数据分析_对数据的基础操作_加载、查看、简单数据分析---以kaggle经典案例——泰坦尼克号为例
本文利用kaggle经典案例---泰坦尼克号, 用python语言, 基于pandas库, 主要面向数据分析初学者和想要了解数据分析的人群,简要介绍了数据分析时的基本操作命令和在实战中数据分析的思路及方法.数据基本操作命令由加载数据、认识数据的不同类型、数据预处理、数据可视化等构成, 并提到了多种在加载数据、数据查看、保存数据时初学者常遇到的问题及解决方法.在数据分析的实战中, 介绍了基本思路及方
数据分析 加载、查看、简单数据分析---------以kaggle经典案例——泰坦尼克号为例
Python语言 pandas和numpy库
文章目录
前言
随着现代社会的不断发展,数据分析在我们的日常生活和学习中, 发挥着越来越重要的作用. 所谓"数据分析", 就是将用适当的统计分析方法, 对搜集来的大量数据进行处理、分析, 将所得数据汇总, 进而理解数据所表达的内容, 以求最大化利用所得数据, 提取有效信息, 辅助对相关问题的研究.
本文结合了kaggle经典案例——泰坦尼克号的相关数据, 介绍了数据分析中, 对数据的基础操作, 包括数据加载、数据查看、对数据的的简单分析等.
以下是本篇文章正文内容,可供参考, 如有错漏, 欢迎指正
一、数据的基础操作命令
1. 加载数据
1.1 加载数据
本文以.csv导入为例, 除此之外, 常见的还有table格式导入
两种格式在一定程度下, 可实现"转换".
#如果想将table和.csv读取成一样的结果 (看起来一样) 将默认的分割sep参数 改掉
df0=pd.read_table('train.csv',sep=',')
1.1.1相对路径
df = pd.read_csv('train.csv')
1.1.2 绝对路径
df = pd.read_csv('C:/Users/Desktop/数据分析/train.csv')
1.2 加载数据时的特殊情况
1.2.1 绝对路径导入数据报错
检查绝对路径好麻烦QWQ…
那么!
可以!!
酱紫啦!!!
将需要处理的数据文件, 放入当前工作目录中, 通过查看所在工作目录的方法 os.getcwd() 得到绝对路径, 即可!
Tip: 记得~ import os
import os
path = os.path.abspath('train.csv')
df = pd.read_csv(path)
1.2.2 导入数据较大
当导入数据大时, 可使用chunker(数据块)进行逐块读取
#在pandas中获得chunk
df.get_chunk()
2. 认识数据
2.1 数据类型
pandas中有两个重要的数据类型DateFrame和Series. 接下来会通过例子认识它们.
获取数据类型.
type(df)
2.1.1 DateFrame
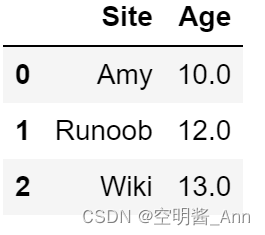
data = [['Amy',10],['Runoob',12],['Wiki',13]]
df1 = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df1)
2.1.2 Series
a = ["Google", "Runoob", "Wiki"]
ds = pd.Series(a, index = ["x", "y", "z"])
print(ds)

2.2 数据预处理
2.2.1 查看数据表格的大小
df.shape
2.2.2 更改数据表格名称
例: 表头的中英文转换
df.columns=['乘客ID','是否幸存','乘客等级(1/2/3等舱位)','乘客姓名','性别',
'年龄','堂兄弟/妹个数','父母与小孩个数','船票信息',
'票价','客舱','登船港口']
'''PassengerId => 乘客ID
Survived => 是否幸存
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口'''
修改前:
修改后:

2.2.3 查看数据缺失值
df.isnull() #判断缺失值 判断数据是否为 空--True/非空--False
2.2.4 查看表格列名称
df.columns
2.2.5 查看指定列的值
df['Cabin'].head(3)#.head() 指定只显示前3

2.2.6 删除多余列
方法一:
del test_1['a']
方法二:
test_1.drop(['a'],axis=1,inplace=False)# False 默认值 可不写
#注意 inplace这个参数 True时候 不是副本 反之, 对比如下, 只是[忽略],是副本
2.2.7 忽略某些列
test_1.drop(['a'],axis=1,inplace=True)
#注意 inplace这个参数 True时候 不是副本 反之, 对比如上, 只是[忽略],是副本
2.2.8 显示数据
显示表格的前10行(默认值:5)
df.head(10)
显示表格的后10行(默认值:5)
df.tail(10)
loc显示指定数据
例: 将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage1.loc[[100,105,108],['Pclass','Name','Sex']]

iloc显示指定数据
与loc方法显示数据不同, loc使用名称;
iloc使用位置. 需要看要查找的在第几列注意: DataFrame的第一从0开始算
例; 将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage1.iloc[[100,105,108],[3,4,5]]

3. 分析数据
3.1 数据的排序
3.1.1数据排序
结合numpy库, 生成随机数据, 用作例子
sample = pd.DataFrame(np.random.randn(3,3),
index=list('213'),
columns=list('bca'))
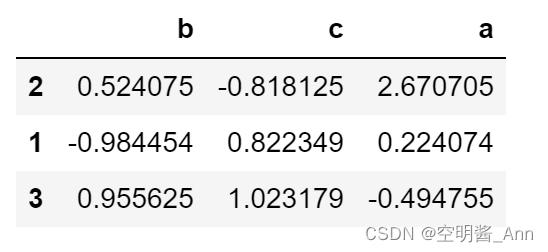
b 列索引 按照升序排列 最大的在上
sample.sort_values('b')
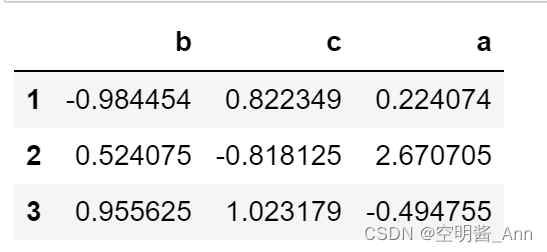
行索引 升序排列
sample.sort_index()
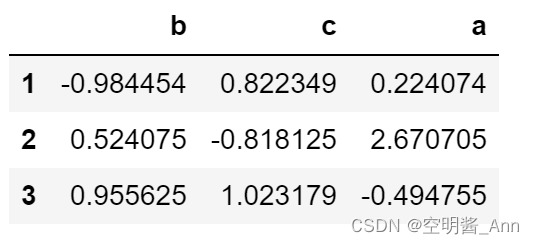
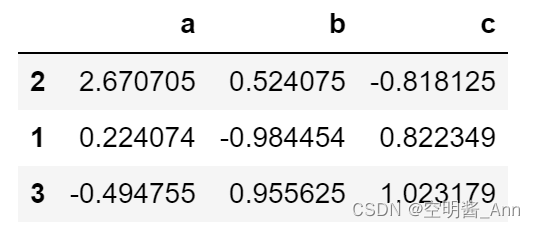
列索引 升序排列
sample.sort_index(axis=1) #修改默认参数 axis=0
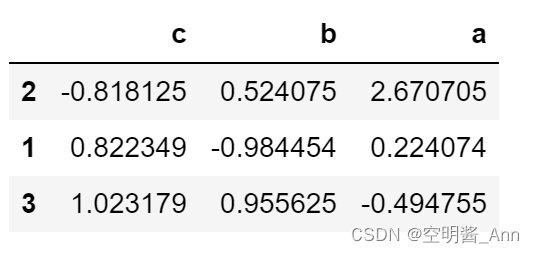
列索引 降序排序
sample.sort_index(axis=1,ascending=False)
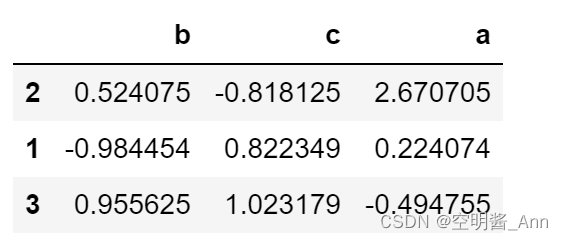
指定的列 降序排序
sample.sort_values(['a','c'],ascending=False)
3.1.2 数据排序时遇到问题
当数据经过初步处理后, 排序的索引值已然发生变化, 这时若仍然直接按照原始值索引, 并不能得到想要的结果.
因此, 需要对数据重新设置索引, 以解决数据索引问题.
#index索引
midage1.index
#重新设置数据索引
midage1 = midage.reset_index(drop=True)
midage1.to_csv('midage1.csv')
3.2 筛选数据
例:
以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midag
midage= test_1[(test_1['Age']>10) & (test_1['Age'] < 50) ] #交集
midage.head()
3.3 数据分析
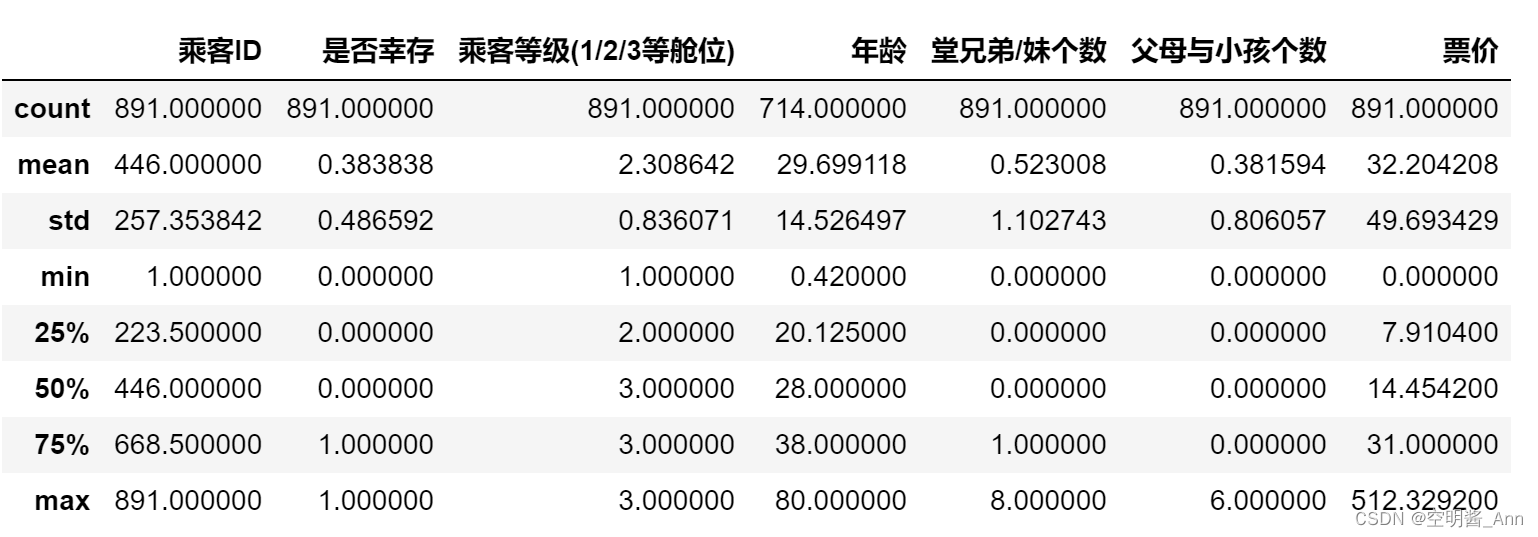
3.3.1 描述性统计数据

df.describe()
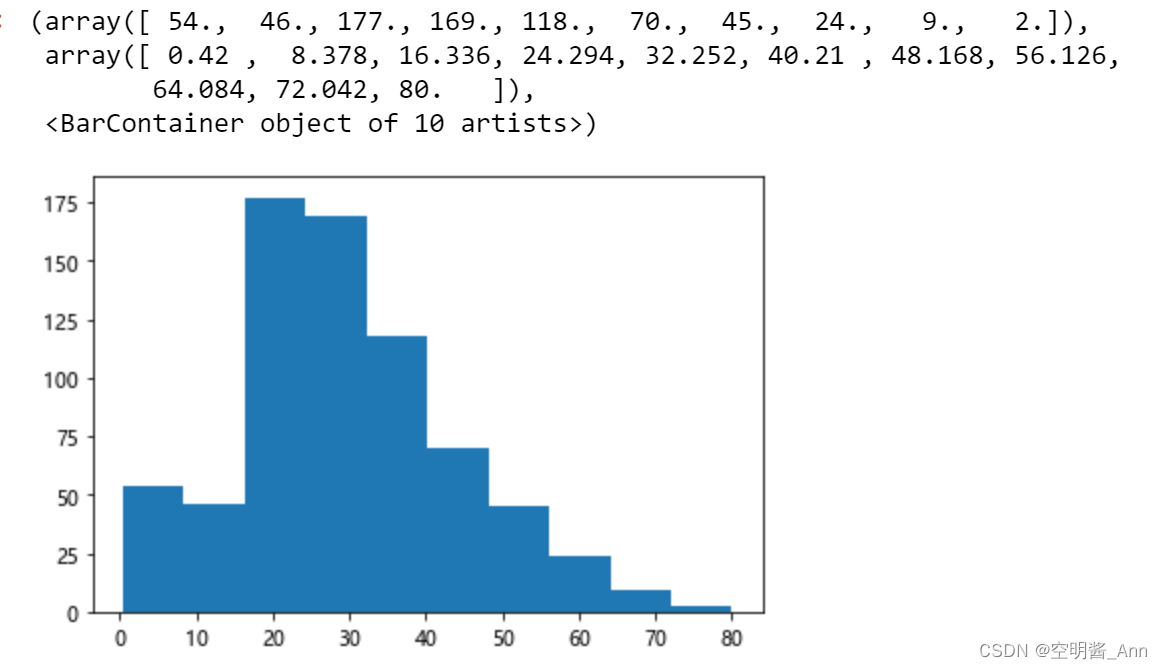
3.3.2 数据可视化
from matplotlib import pyplot as plt
plt.hist(df['年龄'])
4. 保存数据
4.1 保存数据
df.to_csv('train_chinese.csv')
4.2 保存时乱码
不同的操作系统保存, 极有可能出现乱码.
可加入encoding='GBK' 或者 ’encoding = ’utf-8‘尝试解决.
df.to_csv('train_chinese.csv',encoding='GBK')
二、数据分析案例实践
首先在kaggle网页, 获取相关数据, kaggle经典案例—泰坦尼克号
接下来进入数据分析.
1.引入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
2.读取数据
df = pd.read_csv('train.csv')

3. 数据分析
首先, 查看数据缺失值, 对数据进行预处理;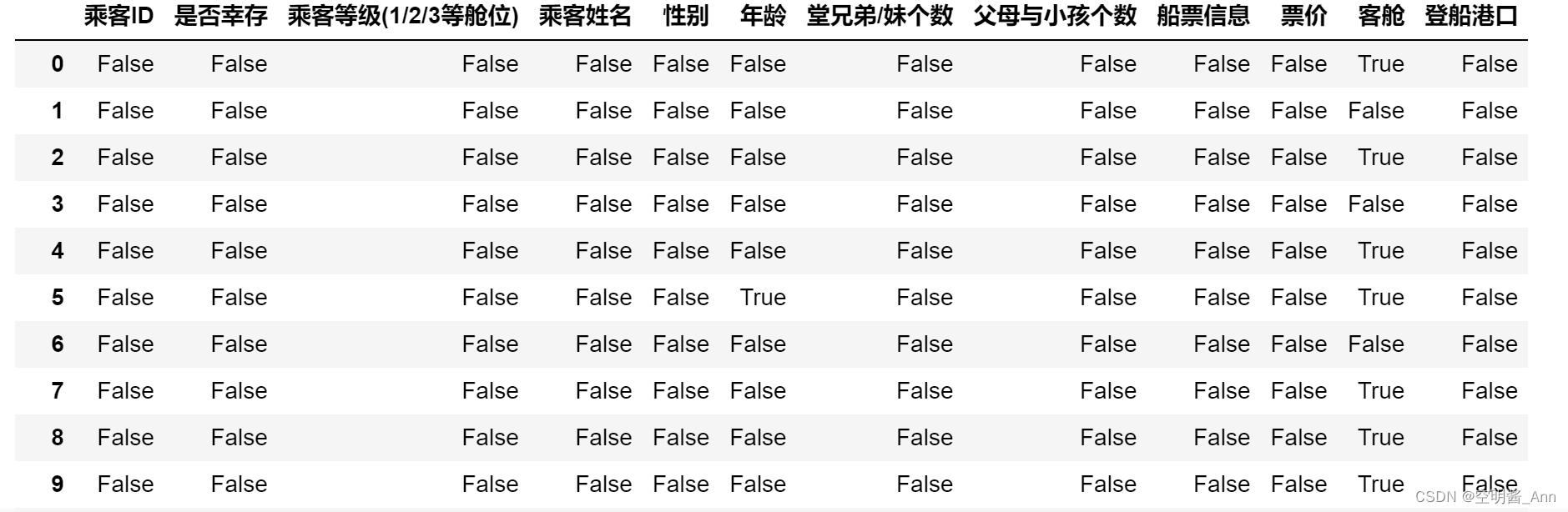
接着, 打印数据摘要, 查看数据的描述性统计信息, 根据信息推断, 可能导致乘客遇难的因素;
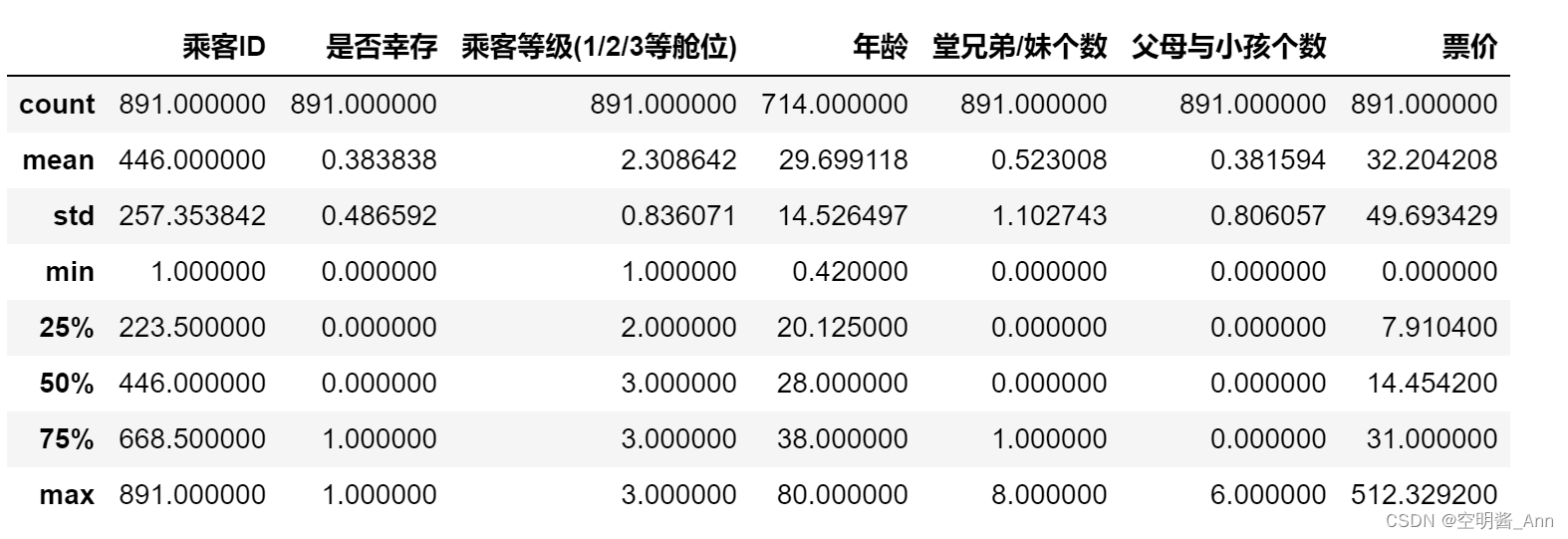
然后, 为进一步找到乘客遇难的关键因素, 对数据进行排序处理.
从中基本可推断, 票价越高的乘客, 存活几率越高.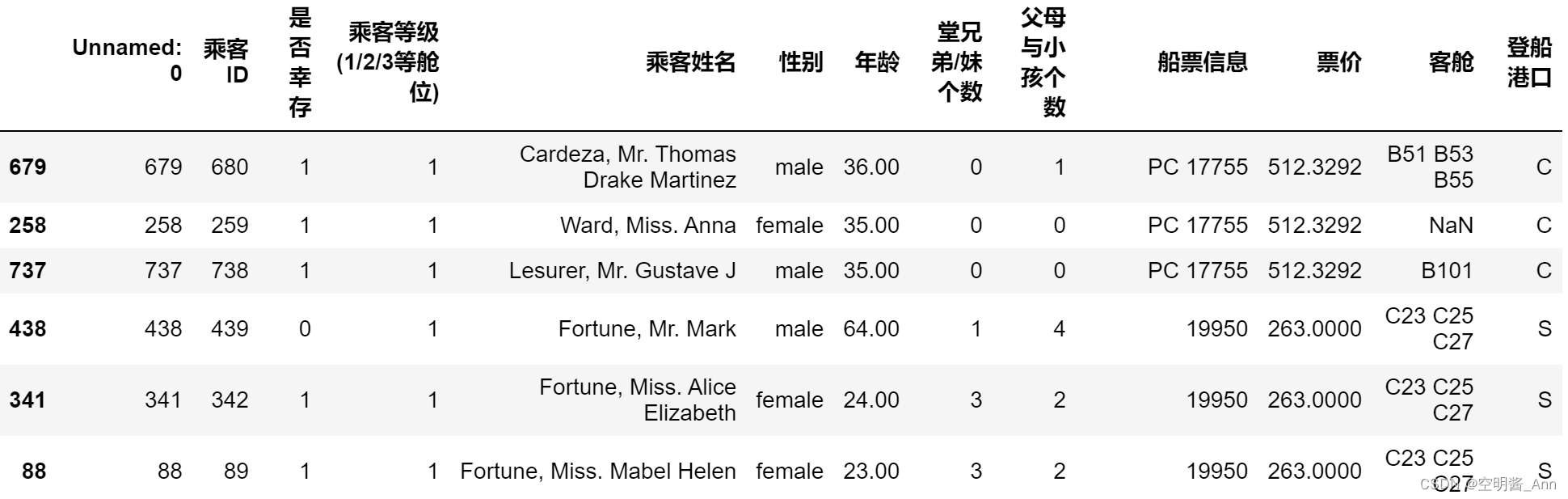

最后, 运用数据可视化的方式, 将结果更为清晰直观地呈现.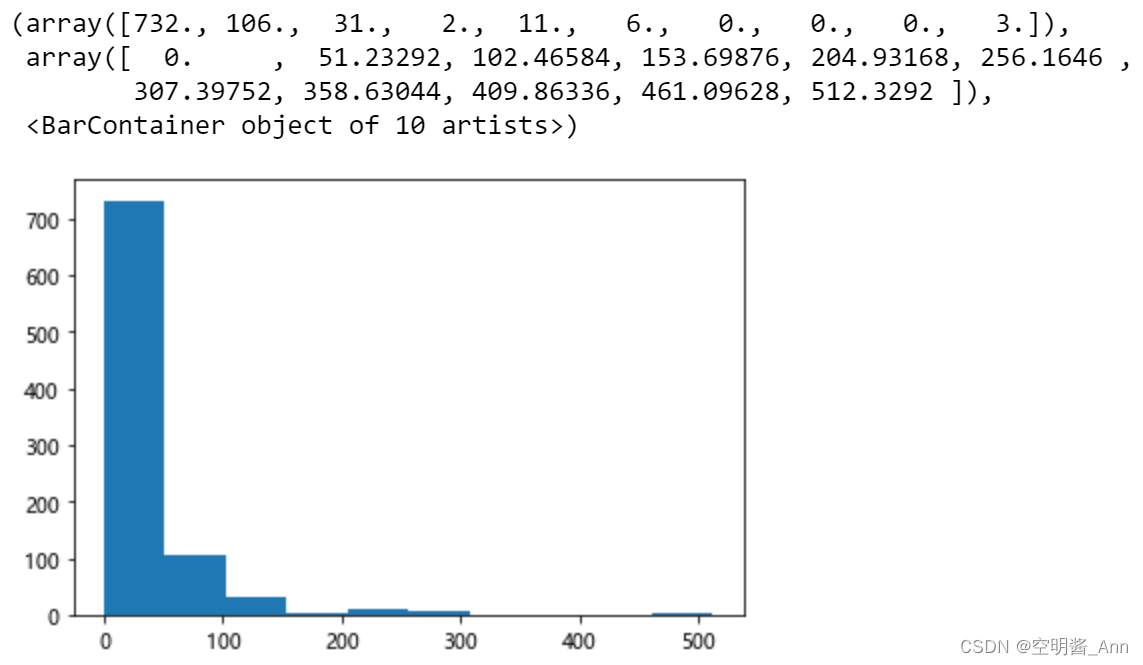
主要代码示例如下:
df.isnull()
df.info()
df.describe()
df.sort_values(['票价','年龄'],ascending=False)
df['票价'].describe()
#得到统计表 通过画图来直观感受一下
from matplotlib import pyplot as plt
plt.hist(df['票价'])
4. 保存数据
df.to_csv('train_chinese.csv',encoding='GBK')
总结
以上就是本文的主要内容. 主要从kaggle经典案例——泰坦尼克号出发, 以Python语言为例, 简要介绍了pandas中的基本数据分析的方法.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)