大语言模型本地部署及应用(二): 保留原格式英文PDF翻译—PDFMathTranslate
写了两个多小时终于把第一篇内容整理完了,接下来我来整理一下今天上午尝试的PDF原格式全文翻译开源软件-PDFMathTranslate的部署和使用如果想本地离线完成英文PDF翻译任务,可以参考本篇文章。但是需要自己部署的话,建议先根据我上一篇文章把Ollama部署一下。为什么我不一次弄完,因为篇幅太长了。此外,在弄这个软件之前,我还使用了“沉浸式翻译”这个插件,但是我觉得这个插件不适合我,有需要的
大语言模型本地部署及应用(二): 保留原格式英文PDF翻译—PDFMathTranslate
0 前言
写了两个多小时终于把第一篇内容整理完了,接下来我来整理一下今天上午尝试的
PDF原格式全文翻译开源软件-PDFMathTranslate的部署和使用
如果想本地离线完成英文PDF翻译任务,可以参考本篇文章。但是需要自己部署的话,建议先根据我上一篇文章把Ollama部署一下。为什么我不一次弄完,因为篇幅太长了。
此外,在弄这个软件之前,我还使用了“沉浸式翻译”这个插件,但是我觉得这个插件不适合我,有需要的可以自己去学一下,我这里提一嘴,后续可能也会记录我之前做的关于这个的相应的内容。
在这里就需要安装有Conda环境了,然后还需要会使用终端运行命令行完成操作。
当然要是你觉得conda过于臃肿,也可以使用官方介绍的uv完成下载和使用!
1 PDFMathTranslate
参考视频:PDF原格式全文翻译开源软件-PDFMathTranslate的部署和使用
PDFMathTranslate官网:PDFMathTranslate的GitHub官方说明
视频里没有介绍的可以自己看看官方文档,介绍的还是挺详细的!
2 部署环境
2.1 创建虚拟环境
使用命令行创建。
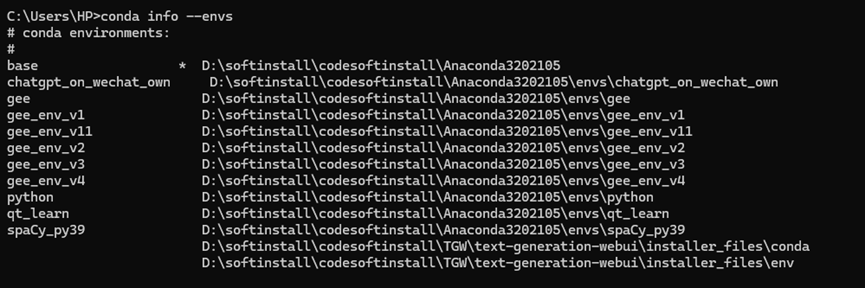
先查看一下我现在安装的虚拟环境,之前没管理好,安装的有一些乱。
conda info --envs
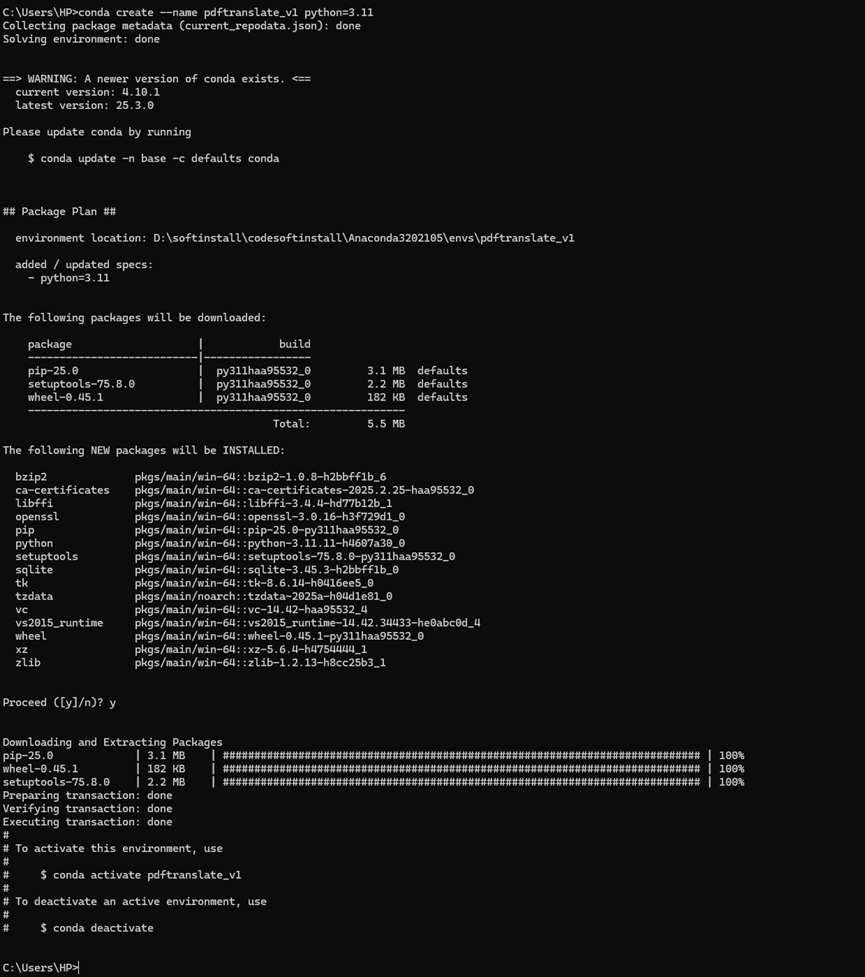
先再创建一个新的虚拟环境,使用python的3.11版本,然后命名为pdftranslate_v1。中间需要输入一个y。
conda create --name pdftranslate_v1 python=3.11
y
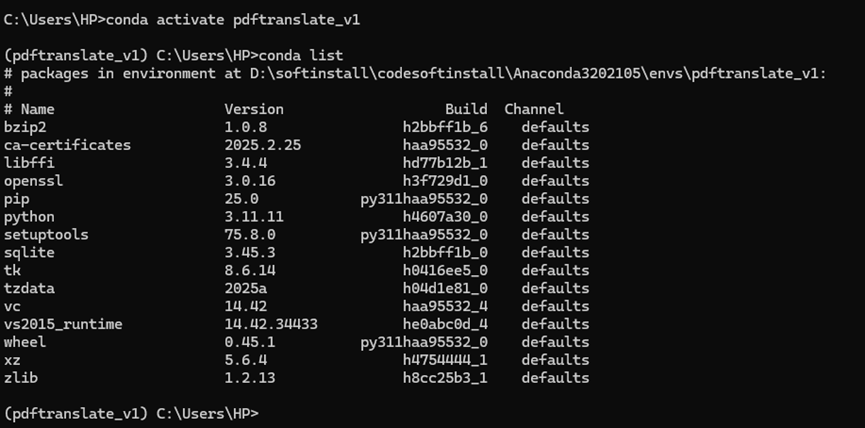
激活环境以及查看安装的包
conda activate pdftranslate_v1 # 激活环境
conda list # 查看安装包
2.2 安装库
输入安装命令,安装pdf2zh:(安装库时建议弄一个镜像源,之前都有提到过)
pip install pdf2zh

我运行完之后,好像还漏了一个库,导致后续操作不行,所以我这里提醒一下,我不清楚其他人的情况。
pip install argostranslate
自己看情况处理
以上就完成了软件PDFMathTranslate的安装。
3 PDFMathTranslate的使用流程
3.1 网页端使用
安装好pdf2zh这个库之后可以直接在命令行输入:pdf2zh -i进入网页,如果不小心把终端窗口关闭了,可以重新激活使用
conda activate pdftranslate_v1
pdf2zh -i
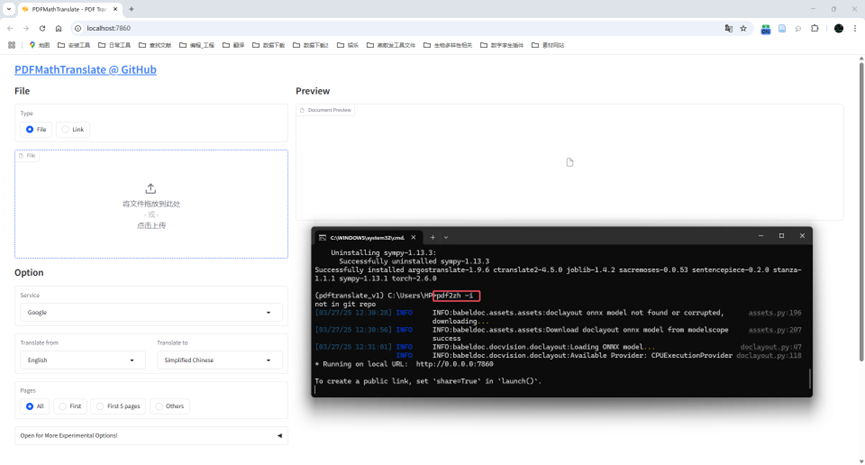
先简单用官方默认的 “谷歌翻译” 翻译一个文档:
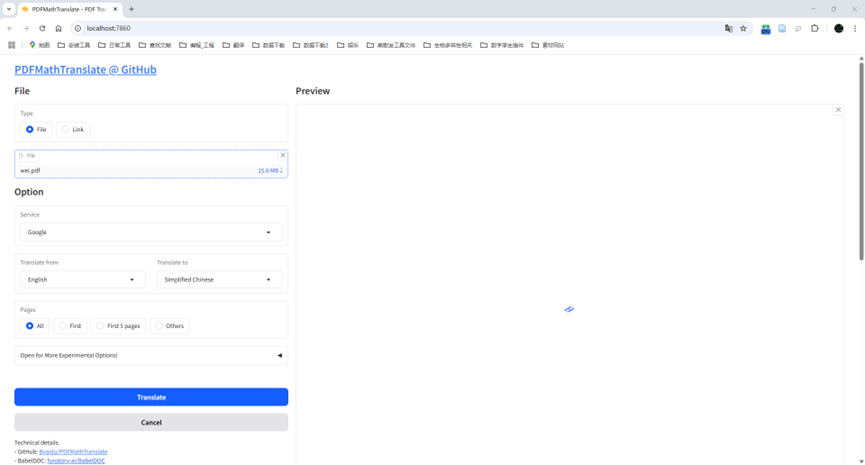
命令行狂报错,用不了谷歌翻译服务。
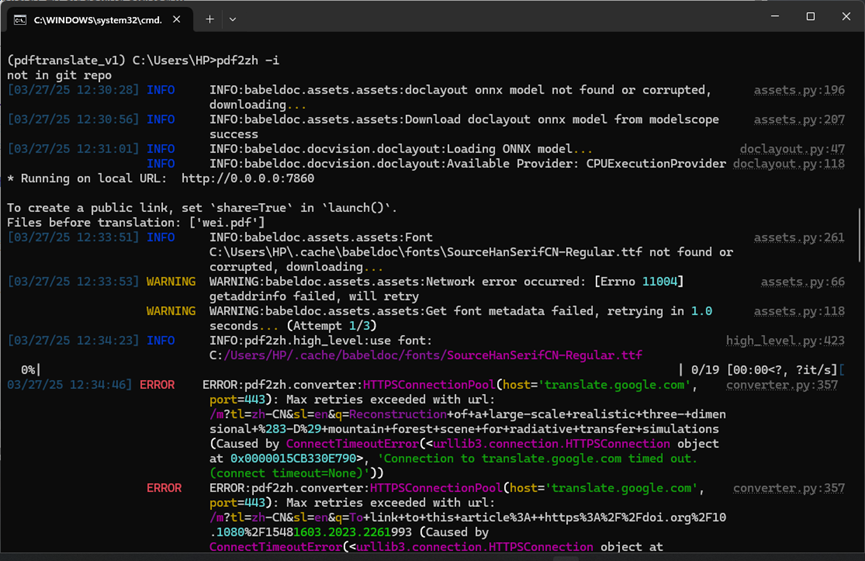
然后换一个 “bing翻译” 服务,没卡顿,能出现结果。

然后可以双语对照下载文档: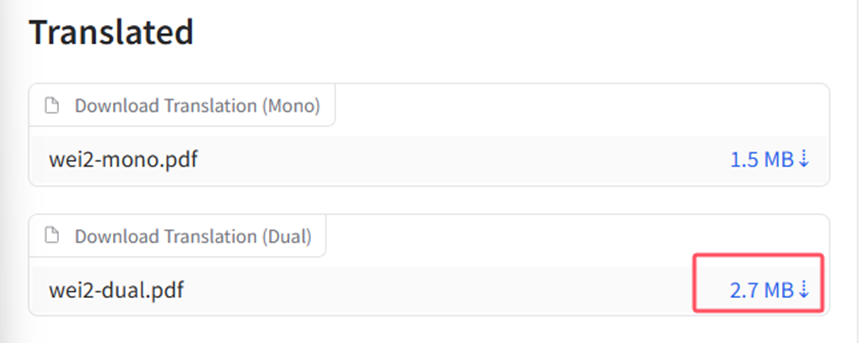

网页端接口还有其他的一些AI模型的接口,可以自己设置API,我这里就不介绍了。
3.2 终端命令行运行完成翻译
使用终端命令行窗口 完成翻译
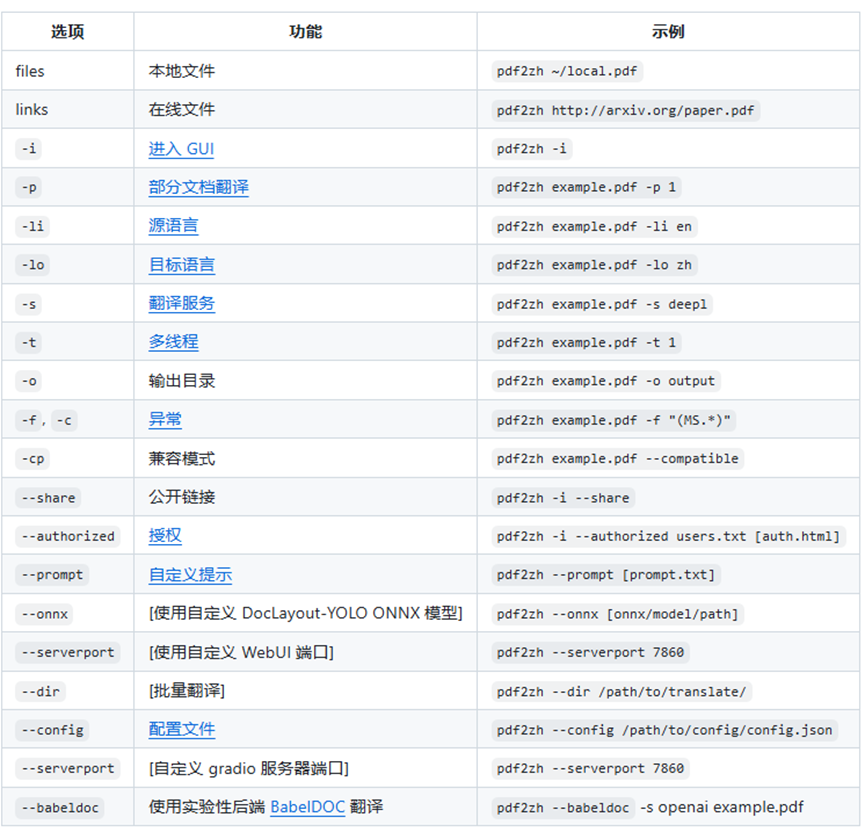
可以看看官网介绍的一些终端命令,如下:
(1)是全部翻译还是部分翻译:

(2)可以对指定路径的文件,如:
pdf2zh E:\data\datafile\研究生\阅读文献\2025\01\20250117\wei2.pdf
(3)还有目标语言的设置:
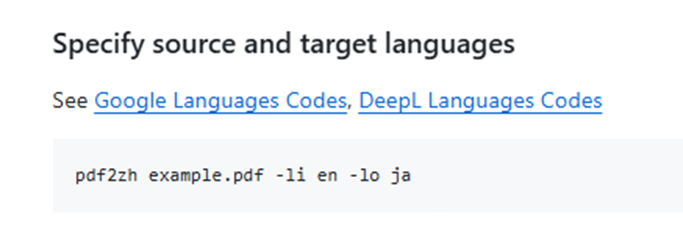
(4)设置翻译服务:具体翻译模型的Service命名见官网。

(5)确定输出目录:
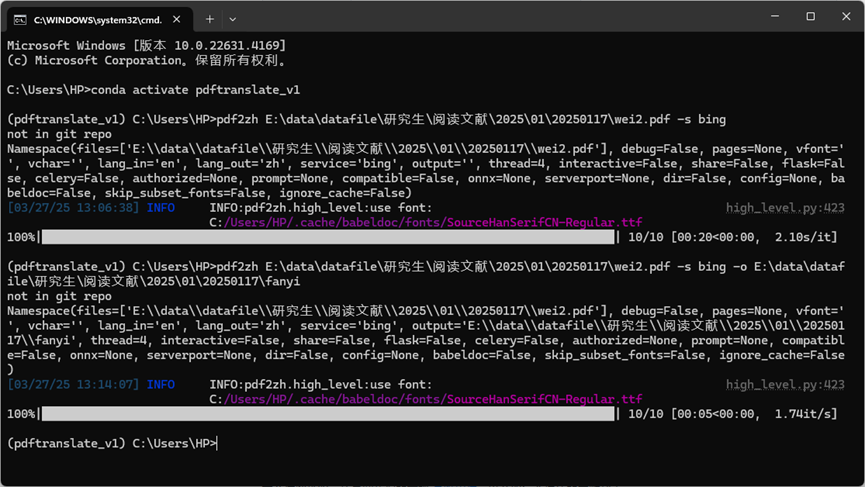
pdf2zh E:\data\datafile\研究生\阅读文献\2025\01\20250117\wei2.pdf -s bing -o E:\data\datafile\研究生\阅读文献\2025\01\20250117\fanyi
(6)其他一些命令内容:
(7) 输出结果:
命令行这里没有报错, “bing” 翻译服务速度不错
此外还有批量翻译的命令,可以自己看一下。
3.3 使用本地部署的大模型完成翻译
终于到本次目的的重点了:利用PDFMathTranslate使用ollama安装的本地大语言模型进行翻译。
(1)看看安装的模型
首先看看我自己本地的ollama安装的模型有那些:
先打开ollama服务:
使用命令也可以,直接点击exe文件也可以:
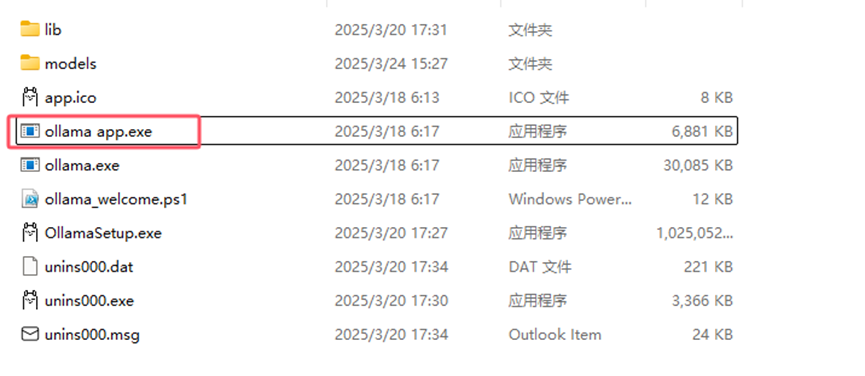
注意是带有app的这个exe文件,不是下面那个。
启动后右击空白地区,打开终端
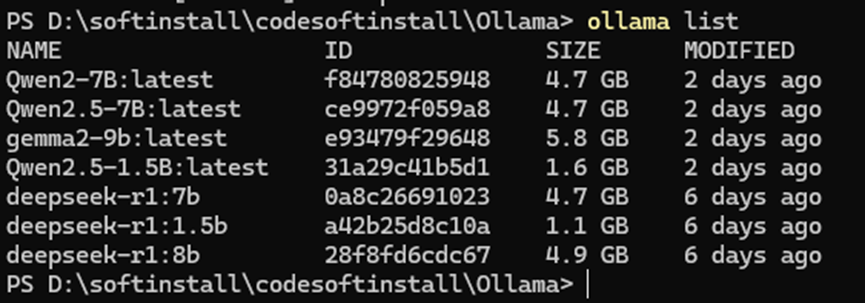
查看已安装的模型:ollama list
ollama list
(2) PDFMathTranslate配置Ollama
看看PDFMathTranslate配置本地模型的操作:
选择ollama服务(这里是网页运行),需要设置本地端口和模型名称:端口默认(如果你安装ollama的时候没有修改端口号,默认就是这个)
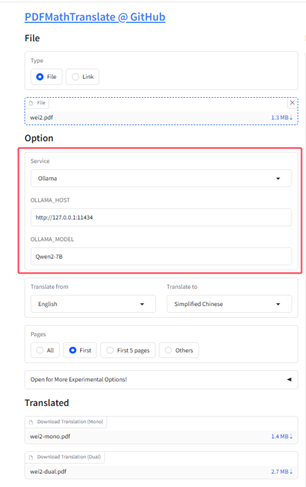
我使用本地安装的Qwen2-7B模型运行一下试一下效果:
然后效果还是不错的,就是慢了一些,但是我电脑的问题,不是模型的问题,有机会升级配置的时候应该会快不少:
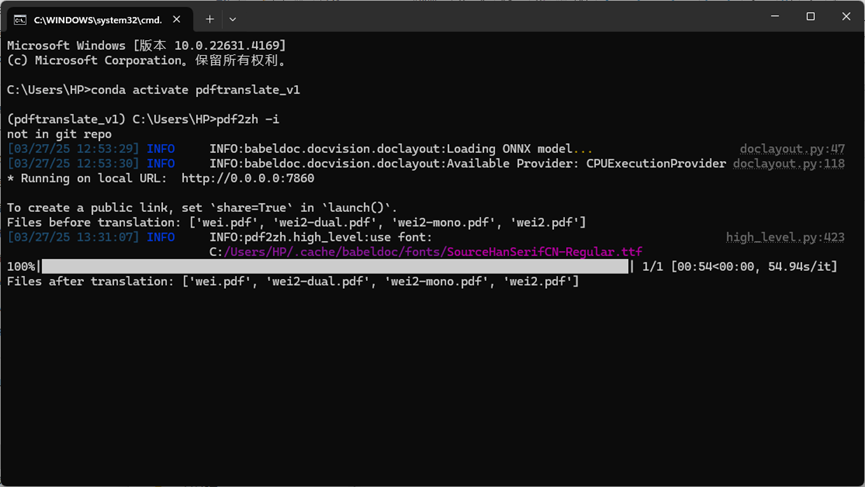
跟前面使用bing服务相比,还是慢很多的,但是我的能用本地大模型运行,就这样还是不错的!!!
试一下终端命令行运行:
pdf2zh E:\data\datafile\研究生\阅读文献\2025\01\20250117\wei2.pdf -s ollama:Qwen2-7B -o E:\data\datafile\研究生\阅读文献\2025\01\20250117\fanyi2
我的6G显存基本跑满,还是硬件限制了我的速度呀。
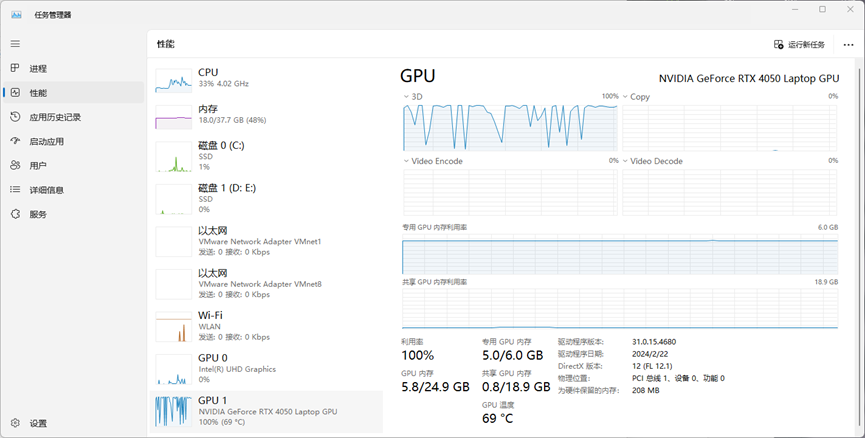
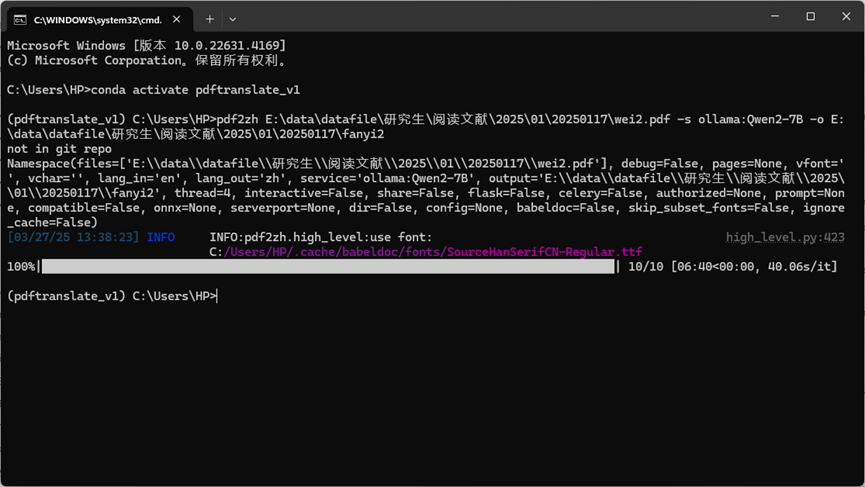
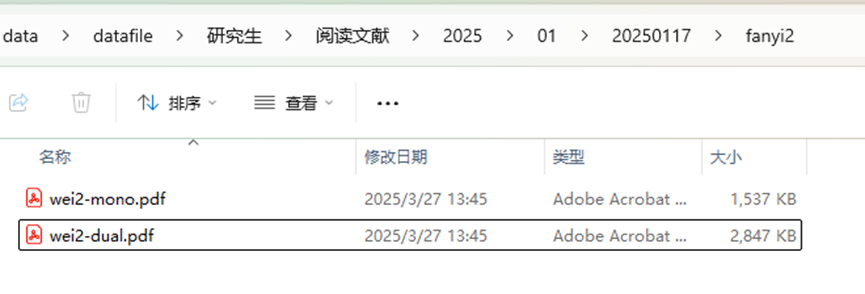
结果大概几分钟一篇论文,这个可以放后台跑,电脑无事的时候就可放后台弄了,这样后期看论文的时候能更方便地完成对照理解。
当然看文献的时候还是建议多理解一下英文,学习一下,翻译后的内容只是为了参考。
现在只用了Qwen2-7B的模型,还有其他大语言模型,需要自己去试一下,我这里就不试了。
不联网状态试一下。这里是另一篇:
pdf2zh E:\data\datafile\研究生\阅读文献\2025\01\20250117\wei3.pdf -s ollama:Qwen2-7B -o E:\data\datafile\研究生\阅读文献\2025\01\20250117\fanyi3
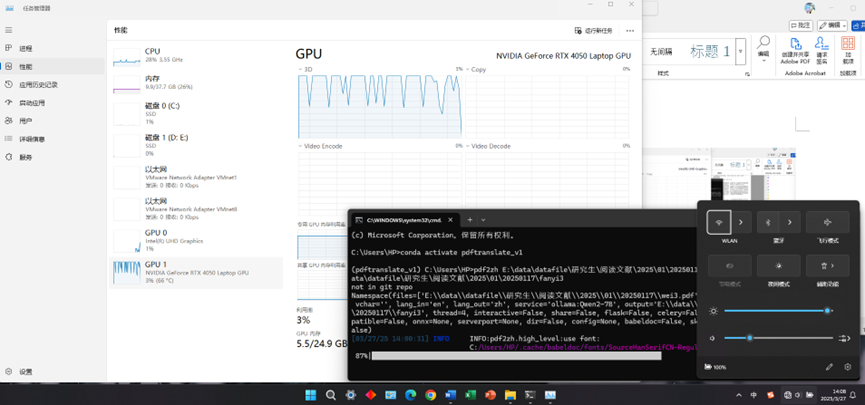
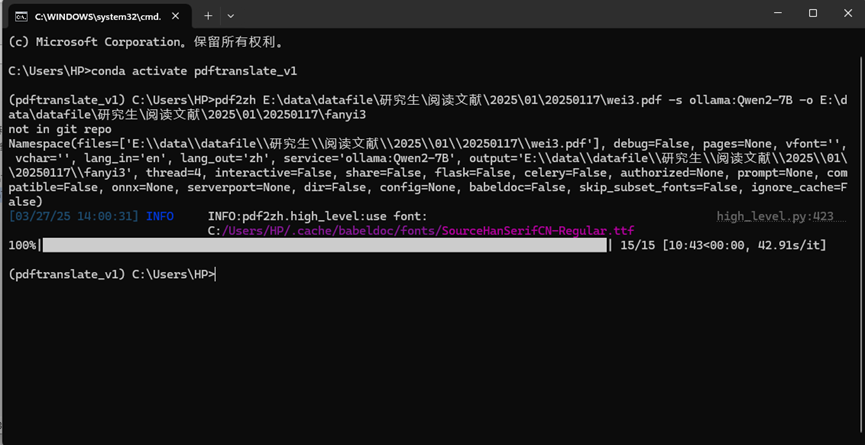
效果还是不错的:

4 结束语
之前想做的东西,通过学习各种资料,最后还是实现了我想要的内容,后续应该还是能让我的效率提高不少吧。大概!
后面再写一篇最近在弄这个东西而去学习有关内容的记录情况,以供大家参考!!!
上一篇文章
上一篇文章的发布情况,2025年3月27日发布,我来看一下啥时候回变成VIP可见。(~坏笑)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)