深度学习--TensorFlow (1)单层感知器1 -- 实现单数据训练
目录基础理论1、单词感知器介绍2、单词感知器学习规则前向传递(得到输出y)反向传递(更新权重w)手写单层感知器1、初始参数设置2、正向传播(得到输出y)3、 反向传播(更新权重参数)总代码基础理论1、单词感知器介绍感知器:模拟生物神经网络的人工神经网络结构。w:权值,可以调节神经信号输入值的大小。b:偏置,相当于神经元内部自带的信号。f(x):激活函数,信号进行线性/非线性变化。(有sign、si
·
目录
一、基础理论
1、单词感知器介绍
感知器:模拟生物神经网络的人工神经网络结构。
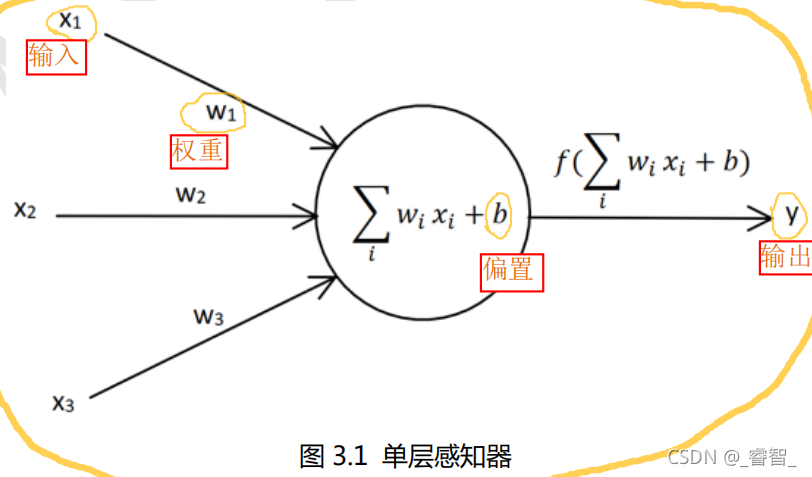
w:权值,可以调节神经信号输入值的大小。
b:偏置,相当于神经元内部自带的信号。
f(x):激活函数,信号进行线性/非线性变化。(有sign、sigmoid、relu等等激活函数)
例:
一个典型的激活函数:sign(x):当x>0时,输出为1;当x=0时,输出为0,当x=-1时,输出为-1。

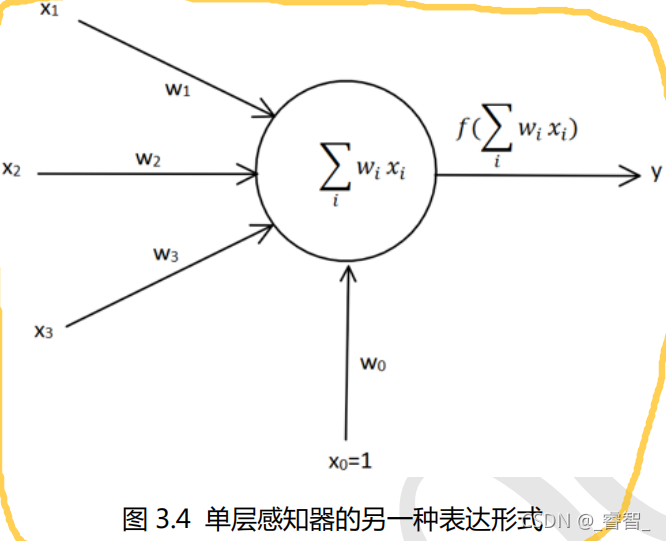
(把最开始的单层感知器的偏置值b变成了输入w0*x0,w0*x0实际上就是w0)
2、单词感知器学习规则
感知器学习规则:感知器中的权重参数w训练方法。
前向传递(得到输出y)
(b是偏置)

反向传递(更新权重w)
更新权重:

二、实现单层感知器
1、初始参数设置
先设置初始参数,输入、权重、偏置、正确标签、学习率等等。
# 输入
x0, x1, x2 = 2, 4, 7
# 初始权重
w0, w1, w2 = 3, 5, 6
# 偏置
b = 1
# 标签(正确标签,训练结束的目标)
true = -1
# 学习率(即yingta)
lr = 1(犯了一个愚蠢的错误,sign函数最后的结果只有-1和1两个值,我居然设置了一个12的标签,自然永远都不可能满足要求)
2、正向传播(得到输出y)
# 开始训练(正向、反向传播)
for i in range(100):
# 2、正向传播:求输出y
# 这里选用sign激活函数
y = np.sign(w0*x0+w1*x1+w2*x2)
print(w0, w1, w2)
print(y)
3、 反向传播(更新权重参数)
# 3、反向传播:更新权重参数
# 如果没有达到训练目标,更新w权重
if y != true:
w0 += lr * (true - y) * x0
w1 += lr * (true - y) * x1
w2 += lr * (true - y) * x2
else:
print('训练成功!y = ', y)
break
换一组数据:

(可以看出来,数据越大,需要训练的次数越多)
总代码
# 手写单层感知器
import numpy as np
# 1、设置初始参数
# 输入
x0, x1, x2 = 2, 4, 7
# 初始权重
w0, w1, w2 = 13, 15, 16
# 偏置
b = 1
# 标签(正确标签,训练结束的目标)
true = -1
# 学习率(即yingta)
lr = 1
# 开始训练(正向、反向传播)
for i in range(100):
# 2、正向传播:求输出y
# 这里选用sign激活函数
y = np.sign(w0*x0+w1*x1+w2*x2)
print(w0, w1, w2)
print(y)
# 3、反向传播:更新权重参数
# 如果没有达到训练目标,更新w权重
if y != true:
w0 += lr * (true - y) * x0
w1 += lr * (true - y) * x1
w2 += lr * (true - y) * x2
else:
print('训练成功!y = ', y)
break
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)