神经网络与深度学习总结(二)
目前主流的深度学习平台有很多,各有其特点和适用场景。: 支持多种语言和系统,生态完善,工业界应用广泛。: 在计算机视觉领域有较好的积累,速度快。: 以其动态图机制和易用性受到学术界的青睐,社区活跃。: 支持多种语言,分布式训练性能优秀。PaddlePaddle (百度): 国内用户友好,提供丰富的预训练模型。选择合适的平台需要考虑学习材料的丰富程度、CNN/RNN建模能力、易用性、运行速度以及多G
本周我们学习了卷积神经网络(CNN)的基础知识,以下是对本周课程的总结,希望能帮助大家回顾所学。
一、为什么要“深度”学习
1.1 全连接网络的问题
传统的全连接网络在处理例如图像这样高维输入时,会面临诸多挑战。最主要的问题是参数数量过多。例如,一个1000x1000像素的图像,如果隐含层有100万个节点,那么仅输入层到隐含层的连接权重数量级就达到了 1×10121 \times 10^{12}1×1012。如此庞大的参数量会导致以下问题:
- 计算缓慢:大量的乘法和加法运算使得网络训练和推理非常耗时。
- 难以收敛:参数过多,优化面复杂,容易陷入局部极小值。
- 容易过拟合:模型在训练数据上表现很好,但在未见过的数据上表现差,泛化能力弱。
为了解决计算缓慢的问题,一个直观的想法是减少权值连接,即采用局部连接网络,让每个节点只与上一层的少数神经元相连。而为了解决过拟合和收敛困难的问题,借鉴了人类视觉信息分层处理的思路,即每一层在上层提取特征的基础上进行再处理,得到更高级别的特征,这便是深度学习中“深度”的由来。
1.2 深度学习平台简介
目前主流的深度学习平台有很多,各有其特点和适用场景。PPT中列举了几个常用的框架,例如:
- TensorFlow (Google): 支持多种语言和系统,生态完善,工业界应用广泛。
- Caffe (UC Berkeley): 在计算机视觉领域有较好的积累,速度快。
- PyTorch (Facebook): 以其动态图机制和易用性受到学术界的青睐,社区活跃。
- MXNet (Amazon/DMLC): 支持多种语言,分布式训练性能优秀。
- PaddlePaddle (百度): 国内用户友好,提供丰富的预训练模型。
选择合适的平台需要考虑学习材料的丰富程度、CNN/RNN建模能力、易用性、运行速度以及多GPU支持等因素。
1.3 PyTorch简介与基本使用
PyTorch是一个基于Python的科学计算包,主要针对两类人群:
- 希望GPU加速的NumPy替代品。
- 一个提供极大灵活性和速度的深度学习研究平台。
PyTorch的核心概念包括:
- 张量 (Tensor): 类似于NumPy的ndarrays,但可以在GPU上使用以加速计算。张量是PyTorch中数据表示的基本单位,可以是一维(向量)、二维(矩阵)或更高维度的数组。
- 计算图 (Computational Graph): PyTorch使用动态计算图。这意味着图的构建是在运行时进行的,可以根据需要进行修改。计算图描述了张量之间的运算关系,是自动求导(Autograd)的基础。
PyTorch的基本使用流程通常包括:
- 使用
torch.Tensor表示数据。 - 使用
Dataset和DataLoader来高效地读取和预处理样本数据及标签。 - 使用
torch.autograd.Variable(在较新版本中,Tensor本身就支持自动求导) 来存储神经网络的权重等参数,并跟踪其梯度。 - 构建神经网络模型,通常通过继承
torch.nn.Module类来实现。 - 定义损失函数和优化器。
- 进行模型的训练和评估。
一个简单的PyTorch张量运算示例:
import torch
# 创建张量
x = torch.tensor([1.0, 2.0, 3.0])
y = torch.tensor([4.0, 5.0, 6.0])
# 张量加法
z = x + y
print(f"x: {x}")
print(f"y: {y}")
print(f"z (x+y): {z}")
# 检查PyTorch版本和CUDA是否可用
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA device count: {torch.cuda.device_count()}")
print(f"Current CUDA device: {torch.cuda.current_device()}")
print(f"Device name: {torch.cuda.get_device_name(torch.cuda.current_device())}")
# 将张量移动到GPU
x_cuda = x.cuda()
y_cuda = y.cuda()
z_cuda = x_cuda + y_cuda
print(f"z_cuda (on GPU): {z_cuda}")
二、卷积神经网络(CNN)基础
卷积神经网络是深度学习领域中非常重要的一类网络,尤其在图像处理、计算机视觉等领域取得了巨大成功。
2.1 深度学习介绍:进化史与典型任务
从早期的感知机到如今复杂的深层网络结构,深度学习在许多典型任务上都取得了突破性进展,例如图像分类、目标检测、语音识别、自然语言处理等。
2.2 基本概念
特征提取 (Feature Extraction)
CNN的核心思想是局部感受野 (local receptive fields)、权值共享 (weight sharing) 和 下采样 (subsampling/pooling)。其灵感来源于生物视觉系统。神经生理学研究(如1981年Hubel和Wiesel的诺贝尔奖工作)发现,高等动物的视觉皮层细胞对特定方向的边缘、条纹等局部特征敏感。CNN通过模拟这种机制,逐层提取图像的特征,从低级的边缘、角点到高级的纹理、物体部件,最终形成对整个图像的理解。
卷积 (Convolution) 是CNN中最核心的操作。它通过一个可学习的卷积核 (kernel/filter) 在输入图像(或特征图)上滑动,计算卷积核与对应局部区域的点积,从而得到新的特征图。这个过程可以看作是对输入图像进行不同方向的滤波。
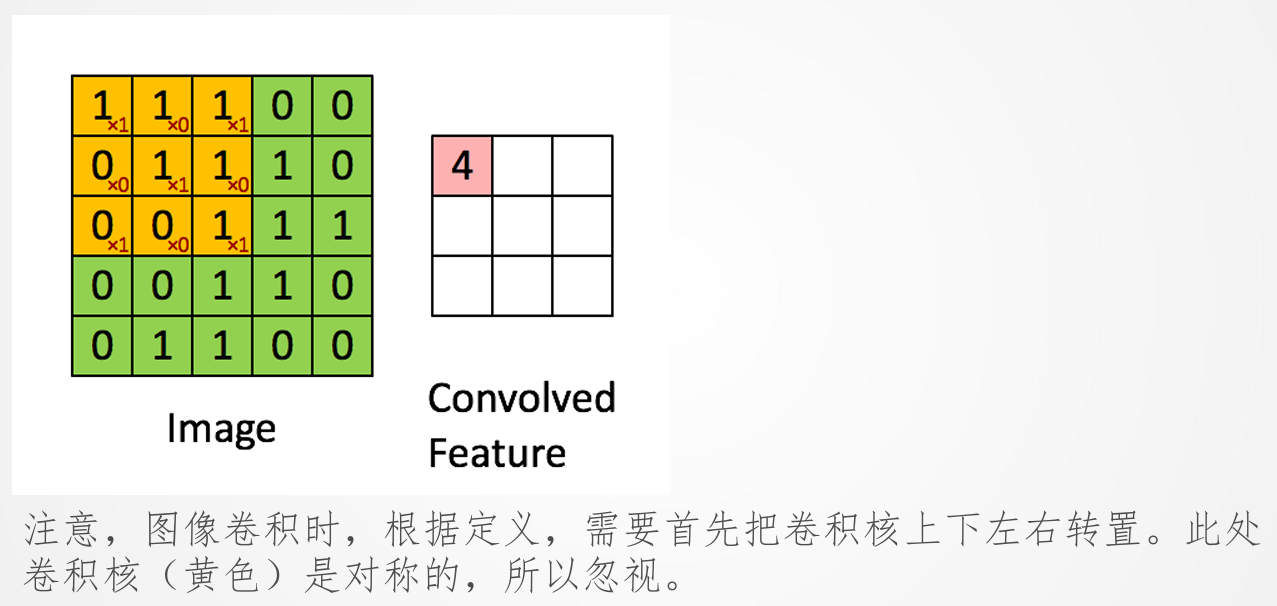
*图1: 卷积操作示意图 *
需要注意的是,在严格的数学定义中,图像卷积时需要先将卷积核进行翻转。但在深度学习实践中,通常实现的是互相关 (cross-correlation) 操作,因为卷积核是可学习的,翻转与否不影响最终学习到的特征表示能力。
填充 (Padding)
在进行卷积操作时,如果卷积核的尺寸大于1x1,输出特征图的尺寸会小于输入特征图。为了控制输出特征图的尺寸,或者为了让卷积核能够处理到图像边缘的像素,常常会在输入图像的边界进行填充 (Padding)。通常使用0进行填充 (zero-padding),也可以复制边界像素。在nn.Conv2d中,padding参数可以控制填充的大小。
步长 (Stride)
步长 (Stride) 定义了卷积核在输入图像上滑动的步幅。如果步长为1,则卷积核每次移动一个像素;如果步长为2,则每次移动两个像素。步长会影响输出特征图的尺寸,较大的步长会导致输出尺寸减小。在nn.Conv2d中,stride参数可以控制步长。
多通道卷积 (Multi-channel Convolution)
当输入数据具有多个通道时(例如RGB彩色图像有3个通道),卷积核也需要有相应的通道数。nn.Conv2d的in_channels参数指定了输入通道数,out_channels指定了输出特征图的数量(即卷积核的数量)。
池化 (Pooling / Subsampling)
池化 (Pooling) 或称为下采样 (Subsampling) 是CNN中常用的操作,通常在卷积层之后。其主要目的是:
- 减少特征图的维度 (降维),从而减少后续层的参数数量和计算量,防止过拟合。
- 赋予模型一定程度的平移不变性。即当输入图像发生微小的平移时,池化操作可以使得输出特征保持相对稳定。
常见的池化操作有最大池化 (Max Pooling) 和 平均池化 (Average Pooling)。最大池化是在池化窗口内取最大值作为输出,而平均池化是取平均值。
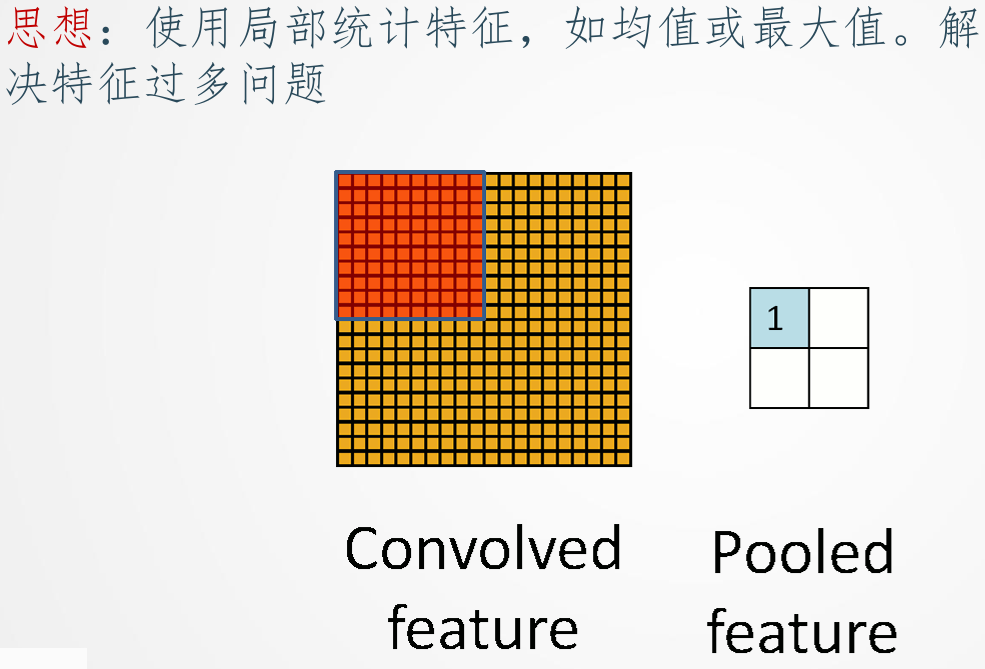
*图2: 池化操作示意图 *
卷积神经网络结构
一个典型的卷积神经网络通常由以下几种类型的层堆叠而成:
- 输入层 (Input Layer): 接收原始数据,如图像像素。
- 卷积层 (Convolutional Layer): 使用卷积核提取局部特征。
- 激活层 (Activation Layer): 对卷积层的输出进行非线性变换,引入非线性因素,常用的激活函数有ReLU、Sigmoid、Tanh等。PyTorch中如
nn.ReLU()。 - 池化层 (Pooling Layer): 对特征图进行下采样,减少维度。
- 全连接层 (Fully Connected Layer): 在网络的最后阶段,将前面提取到的特征进行整合,用于分类或回归任务。PyTorch中如
nn.Linear()。 - 输出层 (Output Layer): 输出最终结果,如分类概率。
通常,卷积层和池化层会交替出现多次,形成一个“特征提取器”。网络的深处提取的是更抽象、更高级的特征。
下面是一个使用PyTorch构建简单CNN模型的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
# 第一个卷积层:输入1通道(如灰度图),输出10个特征图,卷积核5x5
self.conv1 = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5)
# 第一个池化层:最大池化,窗口2x2,步长2
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 第二个卷积层:输入10通道,输出20个特征图,卷积核5x5
self.conv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5)
# 第二个池化层
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层,输入维度需要根据卷积和池化后的特征图大小计算
# 假设输入是28x28的图像:
# After conv1 (kernel 5, stride 1, no padding): (28-5+1) = 24x24. Output: 10x24x24
# After pool1 (kernel 2, stride 2): 24/2 = 12x12. Output: 10x12x12
# After conv2 (kernel 5, stride 1, no padding): (12-5+1) = 8x8. Output: 20x8x8
# After pool2 (kernel 2, stride 2): 8/2 = 4x4. Output: 20x4x4
# Flattened size: 20 * 4 * 4 = 320
self.fc1 = nn.Linear(20 * 4 * 4, 50) # 320是展平后的维度
self.fc2 = nn.Linear(50, num_classes)
def forward(self, x):
# x: input tensor (batch_size, 1, 28, 28) for MNIST-like data
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
# 展平操作,将多维特征图变为一维向量
x = x.view(-1, 20 * 4 * 4) # -1表示batch_size自动推断
x = F.relu(self.fc1(x))
x = self.fc2(x) # 输出层通常不加激活,Softmax在损失函数中处理
return x
# 创建模型实例
model = SimpleCNN(num_classes=10)
print(model)
# 测试一个随机输入
# (batch_size, channels, height, width)
dummy_input = torch.randn(1, 1, 28, 28)
output = model(dummy_input)
print(f"Dummy input shape: {dummy_input.shape}")
print(f"Output shape: {output.shape}") # torch.Size([1, 10])
2.3 学习算法 (误差反向传播)
CNN的训练同样依赖于误差反向传播 (Backpropagation, BP) 算法来调整网络中的权重和偏置。其核心思想是将输出层的误差逐层向前传播,计算每一层参数对总误差的贡献(即梯度),然后利用梯度下降等优化算法更新参数。PyTorch的autograd模块会自动处理反向传播和梯度计算。
前向传播
对于一个卷积层,其前向传播可以表示为:
zl(x,y)=∑u=0p−1∑v=0q−1al−1(x+u,y+v)wl,k(u,v)+blz^l(x, y) = \sum_{u=0}^{p-1} \sum_{v=0}^{q-1} a^{l-1}(x+u, y+v) w^{l,k}(u, v) + b^lzl(x,y)=∑u=0p−1∑v=0q−1al−1(x+u,y+v)wl,k(u,v)+bl
al(x,y)=f(zl(x,y))a^l(x, y) = f(z^l(x, y))al(x,y)=f(zl(x,y))
其中,al−1a^{l-1}al−1 是第 l−1l-1l−1 层的激活输出,wl,kw^{l,k}wl,k 是第 lll 层第 kkk 个卷积核的权重,blb^lbl 是偏置项,fff 是激活函数。(x,y)(x,y)(x,y) 表示输出特征图上的位置,(u,v)(u,v)(u,v) 表示卷积核内的相对位置,p,qp,qp,q 是卷积核的尺寸。
如果第 lll 层是卷积+池化层,则:
al(x,y)=downsample(∑u=0p−1∑v=0q−1al−1(x+u,y+v)wl,k(u,v)+bl)a^l(x, y) = \text{downsample} \left( \sum_{u=0}^{p-1} \sum_{v=0}^{q-1} a^{l-1}(x+u, y+v) w^{l,k}(u, v) + b^l \right)al(x,y)=downsample(∑u=0p−1∑v=0q−1al−1(x+u,y+v)wl,k(u,v)+bl)
误差反向传播
BP算法的目标是计算损失函数 EEE 对网络中每个参数(权重 www 和偏置 bbb)的梯度 ∂E∂w\frac{\partial E}{\partial w}∂w∂E 和 ∂E∂b\frac{\partial E}{\partial b}∂b∂E。
对于输出层,误差项 δL\delta^LδL (通常定义为 ∂E∂zL\frac{\partial E}{\partial z^L}∂zL∂E ) 可以直接计算。例如,对于均方误差和Sigmoid激活函数,有 δiL=(aiL−yi)aiL(1−aiL)\delta_i^L = (a_i^L - y_i) a_i^L (1 - a_i^L)δiL=(aiL−yi)aiL(1−aiL),其中 yiy_iyi 是目标输出。
对于隐含层,误差项 δl\delta^lδl 需要从后一层 δl+1\delta^{l+1}δl+1 反向传播得到。这个过程涉及到链式法则。
在CNN中,由于存在卷积和池化操作,BP算法的具体形式会更复杂一些:
- 池化层的反向传播:对于最大池化,误差只通过值最大的那个神经元反向传播;对于平均池化,误差会平均分配给池化窗口内的所有神经元。
- 卷积层的反向传播:误差项 δl\delta^lδl 从下一层 δl+1\delta^{l+1}δl+1 反向传播时,需要经过一个与前向传播卷积核“相关”的卷积操作(通常是原卷积核旋转180度)。权重的梯度计算则涉及到输入激活 al−1a^{l-1}al−1 与误差项 δl\delta^lδl 的卷积。
三、LeNet-5 网络
LeNet-5 是由 Yann LeCun 等人在1998年提出的早期卷积神经网络之一,主要用于手写数字识别,并取得了巨大成功,是CNN发展史上的一个里程碑。
3.1 网络介绍与结构
LeNet-5 的整体结构体现了CNN的典型设计:卷积层、池化层交替,最后连接全连接层进行分类。
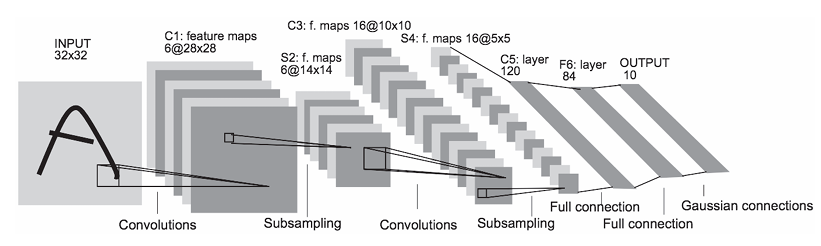
*图3: LeNet-5 网络结构 *
其基本流程可以概括为:
Input -> Conv1 -> Pool1 -> Conv2 -> Pool2 -> Conv3 (FC) -> FC -> Output
下面是使用PyTorch实现LeNet-5的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
# C1: 卷积层, 输入1通道, 输出6通道, 卷积核5x5. 输入32x32 -> 输出28x28
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
# S2: 池化层, 平均池化, 窗口2x2, 步长2. 输出14x14
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
# C3: 卷积层, 输入6通道, 输出16通道, 卷积核5x5. 输出10x10
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
# S4: 池化层, 平均池化, 窗口2x2, 步长2. 输出5x5
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
# C5: 全连接层 (在LeNet原文中是卷积层,但通常实现为全连接)
# 输入维度: 16通道 * 5 * 5 = 400
self.fc1 = nn.Linear(16 * 5 * 5, 120)
# F6: 全连接层
self.fc2 = nn.Linear(120, 84)
# Output: 全连接层
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
# x: (batch_size, 1, 32, 32) - 假设输入是32x32的灰度图
x = self.pool1(F.relu(self.conv1(x))) # 使用ReLU激活,原文用tanh/sigmoid
x = self.pool2(F.relu(self.conv2(x)))
# 展平特征图
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 创建模型
lenet_model = LeNet5(num_classes=10)
print(lenet_model)
# 测试一个随机输入 (假设输入是32x32,LeNet原文针对此尺寸)
# 如果是28x28的MNIST,通常会在输入前padding到32x32,或调整第一层卷积
dummy_input_32 = torch.randn(1, 1, 32, 32)
output_lenet = lenet_model(dummy_input_32)
print(f"LeNet Dummy input shape (32x32): {dummy_input_32.shape}")
print(f"LeNet Output shape: {output_lenet.shape}")
3.2 结构详解
- 输入层 (Input): 32x32像素的灰度图像。
- C1层 (卷积层): 6个5x5的卷积核,步长为1。输出6个28x28的特征图。参数数量:(5×5+1)×6=156(5 \times 5 + 1) \times 6 = 156(5×5+1)×6=156 个。连接数:156×28×28=122304156 \times 28 \times 28 = 122304156×28×28=122304。
- S2层 (池化层/下采样层): 2x2的平均池化,步长为2。将C1的6个28x28特征图下采样为6个14x14的特征图。每个池化单元有可学习的权重和偏置(这与现代CNN中池化层通常无参数不同)。
- C3层 (卷积层): 16个5x5的卷积核。C3层的输入特征图并非与S2层的所有特征图全连接,而是有选择地连接,以打破对称性并减少参数。输出16个10x10的特征图。
- S4层 (池化层/下采样层): 2x2的平均池化,步长为2。将C3的16个10x10特征图下采样为16个5x5的特征图。同样有可学习的参数。
- C5层 (卷积层,实际为全连接层): 120个1x1的卷积核,每个卷积核与S4层的全部16个5x5特征图进行卷积(等效于全连接)。输出120个1x1的特征图(即120个神经元)。参数数量:(5×5×16+1)×120=48120(5 \times 5 \times 16 + 1) \times 120 = 48120(5×5×16+1)×120=48120。
- F6层 (全连接层): 84个神经元,与C5层的120个神经元全连接。参数数量:(120+1)×84=10164(120 + 1) \times 84 = 10164(120+1)×84=10164。
- 输出层 (Output Layer): 最初设计是使用欧式径向基函数 (RBF) 单元,每个类别一个单元,计算输入向量和参数向量之间的欧式距离。现代通常使用Softmax进行多分类。
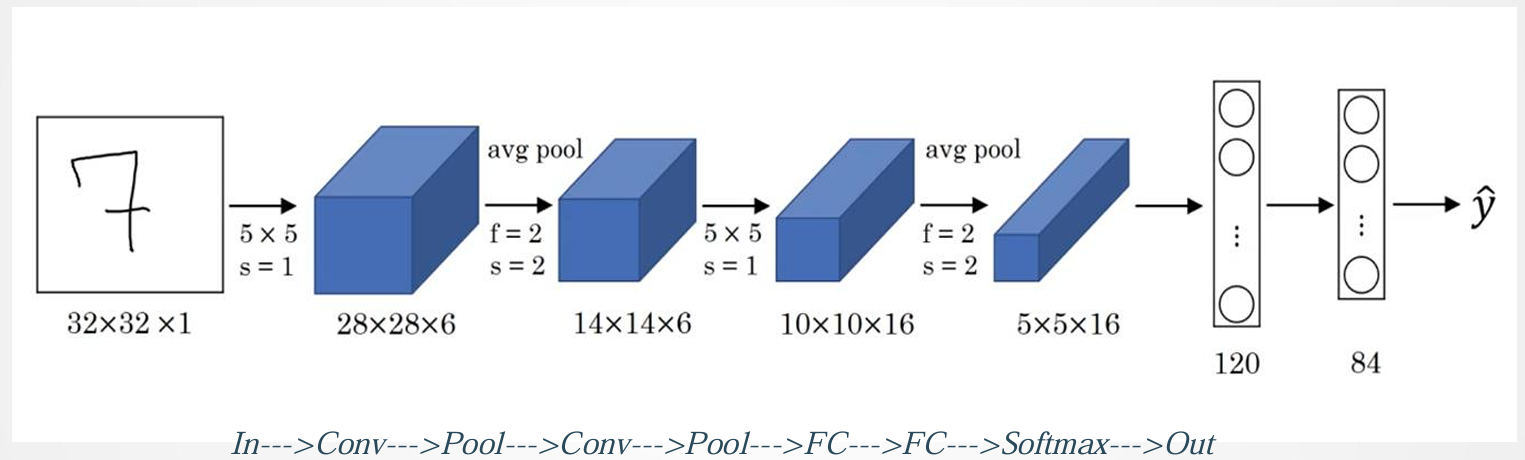
*图4: LeNet-5 网络结构图解 *
LeNet-5 与现代CNN的区别
- 填充 (Padding): LeNet-5在卷积时通常不进行填充,导致特征图尺寸逐渐减小。
- 池化方式: LeNet-5主要使用平均池化,而现代CNN更常用最大池化。
- 激活函数: LeNet-5使用Sigmoid或tanh作为激活函数,现代CNN广泛使用ReLU及其变种,因为它们能更好地解决梯度消失问题并加速训练。
- 网络深度与参数量: LeNet-5相对较浅,参数数量较小(约6万)。现代CNN通常更深,参数量也更大。
一个普遍的规律是,随着网络深度的增加,特征图的宽度和高度通常会衰减,而通道数(特征图数量)会增加,即 nH×nW×nCn_H \times n_W \times n_CnH×nW×nC 中的 nH,nWn_H, n_WnH,nW 减小,nCn_CnC 增大。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)