统计学习方法第四章:朴素贝叶斯法(naive Bayes)
·
目录
工大菜凯,希望通过做笔记记录自己学的知识,也希望能帮助到同样在入门的同学 ❥侵权立删~
朴素贝叶斯法的基本知识点:
基本思想:对于给定的训练数据集,首先基于特征条件独立假设学习输入--输出的联合概率分布,然后基于此模型,对给定的输入X,利用贝叶斯定理求出概率最大的输出Y。

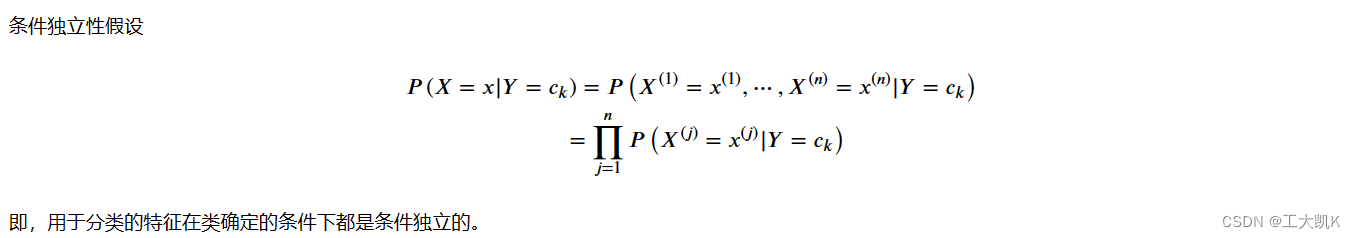
因为概率联合分布无法直接获取,所以我们通过条件概率的方法进行求解。
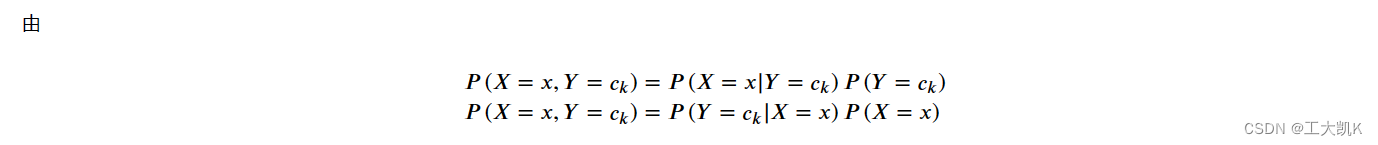
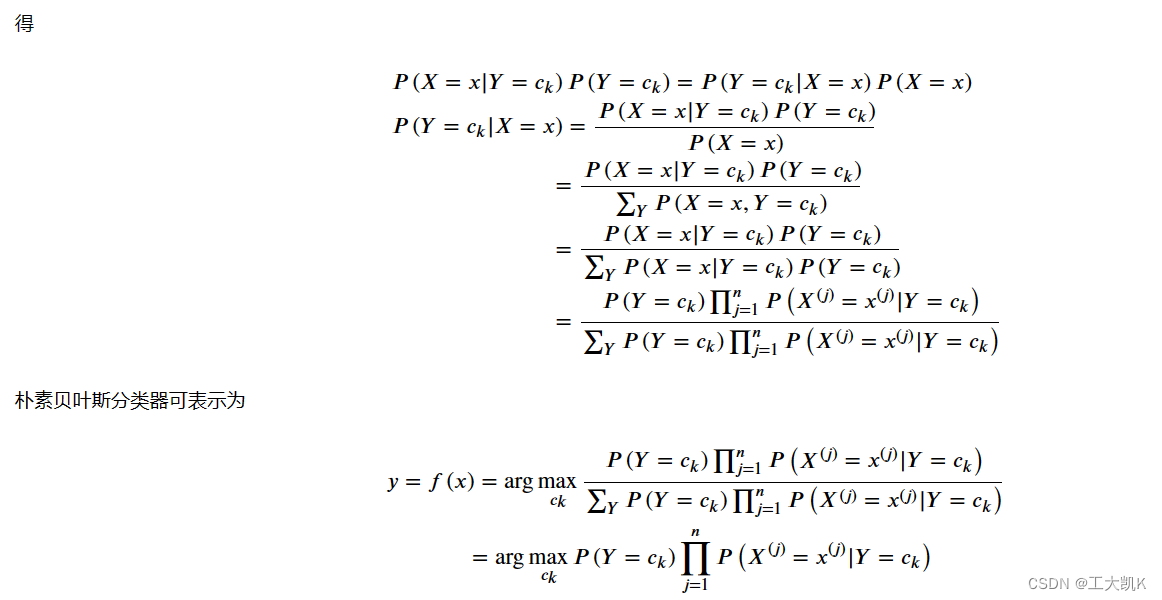
 朴素贝叶斯算法的基本思路:
朴素贝叶斯算法的基本思路: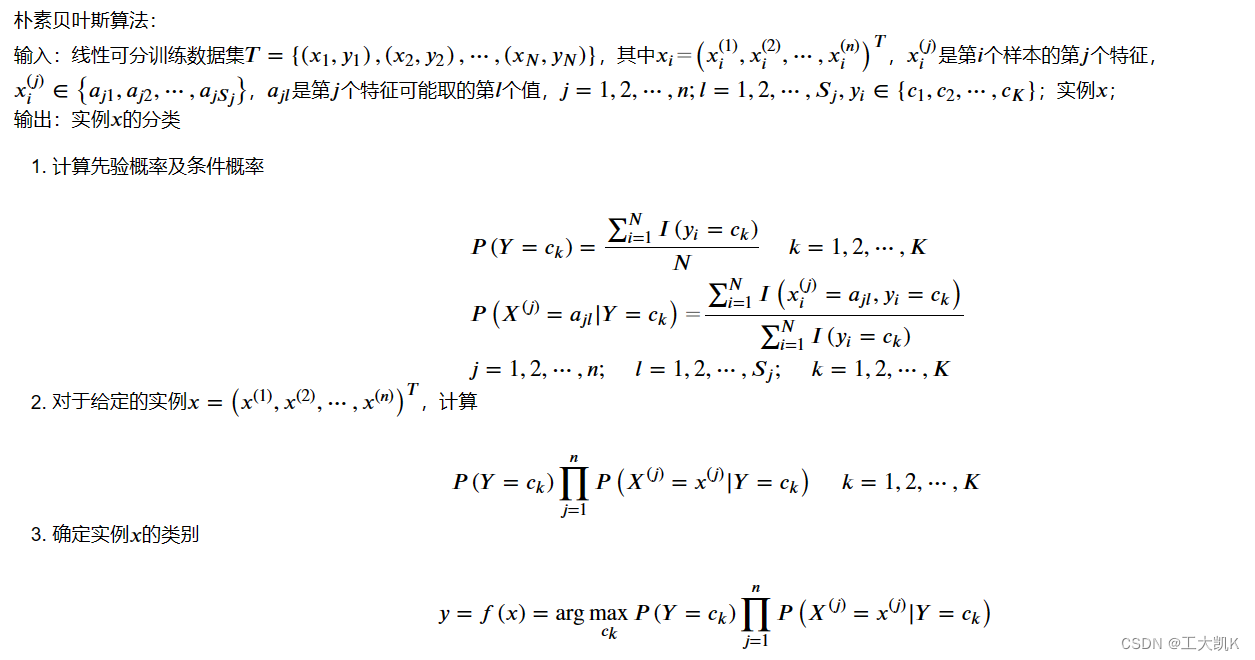
有利于了解贝叶斯算法与概念的相关例题:
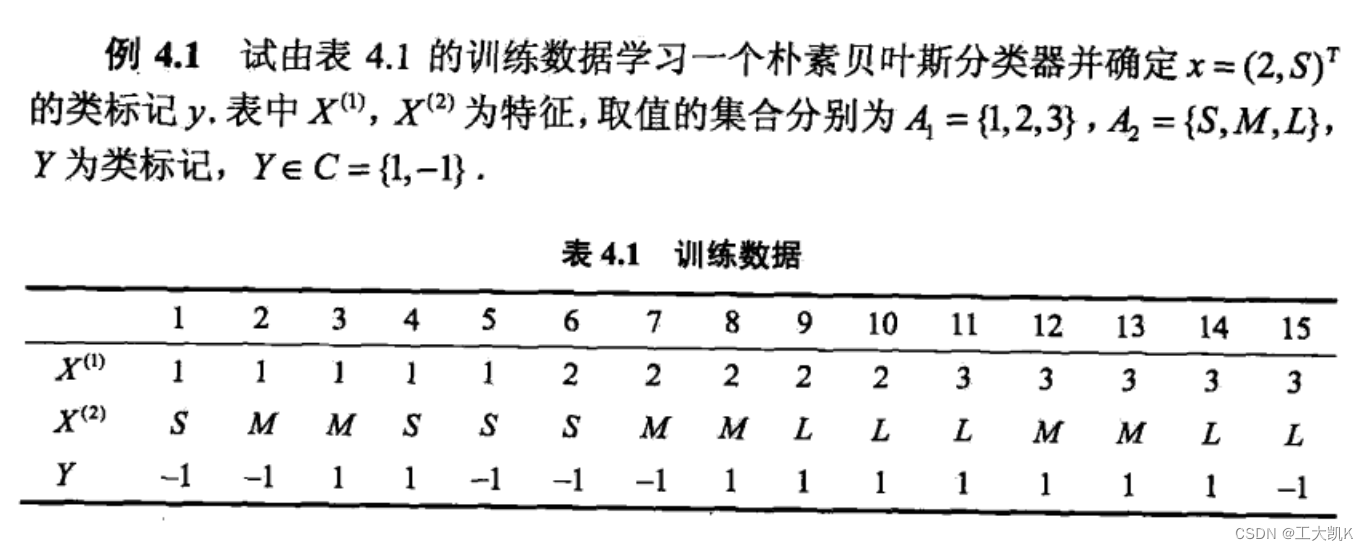
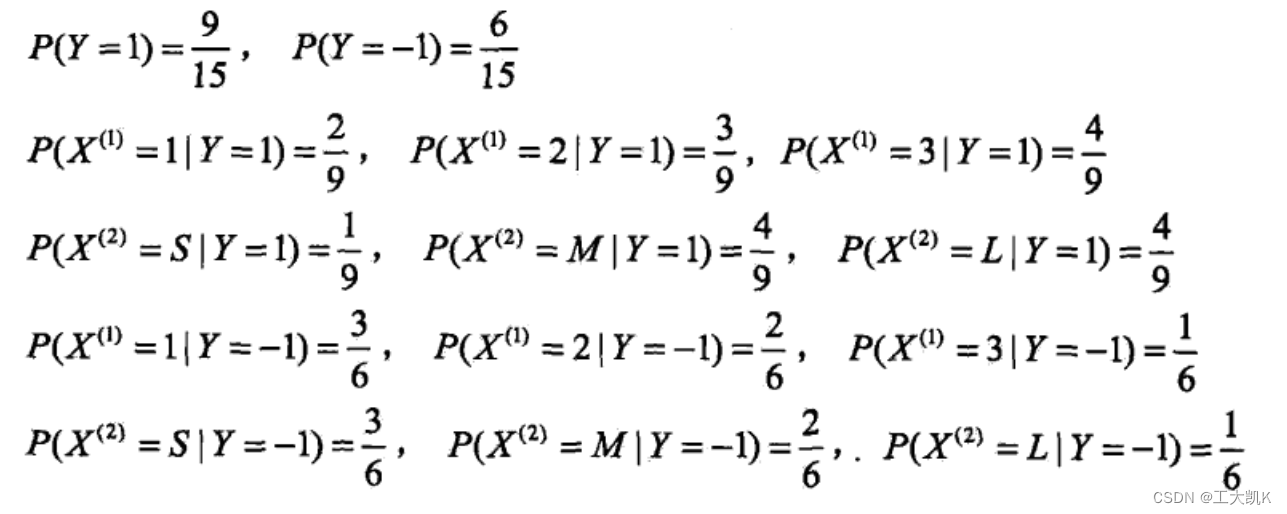
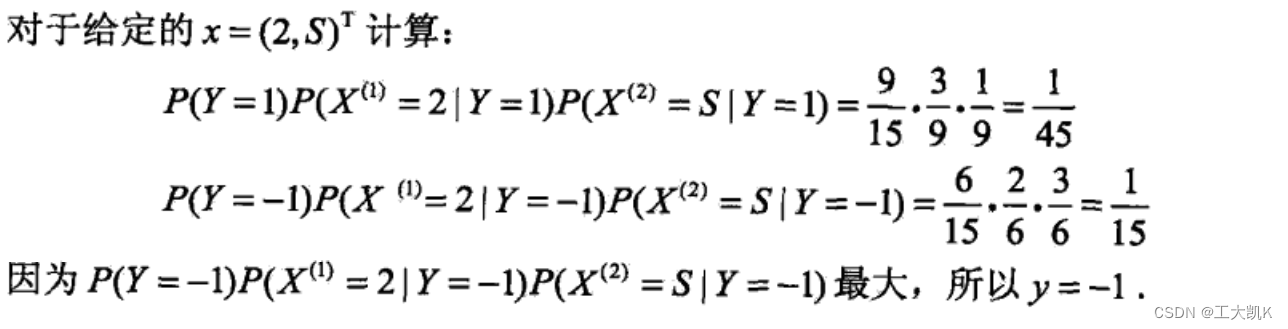
我们发现朴素贝叶斯算法有以个主要的缺陷,当输入空间中缺少某一类标签或缺少某一特征时,可能会出现所要估计的概率值为0的情况。条件概率公式的分子和分母都有可能出现为零的情况。从而导致后面的分类产生偏差,所以我们引入了贝叶斯估计算法。

其中的特征值取不同值的个数(如上面的例题中的
所对应的
=3 注(1,2,3)、
所对应的
=3 注(S,M,L)) K代表的是样本标签类别的个数(如上面例题中K=2 注(-1,1))
改进后的朴素贝叶斯算法(贝叶斯估计)的例题:

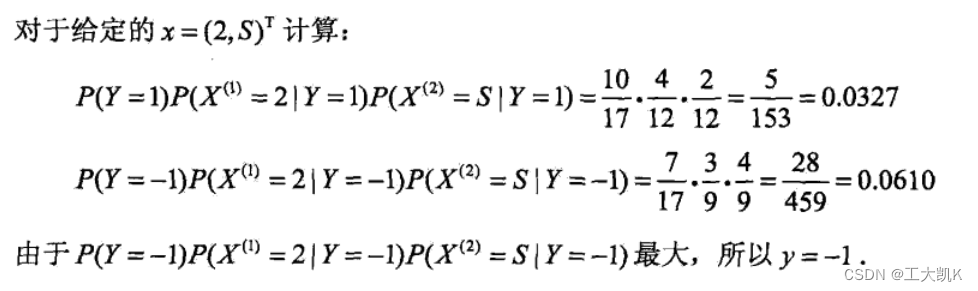
代码分析:
 https://machinelearningmastery.com/naive-bayes-classifier-scratch-python/
https://machinelearningmastery.com/naive-bayes-classifier-scratch-python/训练集和测试集的设置:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# sklearn库中的小型数据集的引入
from sklearn.datasets import load_iris
# sklearn库中引入将数据集划分为训练集和测试集的函数train_test_split()
from sklearn.model_selection import train_test_split
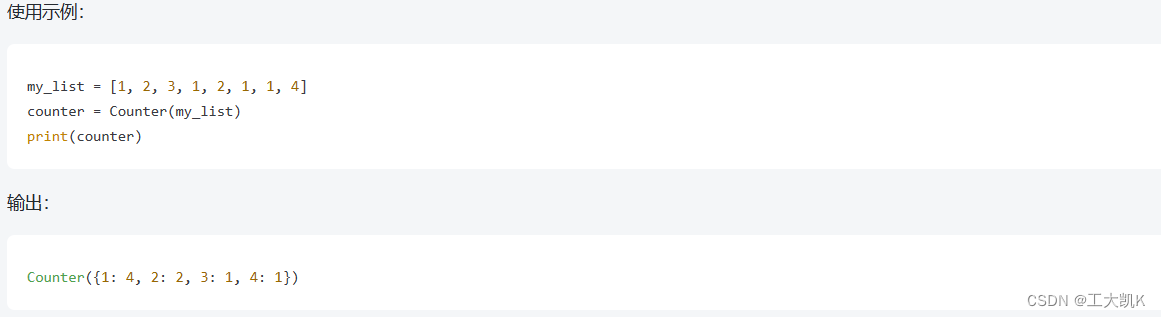
# Counter用于快速、简便地计数可迭代对象中元素的出现次数
# Counter 对象会生成一个字典,其中键是可迭代对象中的元素,值是该元素在可迭代对象中出现的次数。
from collections import Counter
import math相关函数的使用说明补充:

# 数据集的创建
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# 输出数据集df前100个样本(行)的所有列(生成的矩阵为100*5 包含100个样本 4个特征变量 1个标签)
data = np.array(df.iloc[:100, :])
# print(data)
# data[:,:-1]:将data的全部行,除了最后一列标签列其他都输出
# data[:,:-1](相对于前100个样本的特征变量组成的数组)
# data[:,-1]:将全部行,仅仅只有最后一列标签列进行输出
# data[:,-1](相当于前100个样本的样本标签组成的数组)
return data[:,:-1], data[:,-1]# 将特征变量组成的数组赋值给X 将样本标签组成的数组赋值给y
X, y = create_data()
# 将数据集随机分成0.7训练数据集 0.3测试数据集 各个数据的样本和标签仍然是一一对应的
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
print(X_test[0], y_test[0])
高斯朴素贝叶斯模型的构建:
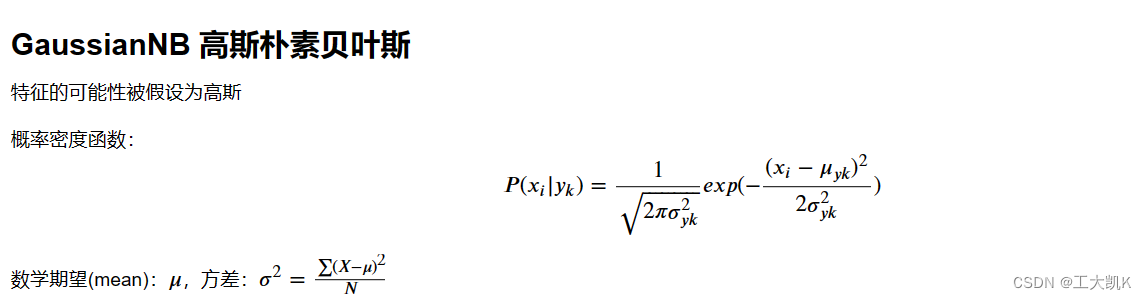
类似于正态分布,但是概率密度、方差都存在区别。
# 建立高斯朴素贝叶斯模型 算法
class NaiveBayes:
def __init__(self):
self.model = None
@staticmethod
# @staticmethod 是一个修饰符,用于声明一个静态方法。
# 修饰在mean上,意味着mean方法是一个静态方法。
# mean可以直接通过类名 NaiveBayes.mean() 调用,而不需要创建 NaiveBayes 的实例
# 数学期望(均值)𝜇
def mean(X):
return sum(X) / float(len(X))
# 标准差(方差)𝜎^2=∑(𝑋−𝜇)^2/𝑁 标准差为𝜎
def stdev(self, X):
avg = self.mean(X)
# 计算列表 X 中每个元素与均值(数学期望) 𝜇 的差的平方,并将结果组成一个新的列表
# 使用 sum() 函数对上一步得到的列表进行求和,得到所有差的平方的总和
# 代码的功能是计算列表 X 中元素与其均值(数学期望)的差的平方的平均值,并返回这个平均值的平方根
return math.sqrt(sum([pow(x-avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
# 对训练数据X_train进行处理,并生成一个包含特征的概率分布参数的列表summaries。
def summarize(self, train_data):
# 在每次循环中,调用 self.mean(i) 计算特征列 i 的均值,并调用 self.stdev(i) 计算特征列 i
# 的标准差,最终得到一个由均值和标准差组成的元组。
# 根据训练数据 train_data,通过计算每个特征列的均值和标准差,生成了一个含有特征列概率分布参
# 数的列表 summaries
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分类别求出数学期望和标准差
def fit(self, X, y):
# set(y):得到标签几何labels,其中每个不同的标签都是唯一的
labels = list(set(y))
# 因为labels 是一个可迭代的对象,它包含了所有的标签值
# 通过{label:[] for label in labels},对于labels中的每个标签值label,都创建一个键值对,
# 其中键是label,值是一个空列表[]。最终的结果是一个字典,其中每个标签对应的一个空列表。
data = {label:[] for label in labels}
# zip(X,y): 将特征矩阵X和标签向量y进行配对
# 将每个特征f根据对应的标签label存储在data字典中的相应列表中。实现特征数据按照类别划分的操作
for f, label in zip(X, y):
data[label].append(f)
# 创建一个空字典self.model,再通过data.items()获取字典的键值对
# 其中键是类别标签,值是该类别的对应的特征数据列表
# 对应于每个标签(类别),调用self.summarize(value)函数 计算该类别的数学期望和标准差
# 并以字典的形式将标签和结果存储在self.model字典中对应的类别键位置
self.model = {label: self.summarize(value) for label, value in data.items()}
return 'gaussianNB train done!'
# 计算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
# 创建一个空字典,用于存储概率结果
probabilities = {}
for label, value in self.model.items():
# 对应于模型中的每个标签所对应的初始值的概率都设置为1
# 在循环中,使用高斯分布的概率密度函数计算每个特征的概率,并将其乘积累积到当前标签的概率上。
# 由于初始概率为1,通过乘积累积的方式,每个特征的概率都会与初始概率相乘,得到最终的标签概率。
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(input_data[i], mean, stdev)
return probabilities
# 返回预测得到的标签值
def predict(self, X_test):
# 接受一个测试数据X_text .items()的作用是将字典转化为一个包含键值对的可迭代对象
# key=lambda x: x[-1] 取出每个键值对中的最后一个元素,即概率值
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
# 利用sorted进行排序然后[-1][0]代表的是取出排序后的结果中的最后一个元素,并获取其中的第一个元素,即具有最高概率的标签。
label = sorted(self.calculate_probabilities(X_test).items(), key=lambda x: x[-1])[-1][0]
return label
# 评估模型的准确率的方法(将预测正确的样本数量right除以总样本数量len(X_text)得到准确率)
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))# 测试代码
model = NaiveBayes()
# 创建模型,高斯朴素贝叶斯模型训练
model.fit(X_train, y_train)
#模型预测
print(model.predict([4.5, 3.2, 1.3, 0.2]))
# 准确率输出
model.score(X_test, y_test)

运用 sklearn.naive_bayes:
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)
print(clf.predict([[4.4, 3.2, 1.3, 0.2]]))
print(clf.score(X_test, y_test))
函数使用方法补充:



data[label].append(f)




DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)