残差网络ResNet50学习与训练多分类任务-365每周深度学习J1
则在20后的梯度几乎都会小于0.1,最终当层数很大时就几乎等于零。而残杀网络则解决了网络不能深下去的问题。因为它在每一层计算梯度的都开了一个洞,它既可以通过这层,也可以不用这层。所以当这层对梯度消失影响很大时,就可以不用。残差网络的作用为解决梯度消失问题。如何通过激活函数后的梯度始终小于1,不妨设上限为0.9,则经过N层后的梯度会小于。点击头像并查看免费下载。
·
目录
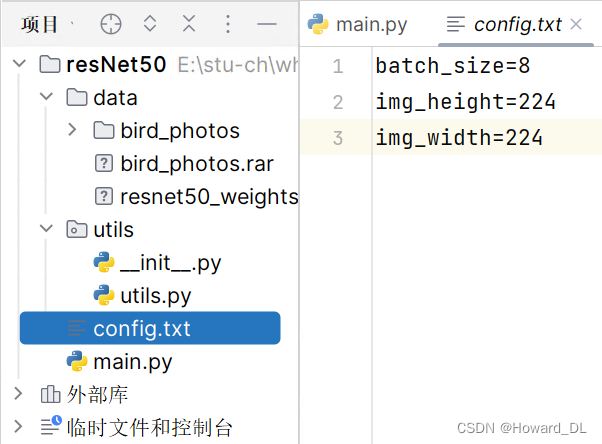
数据集下载
在我上传的资源中。点击头像并查看免费下载
resnet网络讲解
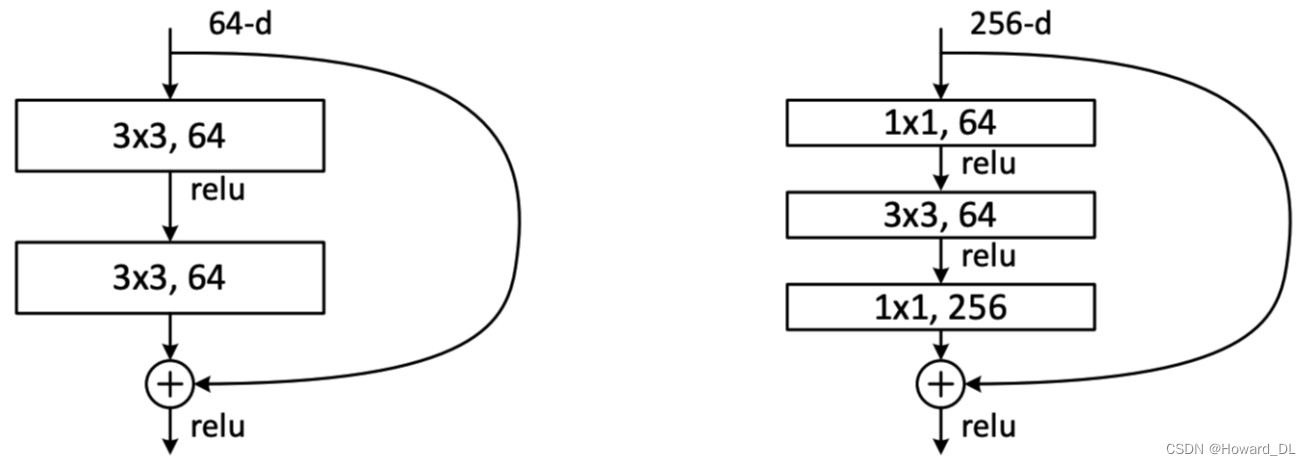
残差网络的作用为解决梯度消失问题。如何通过激活函数后的梯度始终小于1,不妨设上限为0.9,则经过N层后的梯度会小于,则在20后的梯度几乎都会小于0.1,最终当层数很大时就几乎等于零。而残杀网络则解决了网络不能深下去的问题。因为它在每一层计算梯度的都开了一个洞,它既可以通过这层,也可以不用这层。所以当这层对梯度消失影响很大时,就可以不用。
应用resnet50解决多分类任务思路
导包
处理数据集
查看数据集
搭建模型
训练
测试
导包
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
import os,PIL,pathlib
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
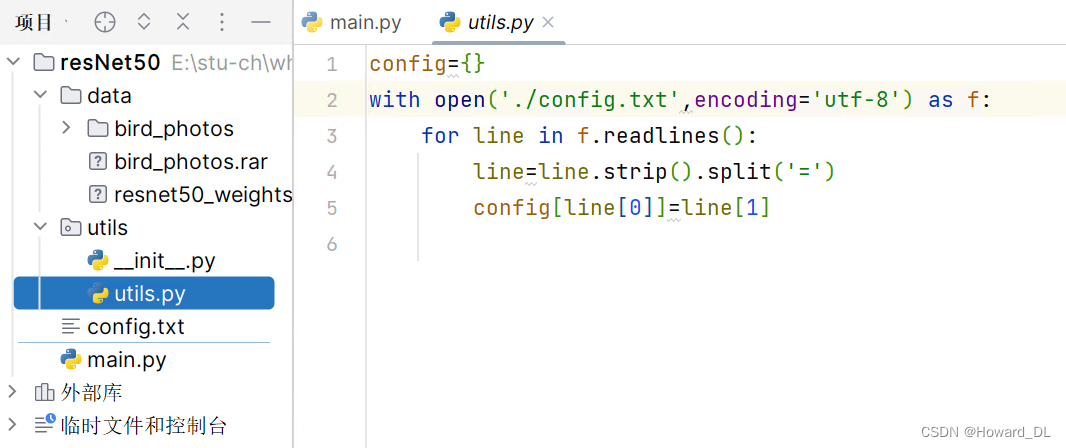
from utils.utils import *处理数据集
data_dir=r'E:\stu-ch\whale\tensorflow\resNet50\data\bird_photos'
data_dir=pathlib.Path(data_dir)
#%%
image_count=len(list(data_dir.glob('*/*')))
train_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='training',
seed=123,
image_size=(int(config['img_height']),int(config['img_width'])),
batch_size=int(config['batch_size'])
)
val_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset='validation',
seed=123,
image_size=(int(config['img_height']), int(config['img_width'])),
batch_size=int(config['batch_size'])
)
查看数据集
#%%
class_names=train_ds.class_names
print(class_names)
#%%
plt.figure(figsize=(10,5))
for images,labels in train_ds.take(1):
for i in range(8):
ax=plt.subplot(2,4,i+1)
plt.imshow(images[i].numpy().astype('uint8'))
plt.title(class_names[labels[i]])
plt.axis('off')
plt.show()
#%%
for image_batch,labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
#%%
train_ds=train_ds.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
val_ds=val_ds.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
搭建模型
#%%
from tensorflow.keras import layers
from tensorflow.keras.layers import Input,Activation,BatchNormalization,Flatten
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D,ZeroPadding2D,AveragePooling2D
from tensorflow.keras.models import Model
def identity_block(input_tensor,kernel_size,filters,stage,block):
filters1,filters2,filters3=filters
name_base=str(stage)+block+'_identity_block_'
x=Conv2D(filters1,(1,1),name=name_base+'conv1')(input_tensor)
x=BatchNormalization(name=name_base+'bn1')(x)
x=Activation('relu',name=name_base+'relu1')(x)
x=Conv2D(filters2,kernel_size,padding='same',name=name_base+'conv2')(x)
x=BatchNormalization(name=name_base+'bn2')(x)
x=Activation('relu',name=name_base+'relu2')(x)
x=Conv2D(filters3,(1,1),name=name_base+'conv3')(x)
x=BatchNormalization(name=name_base+'bn3')(x)
x=layers.add([x,input_tensor],name=name_base+'add')
x=Activation('relu',name=name_base+'relu4')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block,strides=(2,2)):
filters1, filters2, filters3 = filters
res_name_base=str(stage)+block+"_conv_block_res_"
name_base = str(stage) + block + '_conv_block_'
x = Conv2D(filters1, (1, 1), strides=strides,name=name_base + 'conv1')(input_tensor)
x = BatchNormalization(name=name_base + 'bn1')(x)
x = Activation('relu', name=name_base + 'relu1')(x)
x = Conv2D(filters2, kernel_size,padding='same' ,name=name_base + 'conv2')(x)
x = BatchNormalization(name=name_base + 'bn2')(x)
x = Activation('relu', name=name_base + 'relu2')(x)
x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)
x = BatchNormalization(name=name_base + 'bn3')(x)
x2 = Conv2D(filters3, (1, 1), strides=strides,name=name_base + 'conv')(input_tensor)
x2 = BatchNormalization(name=res_name_base + 'bn')(x2)
x = layers.add([x, x2], name=name_base + 'add')
x = Activation('relu', name=name_base + 'relu4')(x)
return x
def resnet50(input_shape=[224,224,3],classes=1000):
img_input=Input(shape=input_shape)
x=ZeroPadding2D((3,3))(img_input)
x=Conv2D(64,(7,7),strides=(2,2),name='conv1')(x)
x=BatchNormalization(name='bn_conv1')(x)
x=Activation('relu')(x)
x=MaxPooling2D((3,3),strides=(2,2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')
x = AveragePooling2D((7, 7), name='avg_pool')(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax', name='fc1000')(x)
model = Model(img_input, x, name='resnet50')
# 加载预训练模型
model.load_weights(r"data\resnet50_weights_tf_dim_ordering_tf_kernels.h5")
return model
model = resnet50()
model.summary()训练
opt=tf.keras.optimizers.Adam(learning_rate=1e-7)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#%%
epochs=20
history=model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
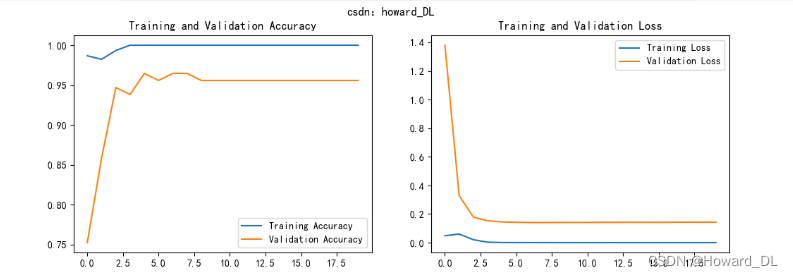
)展示训练结果
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.suptitle("csdn:howard_DL")
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
结果

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)