基于hadoop的网站流量日志数据分析系统
本文介绍了基于Hadoop的网站流量日志数据分析系统搭建过程。首先详细说明了Hadoop集群的安装配置步骤,包括环境变量设置、核心配置文件修改以及集群初始化启动。接着使用500万条搜狗搜索日志数据,通过MapReduce编程实现了用户搜索关键词Top10统计,包含Mapper过滤数据、Reducer排序统计以及Driver驱动的完整代码实现。最后将分析结果保存至MySQL数据库,为后续可视化展示提
基于hadoop的网站流量日志数据分析系统
引言
本文介绍了基于Hadoop的网站流量日志数据分析系统搭建过程。首先详细说明了Hadoop集群的安装配置步骤,包括环境变量设置、核心配置文件修改以及集群初始化启动。接着使用500万条搜狗搜索日志数据,通过MapReduce编程实现了用户搜索关键词Top10统计,包含Mapper过滤数据、Reducer排序统计以及Driver驱动的完整代码实现。最后将分析结果保存至MySQL数据库,为后续可视化展示提供数据支持。整个系统展示了Hadoop在大规模日志数据处理中的应用价值。
一 hadoop集群搭建
1、准备安装包,解压
2、配置环境变量并验证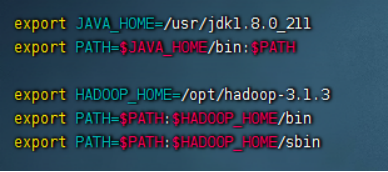
查看hadoop版本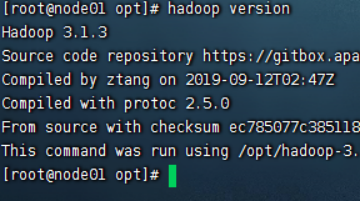
3、配置配置文件
1)配置core-site.xml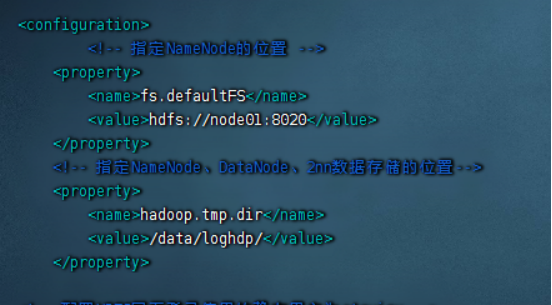
2)配置hdfs-site.xml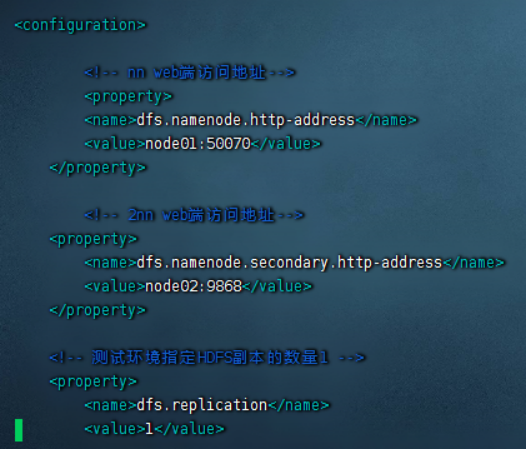
3)配置yarn-site.xml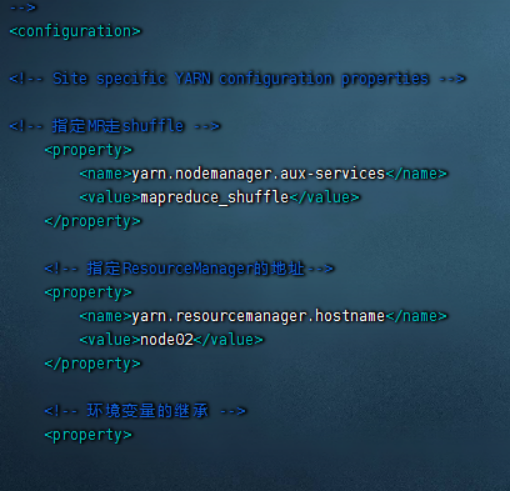
4)配置mapred-site.xml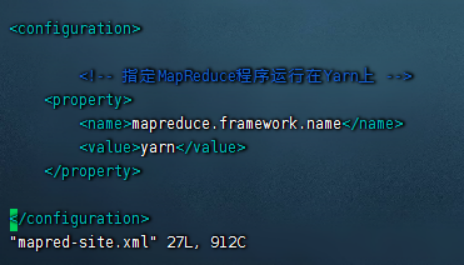
5)配置workers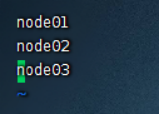
4、初始化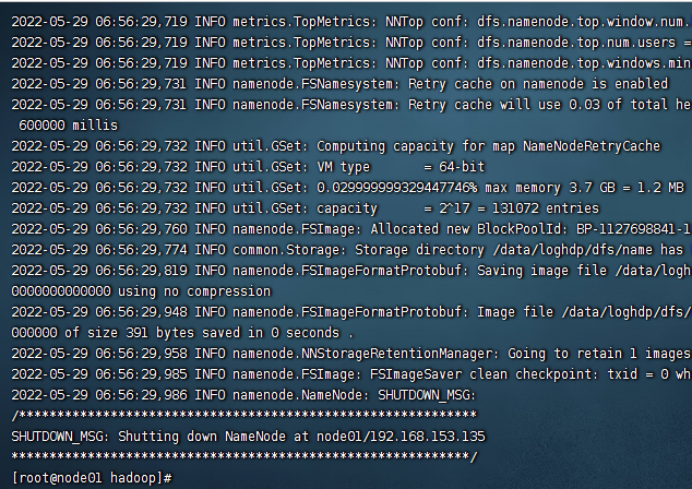
5、启动
1)启动hdfs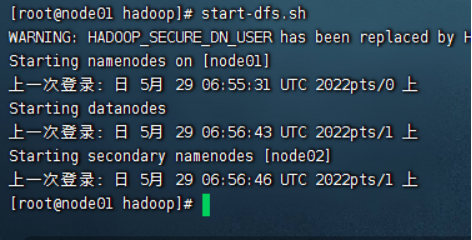
2)启动yarn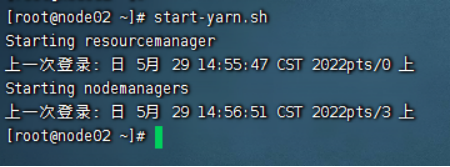
6、查看进程与页面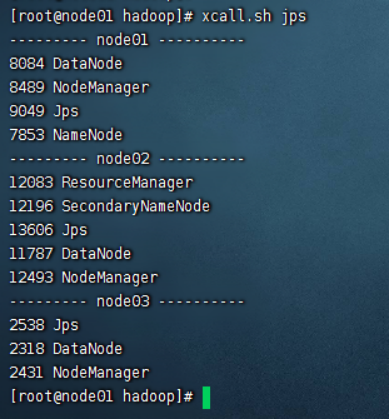
查看namenode页面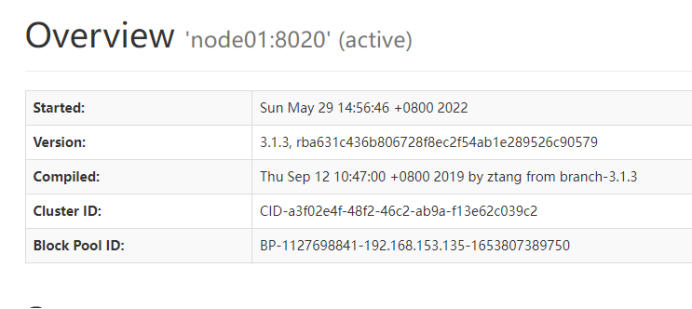
查看yarn页面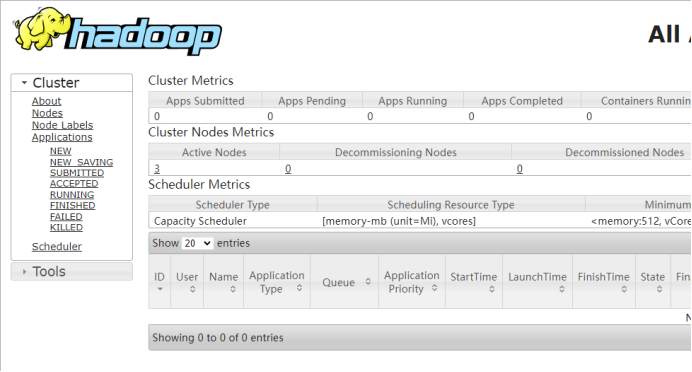
二 MapReduce数据分析
1、数据集描述
1)选择爬取的搜狗用户搜索日志,字段信息如下
| 字段 | 描述 |
|---|---|
| dt | 时间 |
| uid | 用户id |
| keyword | 搜索关键字 |
| recommendRk | 推荐排行 |
| rk | 点击顺序 |
| recommendRk | 推荐排行 |
| url | 链接 |
数据样式如下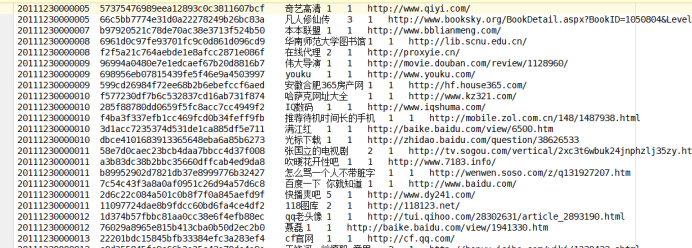
2)数据量
500万条
2、分析指标
统计用户搜索top10关键词,并取出分析结果可视化
3、MapReduce代码编写
1)Map
过滤掉不合法的数据,切割数据。将k设置为1,搜索关键字设置为v。发送到reduce中
public static class Map extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行 : 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/
String line = value.toString();
//获取搜索词信息
if (line.length() > 0 && line.split("\t").length == 6) {
//获取搜索词
String[] strings = line.split("\t");
String searchWord = strings[2];
k.set("1");
v.set(searchWord);
context.write(k, v);
}
}
}
2)Reduce
获取到map阶段传入的数据,定义一个全局map对关键字进行累加计算,将map转化为list倒序排序,获取前10的结果,写出。
public static class Reduce extends Reducer<Text, Text, Text, Text> {
Text v = new Text();
HashMap<String, Integer> hashMap = new HashMap<>();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//将数据写入map
for (Text value : values) {
String word = value.toString();
if (hashMap.containsKey(word))
hashMap.put(word, hashMap.get(word) + 1);
else
hashMap.put(word, 1);
}
//排序
ArrayList<java.util.Map.Entry<String, Integer>> entries = new ArrayList<>(hashMap.entrySet());
entries.sort(new Comparator<java.util.Map.Entry<String, Integer>>() {
@Override
public int compare(java.util.Map.Entry<String, Integer> o1, java.util.Map.Entry<String, Integer> o2) {
return o2.getValue() - o1.getValue();
}
});
//取前10
List<java.util.Map.Entry<String, Integer>> subList = entries.subList(0, 10);
//写出
for (java.util.Map.Entry<String, Integer> entry : subList) {
v.set(entry.getKey() + "\t" + entry.getValue());
context.write(null, v);
}
}
}
3)Driver
设置Map、Reduce的类型,并指定集群的地址
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
/**
* 打包到集群跑配置
*/
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node01:8020");
String[] otherArgs = new String[]{args[0], args[1]};
Job job = Job.getInstance(conf, "TestSogou");
job.setJarByClass(TestSogou.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
4、打包集群运行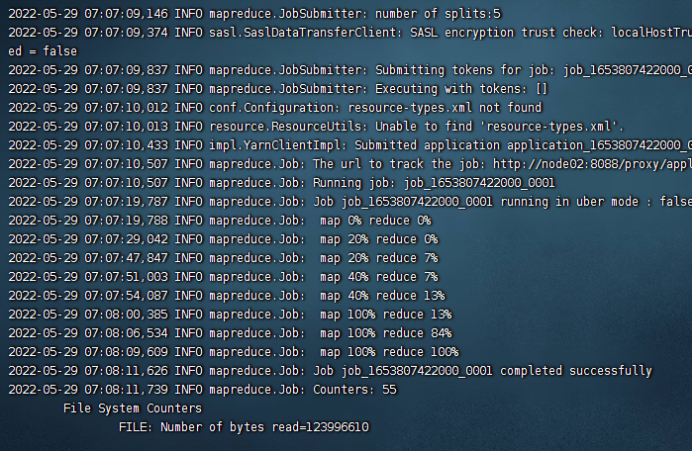
查看运行结果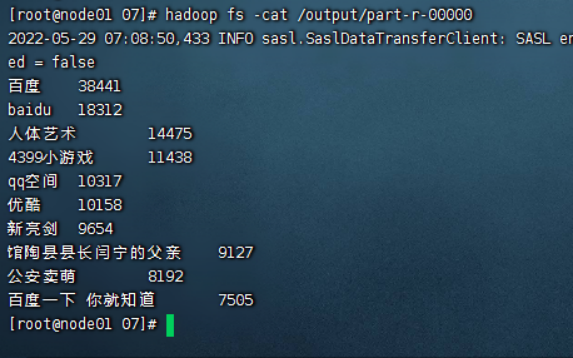
三 保存数据到mysql中
1、mysql建表
CREATE TABLE sogou_analysis(
word text,
cnt int
)
2、python代码
读取MapReduce统计的数据,并将其写入mysql中
(1) 获取mysql连接
import pymysql
conn = pymysql.connect(host ='hdp',port = 3306, user = 'root',passwd = '111111',db = 'test', charset='utf8')
(2) 插入数据到mysql
root = "output/part-r-00000"
with open(root, 'r', encoding='utf-8') as f:
while True:
line = f.readline()
if not line:
break
strings = line.split("\t")
cur = conn.cursor()
sql = 'insert into sogou_analysis VALUES (\''+strings[0]+'\','+strings[1]+')'
cur.execute(sql)
conn.commit()
print('sogou热搜数据插入成功!')
3、运行
查看mysql数据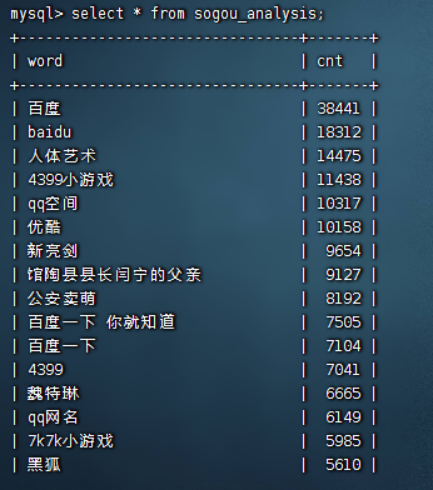
四 echarts网页设计
1、页面设计
使用echarts生成柱状图可视化图表
<script>
$.get('http://localhost:9081/getPart', function (res) {
var top20Chart = echarts.init(document.getElementById('map'));
top20Chart.setOption({
color: ['#3398DB'],
tooltip: {
trigger: 'axis',
axisPointer: { // 坐标轴指示器,坐标轴触发有效
type: 'shadow' // 默认为直线,可选为:'line' | 'shadow'
}
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
xAxis: [
{
type: 'category',
data: res.key,
axisTick: {
alignWithLabel: true
},
//x轴旋转
axisLabel: {
interval: 0, //隔几项显示一个标签
rotate: "45" //标签倾斜的角度,旋转的角度是-90到90度
}
}
],
yAxis: [
{
type: 'value'
}
],
series: [
{
name: '搜索数量',
type: 'bar',
barWidth: '60%',
data: res.val
}
]
});
});
</script>
五 服务端设计与效果展示
1、Controller
//搜狗日志热搜分析
@RequestMapping(value = "/getPart")
public Map getPart2(){
List<Map<String,Object>> list = moveService.getPart();
List key = new ArrayList();
List val = new ArrayList();
Map returnMap = new HashMap<String, List>();
for(Map<String,Object> m:list) {
key.add(m.get("name"));
val.add(m.get("value"));
}
returnMap.put("key", key);
returnMap.put("val", val);
return returnMap;
}
2、Service
//搜狗日志热搜分析
public List<Map<String, Object>> getPart() {
return telecomDao.getPart();
}
3、DAO
//搜狗日志热搜分析
@Select("SELECT word name, cnt value from sogou_analysis order by cnt desc limit 10")
public List<Map<String,Object>> getPart();
启动项目
浏览器输入localhost:9081/index.html查看结果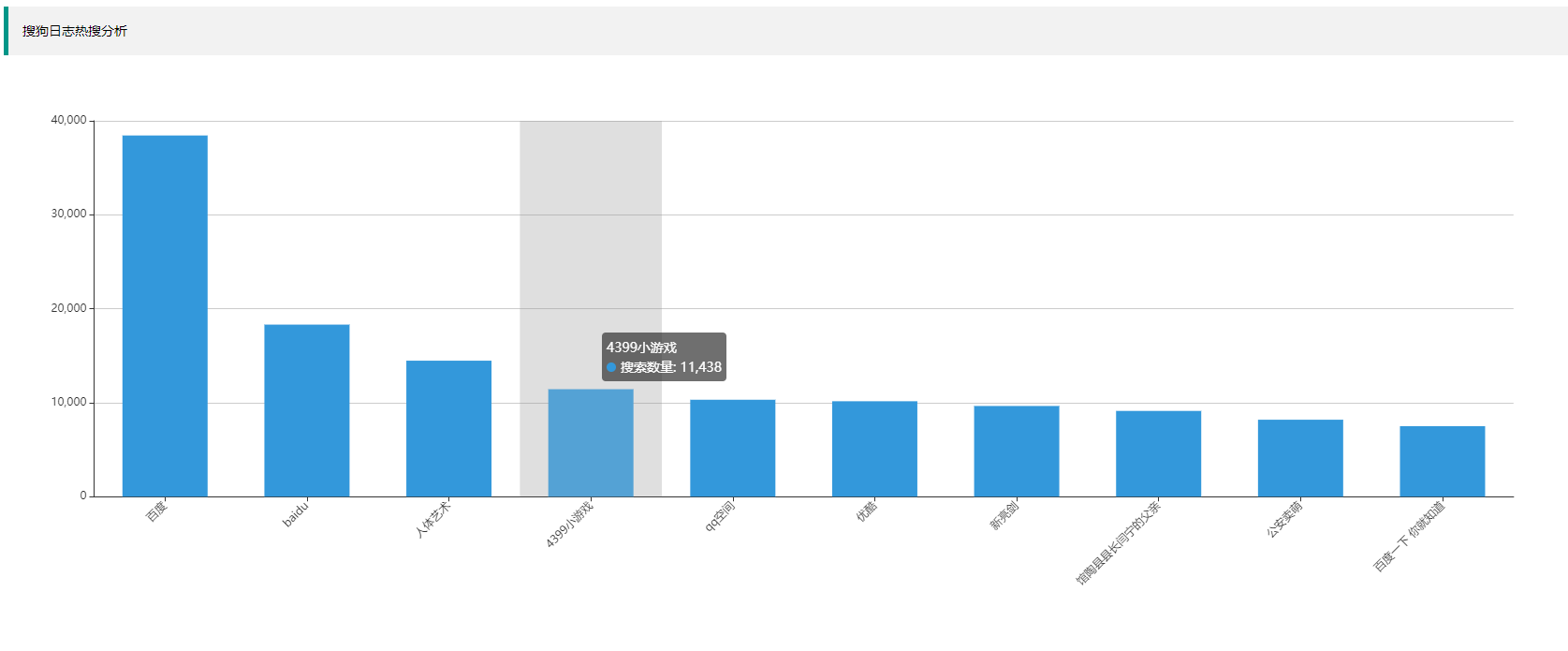
可见用户使用搜狗但对百度情有独钟,另外用户对于游戏、影视等泛娱乐化资源很感兴趣
其他
完整代码和数据等可留言或ping我:ari.chen.cn@gmail.com

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)