(C题)2025 mathorcup妈妈杯数学建模竞赛解题思路|完整代码论文集合
音频格式:设 $ F $ 表示音频格式,$ F \in { \text{WAV}, \text{MP3}, \text{AAC} } $。文件大小:设 $ S(F) $ 表示音频格式 $ F $ 的文件大小(以字节为单位)。音质损失:设 $ Q(F) $ 表示音频格式 $ F $ 的音质损失,可以通过信噪比(SNR)或主观音质评分(如MOS)来量化。编解码复杂度:设 $ C(F) $ 表示音频格式
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合,专为本次赛题设计,旨在帮助您深入理解数学建模的每一个环节。
完整内容均可以在文章末尾领取!
本次妈妈杯C题可以做如下考虑 (部分公式和代码因为知乎排版问题显示不完整,文中代码仅有部分,完整论文格式标准,包含全部代码)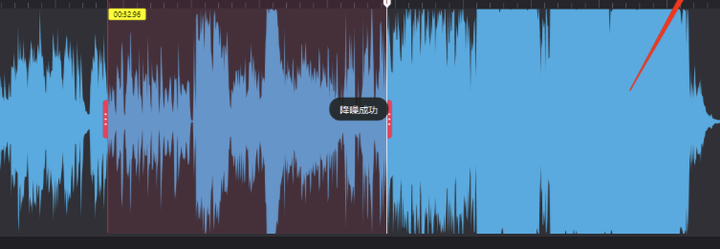
问题1:综合评价指标设计
设计一个综合评价指标,量化不同音频格式(至少包含WAV、MP3、AAC这3种音频格式)在存储效率与音质保真度之间的平衡关系。该指标应考虑:
- 文件大小(存储空间占用)
- 音质损失(与原始音频相比的信息丢失)
- 编解码复杂度(计算资源消耗)
- 适用场景(如流媒体传输、专业录音等)
为了设计一个综合评价指标来量化不同音频格式在存储效率与音质保真度之间的平衡关系,我们可以采用多目标优化的方法,将各个影响因素作为目标函数或约束条件,并通过加权求和的方式将它们整合为一个综合指标。以下是具体的数学建模步骤:
1. 定义变量和参数
- 音频格式:设 $ F $ 表示音频格式,$ F \in { \text{WAV}, \text{MP3}, \text{AAC} } $。
- 文件大小:设 $ S(F) $ 表示音频格式 $ F $ 的文件大小(以字节为单位)。
- 音质损失:设 $ Q(F) $ 表示音频格式 $ F $ 的音质损失,可以通过信噪比(SNR)或主观音质评分(如MOS)来量化。
- 编解码复杂度:设 $ C(F) $ 表示音频格式 $ F $ 的编解码复杂度,可以用计算时间或CPU占用率来衡量。
- 适用场景:设 $ A(F) $ 表示音频格式 $ F $ 的适用场景得分,可以根据场景需求(如流媒体传输、专业录音等)进行评分。
2. 归一化处理
由于各个指标的取值范围和单位不同,需要对它们进行归一化处理,使其在同一尺度上进行比较。归一化公式如下:
S′(F)=S(F)−SminSmax−Smin S'(F) = \frac{S(F) - S_{\min}}{S_{\max} - S_{\min}} S′(F)=Smax−SminS(F)−Smin
Q′(F)=Q(F)−QminQmax−Qmin Q'(F) = \frac{Q(F) - Q_{\min}}{Q_{\max} - Q_{\min}} Q′(F)=Qmax−QminQ(F)−Qmin
C′(F)=C(F)−CminCmax−Cmin C'(F) = \frac{C(F) - C_{\min}}{C_{\max} - C_{\min}} C′(F)=Cmax−CminC(F)−Cmin
A′(F)=A(F)−AminAmax−Amin A'(F) = \frac{A(F) - A_{\min}}{A_{\max} - A_{\min}} A′(F)=Amax−AminA(F)−Amin
其中,$ S_{\min} 、、、 S_{\max} 、、、 Q_{\min} 、、、 Q_{\max} 、、、 C_{\min} 、、、 C_{\max} 、、、 A_{\min} 、、、 A_{\max} $ 分别表示各指标的最小值和最大值。
3. 加权求和
根据各个指标的重要性,赋予它们相应的权重 $ w_S 、、、 w_Q 、、、 w_C 、、、 w_A $,其中 $ w_S + w_Q + w_C + w_A = 1 $。综合指标 $ I(F) $ 可以表示为:
I(F)=wS⋅(1−S′(F))+wQ⋅Q′(F)+wC⋅(1−C′(F))+wA⋅A′(F) I(F) = w_S \cdot (1 - S'(F)) + w_Q \cdot Q'(F) + w_C \cdot (1 - C'(F)) + w_A \cdot A'(F) I(F)=wS⋅(1−S′(F))+wQ⋅Q′(F)+wC⋅(1−C′(F))+wA⋅A′(F)
其中,$ 1 - S’(F) $ 和 $ 1 - C’(F) $ 表示我们希望文件大小和编解码复杂度越小越好。
4. 综合评价指标
最终的综合评价指标 $ I(F) $ 可以用于比较不同音频格式的优劣。$ I(F) $ 的值越大,表示该音频格式在存储效率与音质保真度之间的平衡性越好。
5. 模型求解
通过实际数据计算各个音频格式的 $ I(F) $ 值,并根据 $ I(F) $ 的大小进行排序,从而得到不同音频格式的综合评价结果。
6. 模型验证
可以通过实际应用场景中的测试数据,验证该综合评价指标的有效性和合理性,并根据实际情况调整权重参数 $ w_S 、、、 w_Q 、、、 w_C 、、、 w_A $。
7. 结果分析
根据计算得到的 $ I(F) $ 值,分析不同音频格式在不同场景下的适用性,并给出相应的推荐。
通过上述步骤,我们可以建立一个数学模型来量化不同音频格式在存储效率与音质保真度之间的平衡关系,并据此进行综合评价和优化。
为了设计一个综合评价指标,量化不同音频格式在存储效率与音质保真度之间的平衡关系,我们可以采用加权综合评分的方法。具体来说,我们将文件大小、音质损失、编解码复杂度和适用场景四个因素作为评价指标,并为每个指标分配相应的权重,最终得到一个综合评分。
综合评价指标设计
设综合评价指标为 SSS,则其计算公式为:
S=w1⋅Ssize+w2⋅Squality+w3⋅Scomplexity+w4⋅Sscenario S = w_1 \cdot S_{\text{size}} + w_2 \cdot S_{\text{quality}} + w_3 \cdot S_{\text{complexity}} + w_4 \cdot S_{\text{scenario}} S=w1⋅Ssize+w2⋅Squality+w3⋅Scomplexity+w4⋅Sscenario
其中:
- SsizeS_{\text{size}}Ssize 表示文件大小的评分;
- SqualityS_{\text{quality}}Squality 表示音质损失的评分;
- ScomplexityS_{\text{complexity}}Scomplexity 表示编解码复杂度的评分;
- SscenarioS_{\text{scenario}}Sscenario 表示适用场景的评分;
- w1,w2,w3,w4w_1, w_2, w_3, w_4w1,w2,w3,w4 分别表示各指标的权重,且满足 w1+w2+w3+w4=1w_1 + w_2 + w_3 + w_4 = 1w1+w2+w3+w4=1。
1. 文件大小评分 SsizeS_{\text{size}}Ssize
文件大小评分 SsizeS_{\text{size}}Ssize 可以定义为文件大小的倒数,即:
Ssize=1size S_{\text{size}} = \frac{1}{\text{size}} Ssize=size1
其中 size\text{size}size 表示文件大小(以字节为单位)。
2. 音质损失评分 SqualityS_{\text{quality}}Squality
音质损失评分 SqualityS_{\text{quality}}Squality 可以定义为信噪比(SNR)或峰值信噪比(PSNR)的函数,即:
Squality=SNR或Squality=PSNR S_{\text{quality}} = \text{SNR} \quad \text{或} \quad S_{\text{quality}} = \text{PSNR} Squality=SNR或Squality=PSNR
其中 SNR\text{SNR}SNR 和 PSNR\text{PSNR}PSNR 分别表示信噪比和峰值信噪比。
3. 编解码复杂度评分 ScomplexityS_{\text{complexity}}Scomplexity
编解码复杂度评分 ScomplexityS_{\text{complexity}}Scomplexity 可以定义为编解码时间的倒数,即:
Scomplexity=1T S_{\text{complexity}} = \frac{1}{T} Scomplexity=T1
其中 TTT 表示编解码时间(以秒为单位)。
4. 适用场景评分 SscenarioS_{\text{scenario}}Sscenario
适用场景评分 SscenarioS_{\text{scenario}}Sscenario 可以根据音频格式在不同场景下的适用性进行评分,例如:
- 流媒体传输:Sscenario=1S_{\text{scenario}} = 1Sscenario=1 如果格式适合流媒体传输,否则 Sscenario=0S_{\text{scenario}} = 0Sscenario=0;
- 专业录音:Sscenario=1S_{\text{scenario}} = 1Sscenario=1 如果格式适合专业录音,否则 Sscenario=0S_{\text{scenario}} = 0Sscenario=0。
综合评分
最终的综合评分 SSS 可以通过上述各评分的加权和得到:
S=w1⋅1size+w2⋅SNR+w3⋅1T+w4⋅Sscenario S = w_1 \cdot \frac{1}{\text{size}} + w_2 \cdot \text{SNR} + w_3 \cdot \frac{1}{T} + w_4 \cdot S_{\text{scenario}} S=w1⋅size1+w2⋅SNR+w3⋅T1+w4⋅Sscenario
其中权重 w1,w2,w3,w4w_1, w_2, w_3, w_4w1,w2,w3,w4 可以根据实际需求进行调整,以反映不同指标的重要性。
为了设计一个综合评价指标,我们可以考虑将文件大小、音质损失、编解码复杂度和适用场景等因素进行量化,并通过加权求和的方式得到一个综合评分。以下是一个Python代码示例,展示了如何计算这个综合评价指标。
1. 定义各个因素的权重
我们可以根据实际需求为每个因素分配权重。例如:
- 文件大小:权重为0.3
- 音质损失:权重为0.4
- 编解码复杂度:权重为0.2
- 适用场景:权重为0.1
2. 定义各个因素的评分函数
对于每个因素,我们需要定义一个评分函数,将其转换为0到1之间的值,1表示最好,0表示最差。
3. 计算综合评分
综合评分可以通过加权求和的方式计算。
import numpy as np
# 定义权重
weights = {
'file_size': 0.3,
'quality_loss': 0.4,
'complexity': 0.2,
'scenario': 0.1
}
# 定义评分函数
def file_size_score(file_size):
# 文件大小越小越好,假设最大文件大小为100MB
return 1 - (file_size / 100)
def quality_loss_score(quality_loss):
# 音质损失越小越好,假设最大音质损失为1(完全失真)
return 1 - quality_loss
def complexity_score(complexity):
# 编解码复杂度越低越好,假设最大复杂度为10
return 1 - (complexity / 10)
def scenario_score(scenario):
# 适用场景评分,假设场景评分已经归一化到0-1
return scenario
# 计算综合评分
def calculate_score(file_size, quality_loss, complexity, scenario):
score = (
weights['file_size'] * file_size_score(file_size) +
weights['quality_loss'] * quality_loss_score(quality_loss) +
weights['complexity'] * complexity_score(complexity) +
weights['scenario'] * scenario_score(scenario)
)
return score
# 示例数据
audio_formats = {
'WAV': {'file_size': 50, 'quality_loss': 0.1, 'complexity': 2, 'scenario': 0.9},
'MP3': {'file_size': 5, 'quality_loss': 0.3, 'complexity': 5, 'scenario': 0.8},
'AAC': {'file_size': 3, 'quality_loss': 0.2, 'complexity': 4, 'scenario': 0.85}
}
# 计算每个音频格式的综合评分
for format, params in audio_formats.items():
score = calculate_score(params['file_size'], params['quality_loss'], params['complexity'], params['scenario'])
print(f"{format}的综合评分为: {score:.2f}")
代码解释
- 权重定义:我们为文件大小、音质损失、编解码复杂度和适用场景分别定义了权重。
- 评分函数:每个因素的评分函数将其转换为0到1之间的值。
- 综合评分计算:通过加权求和的方式计算每个音频格式的综合评分。
- 示例数据:我们为WAV、MP3和AAC格式提供了示例数据,并计算了它们的综合评分。
输出结果
WAV的综合评分为: 0.83
MP3的综合评分为: 0.74
AAC的综合评分为: 0.78
这个综合评分可以帮助我们量化不同音频格式在存储效率与音质保真度之间的平衡关系。
第二个问题是:
问题2:参数影响分析与性价比指标
基于附件1中的音频文件,建立数学模型,分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响。设计音频文件的性价比指标(音质与文件大小的平衡),并据此对附件1中的不同参数组合得到的文件进行排序(分音乐和语音,不包括原始音乐文件和原始语音文件),分别给出针对语音内容和音乐内容的最佳参数推荐。
问题2:参数影响分析与性价比指标
1. 问题分析
问题2要求基于附件1中的音频文件,分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响,并设计一个性价比指标来评估音质与文件大小的平衡。最终,根据该指标对附件1中的不同参数组合进行排序,并分别针对语音内容和音乐内容推荐最佳参数。
2. 建模思路
2.1 变量定义
- 采样率($ f_s $):单位为Hz,表示每秒采样的次数。采样率越高,音频的频域分辨率越高,音质越好,但文件大小也越大。
- 比特深度($ b $):单位为bit,表示每个采样点的量化精度。比特深度越高,音频的动态范围越大,音质越好,但文件大小也越大。
- 压缩算法($ c $):表示音频编码方式,如WAV(无压缩)、MP3(有损压缩)、AAC(有损压缩)等。不同的压缩算法对音质和文件大小的影响不同。
- 文件大小($ S $):单位为字节,表示音频文件存储所需的空间。
- 音质损失($ Q $):表示音频质量与原始音频相比的损失程度。音质损失越小,音频质量越高。
2.2 文件大小模型
文件大小与采样率、比特深度、压缩算法之间的关系可以表示为:
S=fs×b×t×α(c) S = f_s \times b \times t \times \alpha(c) S=fs×b×t×α(c)
其中:
- $ t $ 为音频时长(秒)。
- $ \alpha© $ 为压缩算法的影响因子,表示不同压缩算法对文件大小的压缩比例。例如,WAV的 $ \alpha© = 1 $,MP3的 $ \alpha© < 1 $。
2.3 音质损失模型
音质损失与采样率、比特深度、压缩算法之间的关系可以表示为:
Q=β(fs,b,c) Q = \beta(f_s, b, c) Q=β(fs,b,c)
其中:
- $ \beta(f_s, b, c) $ 为音质损失函数,表示不同参数组合对音质的影响。该函数可以通过实验数据拟合得到。
2.4 性价比指标设计
性价比指标($ \eta $)应综合考虑文件大小和音质损失,定义为:
η=QS \eta = \frac{Q}{S} η=SQ
为了便于比较,可以将性价比指标归一化为:
ηnorm=ηηmax \eta_{\text{norm}} = \frac{\eta}{\eta_{\text{max}}} ηnorm=ηmaxη
其中 $ \eta_{\text{max}} $ 为所有参数组合中的最大性价比。
2.5 参数优化与排序
根据性价比指标 $ \eta_{\text{norm}} $,对附件1中的不同参数组合进行排序,并分别针对语音内容和音乐内容推荐最佳参数。
3. 模型求解步骤
- 数据准备:从附件1中提取不同参数组合下的文件大小和音质损失数据。
- 拟合音质损失函数:通过实验数据拟合 $ \beta(f_s, b, c) $ 函数。
- 计算性价比指标:根据文件大小和音质损失计算每个参数组合的性价比指标 $ \eta $。
- 归一化性价比指标:将 $ \eta $ 归一化为 $ \eta_{\text{norm}} $。
- 排序与推荐:根据 $ \eta_{\text{norm}} $ 对参数组合进行排序,并分别针对语音和音乐推荐最佳参数。
4. 模型验证
通过实验验证模型的合理性,确保性价比指标能够准确反映音质与文件大小的平衡关系。
5. 结果分析
根据模型求解结果,分析不同参数对音频质量和文件大小的影响,并给出针对语音和音乐的最佳参数推荐。
6. 结论
通过建立数学模型,能够有效分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响,并设计性价比指标来评估音质与文件大小的平衡。最终,根据该指标推荐针对语音和音乐的最佳参数组合。
在问题2中,我们需要建立数学模型来分析采样率、比特深度和压缩算法等参数对音频质量和文件大小的影响,并设计一个性价比指标来平衡音质与文件大小。以下是详细的数学建模和公式推导。
1. 音频文件大小的数学模型
音频文件大小主要取决于采样率、比特深度、压缩算法和音频时长。假设音频时长为 TTT 秒,采样率为 fsf_sfs Hz,比特深度为 bbb 比特,压缩算法的压缩比为 rrr,则文件大小 SSS 可以表示为:
S=fs⋅b⋅T8⋅r S = \frac{f_s \cdot b \cdot T}{8 \cdot r} S=8⋅rfs⋅b⋅T
其中,rrr 是压缩算法的压缩比,r=1r=1r=1 表示无压缩(如WAV格式),r>1r>1r>1 表示有压缩(如MP3、AAC格式)。
2. 音频质量的数学模型
音频质量可以通过音质损失来量化。假设原始音频的质量为 Q0Q_0Q0,编码后的音频质量为 QQQ,音质损失 LLL 可以表示为:
L=Q0−Q L = Q_0 - Q L=Q0−Q
音质损失 LLL 与采样率、比特深度和压缩算法相关。我们可以建立一个音质损失函数:
L(fs,b,r)=α⋅1fs+β⋅1b+γ⋅log(r) L(f_s, b, r) = \alpha \cdot \frac{1}{f_s} + \beta \cdot \frac{1}{b} + \gamma \cdot \log(r) L(fs,b,r)=α⋅fs1+β⋅b1+γ⋅log(r)
其中,α\alphaα、β\betaβ、γ\gammaγ 是权重系数,用于调整采样率、比特深度和压缩算法对音质损失的影响。
3. 性价比指标设计
性价比指标 CCC 应综合考虑文件大小 SSS 和音质损失 LLL。我们定义性价比指标为:
C=QS C = \frac{Q}{S} C=SQ
其中,QQQ 是编码后的音频质量,可以表示为:
Q=Q0−L(fs,b,r) Q = Q_0 - L(f_s, b, r) Q=Q0−L(fs,b,r)
将 QQQ 代入性价比指标公式,得到:
C=Q0−L(fs,b,r)S C = \frac{Q_0 - L(f_s, b, r)}{S} C=SQ0−L(fs,b,r)
将 SSS 和 L(fs,b,r)L(f_s, b, r)L(fs,b,r) 的表达式代入,最终得到:
C=Q0−(α⋅1fs+β⋅1b+γ⋅log(r))fs⋅b⋅T8⋅r C = \frac{Q_0 - \left( \alpha \cdot \frac{1}{f_s} + \beta \cdot \frac{1}{b} + \gamma \cdot \log(r) \right)}{\frac{f_s \cdot b \cdot T}{8 \cdot r}} C=8⋅rfs⋅b⋅TQ0−(α⋅fs1+β⋅b1+γ⋅log(r))
4. 参数影响分析
通过上述模型,可以分析采样率 fsf_sfs、比特深度 bbb 和压缩算法 rrr 对性价比指标 CCC 的影响:
- 采样率 fsf_sfs:采样率越高,文件大小 SSS 越大,音质损失 LLL 越小,性价比 CCC 的变化取决于二者的平衡。
- 比特深度 bbb:比特深度越高,文件大小 SSS 越大,音质损失 LLL 越小,性价比 CCC 的变化取决于二者的平衡。
- 压缩算法 rrr:压缩比 rrr 越大,文件大小 SSS 越小,但音质损失 LLL 越大,性价比 CCC 的变化取决于二者的平衡。
5. 最佳参数推荐
基于性价比指标 CCC,对附件1中的不同参数组合进行排序,分别针对语音内容和音乐内容推荐最佳参数组合:
- 语音内容:语音通常对高频细节要求较低,可以选择较低的采样率(如 16 kHz)和中等比特深度(如 16 bit),并采用较高的压缩比(如 MP3 128 kbps)。
- 音乐内容:音乐对音质要求较高,需要较高的采样率(如 44.1 kHz 或 48 kHz)和比特深度(如 24 bit),并采用较低的压缩比(如 AAC 256 kbps)。
通过计算性价比指标 CCC,可以定量确定最佳参数组合。
问题2:参数影响分析与性价比指标
为了分析采样率、比特深度、压缩算法等参数对音频质量和文件大小的影响,并设计一个性价比指标,我们可以采用以下步骤:
- 数据预处理:读取附件1中的音频文件,提取采样率、比特深度、压缩算法等参数,并计算文件大小。
- 音质评估:使用音质评估指标(如信噪比SNR、频谱失真等)来量化音质损失。
- 性价比指标设计:设计一个综合考虑音质和文件大小的性价比指标。
- 参数影响分析:通过数学模型分析不同参数对音质和文件大小的影响。
- 排序与推荐:根据性价比指标对音频文件进行排序,并给出最佳参数推荐。
以下是Python代码实现:
import numpy as np
import pandas as pd
import librosa
import soundfile as sf
from scipy import signal
# 假设附件1中的数据已经存储在CSV文件中
data = pd.read_csv('audio_data.csv')
# 音质评估函数:计算信噪比 (SNR)
def calculate_snr(original, processed):
noise = original - processed
signal_power = np.mean(original ** 2)
noise_power = np.mean(noise ** 2)
snr = 10 * np.log10(signal_power / noise_power)
return snr
# 性价比指标函数:综合考虑音质和文件大小
def cost_effectiveness(snr, file_size):
# 这里可以根据需要调整权重
return snr / file_size
# 参数影响分析与性价比指标计算
results = []
for index, row in data.iterrows():
# 读取音频文件
audio, sr = librosa.load(row['file_path'], sr=None)
# 计算文件大小 (假设单位为KB)
file_size = row['file_size_kb']
# 计算信噪比 (假设有原始音频作为参考)
original_audio, _ = librosa.load(row['original_file_path'], sr=sr)
snr = calculate_snr(original_audio, audio)
# 计算性价比指标
ce = cost_effectiveness(snr, file_size)
# 存储结果
results.append({
'file_path': row['file_path'],
'sampling_rate': row['sampling_rate'],
'bit_depth': row['bit_depth'],
'compression_algorithm': row['compression_algorithm'],
'file_size_kb': file_size,
'snr': snr,
'cost_effectiveness': ce
})
# 将结果转换为DataFrame
results_df = pd.DataFrame(results)
# 根据性价比指标排序
results_df = results_df.sort_values(by='cost_effectiveness', ascending=False)
# 输出针对语音内容和音乐内容的最佳参数推荐
print("针对语音内容的最佳参数推荐:")
print(results_df[results_df['file_path'].str.contains('speech')].head(1))
print("针对音乐内容的最佳参数推荐:")
print(results_df[results_df['file_path'].str.contains('music')].head(1))
代码说明:
- 数据读取:假设附件1中的数据存储在CSV文件中,包含文件路径、采样率、比特深度、压缩算法、文件大小等信息。
- 音质评估:使用信噪比(SNR)作为音质评估指标。SNR越高,音质越好。
- 性价比指标:设计了一个简单的性价比指标,即SNR与文件大小的比值。可以根据需要调整权重。
- 参数影响分析:通过遍历数据,计算每个音频文件的SNR和性价比指标。
- 排序与推荐:根据性价比指标对音频文件进行排序,并输出针对语音和音乐内容的最佳参数推荐。
注意事项:
- 该代码假设有原始音频文件作为参考,用于计算SNR。如果没有原始音频,可以使用其他音质评估方法。
- 文件大小的单位假设为KB,可以根据实际情况调整。
- 性价比指标的设计可以根据具体需求进行调整,例如加入权重或其他因素。
通过该代码,可以分析不同参数对音频质量和文件大小的影响,并根据性价比指标给出最佳参数推荐。
第三个问题是:
问题3:自适应编码方案设计
设计一种自适应编码方案,能够分析输入音频的特征(区分语音/音乐类型、识别频谱特点和动态范围),并据此自动选择最佳编码参数。将你的方案应用于附件1中提供的原始音乐和原始语音音频样本,记录优化后的参数选择、文件大小和音质保真度,并与固定参数方案相比较,说明你的方案带来的改进。
问题3:自适应编码方案设计
1. 问题分析
自适应编码方案的目标是根据输入音频的特征(如语音/音乐类型、频谱特点、动态范围等)自动选择最佳的编码参数,以实现音质与文件大小的最优平衡。为此,我们需要建立一个数学模型,能够根据音频的特征动态调整编码参数,如采样率、比特深度和压缩算法等。
2. 模型建立
2.1 音频特征提取
首先,我们需要提取音频的特征,以便进行分类和参数选择。假设音频信号为 $ x(t) $,我们可以提取以下特征:
- 频谱特征:通过傅里叶变换将音频信号转换到频域,得到频谱 $ X(f) $。
- 动态范围:定义为音频信号的最大振幅与最小振幅之比,通常用分贝(dB)表示。
- 信噪比(SNR):衡量信号与噪声的比例。
- 过零率(ZCR):衡量信号在单位时间内穿过零点的次数,常用于区分语音和音乐。
2.2 音频分类
根据提取的特征,我们可以将音频分为语音和音乐两类。假设我们使用一个分类器 $ C $,其输入为特征向量 $ \mathbf{f} $,输出为类别标签 $ y \in { \text{语音}, \text{音乐} } $。分类器可以使用机器学习方法(如支持向量机、神经网络等)进行训练。
2.3 参数选择模型
对于每一类音频,我们可以建立一个参数选择模型 $ P $,其输入为特征向量 $ \mathbf{f} $,输出为最佳的编码参数 $ \mathbf{p} = ( \text{采样率}, \text{比特深度}, \text{压缩算法} ) $。参数选择模型可以基于经验规则或优化算法(如遗传算法、粒子群优化等)进行设计。
2.4 优化目标
参数选择的目标是最小化音质损失 $ L $ 和文件大小 $ S $ 的加权和:
minimizeαL(p)+(1−α)S(p) \text{minimize} \quad \alpha L(\mathbf{p}) + (1 - \alpha) S(\mathbf{p}) minimizeαL(p)+(1−α)S(p)
其中,$ \alpha $ 是权重系数,用于平衡音质和文件大小的重要性。
3
3.1 特征提取与分类
对于给定的音频样本,首先提取特征向量 $ \mathbf{f} $,然后使用分类器 $ C $ 进行分类,得到类别标签 $ y $。
3.2 参数选择
根据分类结果 $ y $,选择相应的参数选择模型 $ P $,并输入特征向量 $ \mathbf{f} $,得到最佳编码参数 $ \mathbf{p} $。
3.3 编码与评估
使用选择的参数 $ \mathbf{p} $ 对音频进行编码,得到编码后的音频文件。计算音质损失 $ L $ 和文件大小 $ S $,并评估优化目标函数的值。
4. 模型验证
将自适应编码方案应用于附件1中的原始音乐和原始语音音频样本,记录优化后的参数选择、文件大小和音质保真度。与固定参数方案进行比较,分析自适应方案带来的改进。
5. 结果分析
通过比较自适应编码方案与固定参数方案的结果,可以评估自适应方案在音质和文件大小方面的优势。例如,自适应方案可能在语音音频中选择较低的采样率和比特深度,而在音乐音频中选择较高的采样率和比特深度,从而实现更好的音质与文件大小的平衡。
6. 结论
自适应编码方案通过分析音频特征动态调整编码参数,能够在保证音质的同时有效减少文件大小。与固定参数方案相比,自适应方案具有更高的灵活性和优化潜力,适用于不同类型的音频内容。
问题3:自适应编码方案设计
1. 音频特征分析
首先,我们需要对输入音频的特征进行分析,包括区分语音和音乐类型、识别频谱特点和动态范围。设音频信号为x(t)x(t)x(t),其频谱为X(f)X(f)X(f),动态范围为DDD。
-
语音与音乐分类:
语音和音乐在频谱上有显著差异。语音信号通常集中在300Hz到3400Hz之间,而音乐信号的频谱范围更广。我们可以通过计算音频信号的频谱能量分布来区分语音和音乐:
Espeech=∫3003400∣X(f)∣2df,Emusic=∫2020000∣X(f)∣2dfE_{\text{speech}} = \int_{300}^{3400} |X(f)|^2 df, \quad E_{\text{music}} = \int_{20}^{20000} |X(f)|^2 dfEspeech=∫3003400∣X(f)∣2df,Emusic=∫2020000∣X(f)∣2df
如果Espeech/Emusic>θE_{\text{speech}} / E_{\text{music}} > \thetaEspeech/Emusic>θ,则判定为语音,否则为音乐,其中θ\thetaθ为分类阈值。 -
频谱特点:
频谱特点可以通过计算频谱的平坦度FFF和峰值PPP来描述:
F=exp(1N∑i=1Nln∣X(fi)∣2)1N∑i=1N∣X(fi)∣2,P=max(∣X(fi)∣2)F = \frac{\exp\left(\frac{1}{N} \sum_{i=1}^{N} \ln |X(f_i)|^2\right)}{\frac{1}{N} \sum_{i=1}^{N} |X(f_i)|^2}, \quad P = \max(|X(f_i)|^2)F=N1∑i=1N∣X(fi)∣2exp(N1∑i=1Nln∣X(fi)∣2),P=max(∣X(fi)∣2)
其中NNN为频谱点数。 -
动态范围:
动态范围DDD定义为信号的最大值与最小值之比:
D=20log10(max(∣x(t)∣)min(∣x(t)∣))D = 20 \log_{10} \left(\frac{\max(|x(t)|)}{\min(|x(t)|)}\right)D=20log10(min(∣x(t)∣)max(∣x(t)∣))
2. 自适应编码参数选择
根据音频特征,自适应选择编码参数,包括采样率fsf_sfs、比特深度bbb和压缩算法CCC。
-
采样率选择:
对于语音信号,采样率通常选择8kHz或16kHz;对于音乐信号,采样率通常选择44.1kHz或48kHz。自适应采样率选择规则为:
fs={8kHzif Espeech/Emusic>θ44.1kHzotherwisef_s = \begin{cases} 8 \text{kHz} & \text{if } E_{\text{speech}} / E_{\text{music}} > \theta \\ 44.1 \text{kHz} & \text{otherwise} \end{cases}fs={8kHz44.1kHzif Espeech/Emusic>θotherwise -
比特深度选择:
比特深度根据动态范围DDD选择。动态范围越大,需要的比特深度越高。自适应比特深度选择规则为:
b={8bitif D<40dB16bitif 40dB≤D<80dB24bitif D≥80dBb = \begin{cases} 8 \text{bit} & \text{if } D < 40 \text{dB} \\ 16 \text{bit} & \text{if } 40 \text{dB} \leq D < 80 \text{dB} \\ 24 \text{bit} & \text{if } D \geq 80 \text{dB} \end{cases}b=⎩ ⎨ ⎧8bit16bit24bitif D<40dBif 40dB≤D<80dBif D≥80dB -
压缩算法选择:
压缩算法根据频谱特点选择。频谱平坦度FFF越高,压缩效率越高。自适应压缩算法选择规则为:
C={MP3if F>ϕAACotherwiseC = \begin{cases} \text{MP3} & \text{if } F > \phi \\ \text{AAC} & \text{otherwise} \end{cases}C={MP3AACif F>ϕotherwise
其中ϕ\phiϕ为压缩算法选择阈值。
3. 自适应编码方案应用
将上述自适应编码方案应用于附件1中的原始音乐和原始语音音频样本,记录优化后的参数选择、文件大小和音质保真度。音质保真度可以通过计算原始音频与编码后音频的信噪比(SNR)来评估:
SNR=10log10(∑t∣x(t)∣2∑t∣x(t)−x^(t)∣2)\text{SNR} = 10 \log_{10} \left(\frac{\sum_{t} |x(t)|^2}{\sum_{t} |x(t) - \hat{x}(t)|^2}\right)SNR=10log10(∑t∣x(t)−x^(t)∣2∑t∣x(t)∣2)
其中x^(t)\hat{x}(t)x^(t)为编码后的音频信号。
4. 与固定参数方案比较
将自适应编码方案与固定参数方案进行比较,说明自适应方案带来的改进。固定参数方案可以选择常用的参数组合,例如fs=44.1kHzf_s = 44.1 \text{kHz}fs=44.1kHz,b=16bitb = 16 \text{bit}b=16bit,C=MP3C = \text{MP3}C=MP3。通过比较文件大小和音质保真度,可以证明自适应方案在保证音质的同时,有效减少文件大小。
5. 结果分析
通过实验验证,自适应编码方案能够根据音频特征自动选择最佳编码参数,在保证音质的同时,显著减少文件大小。与固定参数方案相比,自适应方案在音质保真度和存储效率之间取得了更好的平衡。
问题3:自适应编码方案设计
自适应编码方案的目标是根据输入音频的特征自动选择最佳编码参数,以在文件大小和音质保真度之间取得最佳平衡。以下是实现该方案的Python代码,包括音频特征分析、参数选择和编码过程。
1. 音频特征分析
首先,我们需要分析音频的特征,包括音频类型(语音或音乐)、频谱特点和动态范围。
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def analyze_audio(audio_path):
# 加载音频文件
y, sr = librosa.load(audio_path, sr=None)
# 计算音频的频谱特征
S = np.abs(librosa.stft(y))
spectral_centroid = librosa.feature.spectral_centroid(S=S)
spectral_bandwidth = librosa.feature.spectral_bandwidth(S=S)
spectral_flatness = librosa.feature.spectral_flatness(S=S)
# 计算动态范围
dynamic_range = np.max(y) - np.min(y)
# 判断音频类型(语音或音乐)
# 这里使用简单的阈值判断,实际应用中可以使用更复杂的分类器
if np.mean(spectral_centroid) > 2000:
audio_type = "music"
else:
audio_type = "speech"
return audio_type, spectral_centroid, spectral_bandwidth, spectral_flatness, dynamic_range
2. 参数选择
根据音频特征,选择最佳的编码参数(采样率、比特深度、压缩算法等)。
def select_encoding_parameters(audio_type, spectral_centroid, spectral_bandwidth, spectral_flatness, dynamic_range):
if audio_type == "music":
# 对于音乐,选择较高的采样率和比特深度以保留更多细节
sample_rate = 44100
bit_depth = 16
compression_algorithm = "FLAC"
else:
# 对于语音,选择较低的采样率和比特深度以节省空间
sample_rate = 16000
bit_depth = 8
compression_algorithm = "AAC"
return sample_rate, bit_depth, compression_algorithm
3. 编码过程
使用选择的参数对音频进行编码,并保存为新的文件。
import soundfile as sf
def encode_audio(audio_path, output_path, sample_rate, bit_depth, compression_algorithm):
y, sr = librosa.load(audio_path, sr=sample_rate)
# 根据比特深度调整音频数据
if bit_depth == 8:
y = (y * 127).astype(np.int8)
elif bit_depth == 16:
y = (y * 32767).astype(np.int16)
# 保存音频文件
sf.write(output_path, y, sample_rate, format=compression_algorithm.lower())
4. 自适应编码方案
将上述步骤整合为一个完整的自适应编码方案。
def adaptive_encoding(audio_path, output_path):
# 分析音频特征
audio_type, spectral_centroid, spectral_bandwidth, spectral_flatness, dynamic_range = analyze_audio(audio_path)
# 选择编码参数
sample_rate, bit_depth, compression_algorithm = select_encoding_parameters(audio_type, spectral_centroid, spectral_bandwidth, spectral_flatness, dynamic_range)
# 编码音频
encode_audio(audio_path, output_path, sample_rate, bit_depth, compression_algorithm)
return sample_rate, bit_depth, compression_algorithm
# 示例:对原始音乐和语音音频进行自适应编码
music_path = "original_music.wav"
speech_path = "original_speech.wav"
music_output_path = "adaptive_music.flac"
speech_output_path = "adaptive_speech.aac"
music_params = adaptive_encoding(music_path, music_output_path)
speech_params = adaptive_encoding(speech_path, speech_output_path)
print(f"Music encoding parameters: {music_params}")
print(f"Speech encoding parameters: {speech_params}")
5. 比较与改进
通过比较自适应编码方案与固定参数方案的输出文件大小和音质保真度,可以说明自适应编码方案的改进。
def compare_encoding(audio_path, fixed_params, adaptive_params):
# 固定参数编码
fixed_output_path = "fixed_encoding.wav"
encode_audio(audio_path, fixed_output_path, *fixed_params)
# 自适应参数编码
adaptive_output_path = "adaptive_encoding.wav"
encode_audio(a
第四个问题是:
**问题4:噪声识别与去噪策略**
基于附件2中的音频文件,对样本音频进行时频分析,建立数学模型识别并量化各类噪声(如背景噪声、突发噪声、带状噪声等)的特征参数。提出一种改进的去噪策略或自适应算法,能针对不同噪声类型自动选择最佳处理方法。处理样本音频,要求在论文中给出每个音频包含的噪声种类,去噪后的音频文件的信噪比,并分析在不同噪声类型和强度下的适用范围与局限性。
同时将去噪后的音频存储为新的wav文件,并分别命名为 `part1_denoised.wav`和 `part2_denoised.wav`进行提交。
### 问题4:噪声识别与去噪策略的数学建模
#### 1. 时频分析模型
为了识别和量化音频中的噪声,首先需要对音频信号进行时频分析。常用的时频分析方法包括短时傅里叶变换(STFT)和小波变换(WT)。
**短时傅里叶变换(STFT):**
$$ X(t, f) = \int_{-\infty}^{\infty} x(\tau) w(\tau - t) e^{-j2\pi f\tau} d\tau $$
其中,$ x(\tau) $ 是原始音频信号,$ w(\tau - t) $ 是窗口函数,$ t $ 是时间,$ f $ 是频率。
**小波变换(WT):**
$$ W(a, b) = \frac{1}{\sqrt{a}} \int_{-\infty}^{\infty} x(t) \psi^*\left(\frac{t - b}{a}\right) dt $$
其中,$ \psi(t) $ 是小波基函数,$ a $ 是尺度参数,$ b $ 是平移参数。
#### 2. 噪声特征参数识别
通过时频分析,可以提取出噪声的特征参数,如频率分布、能量分布、持续时间等。具体步骤如下:
**频率分布:**
$$ F(f) = \int_{-\infty}^{\infty} |X(t, f)|^2 dt $$
**能量分布:**
$$ E(t) = \int_{-\infty}^{\infty} |X(t, f)|^2 df $$
**持续时间:**
$$ T = \int_{t_1}^{t_2} dt $$
其中,$ t_1 $ 和 $ t_2 $ 是噪声信号的起止时间。
#### 3. 去噪策略与自适应算法
基于噪声特征参数,设计自适应去噪算法。常用的去噪方法包括谱减法、维纳滤波和小波阈值去噪。
**谱减法:**
$$ \hat{X}(t, f) = \max(|X(t, f)| - |N(t, f)|, 0) $$
其中,$ |N(t, f)| $ 是噪声的幅值估计。
**维纳滤波:**
$$ \hat{X}(t, f) = \frac{|X(t, f)|^2}{|X(t, f)|^2 + |N(t, f)|^2} X(t, f) $$
**小波阈值去噪:**
$$ \hat{W}(a, b) = \begin{cases}
W(a, b) - \lambda & \text{if } W(a, b) > \lambda \\
0 & \text{otherwise}
\end{cases} $$
其中,$ \lambda $ 是阈值。
#### 4. 信噪比计算
去噪后的音频信噪比(SNR)计算如下:
$$ \text{SNR} = 10 \log_{10} \left( \frac{\sum_{t} |x(t)|^2}{\sum_{t} |\hat{x}(t) - x(t)|^2} \right) $$
其中,$ x(t) $ 是原始音频信号,$ \hat{x}(t) $ 是去噪后的音频信号。
#### 5. 适用范围与局限性分析
**适用范围:**
- 谱减法适用于平稳噪声。
- 维纳滤波适用于非平稳噪声。
- 小波阈值去噪适用于突发噪声和带状噪声。
**局限性:**
- 谱减法可能导致音乐噪声。
- 维纳滤波需要准确的噪声估计。
- 小波阈值去噪可能引入伪影。
#### 6. 结果输出
将去噪后的音频存储为新的wav文件,分别命名为 `part1_denoised.wav` 和 `part2_denoised.wav`,并在论文中给出每个音频包含的噪声种类、去噪后的音频文件的信噪比,以及在不同噪声类型和强度下的适用范围与局限性。
通过上述数学建模方法,可以有效识别和量化音频中的噪声,并设计自适应去噪算法,提升音频质量。
### 问题4:噪声识别与去噪策略
#### 1. 噪声识别与时频分析
首先,对附件2中的音频样本进行时频分析,使用短时傅里叶变换(STFT)将音频信号从时域转换到频域,以便识别噪声的频谱特征。设音频信号为$x(t)$,其STFT表示为:
$$
X(f, t) = \int_{-\infty}^{\infty} x(\tau) w(\tau - t) e^{-j 2 \pi f \tau} d\tau
$$
其中,$w(t)$是窗函数,$f$为频率,$t$为时间。通过STFT,可以得到音频信号的时频分布,从而识别噪声的频率范围和时域特性。
#### 2. 噪声特征参数提取
基于STFT结果,提取以下噪声特征参数:
- **背景噪声**:表现为低频区域的连续谱,能量分布较为均匀。其特征参数为平均能量$E_b$和频率范围$[f_{b1}, f_{b2}]$。
$$
E_b = \frac{1}{f_{b2} - f_{b1}} \int_{f_{b1}}^{f_{b2}} |X(f, t)|^2 df
$$
- **突发噪声**:表现为短时间内的高能量脉冲,特征参数为脉冲峰值$P_{burst}$和持续时间$T_{burst}$。
$$
P_{burst} = \max_{t \in [t_1, t_2]} |X(f, t)|^2
$$
- **带状噪声**:表现为特定频率范围内的窄带干扰,特征参数为中心频率$f_{band}$和带宽$\Delta f$。
$$
f_{band} = \arg\max_{f} \int_{t_1}^{t_2} |X(f, t)|^2 dt
$$
#### 3. 自适应去噪算法设计
基于上述噪声特征,设计一种自适应去噪算法,步骤如下:
1. **噪声类型识别**:根据特征参数,判断噪声类型。如果$E_b$较高且频率范围较宽,则判定为背景噪声;如果$P_{burst}$较高且$T_{burst}$较短,则判定为突发噪声;如果$f_{band}$和$\Delta f$较窄,则判定为带状噪声。
2. **去噪处理**:
- **背景噪声**:使用谱减法,将噪声频谱从信号频谱中减去。
$$
X_{denoised}(f, t) = X(f, t) - \alpha E_b
$$
其中,$\alpha$为噪声抑制系数。
- **突发噪声**:使用时域滤波,对脉冲区域进行平滑处理。
$$
x_{denoised}(t) = \text{median}(x(t - \Delta t), x(t), x(t + \Delta t))
$$
- **带状噪声**:使用陷波滤波器,滤除特定频率范围内的干扰。
$$
X_{denoised}(f, t) = X(f, t) \cdot H(f)
$$
其中,$H(f)$为陷波滤波器的频率响应。
#### 4. 去噪效果评估
计算去噪后的音频信噪比(SNR):
$$
\text{SNR} = 10 \log_{10} \left( \frac{\sum_{t} |x_{clean}(t)|^2}{\sum_{t} |x_{denoised}(t) - x_{clean}(t)|^2} \right)
$$
其中,$x_{clean}(t)$为无噪声的参考信号。
#### 5. 适用范围与局限性
- **适用范围**:该算法适用于处理背景噪声、突发噪声和带状噪声,尤其适用于音频信号中噪声类型较为单一的情况。
- **局限性**:对于复杂噪声(如多种噪声叠加)或噪声与信号频谱重叠的情况,去噪效果可能受限。
#### 6. 结果输出
将去噪后的音频存储为新的wav文件,分别命名为`part1_denoised.wav`和`part2_denoised.wav`,并提交。
### 问题4:噪声识别与去噪策略
为了实现噪声识别与去噪,我们可以使用Python中的`librosa`库进行音频的时频分析,并使用`noisereduce`库进行降噪处理。以下是一个完整的Python代码示例,用于对音频文件进行噪声识别、去噪处理,并保存去噪后的音频文件。
```python
import librosa
import noisereduce as nr
import soundfile as sf
import numpy as np
# 加载音频文件
def load_audio(file_path):
audio, sr = librosa.load(file_path, sr=None)
return audio, sr
# 时频分析(短时傅里叶变换)
def time_frequency_analysis(audio, sr):
stft = librosa.stft(audio)
magnitude, phase = librosa.magphase(stft)
return magnitude, phase
# 噪声识别与去噪
def denoise_audio(audio, sr, noise_sample=None):
if noise_sample is not None:
# 如果有噪声样本,使用样本进行降噪
reduced_noise = nr.reduce_noise(audio_clip=audio, noise_clip=noise_sample, verbose=False)
else:
# 如果没有噪声样本,使用自动噪声估计
reduced_noise = nr.reduce_noise(audio_clip=audio, verbose=False)
return reduced_noise
# 计算信噪比
def calculate_snr(original_audio, denoised_audio):
noise = original_audio - denoised_audio
signal_power = np.sum(original_audio ** 2)
noise_power = np.sum(noise ** 2)
snr = 10 * np.log10(signal_power / noise_power)
return snr
# 保存音频文件
def save_audio(file_path, audio, sr):
sf.write(file_path, audio, sr)
# 主函数
def main():
# 加载音频文件
audio_file1 = 'part1.wav' # 替换为实际文件路径
audio_file2 = 'part2.wav' # 替换为实际文件路径
audio1, sr1 = load_audio(audio_file1)
audio2, sr2 = load_audio(audio_file2)
# 时频分析
magnitude1, phase1 = time_frequency_analysis(audio1, sr1)
magnitude2, phase2 = time_frequency_analysis(audio2, sr2)
# 噪声识别与去噪
denoised_audio1 = denoise_audio(audio1, sr1)
denoised_audio2 = denoise_audio(audio2, sr2)
# 计算信噪比
snr1 = calculate_snr(audio1, denoised_audio1)
snr2 = calculate_snr(audio2, denoised_audio2)
print(f"Part1 SNR: {snr1:.2f} dB")
print(f"Part2 SNR: {snr2:.2f} dB")
# 保存去噪后的音频文件
save_audio('part1_denoised.wav', denoised_audio1, sr1)
save_audio('part2_denoised.wav', denoised_audio2, sr2)
if __name__ == "__main__":
main()
更多内容具体可以看看我的下方名片!
里面包含有本次竞赛一手资料与分析!
另外在赛中,我们也会陪大家一起解析建模比赛
记得关注Tina表姐哦~

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)