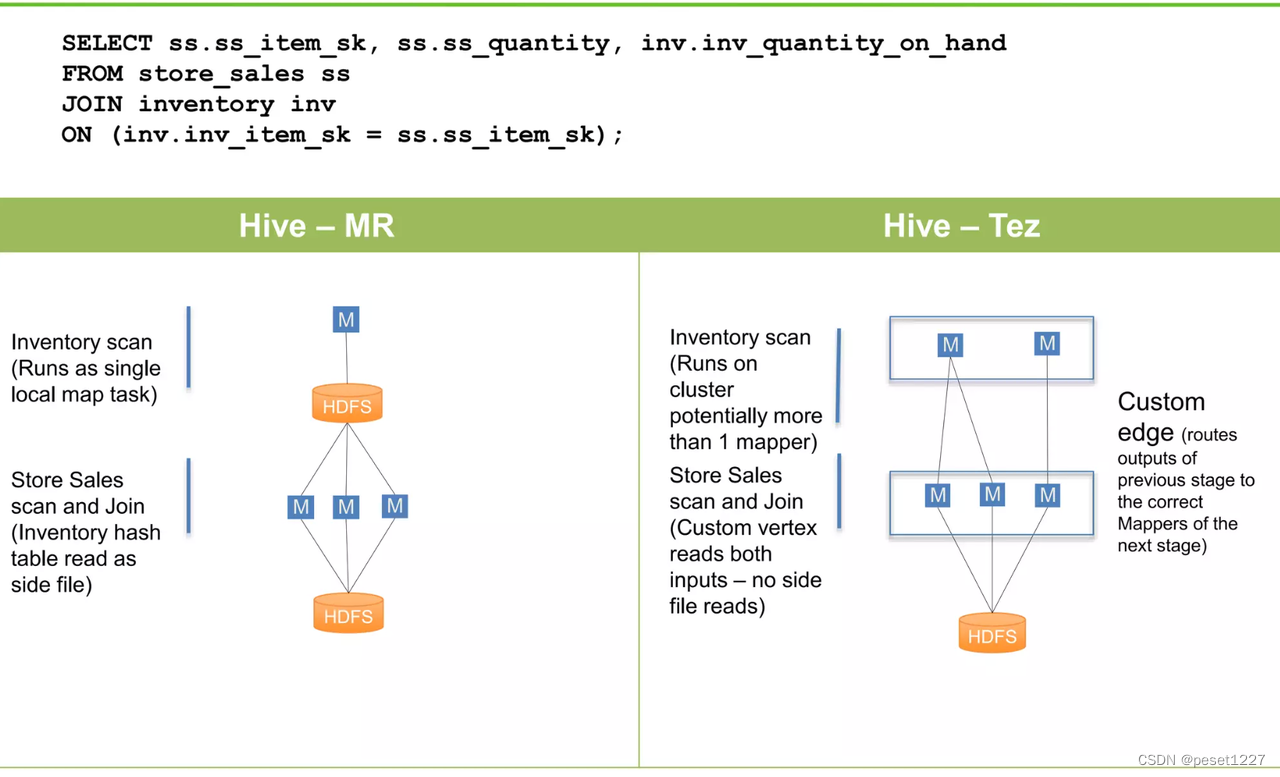
分布式数据处理是动态的,很难提前确定最优的数据移动方法。在运行时提供了更多信息,这可能有助于进一步优化执行计划。因此,Tez 包括对可插入顶点管理模块的支持,以收集运行时信息并动态更改数据流图以优化性能和资源利用率。
优化性能和资源管理
YARN 根据集群容量和负载管理 Hadoop 集群中的资源。Tez 执行引擎框架有效地从 YARN 获取资源,能够及时的释放资源,重用 container,节省调度时间,对内存的资源要求率不高。
对于 Tez,它的容错机制相对较弱。当一个任务失败时,Tez 会停止整个作业的执行,并需要手动处理失败的任务或重新启动整个作业。这可能导致一些数据丢失和执行延迟。另外 Tez 只支持 yarn 的运行模式。
总结
MapReduce 和 Tez 都是用于大规模数据处理的计算框架,它们都可以将计算任务分布在集群中的多个节点上并行执行。然而,它们在设计理念、编程模型和性能优化方面存在一些区别。
| 特点 | MapReduce | Tez |
| 数据处理 | 处理静态数据 | 处理静态和流式数据 |
| 性能 | 迭代计算和交互式处理性能较差 | 供更高的性能和更低的延迟 |
| 交互式查询 | 不支持 | 支持 |
| 资源利用率 | 资源利用率较低 | 资源利用率较高 |
| DAG | 不支持 | 支持 |
| 核心框架 | 独立框架 | 基于Hadoop YARN |
| 扩展性 | 受限于MapReduce作业格式和数据分布情况 | 更灵活,可嵌入其他计算框架中 |
| 磁盘I/O | 需要将结果写入磁盘,导致增加计算时间 | 基于实际数据信息进行动态性能优化 |
| 适用场景 | 适合批处理大数据集的离线计算任务 | 适合实时数据处理和复杂分析任务 |

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)