Python数据分析基本练习一:数据预处理 + 数据可视化分析
仅供个人练习。
·
超市销售数据集提供了超市交易的全面概述,跟踪产品类别、单价、销售数量等详细信息。它还包括客户人口统计数据,例如性别和会员类型。此数据集非常适合分析销售趋势、客户行为和收入绩效,提供洞察以优化促销和产品策略。
销售数据集关键字段:
-
发票 ID:每笔交易的唯一标识符。
-
Branch:特定的超市分店(例如 A、B、C)。
-
City(城市):分行所在的城市。
-
客户类型:指示客户是“会员”还是“普通”。
-
性别:用于人口统计分析的客户性别。
-
Product Line: 商品分类(例如,杂货、服装)。
-
单价: 每件商品的价格。
-
数量:在交易中购买的商品。
-
税额 (5%): 税额(税前总额的 5%)。
注:数据来源于国外数据库。
一、数据预处理
所有代码的输出就不写print语句了,因为我是用jupyter lab运行的。
import pandas as pd
# 导入数据
data0 = pd.read_csv(r"C:\Users\31049\Desktop\archive\supermarket_sales new.csv")
# 修改成中文列名(个人习惯hhh)
data0.columns = ['性别', 'Invoice ID', '分店', '城市', '顾客类型',
'商品分类', '单价', '销量', '税额 5%']
# 输出前5行数据,看看数据大概是怎么样的
data0.head(5)
# 删除重复数据,并输出相关参数信息
data0 = data0.drop_duplicates()
data0.info()
# 总共1000条数据,共9列特征,各列都没有缺失值,还可以查看各列的数据类型
# 计算并添加"税前总额"列
data0['税前总额'] = data0["单价"] * data0["销量"]
# 计算并添加"税后总额"列
data0["税后总额"] = data0["单价"] * data0["销量"] + data0["税额 5%"]
data0.head(5)
# 查看数值型特征的基本统计信息
data0.describe()
# 可以看到每个特征的均值、标准差、各分位数、最大值和最小值。
# 1、根据均值和分位数,我们可以知道每个特征的大致分布状况。比如最后一列,超过 %50 的含税总额低于均值。
# 2、 根据标准差,可以知道每个特征的稳定性,还可以推测有没有异常值。
# 比如税额这一列,标准差较大,说明可能存在大额交易(或者说是异常值)。
# 3、根据最大值和最小值,我们可以发现一些差别和特殊情况。
# 比如,单价:单价的范围从10.08元到99.96元,跨度较大,说明商品种类的单价差异较大。
# 比如,销量:销量的范围从1件到10件,这表明大多数的购买行为是小批量购买。
# 比如,税后总额:最大值为1346.36元,说明有一些大宗商品的购买会使得总额远高于其他交易。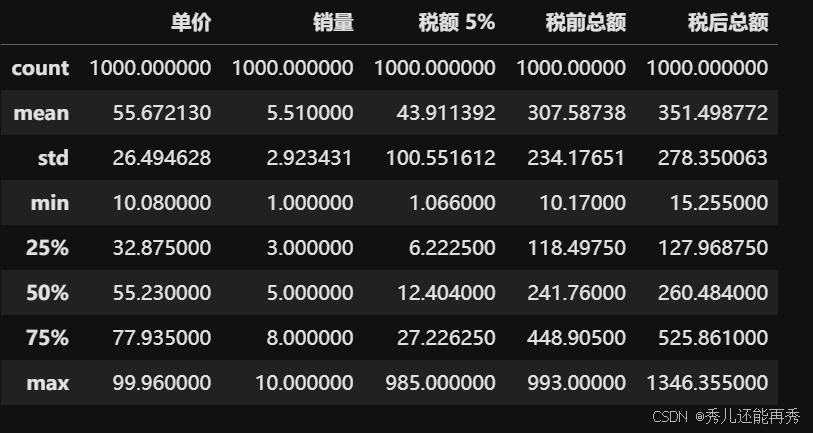
二、可视化分析
# 导入可视化用到的库
import seaborn as sns
import matplotlib.pyplot as plt
# 设置字体, 防止图表中文标题乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 用于显示负号
plt.rcParams['axes.unicode_minus'] = False (一)销售趋势分析
1、按分店分析
# 分店总收入(分税前和税后)
branch_sum1 = data0.groupby("分店").agg({"税前总额":"sum", "税后总额": "sum"}).reset_index()
branch_sum1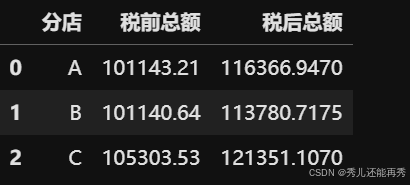
# 将数据从宽格式转换为长格式(即同一张图绘制两种柱状图的格式)
branch_sum1 = pd.melt(branch_sum1, id_vars=["分店"], value_vars=['税前总额', '税后总额'], var_name='总额类型', value_name='总额') # id_vars: identifier variables
branch_sum1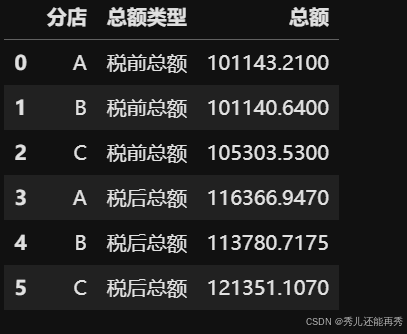
# 绘制柱状图
plt.figure(figsize=(10, 6))
ax = sns.barplot(x="分店", y='总额', hue="总额类型",data=branch_sum1)
# 给柱状图添加数值标签
for p in ax.patches:
ax.annotate(f'{p.get_height():.0f}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
fontsize=12, color='red',
xytext=(0, 5), textcoords='offset points')
plt.title("不同分店的总额")
plt.show()
# 结论: 税前、税后总额各自在每个分店的差异并不是很大,不过都是C分店总额偏高一点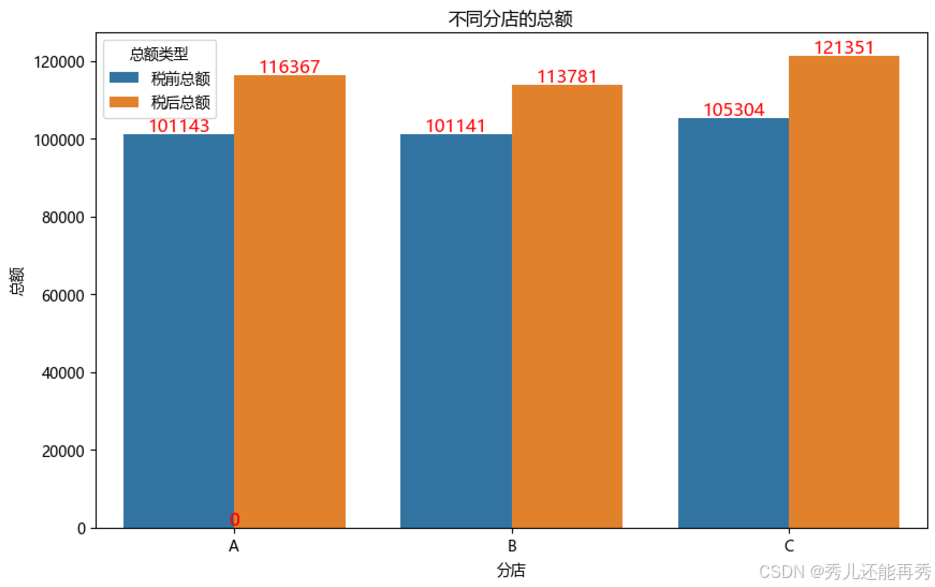
# 分店的销量
branch_sum2 = data0.groupby("分店")['销量'].sum().reset_index()
# 绘制柱状图
ax0=sns.barplot(x="分店", y="销量", data=branch_sum2)
# 给柱状图添加数值标签
for p in ax0.patches:
ax0.annotate(f'{p.get_height():.0f}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
fontsize=12, color='red',
xytext=(0, 5), textcoords='offset points')
plt.title("不同分店的销量")
plt.show
# 结论:每个分店的销量基本一致,没有显著差异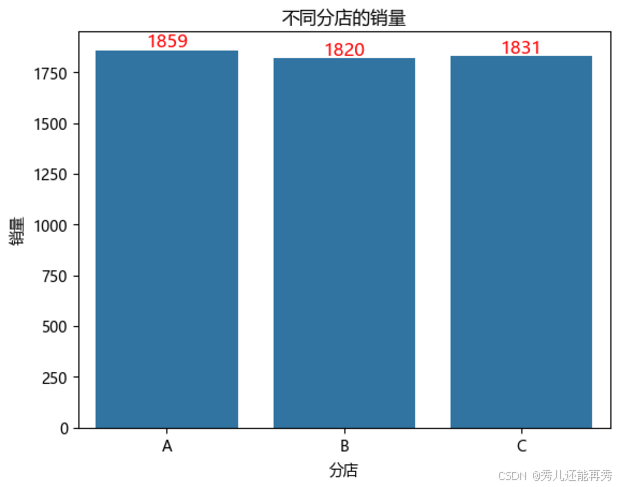
2、按城市分析
city_sum1 = data0.groupby("城市").agg({"税前总额":"sum", "税后总额": "sum"}).reset_index()
# 将数据从宽格式转换为长格式(即同一张图绘制两种柱状图的格式)
city_sum1 = pd.melt(city_sum1, id_vars=["城市"], value_vars=['税前总额', '税后总额'], var_name='总额类型', value_name='总额')
# 绘制柱状图
plt.figure(figsize=(10, 6))
ax = sns.barplot(x="城市", y='总额', hue="总额类型",data=city_sum1)
# 给柱状图添加数值标签
for p in ax.patches:
ax.annotate(f'{p.get_height():.0f}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
fontsize=12, color='red',
xytext=(0, 5), textcoords='offset points')
plt.title("不同城市的总额")
plt.show()
# 结论:不同城市之间的总收入(税前或税后)差异不是很大,其中 Naypyitaw 这个城市总收入最高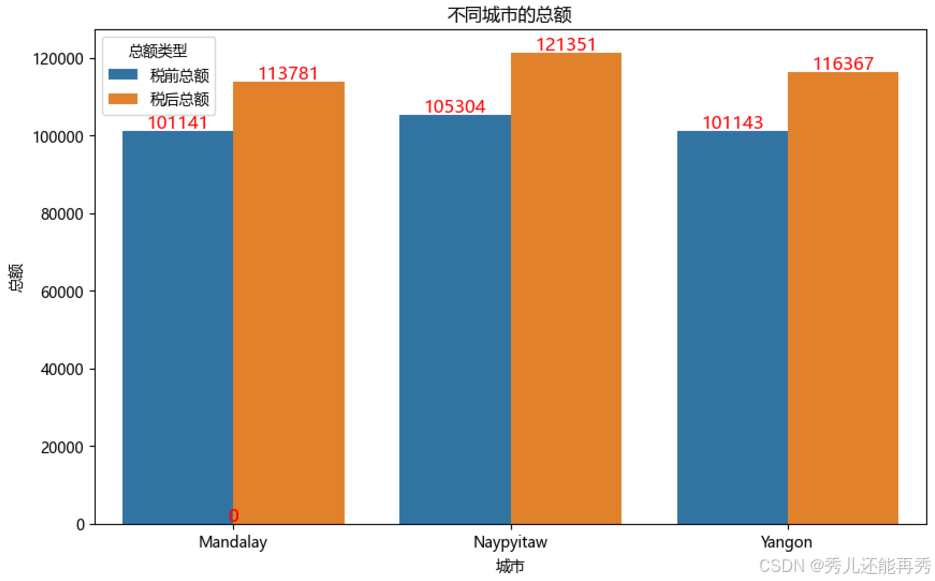
# 不同城市的销量
city_sum2 = data0.groupby("城市")['销量'].sum().reset_index()
# 绘制柱状图
plt.figure(figsize=(10, 6))
ax = sns.barplot(x="城市", y='销量',data=city_sum2)
# 给柱状图添加数值标签
for p in ax.patches:
ax.annotate(f'{p.get_height():.0f}',
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
fontsize=12, color='red',
xytext=(0, 5), textcoords='offset points')
plt.title("不同城市的销量")
plt.show()
# 结论:这三个城市的销量基本一致,没有显著差异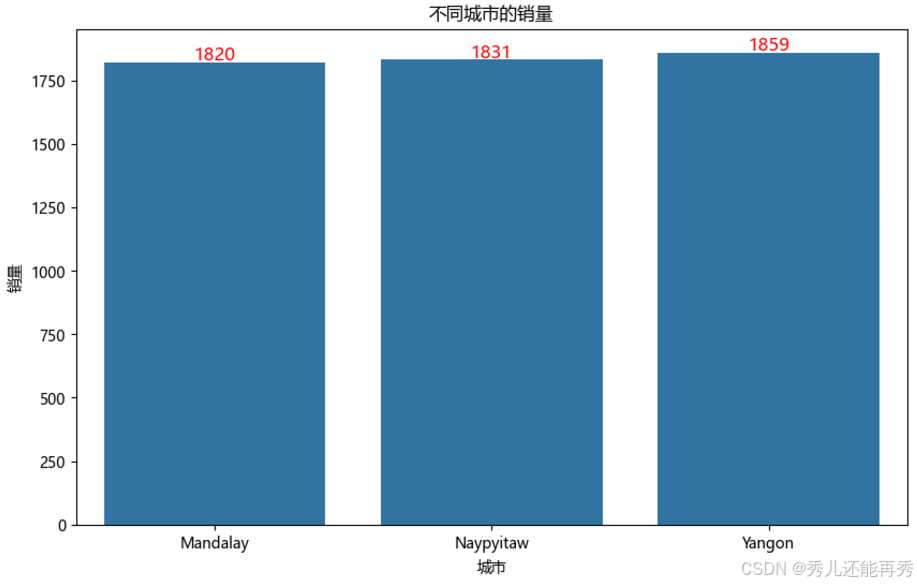
3、按商品分类分析
# 按商品分类汇总
product_line_sum = data0.groupby('商品分类').agg({'税后总额': 'sum', '销量': 'sum'}).reset_index()
# 商品分类——总收入对比柱状图
sns.barplot(y='商品分类', x='税后总额', data=product_line_sum)
plt.title('商品种类——总收入图例')
plt.xlabel('总收入(税后)')
plt.ylabel('商品分类')
plt.show()
# 商品分类——销量对比柱状图
sns.barplot(y='商品分类', x='销量', data=product_line_sum)
plt.title('商品种类——销量图例')
plt.xlabel('总销量')
plt.ylabel('商品分类')
plt.show()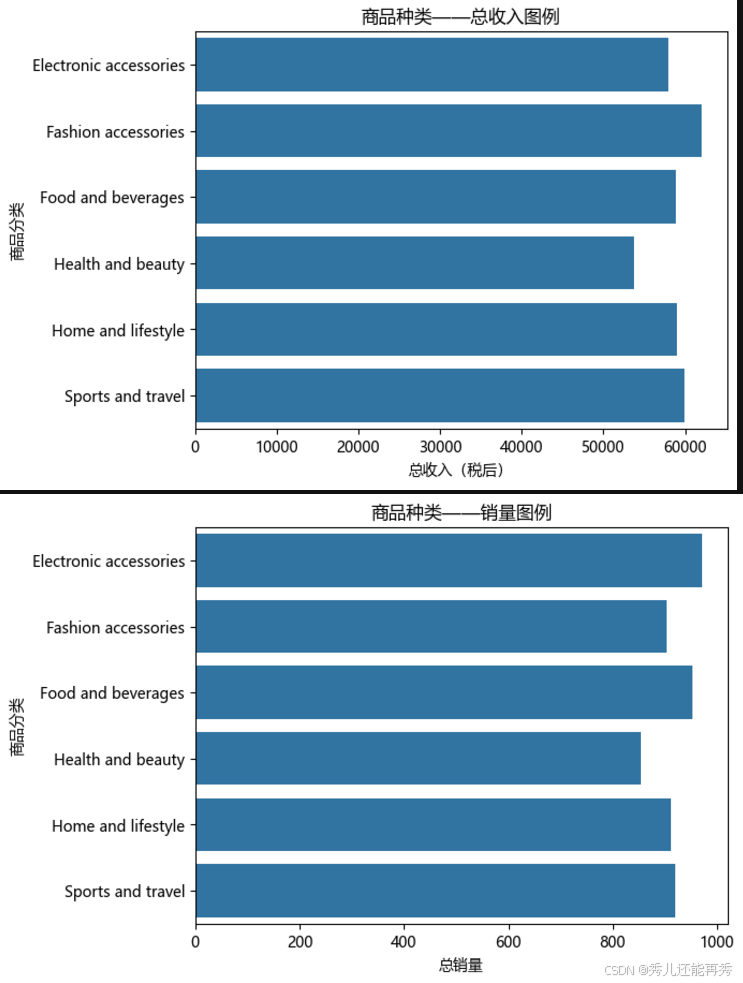
(二)客户行为分析
1、按性别分析
# 性别消费行为
gender_sum = data0.groupby('性别').agg({'税后总额': 'mean', '销量': 'sum'}).reset_index()
# 绘制性别平均消费金额对比
sns.barplot(x='性别', y='销量', data=gender_sum)
plt.title('性别——平均消费图')
plt.ylabel('平均消费')
plt.xlabel('消费')
plt.show()
# 结论:女性平均消费水平更高于男性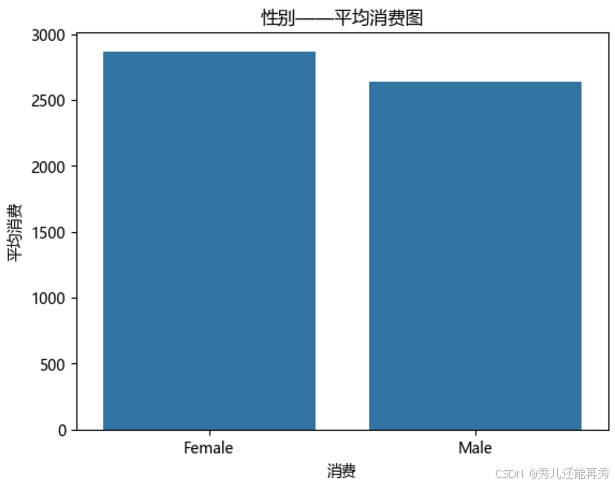
2、按顾客类型分析
....
当然了,还可以从其他很多种角度分析这个数据集,还可以结合不同的图来分析。这里我只简单的练习一些数据处理和简单可视化的相关 python 语句,扎实一下基本功。
# 文章如有错误,欢迎大噶不吝赐教!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)