【python】python上市企业财务数据分析与可视化(源码+数据集)【独一无二】
要求加载CSV文件,清理无效列,确保列名和数据格式规范,筛选特定时间段的数据,计算财务指标并保留2位小数。最终,生成一个包含标题、坐标轴名称、图例和工具箱的交互式折线图,并保存为HTML文件供展示。对数据的列名进行处理,确保列名为字符串格式且去除首尾空格,这有助于避免在后续处理中因为列名不一致而产生错误。从原数据中筛选出‘流动资产合计(万元)’和‘资产总计(万元)’这两行数据,以便进行后续分析。将
python财务数据分析与可视化(源码+数据集)【独一无二】
1. 设计要求
设计要求:该项目旨在使用pandas库对财务数据进行清洗、处理和分析,计算“流动资产占比”比率,并通过pyecharts生成折线图进行可视化展示。要求加载CSV文件,清理无效列,确保列名和数据格式规范,筛选特定时间段的数据,计算财务指标并保留2位小数。最终,生成一个包含标题、坐标轴名称、图例和工具箱的交互式折线图,并保存为HTML文件供展示。
2. 设计思路
1. 数据加载与清理部分:
-
加载数据:
data = pd.read_csv('cwbbzy_600871.csv')代码首先通过
pandas库的read_csv函数加载CSV文件中的数据。data变量存储了加载后的数据。 -
处理列名:
data.columns = data.columns.astype(str).str.strip()对数据的列名进行处理,确保列名为字符串格式且去除首尾空格,这有助于避免在后续处理中因为列名不一致而产生错误。
-
删除无效列:
data = data.drop(columns=['Unnamed: 15'])删除了无用的列
Unnamed: 15,该列可能是CSV文件中自动生成的无效列。 -
处理列名为日期格式:
data.columns = pd.to_datetime(data.columns, errors='coerce') data = data.loc[:, data.columns.notna()]将所有列名转换为日期格式,以便进行日期排序和筛选。无效日期会被转换为
NaT(即缺失值),然后将这些无效的列删除。
2. 数据筛选与处理:
-
筛选特定数据行:
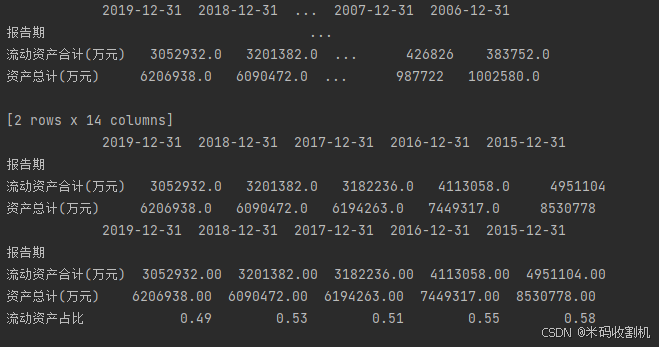
filtered_data = data.loc[['流动资产合计(万元)', '资产总计(万元)']]从原数据中筛选出‘流动资产合计(万元)’和‘资产总计(万元)’这两行数据,以便进行后续分析。
-
数据转换:
filtered_data = filtered_data.apply(pd.to_numeric, errors='coerce')将筛选后的数据中的字符串数据转换为浮点数,便于计算和分析。
-
计算“流动资产占比”:
filtered_data.loc['流动资产占比'] = filtered_data.loc['流动资产合计(万元)'] / filtered_data.loc['资产总计(万元)']计算‘流动资产占比’的比率,即流动资产合计占总资产的比例。这个数据对财务分析至关重要,通常用来衡量公司的流动性。
3. 数据可视化部分:
-
导入折线图模块:
from pyecharts.charts import Line使用
pyecharts库中的折线图(Line)类进行数据的可视化。 -
设置全局配置:
line_chart.set_global_opts( title_opts=opts.TitleOpts(title="财务指标分析", pos_left="center"), legend_opts=opts.LegendOpts(pos_top="5%"), xaxis_opts=opts.AxisOpts(name="年份"), yaxis_opts=opts.AxisOpts(name="比率"), toolbox_opts=opts.ToolboxOpts() )设置折线图的标题、图例位置、坐标轴名称和工具箱选项。工具箱通常包含诸如下载图表、缩放等交互功能。
-
展示图表:
line_chart.render_notebook() line_chart.render("financial_analysis.html")
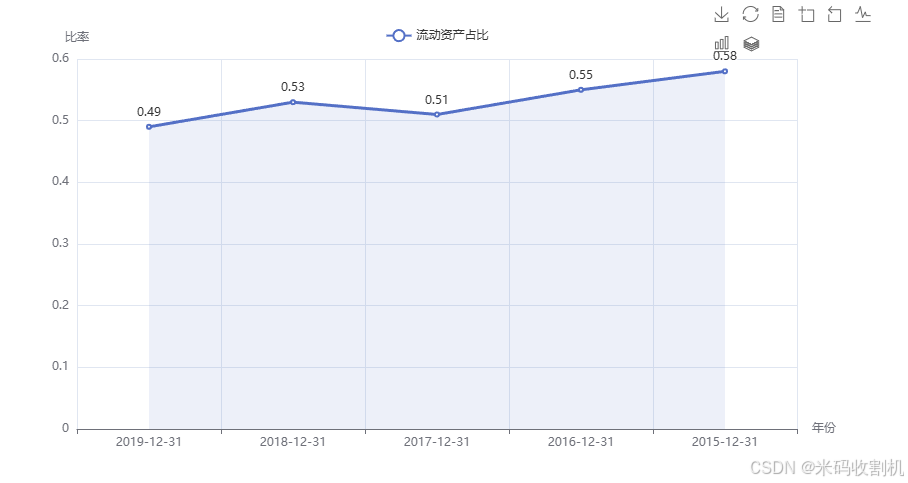
在Jupyter Notebook中显示图表,并将图表保存为HTML文件以供外部查看。
👇👇👇👇👇👇👇👇👇👇👇
👉 源码【传送门】 👈
👆👆👆👆👆👆👆👆👆👆👆


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)