Python数据分析实战:从入门到精通
目录
一、引言
在当今数字化时代,数据已成为企业和社会发展的核心资产。Python 凭借其简洁的语法、强大的功能以及丰富的生态系统,成为数据分析领域的首选工具之一。无论是处理小型数据集,还是应对复杂的大数据场景,Python 都能提供高效且灵活的解决方案。本文将深入探讨 Python 在数据分析中的应用,从环境搭建、核心库使用,到实战案例以及前沿技术拓展,为读者呈现一个完整的数据分析学习路径。对比其他工具(如 Excel、R):“Python 相比 Excel 能处理百万级数据不崩溃,比 R 生态更通用易拓展,尤其适合‘数据处理→建模→部署’全流程打通”。贴业务痛点:“不管是互联网行业分析用户行为、金融行业做风险预测,还是科研领域处理实验数据,Python 都能‘一套代码走天下’,这也是它成为数据分析首选的核心原因”
二、Python 数据分析环境搭建
1. Python 安装
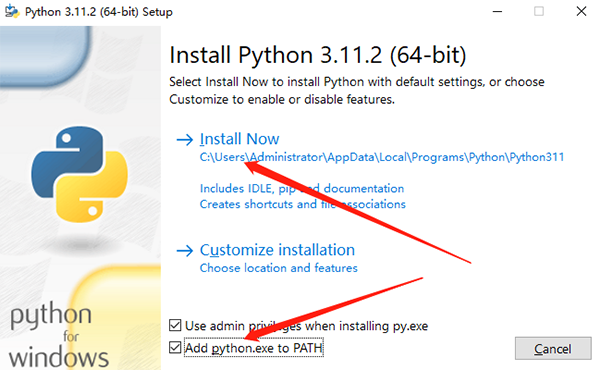
Python 有两个主要版本:Python 2 和 Python 3。由于 Python 2 已停止维护,建议安装 Python 3。可以从 Python 官方网站(https://www.python.org/downloads/ )下载对应操作系统的安装包。安装过程中,务必勾选 “Add Python to PATH” 选项,以便在命令行中方便地调用 Python。安装完成后,在命令行输入python --version,可查看 Python 版本,验证是否安装成功。验证进阶:除了 python --version,可加 python -c "import sys; print(sys.executable)" 查看实际运行的 Python 路径(避免环境冲突)。 排坑提示:“如果命令行输 python 没反应,大概率是 PATH 没配好,Windows 可手动去系统环境变量里检查;Mac/Linux 用 which python 定位路径”。
2. 包管理工具 ——pip 与 conda
pip
pip 是 Python 的标准包管理工具,通过它可以轻松安装、升级和卸载第三方库。例如,安装 NumPy 库只需在命令行输入pip install numpy。
conda
Conda 是一个功能强大的包管理和环境管理工具,尤其适用于科学计算和数据分析领域。它不仅可以管理 Python 包,还能管理非 Python 依赖项。
工具对比:“做数据分析优先用 conda,它能一键装非 Python 依赖(如科学计算库的底层 C 库);纯 Python 项目用 pip 更轻量。简单说:数据科学选 conda,普通开发用 pip”
虚拟环境:“用 conda create -n 环境名 python=3.9 建独立环境,避免不同项目依赖冲突,这是‘干净环境’的关键!
3. 常用集成开发环境(IDE)
PyCharm
PyCharm 是一款专业的 Python IDE,提供了强大的代码编辑、调试、代码分析等功能。它支持多种 Python 框架和库,并且对数据分析库有良好的支持。PyCharm:“选专业版对数据分析更友好,能直接连接数据库、可视化调试;社区版够用但功能少。写代码时用 Alt + Enter 自动补全依赖,效率翻倍!”
Jupyter Notebook
Jupyter Notebook 是一个基于 Web 的交互式计算环境,非常适合数据分析和数据科学。它允许用户创建和共享包含代码、可视化图表和文本说明的文档,方便在数据分析过程中进行探索性分析、记录分析过程和展示结果。通过命令jupyter notebook即可启动 Jupyter Notebook 服务。upyter Notebook:“适合边写边探索(比如做数据可视化迭代),但多人协作推荐用 Jupyter Lab(界面更现代,支持多窗口)。记得用 %timeit 测试代码运行时间,优化性能!”
三、Python 数据分析核心库详解
1. NumPy:数值计算的基石
NumPy 的核心是ndarray(多维数组)对象,它提供了高效的数值存储和计算功能。与 Python 原生列表相比,ndarray在内存占用和计算速度上都有显著优势。核心优势:“Python 列表做循环计算慢得要死,但 NumPy 的向量化运算能让 arr + 1 这样的操作瞬间完成,因为它把循环放到 C 语言层执行(广播机制就是典型案例)”。实用场景:“处理图像数据(本质是多维数组)、金融时间序列(高效计算收益率),NumPy 是‘幕后英雄’”
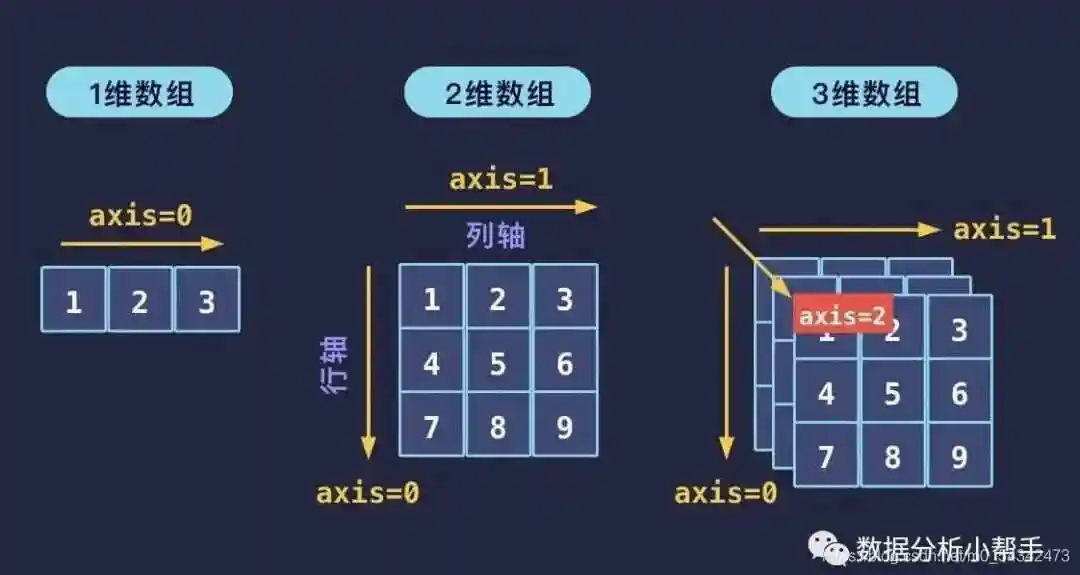
import numpy as np
# 创建一维数组
arr1 = np.array([1, 2, 3, 4, 5])
# 创建二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
# 数组运算
print(arr1 + 1) # 对数组每个元素加1
print(arr2 * 2) # 对数组每个元素乘以2
# 统计函数
print(np.mean(arr1)) # 计算数组平均值
print(np.sum(arr2)) # 计算数组所有元素之和NumPy 还支持广播机制,使得不同形状的数组之间也能进行运算,极大地简化了代码编写。例如:
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([10, 20, 30])
print(a + b)2. Pandas:数据处理的利器
Pandas 提供了两种重要的数据结构:Series和DataFrame。Series是一维带标签的数组,DataFrame是二维的表格型数据结构,类似于 Excel 表格,非常适合处理结构化数据。
分组聚合:“用 groupby 时,结合 agg 能一次算多个指标(比如 df.groupby('类别')['数值列'].agg(['mean', 'max'])),这比 Excel 数据透视表更灵活!”
缺失值:“遇到缺失值别慌,先看 df.isnull().sum() 统计分布,再选填充策略(时间序列用前后值填充,数值列用均值/中位数,类别列用‘未知’标记)”。
import pandas as pd
# 创建DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'London', 'Paris']
}
df = pd.DataFrame(data)
# 查看数据
print(df.head()) # 查看前5行数据
print(df.info()) # 查看数据信息
print(df.describe()) # 查看数据统计摘要
# 数据筛选
print(df[df['Age'] > 30]) # 筛选年龄大于30的行Pandas 在数据读取和写入方面也表现出色,支持 CSV、Excel、SQL 数据库等多种数据格式。
3. Matplotlib:数据可视化的基础
Matplotlib 是 Python 最常用的数据可视化库之一,提供了丰富的绘图函数,可以创建各种静态、动态和交互式图表。
| 类型图 | 作用及特点 |
|
折线图 (Line Plot) |
作用:展示数据随时间或顺序的变化趋势。 特点:清晰显示数据波动和走向。 |
|
散点图 (Scatter Plot) |
作用:观察两个变量之间的相关性或分布关系。 特点:直观显示数据点的聚集或离散情况。 |
| 柱状图(Bar Chart) | 作用:比较不同类别数据的大小或频率。 特点:横向/纵向对比鲜明,适合分类数据。 |
| 直方图(Histogram) | 作用:展示连续数据的分布形态(如频率分布)。 特点:直观呈现数据的集中趋势和离散程度。 |
| 饼图(Pie Chart) | 作用:显示各部分占总体的比例关系。 特点:简明扼要,适合展示占比数据。 |
| 箱线图(Box Plot) |
作用:展示数据的分布特征(如中位数、四分位数、异常值),用于比较多组数据的离散程度和偏态。 特点:简洁直观,能快速识别数据的集中趋势、离群值和分布形态。 |
plt.plot(x, y, marker='o', linestyle='-', color='b') # 绘制折线(带标记点)
plt.title('折线图示例')
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
plt.grid(True) # 显示网格
plt.show()# 生成随机数据(示例:模拟身高与体重的关系)
np.random.seed(42)
height = np.random.normal(170, 10, 50) # 身高(均值170,标准差10)
weight = np.random.normal(65, 15, 50) # 体重(均值65,标准差15)
plt.scatter(height, weight, c='r', alpha=0.6) # 绘制散点(颜色红色,透明度0.6)
plt.title('散点图:身高与体重的关系')
plt.xlabel('身高(cm)')
plt.ylabel('体重(kg)')
plt.show()plt.barh(categories, values, color='green') # 横向柱状图(barh为横向,bar为纵向)
plt.title('横向柱状图:类别数据对比')
plt.xlabel('数值')
plt.ylabel('类别')
plt.show()# 生成随机数据(示例:学生成绩分布)
np.random.seed(42)
scores = np.random.normal(75, 10, 1000) # 模拟成绩(均值75,标准差10)
plt.hist(scores, bins=20, edgecolor='black', alpha=0.7) # bins为分组数
plt.title('直方图:学生成绩分布')
plt.xlabel('分数')
plt.ylabel('频数')
plt.show()labels = ['类别A', '类别B', '类别C', '类别D']
sizes = [30, 25, 20, 25]
colors = ['#ff9999', '#66b3ff', '#99ff99', '#ffcc99']
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
plt.axis('equal') # 保证饼图为正圆形
plt.title('饼图:类别占比')
plt.show()
代码说明:# 生成随机数据(示例:不同班级的成绩分布)
np.random.seed(42)
scores = np.random.normal(75, 10, 100) # 模拟成绩(均值75,标准差10)
plt.boxplot(scores, patch_artist=True, labels=['成绩']) # patch_artist=True 允许设置颜色
plt.title('单组数据箱线图:成绩分布')
plt.ylabel('分数')
plt.show()
多组数据箱线图(横向对比)
# 生成多组数据(示例:三个班级的成绩对比)
np.random.seed(42)
class1 = np.random.normal(70, 15, 50)
class2 = np.random.normal(80, 10, 50)
class3 = np.random.normal(75, 20, 50)
data = [class1, class2, class3]
plt.boxplot(
data,
patch_artist=True, # 允许填充颜色
labels=['班级1', '班级2', '班级3'], # 分组标签
boxprops={'facecolor': '#99ccff'}, # 箱体颜色
whiskerprops={'color': 'black'}, # 须的颜色
capprops={'color': 'black'}, # 箱线端点颜色
flierprops={'marker': 'o', 'color': 'red', 'markersize': 5} # 异常值样式
)
plt.title('多组数据箱线图:班级成绩对比')
plt.ylabel('分数')
plt.show()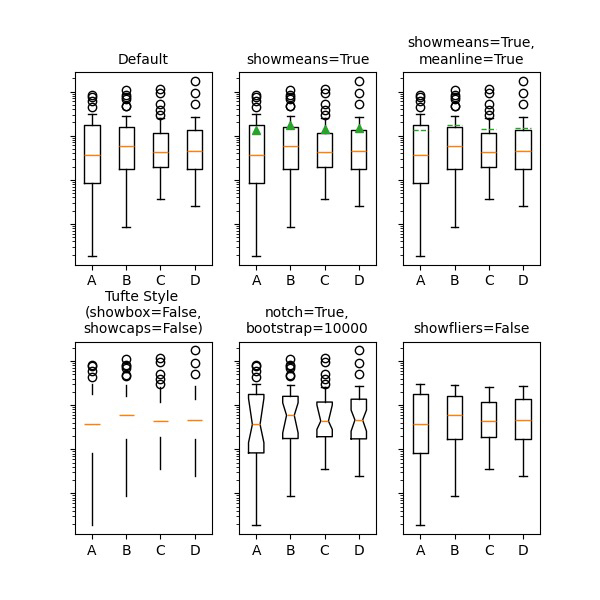
• 设计逻辑:“折线图别用太艳的颜色,金融数据常用蓝/灰;柱状图间距设为 0.8 更美观;多图排版用 subplots 统一控制布局”。
• 场景延伸:“箱线图适合看异常值(比如竞赛数据里的极端分数),热力图能展示特征相关性(分析用户行为时超有用)”。
通过设置各种参数,如颜色、线条样式、字体等,可以对图表进行个性化定制,使其更加美观和专业。
四、Python 数据分析实战案例
 在实际工作中,Python 数据分析需要结合真实的业务需求与数据特点。下面通过多个领域的实战案例,给出更贴近实际场景的代码,涵盖数据读取、清洗、分析和可视化全流程。
在实际工作中,Python 数据分析需要结合真实的业务需求与数据特点。下面通过多个领域的实战案例,给出更贴近实际场景的代码,涵盖数据读取、清洗、分析和可视化全流程。
案例背景
某医院的电子病历系统导出了患者就诊数据,数据存储在 SQLite 数据库中,包含患者 ID、性别、年龄、就诊日期、诊断结果、住院天数、治疗费用等字段。我们需要分析不同年龄段患者的平均住院费用、常见疾病的季节性分布以及治疗费用的影响因素。
数据分析过程
import pandas as pd
import sqlite3
import matplotlib.pyplot as plt
import seaborn as sns
# 连接SQLite数据库
conn = sqlite3.connect('medical_data.db')
# 读取数据
medical_data = pd.read_sql_query("SELECT * FROM patients", conn)
# 关闭数据库连接
conn.close()
# 数据清洗
# 处理缺失值,用年龄均值填充缺失的年龄数据
medical_data['Age'] = medical_data['Age'].fillna(medical_data['Age'].mean())
# 处理异常住院天数,过滤掉住院天数小于0的数据
medical_data = medical_data[medical_data['Length of Stay'] >= 0]
# 分析不同年龄段患者的平均住院费用
medical_data['Age_Group'] = pd.cut(medical_data['Age'], bins=[0, 18, 30, 40, 50, 60, 100],
labels=['0-18', '19-30', '31-40', '41-50', '51-60', '60+'])
average_cost_by_age = medical_data.groupby('Age_Group')['Treatment Cost'].mean()
plt.figure(figsize=(10, 6))
average_cost_by_age.plot(kind='bar')
plt.title('Average Treatment Cost by Age Group')
plt.xlabel('Age Group')
plt.ylabel('Average Treatment Cost')
plt.show()
# 分析常见疾病的季节性分布
medical_data['Month'] = medical_data['Visit Date'].dt.month
top_diseases = medical_data['Diagnosis'].value_counts().head(5).index
seasonal_disease = medical_data[medical_data['Diagnosis'].isin(top_diseases)]
plt.figure(figsize=(12, 6))
sns.countplot(x='Month', hue='Diagnosis', data=seasonal_disease)
plt.title('Seasonal Distribution of Common Diseases')
plt.xlabel('Month')
plt.ylabel('Number of Cases')
plt.show()
# 简单分析治疗费用的影响因素(以住院天数为例)
plt.figure(figsize=(10, 6))
sns.regplot(x='Length of Stay', y='Treatment Cost', data=medical_data)
plt.title('Relationship between Length of Stay and Treatment Cost')
plt.xlabel('Length of Stay')
plt.ylabel('Treatment Cost')
plt.show()业务延伸:“分析‘不同年龄段平均费用’后,可建议医院对老年群体推出套餐;发现‘冬季疾病高发’,提前储备药品资源”
进阶思路:“用 pandas 做漏斗分析(比如竞赛网站‘注册→参赛→获奖’转化),或用 seaborn 画相关性热力图(找用户行为和竞赛成绩的关系)”
1.批判性思考
“很多教程说‘数据清洗要把缺失值全填满’,但实际中,保留缺失值并用 pd.NA 标记,能让模型识别‘数据缺失本身就是一种特征’(比如患者没填‘过敏史’,可能意味着没有过敏)——教条式学习要不得,理解业务场景才是王道。”
五、Python 数据分析的进阶与拓展
1. 机器学习在数据分析中的应用
Scikit-learn 是 Python 中最常用的机器学习库,提供了丰富的机器学习算法,包括分类、回归、聚类等。想快速搭建机器学习模型?Python里的scikit-learn(简称sklearn)超好用!它像一个“工具箱”,里面有各种算法,从简单的线性模型到复杂的随机森林都有,而且用起来特别顺手。下面手把手教你用它搞定一个分类模型!
(1)准备工作:导入工具
from sklearn import datasets # 加载示例数据集
from sklearn.model_selection import train_test_split # 划分训练和测试数据
from sklearn.ensemble import RandomForestClassifier # 随机森林分类模型
from sklearn.metrics import accuracy_score, classification_report # 评估模型(2)五步搭建模型
2.1 加载数据
iris = datasets.load_iris() # 加载经典鸢尾花数据集
X = iris.data # 花的特征(比如花瓣长度、宽度)
y = iris.target # 花的类别(3种鸢尾花)2.2 划分数据集
X_train, X_test, y_train,
y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 把数据分成两份:70%用来训练模型,30%用来测试效果2.3 选择并训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42) # 选随机森林模型
model.fit(X_train, y_train) # 用训练数据教会模型“认花2.4 用模型预测
y_pred = model.predict(X_test) # 让模型判断测试数据里的花属于哪一类2.5 评估模型好坏
accuracy = accuracy_score(y_test, y_pred) # 计算预测准确率
print(f"模型准确率:{accuracy:.2f}")
print("详细评估报告:")
print(classification_report(y_test, y_pred))
# 输出精确率、召回率等详细指标 调优思路:“用 GridSearchCV 找最优参数(比如随机森林的 n_estimators),对比调参前后准确率变化,让模型更‘聪明’”
结果解读:“用 SHAP 库看特征重要性(比如竞赛成绩里‘练习次数’比‘年龄’影响大),解释模型为什么这么预测,避免‘黑盒’风险”
(3)常见问题怎么办?
• 数据有缺失值:用SimpleImputer填充。
• 特征是文字:用LabelEncoder转成数字。
• 模型不准:试试调参数,或换其他模型(比如逻辑回归、SVM)。
sklearn用起来超简单:
1. 找数据 → 2. 分数据 → 3. 选模型 → 4. 训练 → 5. 测试
2. 大数据处理与分布式计算
当数据量达到 TB 甚至 PB 级别时,传统的单机处理方式已无法满足需求。此时,可以使用 Dask 和 PySpark 等工具进行大数据处理和分布式计算。Dask 提供了与 Pandas 和 NumPy 类似的 API,能够在单机多核心或小型集群上处理大规模数据;PySpark 则是基于 Apache Spark 的 Python 接口,适用于大规模数据的分布式处理和分析,支持在 Hadoop、Spark 集群上运行。
3. 自动化与脚本化数据分析
通过编写 Python 脚本,可以将数据分析流程自动化。例如,使用schedule库实现定时任务,自动从数据库中提取数据、进行分析并生成报告,然后通过smtplib库发送邮件给相关人员。以下是一个简单的定时任务示例:
import schedule
import time
def job():
print("Running data analysis job...")
# 在这里编写数据分析代码
schedule.every(1).hours.do(job)
while True:
schedule.run_pending()
time.sleep(1)六、总结
Python 在数据分析领域的应用前景广阔,从基础的数据处理到复杂的机器学习和大数据分析,Python 都能提供全面的解决方案。通过不断学习和实践,读者可以深入掌握 Python 数据分析技能,在数据驱动的时代中发挥更大的价值。希望本文能为您的 Python 数据分析学习之旅提供有益的帮助,开启数据分析的无限可能。学习路径:“新手先练 Pandas 数据清洗( Kaggle 上的泰坦尼克号数据集超适合),再学 Matplotlib 可视化,最后用 sklearn 建模,一步步来!”行业趋势:“现在数据分析越来越卷‘自动化’(用 Python 脚本定时跑报告)和‘AI 结合’(大模型辅助写分析代码),这些方向值得关注!”

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)