《看穿一切数字的统计学》读书笔记
这算是一本统计学入门书籍,一方面通过该书,告诉我们统计学的强大威力;另一方面,也提醒我们要注意数据处理的误区。
| 书名 | 看穿一切数字的统计学 |
|---|---|
| 作者 | [日]西内启 著;朱悦玮 译 |
| 出版社 | 中信出版社 |
| ISBN | 978–7–5086–4206–2 |
这算是一本统计学入门书籍,一方面通过该书,告诉我们统计学的强大威力;另一方面,也提醒我们要注意数据处理的误区。
大数据时代,我们的通常认为有了全量数据,那就根本不用考虑抽样调查的问题了,实际工作中我们确实也是这么干的,想尽一切办法,快速处理更大更全的数据,以期获得更准确、实时的结果,但真的有必要吗?有没有更优的方法呢?该书给出了新的答案。
1、为什么统计学是最牛的学问
1903年,“科幻小说之父”–赫伯特·乔治·威尔斯曾经预言,在未来社会,统计学思维将像阅读能力一样成为社会人必不可少的能力。
没有阅读能力就无法理解合同和法律中的内容,没有统计学思维就无法了解概率和数据。
为什么统计学会成为最强的武器呢,用一句话来回答,那就是不管在什么领域,收集数据进行分析都是得出最好、最快答案的方法。
现代医疗最重要的手段叫作EBM(Evidence–Based Medicine),翻译过来就是“基于实证的医疗”,也叫“循证医学”。而在上述的实证之中最重要的一环,就是通过科学的方法所得出的统计数据和分析结果。
曾经人类为了得到(自认为)正确的答案而只能寻求神的启示,后来在漫长时间中只能服从权威人士的意见。但是,现在的情况不一样了。最佳答案就存在于每个人周围的数据之中。
2、大幅减少信息成本的抽样调查
在当今时代,“大数据”一词炙手可热,但“大数据分析”会产生什么样的价值?企业真的需要花费巨大代价存储好几万亿字节的庞大数据吗?作者表示,纯粹的技术进步和商业利益之间是没有必然联系,只要掌握了统计学的知识,就会明白基于数据进行正确的经营判断时,根本不需要花费如此巨大的投资。
“大萧条”时期,为了统计失业人口,提出的“随机选取人口总数的0.5%进行抽样调查”。经过随后十几年的慎重检验,发现其准确程度令人震惊。
对于抽样调查结果和真实结果之间的误差专业上会通过标准误差公式来计算
- 比如说,从10万名顾客的数据中对男女性别比率进行调查的结果,假设顾客中女性的比率占70%。那么关于这一结果的标准误差,在增加抽样调查的人数之后会发生怎样的变化呢。结果如图2–3所示。
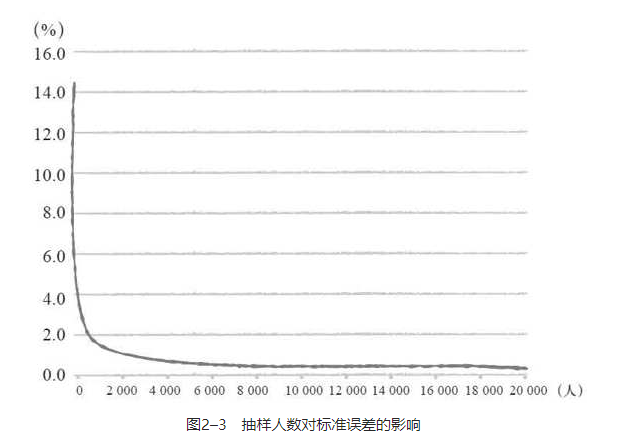
- 继续增加抽样调查人数对标准误差的影响越来越小
这种方法在进行数据分析时“先找到为了进行正确的判断所必需的最少数据”,与现在大数据时代的思考方式刚好相反。
分析本身没有价值,活用分析的结果,才能得到价值。
3、统计学的关键:误差与因果关系
如何让数据分析产生价值,即如何让分析结果“在商业中与具体的行动联系起来”,就必须回答以下“3个问题
- 问题1 做出何种改变能够增加利益?
- 问题2 是否能够做出这种改变?
- 问题3 如果能够做出这种改变,那么带来的利益是否大于所消耗的成本?
而要回答这些问题,就必须使用20世纪先进的现代统计学方法。
单纯的收集数据,可能会得出毫无因果关系的荒谬结论。
作者强调,我们不要用“经验和直觉”这种容易被“记忆偏差”所影响的认识来做判断,而是要用统计学来弥补人性上的这些弱点。
对于电子商务企业常用的A/B测试(统计学上称之为随机对照试验),作者指出其中存在一个陷阱,那就是他们没有考虑误差。这时就要用到卡方检验与p值。
- 实际上没有任何区别,只是因为误差或偶然产生数据差(甚至有可能包括极端的差距)的概率在统计学上称为p值。p值越小(一般在5%以下),数据就越准确
- 只有理解误差,并将误差考虑进去的结果才有意义。
究竟应该对什么样的数据进行比较分析?
收集数据分析,就是将“能够达成目标的事物”与“不能够达成目标的事物”进行比较。在商业领域,检验一个数据是否值得分析,就看它是否能带来直接利益,或者是否能表明带来利益的因果关系。
通过以上方法找到有意义的数据之后,在分析时还必须注意“因果关系的方向”。比如:
- 是因为看到广告才购买商品?还是因为购买商品之后才对广告印象深刻?
- 是因为玩暴力游戏才成为少年犯?还是因为有暴力倾向的人爱玩暴力游戏?
统计学上可以对假设进行验证,在不同程度上了解假设的准确性。同时比较的过程中还要保证“公平”。
4、最强的统计学武器:随机对照试验
费希尔创造的随机对照试验的方法,不但改变了科学哲学,甚至使科学能够影响到的领域爆炸性的扩大。在他的《试验设计》一书中对进行科学证明而选择的顺序中指出,最重要的一点就是“随机”。
科学方法论的重要特征–“观察与试验”,观察”就是对目标进行详细的观看和测量,并且从中找出真相的行为。“试验”则是在改变各类条件的前提下对目标进行观察的行为。
当某种现象不会百分百出现时,费尔希提出将随机因果关系用概率的形式表现出来。
想要对肥料A和肥料B与小麦产量之间的关系进行科学分析的话,试验结果确实很容易受排水、土壤肥沃程度、日照等客观条件的影响。但是,如果将耕地分为许多单位,随机将肥料撒在耕地上,那么施加肥料A的土地分组和施加肥料B的土地分组之间,平均条件就会大致相同。采取随机化的方法,可以使进行比较的两组之间各个条件基本相同。而唯一不同的条件,就是我们希望通过试验进行控制的肥料。如果在这种状态下,两组的产量出现了“并非误差的差距”,那么我们就可以用实际情况来证明“肥料的不同是使产量出现差距的原因”这一因果关系。
- ps:另外,要注意人类“潜意识”的随意判断会影响真正的随机结果。
虽然随机化是统计学中最强有力的武器,但是武器不能随时随地的使用。在这个世界上,有本身就无法进行随机化的情况,有不允许进行随机化的情况,还有虽然可以进行随机化,但如果进行随机化就会出现巨大损失的情况。这3种情况,分别被称为“现实”之壁,“伦理”之壁以及“感情”之壁。
5、无法进行随机对照试验时该怎么办
无法进行随机化并不意味着统计学就完全无法发挥作用,单纯的进行观察也可以发挥统计学的巨大力量。例如,病例对照研究和那些在结果出现前就一直进行持续调查的流行病学研究。另外还有回归分析方法。
展现数据之间的关联性,检测是否属于误差范围的所有方法,大体上都可以看做回归分析的一种方法。
不管是身高还是才能,或者生物的特征等,这个世界上的所有现象都拥有其独特的“随机性”,在统计结果上“回归平凡”,这种现象被称为“均值回归”。
只要你能够看懂回归系数的误差与置信区间的数值之间的联系,那么你的统计能力就会得到大幅提升。
“广义的回归分析”被统计学家们称为广义线性模型。所谓线性,指的就是回归分析中用直线表示的关系性。
广义线性模型对学习者来说简单易懂、一目了然,而且应用范围广阔。
通过下图可以对几乎所有的数据之间的关联性进行分析,并对将来的结果进行预测。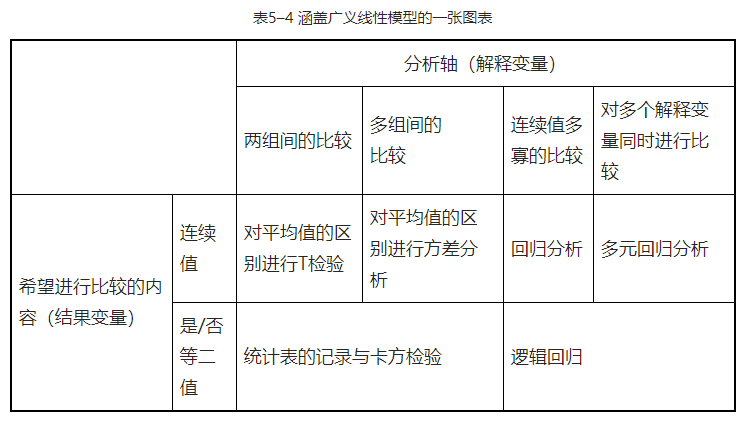
- 辛普森悖论
- 全体进行的单纯比较比内部小群体进行的比较结果相矛盾的情况。
- 要想防止辛普森悖论,就需要像流行病学的观察研究那样保证条件的一致性。
- 这种将具有同样条件的群体进行比较分析的方法,被称为分组分析。
- 但是当“影响结果的条件”越来越多时,这种方法就会逐渐变得不那么可靠。
面对“辛普森悖论”的问题,多元回归分析就会发挥出威力。然后作者以案例的形式讲解了“多元回归分析”和“逻辑回归分析”的方法。*这里作者用这这两个概念对案例的分析解释的不是很清楚,我建议还是直接去网上看相关概念的解释。*
6、应对一切问题的统计学思考方法
这一章作者通过以下几个领域对统计学的应用,阐述了6个种统计学思考方法。
- 把握实际动态的社会调查法。
- 为了找出原因的流行病学——生物统计学。
- 检测抽象概念的心理统计学。
- 进行机械化分类的数据挖掘。
- 对自然语言进行处理的文本挖掘。
- 关心演绎的计量经济学。
并通过讲述贝叶斯派与频率派的对立,指出学习者要能够通过理解统计学家们不同的思考方式,站在不同的立场上增加自己的知识积累,才是正确的选择。
7、帮你站在巨人肩膀上的统计学
学习前人们总结出来的经验和智慧,并且以此为基础进行研究远比自己绞尽脑汁地去思考要看得更远。统计能力可以使你更加迅速而且准确地利用这些前人的智慧,从而站在巨人的肩膀之上。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)