动手学深度学习 - 卷积神经网络 - 7.3. Padding 和 Stride
📘 本文对应李沐《动手学深度学习》7.3 节内容,讲解 CNN 中控制特征图尺寸变化的两个关键技术:Padding(填充)与 Stride(步幅)。
🧱 新所得库 - 深度卷积网络中的 Padding 与 Stride 精讲实战
📘 本文对应李沐《动手学深度学习》7.3 节内容,讲解 CNN 中控制特征图尺寸变化的两个关键技术:Padding(填充)与 Stride(步幅)。
7.3 Padding 和 Stride
在图像卷积过程中,如果每次卷积核都从左上角出发逐像素滑动,那么输出的尺寸会逐层缩小。当堆叠多个卷积层后,图像的边缘信息可能彻底丢失。因此,我们需要引入两种控制输出尺寸的机制:
-
Padding(填充):扩展输入边界,防止尺寸过早缩小;
-
Stride(步幅):跳跃滑动窗口,控制压缩率,降低计算成本。
7.3.1 填充(Padding)
在标准卷积中,输入图像的边缘像素因无法被完全覆盖,往往被忽略,导致“像素利用率”变差,如图所示: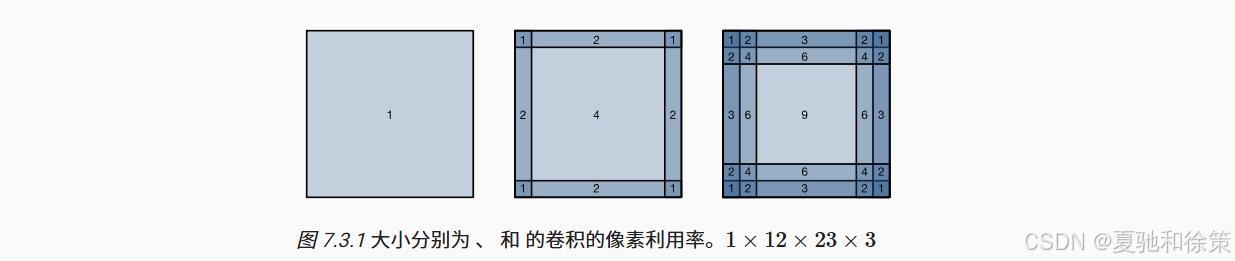
🖼️ 图 7.3.1:不同卷积核大小对像素利用率的影响。可以看到角落几乎完全无参与。
🔧 解决办法:填充
我们通常通过在图像四周添加 0 像素的边框来扩展尺寸。这一操作被称为 填充(padding)。如下图所示: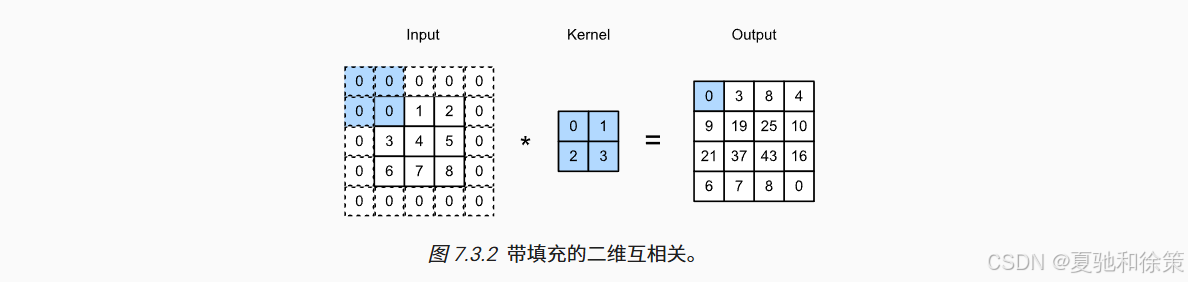
🖼️ 图 7.3.2:带填充的二维互相关,填充后输出矩阵尺寸不再缩小。
📐 输出尺寸计算公式:
假设填充高度为 php_h,填充宽度为 pwp_w,卷积核尺寸为 kh×kwk_h \times k_w,输入尺寸为 nh×nwn_h \times n_w,则输出尺寸为:
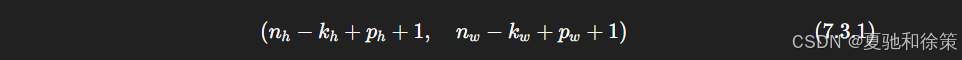
✅ 常用实践:
-
使用奇数大小卷积核(如 3×3、5×5)+ 对称填充,可以保持输出尺寸不变;
-
保持输入输出尺寸一致是图像任务中常见的需求(如语义分割、自动编码器等);
-
PyTorch 中
padding=1搭配kernel_size=3可实现等尺寸输出。
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape # 输出为 torch.Size([8, 8])
🎯 更复杂的填充设置:
可为高和宽分别设置不同的填充量:
conv2d = nn.LazyConv2d(1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape # 仍保持为 (8, 8)
🎓 理论理解:
在卷积层中,如果不使用填充,输入图像会在每一层“缩水”。比如一个 5x5 图像经过一次 3x3 卷积后,输出就变为 3x3。
为了防止这种快速压缩,我们会在输入图像的边缘填充像素(通常为 0),扩大输入的“有效区域”。
输出尺寸公式为:
其中 ph,pwp_h, p_wph,pw 是填充高度和宽度。
🏭 企业实战理解:
-
字节跳动/抖音短视频推荐模型中,使用 padding=1, kernel=3 保证每一层输出尺寸不变,使得模型可以做深度堆叠,尤其用于高分辨率图像内容理解。
-
Google 在 DeepLab V3 语义分割中广泛使用 same padding,保证像素级对齐,提升 mask 的边界精度;
-
NVIDIA 推理优化工具 TensorRT 会根据 padding 自动融合卷积操作,减少内存拷贝,提高推理效率。
7.3.2 步幅(Stride)
默认情况下,卷积窗口每次移动一个像素(stride = 1)。但如果我们每次跨多个像素滑动窗口,会带来两个优势:
-
减少计算量;
-
缩小特征图尺寸(即下采样效果)。
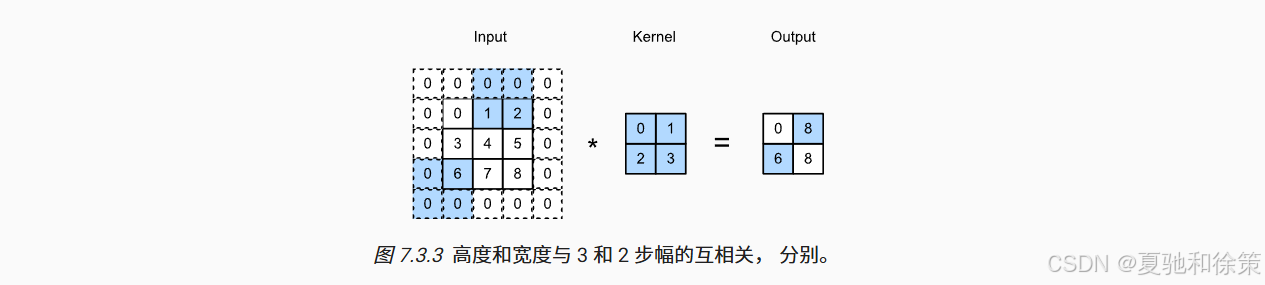
🖼️ 图 7.3.3:高和宽分别为 3 和 2 的步幅下,卷积窗口跳跃滑动。
📐 输出尺寸计算公式:
当 stride 为 sh×sws_h \times s_w 时,输出尺寸为:
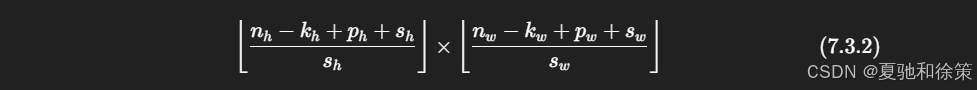
若 stride 恰好整除输入尺寸,则可简化为:
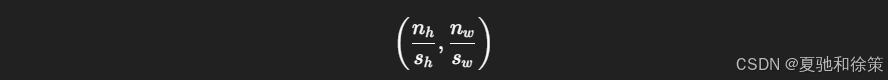
✅ 典型用法:
将特征图尺寸缩小一半:
conv2d = nn.LazyConv2d(1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape # 输出为 torch.Size([4, 4])
设置不对称 stride:
conv2d = nn.LazyConv2d(1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape # 输出为 torch.Size([2, 2])
🎓 理论理解:
Stride 决定卷积窗口每次滑动的距离:
-
默认 stride=1stride=1stride=1:逐像素滑动;
-
设置 stride>1stride > 1stride>1:跳着滑动,常用于下采样。
输出尺寸计算公式:

可以看出,stride 越大,输出越小。
🏭 企业实战理解:
-
百度搜索引擎中使用 stride=2 卷积替代 pooling,进行语义压缩同时保留上下文感知能力;
-
OpenAI 在 GPT-Vision 类 Transformer 模型中 使用嵌入模块基于 stride-4 卷积进行 Patch 提取,减少计算量;
-
NVIDIA 在实时目标检测 YOLOX 中使用 stride=2 提取多尺度特征图,提升小目标检测性能;
-
字节跳动推荐系统中,对用户点击轨迹做序列卷积时使用 stride=2 加速推理、提取局部行为模式。
7.3.3 小结与讨论
-
Padding 是为保持输出尺寸或防止边界信息丢失而在输入边界添加像素;
-
Stride 控制卷积窗口每次移动的跨度,常用于下采样;
-
组合使用 padding 和 stride 能实现灵活的特征图尺寸控制;
-
实际中多使用零填充(zero-padding),因其计算效率高、实现简单;
-
PyTorch、TensorFlow 等框架均支持 kernel、padding、stride 的独立设置。
| 属性 | 作用 | 应用场景 |
|---|---|---|
| Padding | 防止尺寸过早变小,保留边缘 | 图像语义对齐、语义分割、风格迁移 |
| Stride | 控制输出尺寸压缩率 | 特征下采样、加快计算、减少显存 |
默认:
-
padding = 0 → 不填充;
-
stride = 1 → 步幅为1。
🚧 关于零填充的讨论:
-
零填充有明显计算优势,GPU 加速库可以融合 padding + conv;
-
但某些任务(如图像修复、风格迁移)需要非零填充,如 reflection、replicate;
-
Alsallakh 等人在 2020 年提出更鲁棒的 padding 替代方案,但仍需根据任务性质权衡使用。
7.3.4 练习建议
-
理解 kernel=3, padding=1, stride=2 的输出尺寸计算方式;
-
推导图中示例代码的输出尺寸是否正确;
-
思考音频信号中 stride=2 表示什么(→ 下采样);
-
尝试实现镜像填充(reflection padding);
-
步幅大于 1 在计算与统计上的潜在优势。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)