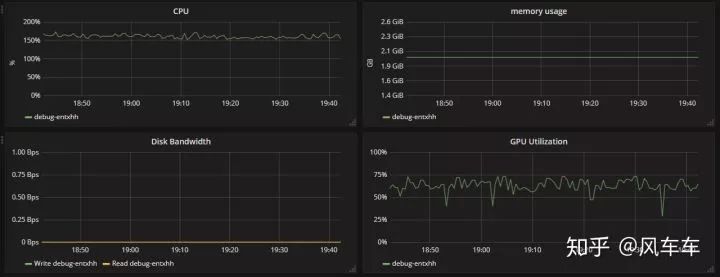
查看gpu使用率 nvidia_在深度学习中喂饱GPU
新智元推荐来源:知乎专栏作者:风车车【新智元导读】深度学习模型训练是不是大力出奇迹,显卡越多越好?非也,没有512张显卡,也可以通过一些小技巧优化模型训练。本文作者分析了他的实践经验。前段时间训练了不少模型,发现并不是大力出奇迹,显卡越多越好,有时候 1 张 v100 和 2 张 v100 可能没有什么区别,后来发现瓶颈在其他地方,写篇文章来总结一下自己用过的一些小 trick,最...
·
新智元推荐 来源:知乎专栏作者:风车车
【新智元导读】深度学习模型训练是不是大力出奇迹,显卡越多越好?非也,没有512张显卡,也可以通过一些小技巧优化模型训练。本文作者分析了他的实践经验。
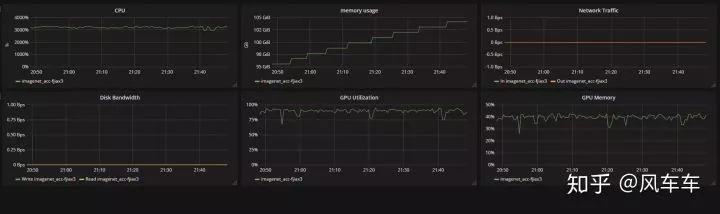
前段时间训练了不少模型,发现并不是大力出奇迹,显卡越多越好,有时候 1 张 v100 和 2 张 v100 可能没有什么区别,后来发现瓶颈在其他地方,写篇文章来总结一下自己用过的一些小 trick,最后的效果就是在 cifar 上面跑 vgg 的时间从一天缩到了一个小时,imagenet 上跑 mobilenet 模型只需要 2 分钟每个 epoch。(文章末尾有代码啦)
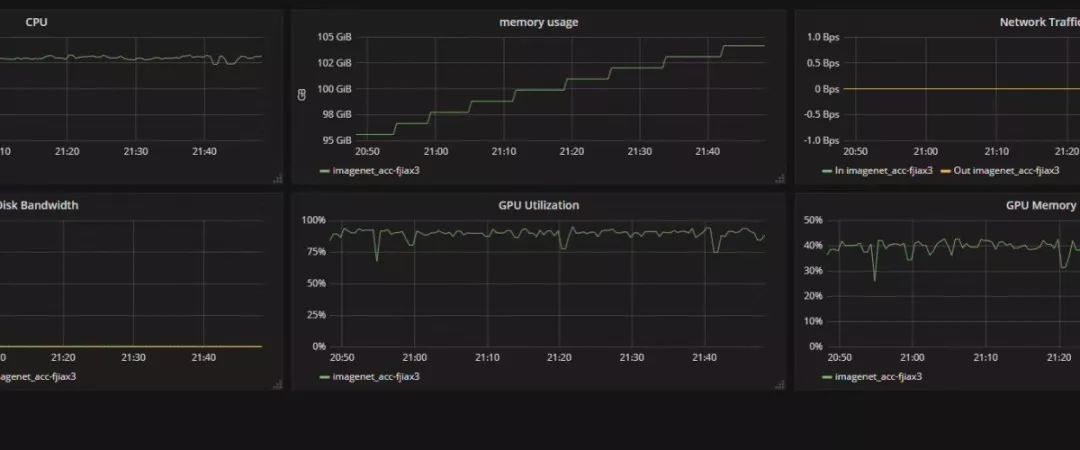
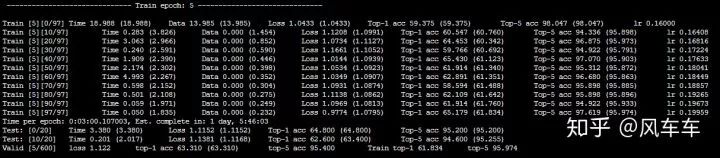
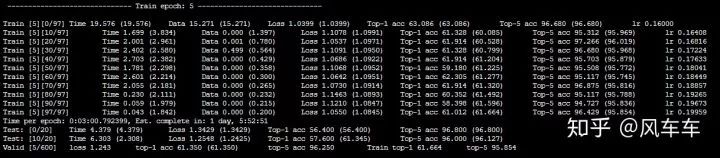
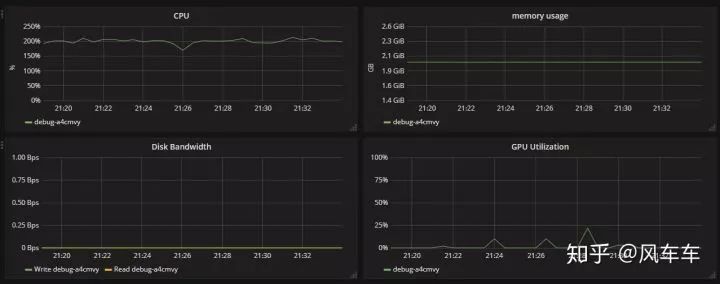
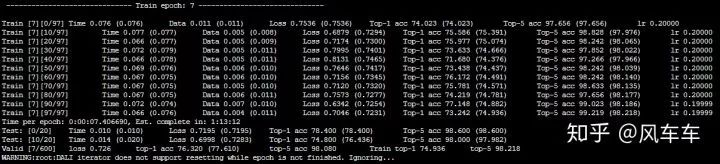
先说下跑 cifar 的时候,如果只是用 torchvision 的 dataloader (用最常见的 padding/crop/flip 做数据增强) 会很慢,大概速度是下面这种,600 个 epoch 差不多要一天多才能跑完,并且速度时快时慢很不稳定。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)