深度学习图像处理基础
人对亮度的差异的分辨能力存在极限。
分辨率
是什么

一张照片被拍摄出来之后,我们将其放大,可以看多许多的小方块单元,这些单元称为像素,组成了整个照片,而分辨率就是水平像素个数和垂直像素个数组合而成

上图相机的最高像素可以达到三千万,像素越高成像越清晰
视网膜屏
视网膜屏

视网膜屏就是像素颗粒很小,很细腻,细腻到人眼看不出来像素颗粒的存在,就被称为视网膜屏
视网膜屏的设计,可以欺骗人类的大脑,将一些零散的画面,反馈到大脑后成为连续的画面,这是视网膜屏的重大意义
人眼的视觉
视力
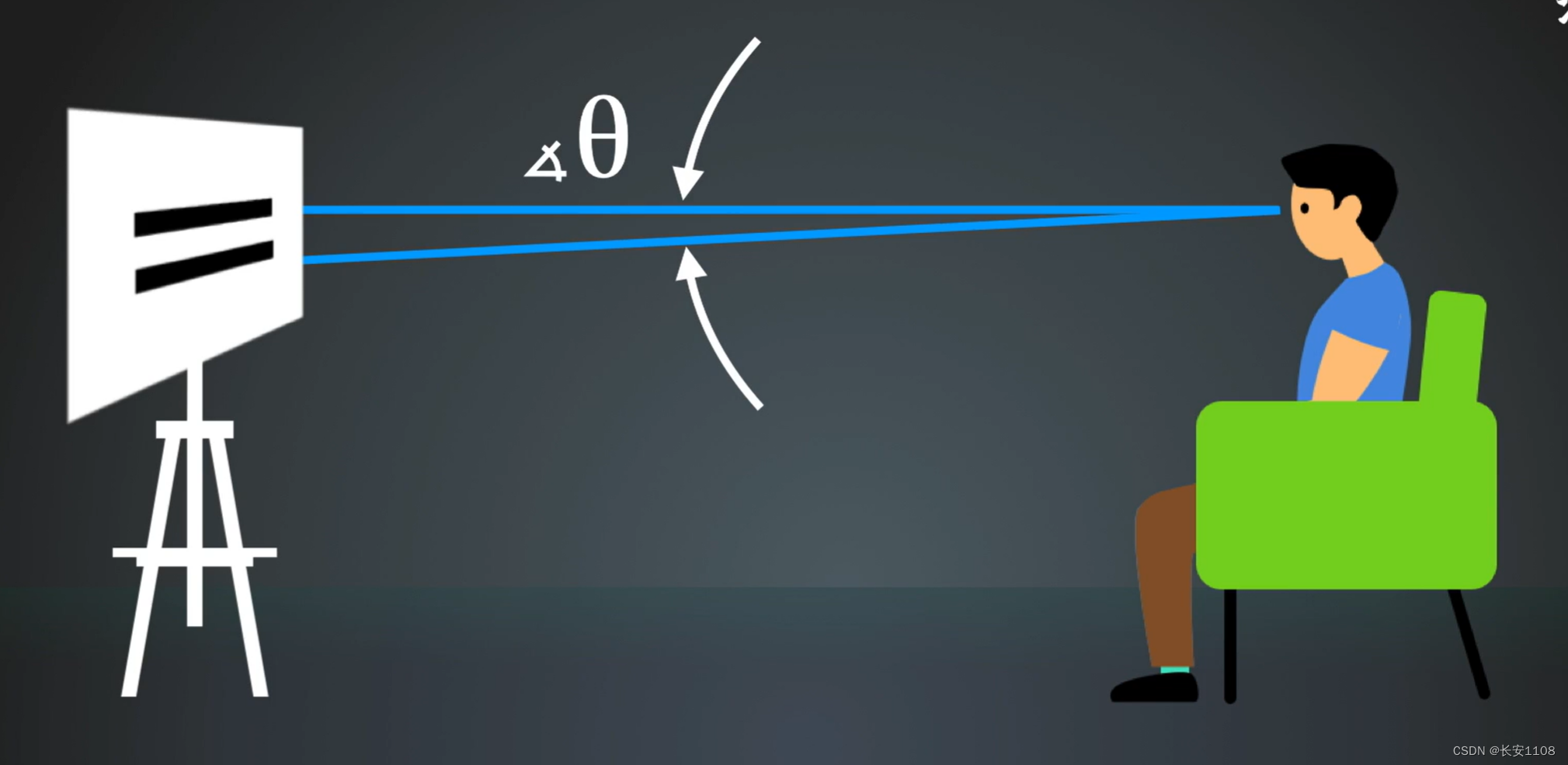
视力是你将两条线看成一条线之后,人眼与两条线形成的夹角,就是视力吗,这个角被称为极限分辨角度

当我们使用E子表,测试视力时,上面所反馈得到的数值,是极限分辨角度的倒数,单位是角分
像素密度

我们通常使用像素密度来判断像素的大小,像素密度是对角线的像素个数/对角线尺寸(单位英寸),得出这块屏幕的像素密度,简称PPI
分辨率 决定总像素数
PPI 决定像素在屏幕上的密度(细腻程度),与屏幕尺寸一起决定画质清晰度
同分辨率,屏幕越小 → PPI 越高 → 画面越清晰
设置合适的PPI,制造视网膜屏
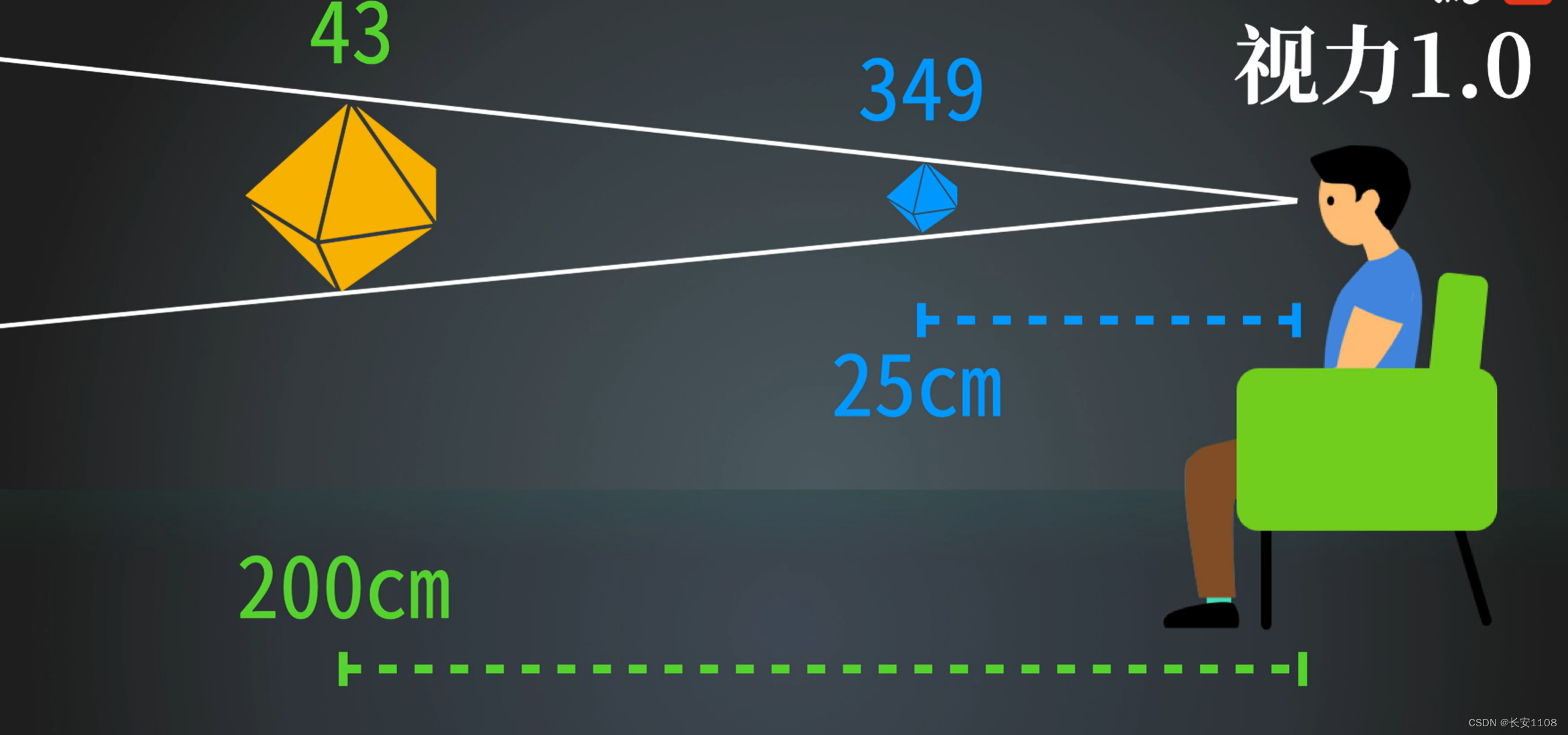
想要计算出一个视网膜屏的PPI,需要得知这个人的视力以及观看距离,视力与观看距离可以计算出视野范围,也就是屏幕尺寸,拿到屏幕尺寸之后,根据人眼能分辨的最小的像素单元大小,就可以计算出设计的屏的对角线有多少像素,再除以对角线长度(英寸),就可以计算出像素的密度,即PPI
色彩
是什么


颜色是光反射的结果,光的本质是电磁波,而人类能够捕捉到的光的波长范围是400nm至700nm
色匹配实验

根据色匹配实验得出,同一种颜色,可以由完全不同的光谱分布实现
且,任何一种颜色,都可以使用红绿蓝三原色不同的比例分配进行合成
色彩匹配的意义
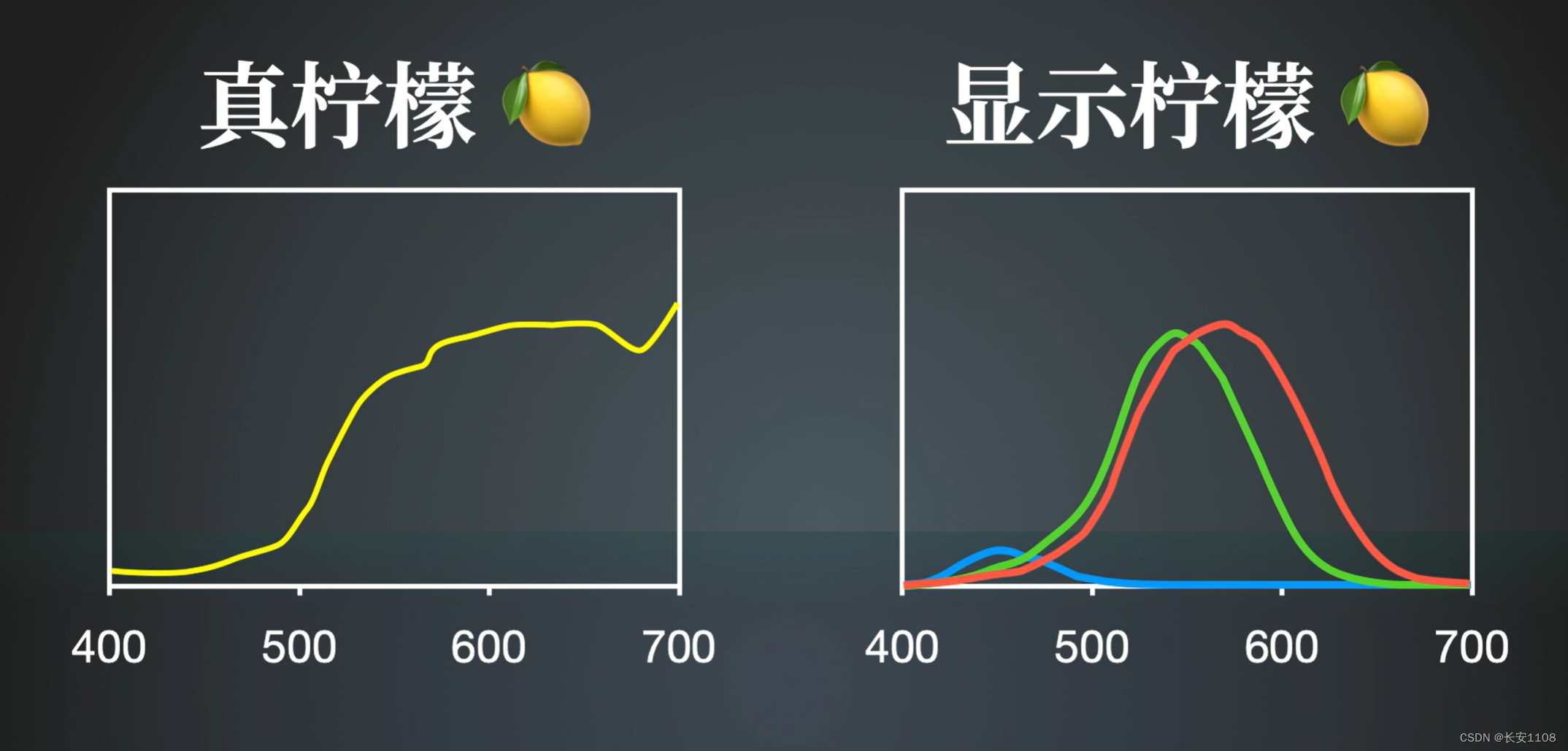
由以上结论可知,我们想要显示一个颜色,无需真的把那个颜色调出来,而是用三原色红绿蓝调制特定的比例从而合成我们想要的颜色,从而用更少的资源更高效的做事
量化色彩匹配
白色合为1
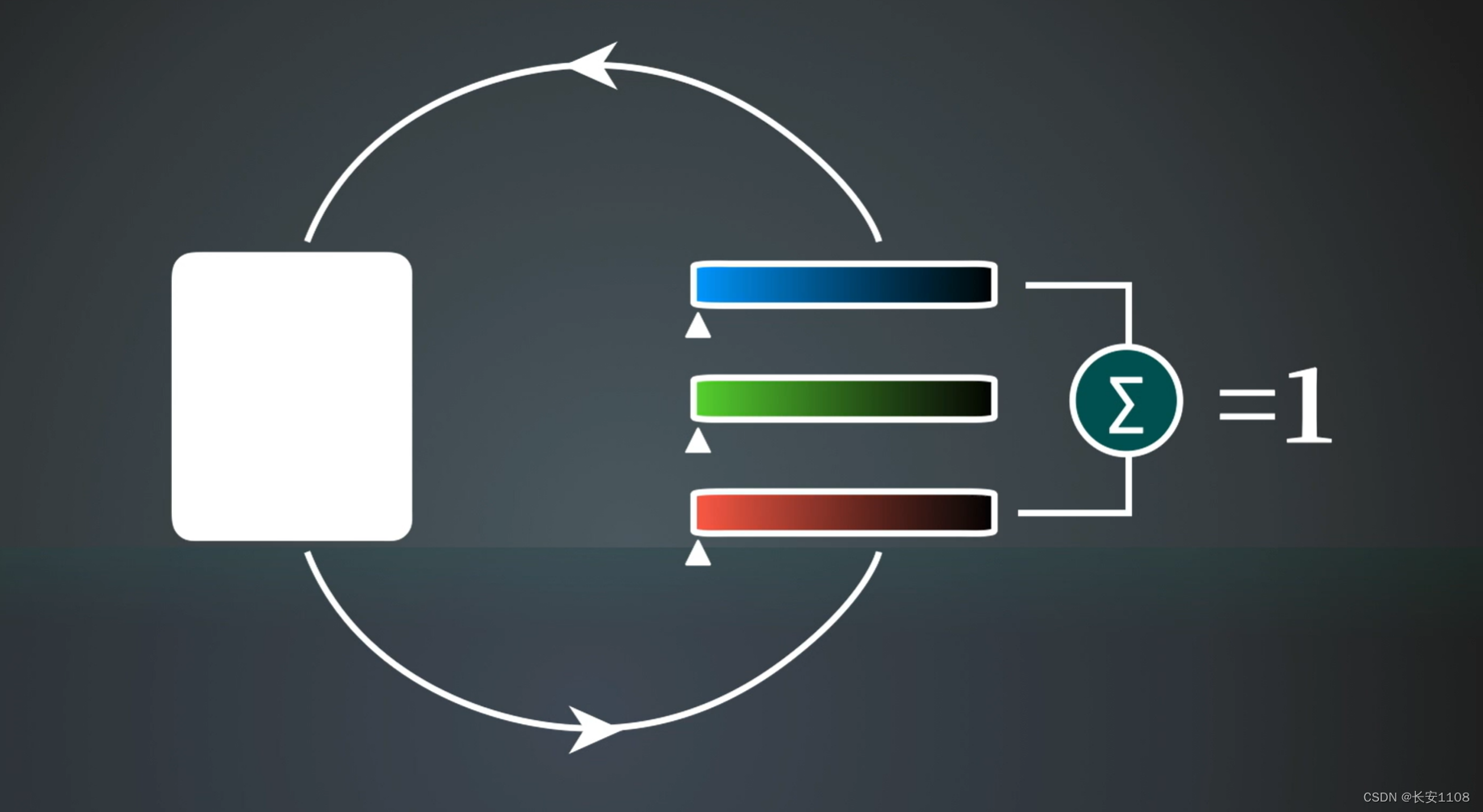
我们规定三原色等比例合成白色时,三色和为1
色度图
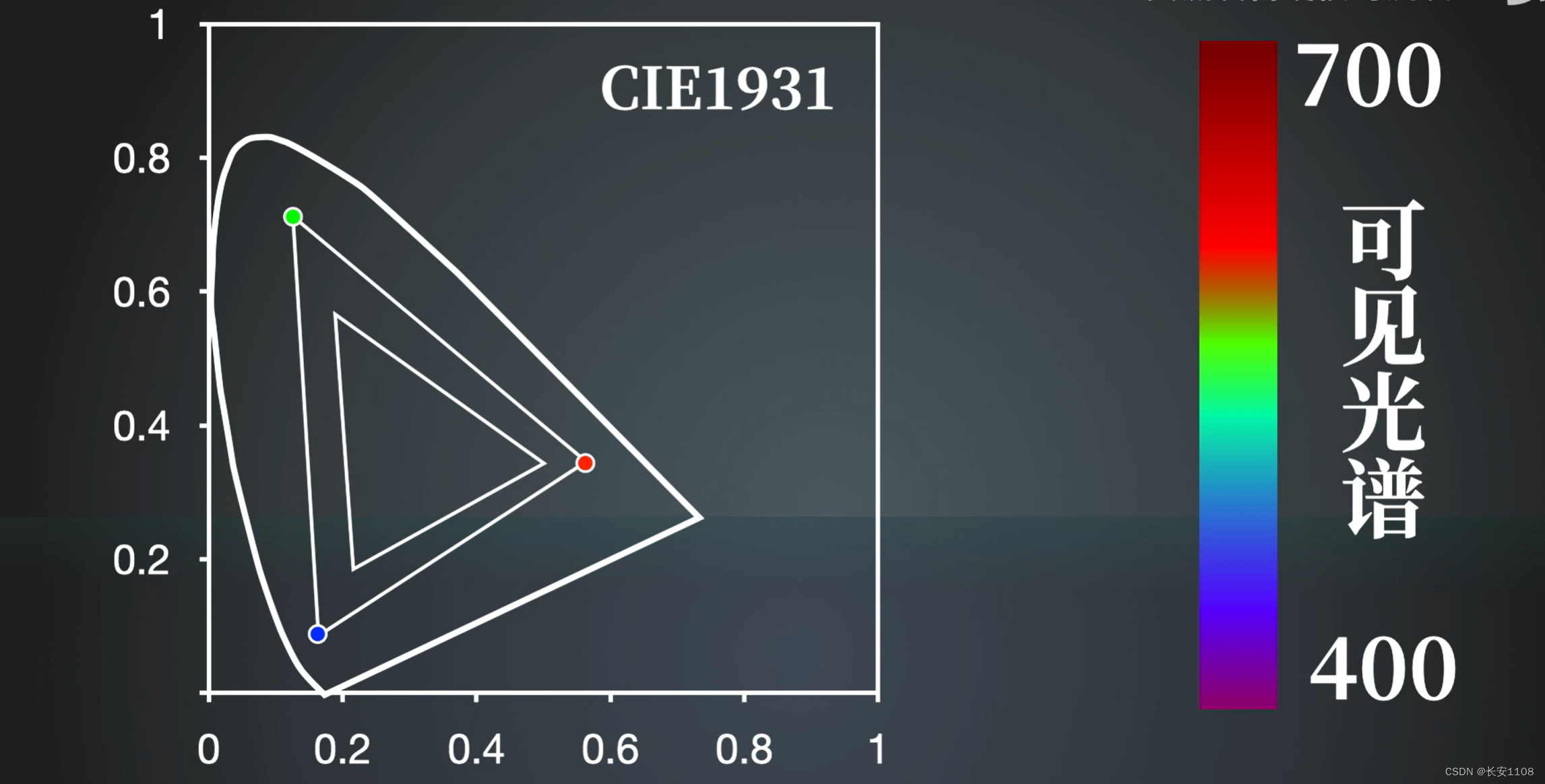
将400nm至700nm的点画在上面的色度坐标图中,会显示出独特的曲线,而从中取三个点形成三角形,那么该三角形内的色彩就可以由这三个点的不同比例匹配出来,所以三角形越大,匹配的色彩越多
但是从工业的角度出发,为了成本,我们只需要一个能将我们日常生活中较为常见的色彩匹配出来的三角形即可,所以出现了许多的三角形标准,如下图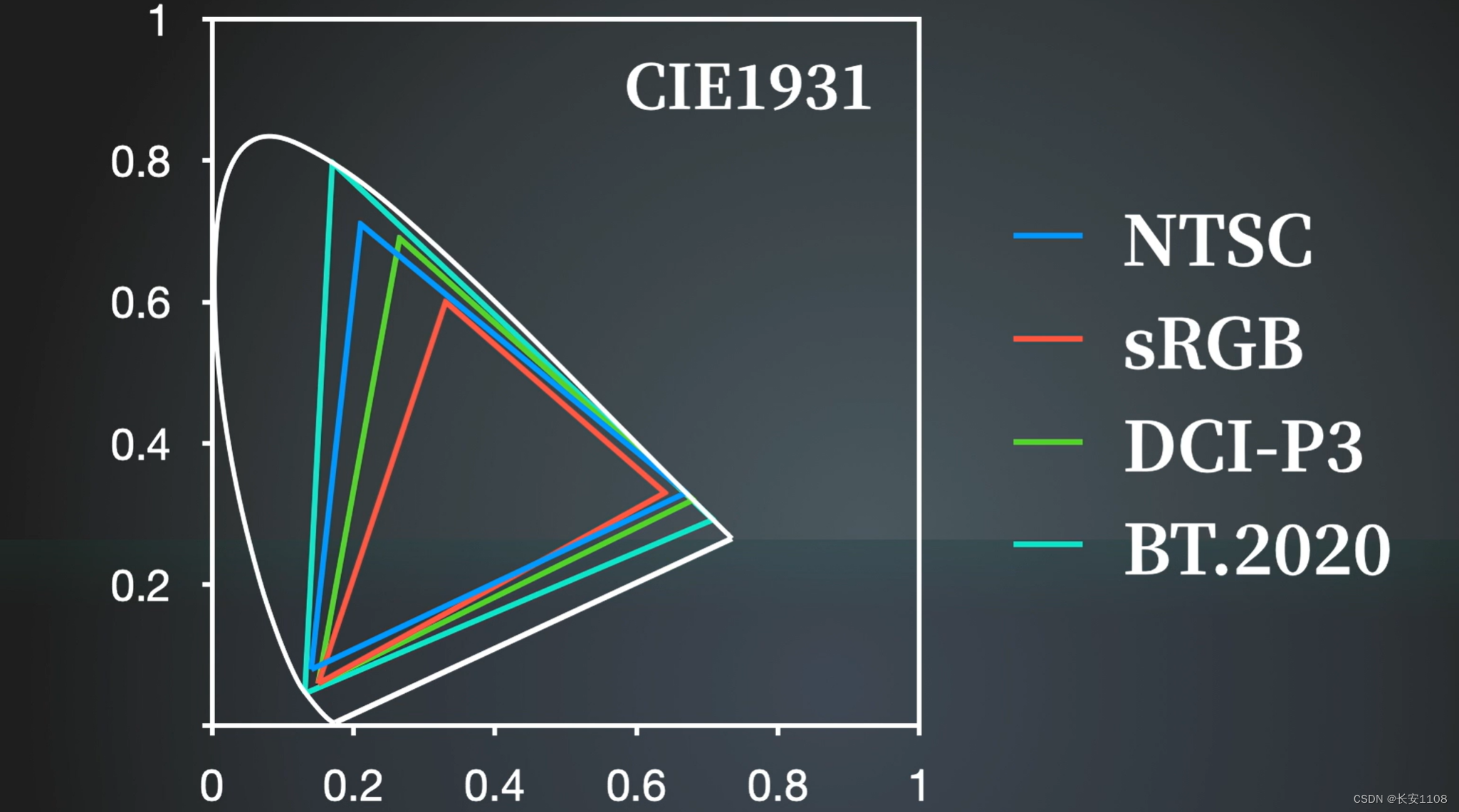
总结

HDR
光亮度(尼特)
人对亮度的差异的分辨能力存在极限
灰阶

一个器件亮度从最暗到最亮被划分为有限个等级,这些等级称为灰阶
而这些有限个灰阶的划分是按照二进制的位数划分的
例如一个8bit的灰阶,有2的8次方个不同的等级,且等级变化不连续,是间断变化的,2的8次方,一共有256个等级
0:最黑 255:最白 中间:不同深浅的灰色
但是由于人眼对亮度差异的分辨存在极限,所以,对于不连续的灰阶,在人眼看来,是连续的
亮度范围

人眼能感知的亮度范围是10的-6次方到10的8次方,但是目前所有的感光器件(例如相机),他的亮度范围都没能达成人眼的范围,都要比人眼的范围小
HDR显示技术

所以,HDR就是将一个相机拍摄的从最暗到最亮的几张有代表性的照片合成到一起,这就是HDR技术
但是HDR技术有可能会造成原来的亮度差异的变化,造成画面的失真
所以,捕捉到更多的灰阶以及足够大的尼特范围,是HDR努力的方向
总结

数字图像化
概览

首先我们得到一张照片
之后,由于相机cmos的限制,我们将其分成3808*2856个像素
之后,每个像素通过 RGB 三个通道表示红绿蓝光强,形成三通道彩色图像,即三个通道,红通道、绿通道、蓝通道三个通道的像素图
最后,每个通道用 8bit 编码量化,0–255 表示光强(即某单色的灰阶),得到数字图像
人脸检测
需要关注的两个问题
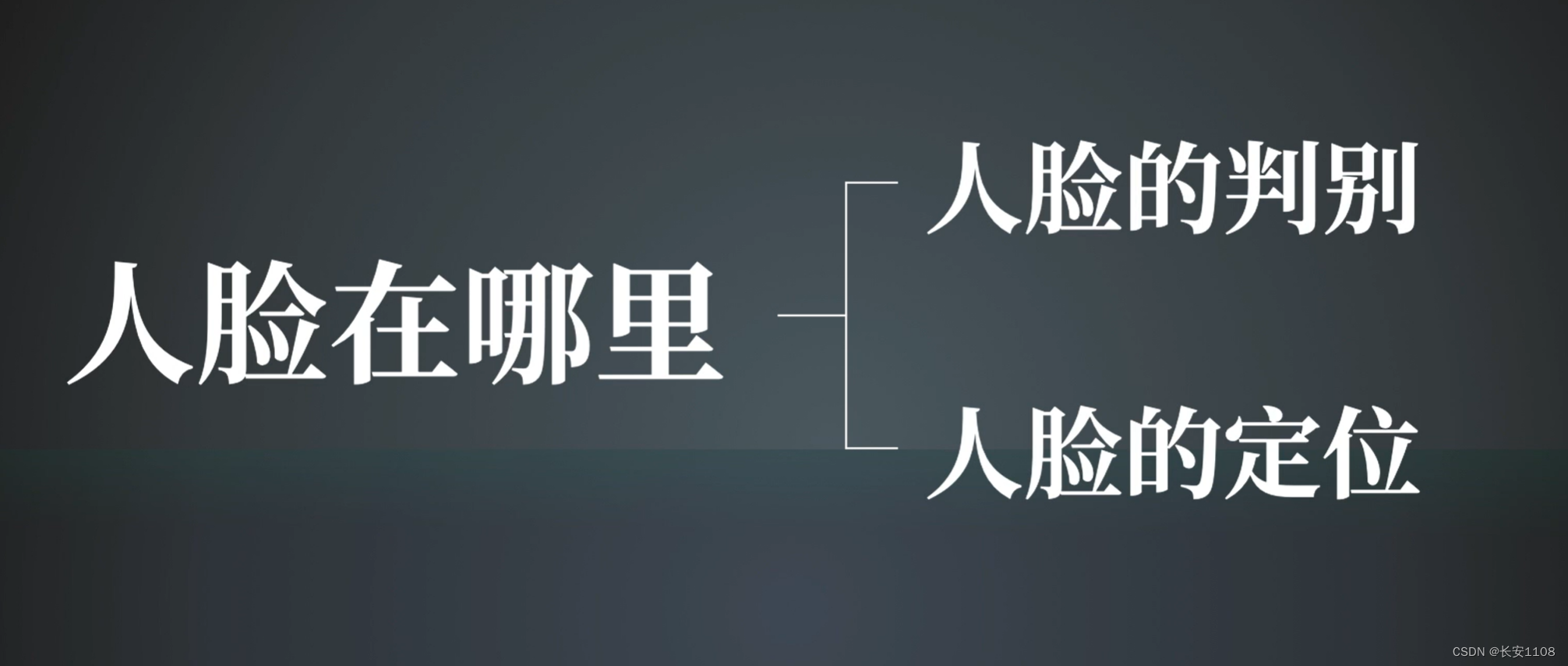
人脸检测需要关注这两个问题
人脸的判别
人脸检测算法

第一步

类哈尔特征

根据不同区域亮暗的区别,以及区域的大小,可以得到如下图所示的类哈尔特征:
白色代表亮的区域,黑色代表暗的区域,而大小则代表像素的多少
集成学习


什么是弱分类器:
只看某一个单一特征,就做出判断

如上几图所示,集成学习就是集成一些正确率不高的线索,最终达到目的,而我们要集成的对象就是弱分类器,他之所以叫做弱分类器,是因为他们单独行动时,准确率不高,但是将他们集成起来,就能达到不错的效果
第二步

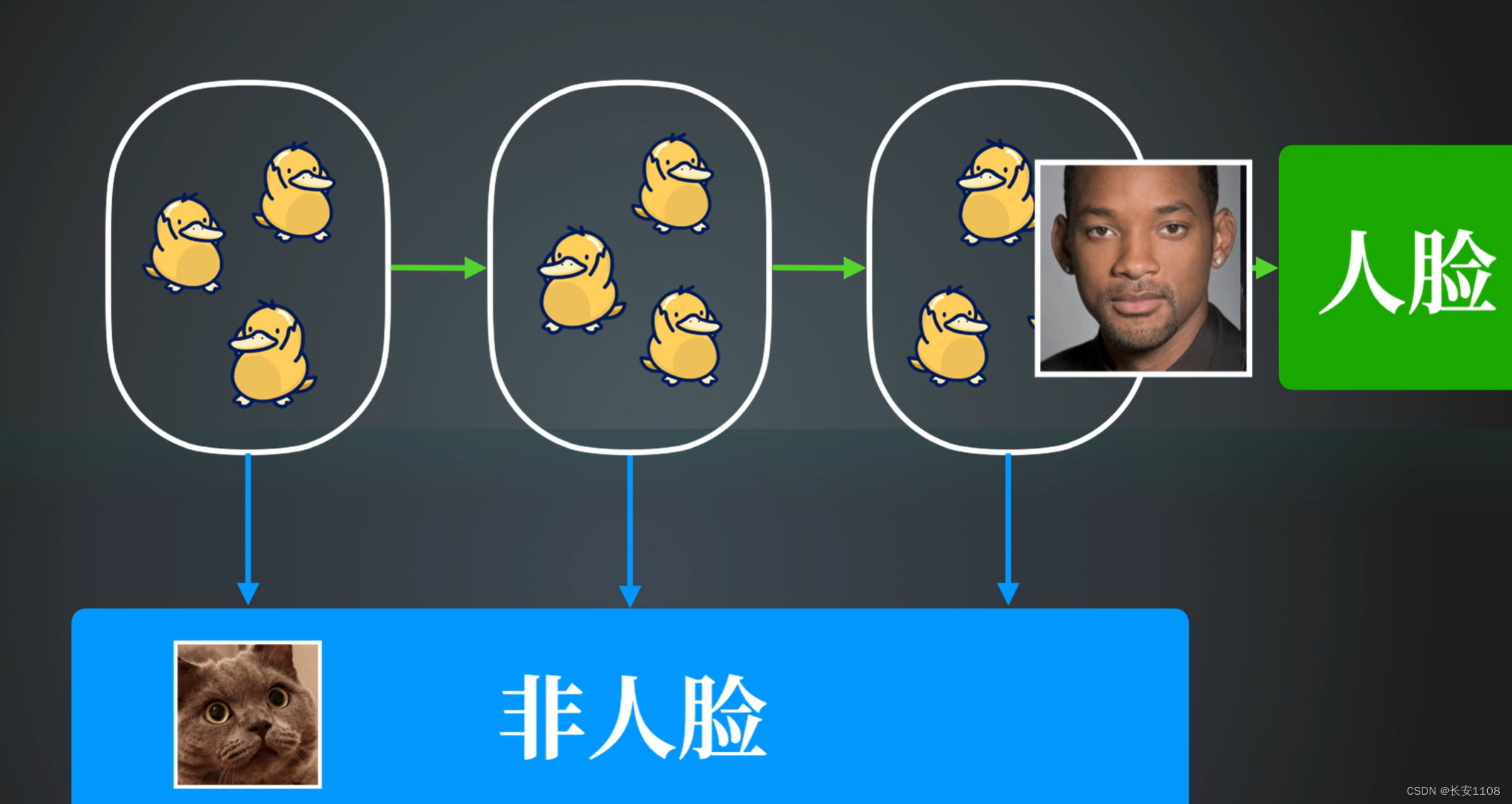
将一些集成分类器时,将分类器进行等级划分,对于一些可以获取到大前提信息的分类器,要放在前面,优先级要高,因为如果大前提不满足,那么更别提细节了
所以,以人脸检测(某个特定的人的脸,如小明的人脸识别解锁手机)来说,最高级是判断是否是人脸(即,是不是人),如果不是,直接排除,无需进行后续运算,可以大大提高效率
第三步

积分图算法
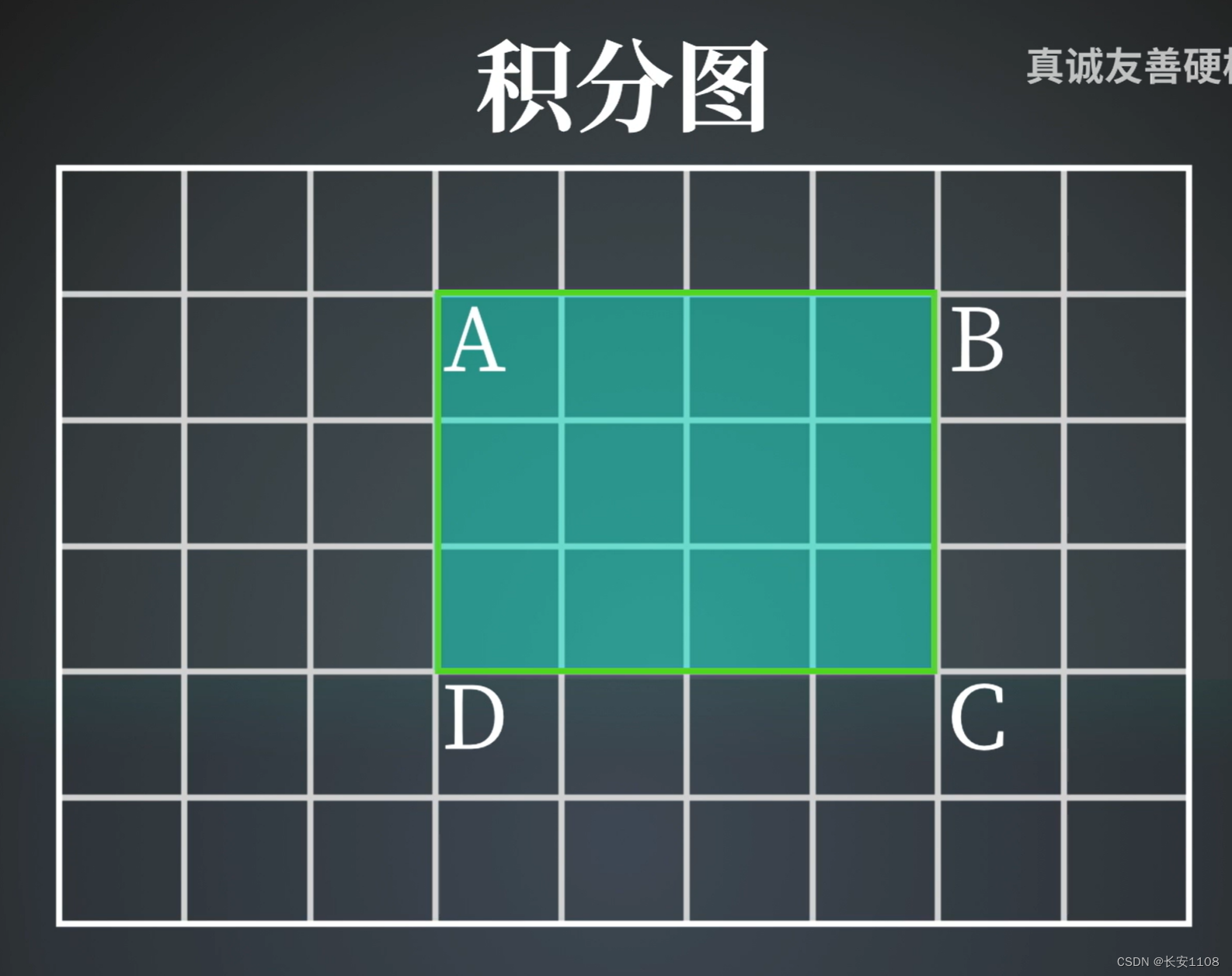
积分图中,一个点的亮度等于其与左上角所组成的矩形的亮度之和,那么如果要计算一个矩形的亮度,就是C-B-D+A(因为减了两次A)
总结
第一步:集成学习(即,集成弱分类器)寻找类哈尔特征
第二步:集成方式使用级联集成,可以提高效率
第三步:使用亮度积分图,可以再次加速寻找过程
进行类哈尔特征级联检测,同时使用亮度积分图进行加速
人脸的定位
滑动窗口与滑动尺寸

设置一个滑动窗口以及滑动尺寸,该窗口从上至下从左至右进行滑动,每次到达停止位置时,进行类哈尔特征级联检测,同时使用亮度积分图进行加速
补充(关于机器学习)

viola-Jones算法的特征是自己设置的,而参数是机器自己通过样本自己得到的,这一过程称为机器学习
今后还有一种算法,特征和参数都是机器学习得到的,该算法是基于深度学习构建的
深度学习十大应用
分辨率增强

分辨率增强,是在空间维度,增强画面的细腻度
帧率增强

帧率增强是在时间维度,增强视频的流畅度
色彩增强

给一张照片或者视频上色
风格迁移

图像分类

根据图像中的内容对图像进行分类
物体检测

之前的人脸检测的更优算法,就是该项的一个应用
物体分割


对物体进行检测时,能够分割出一个物体的轮廓,就是物体分割
特征检测

一个应用是判断摄像头捕捉到的是不是人脸
人脸识别

人脸识别要检测这张脸是谁的脸
物体生成

类似于,无中生有生成一张照片或者视频
神经网络
深度学习,更为详细的翻译是:基于深度神经网络的机器学习,核心在于“深度神经网络”
神经元
工作原理
简介
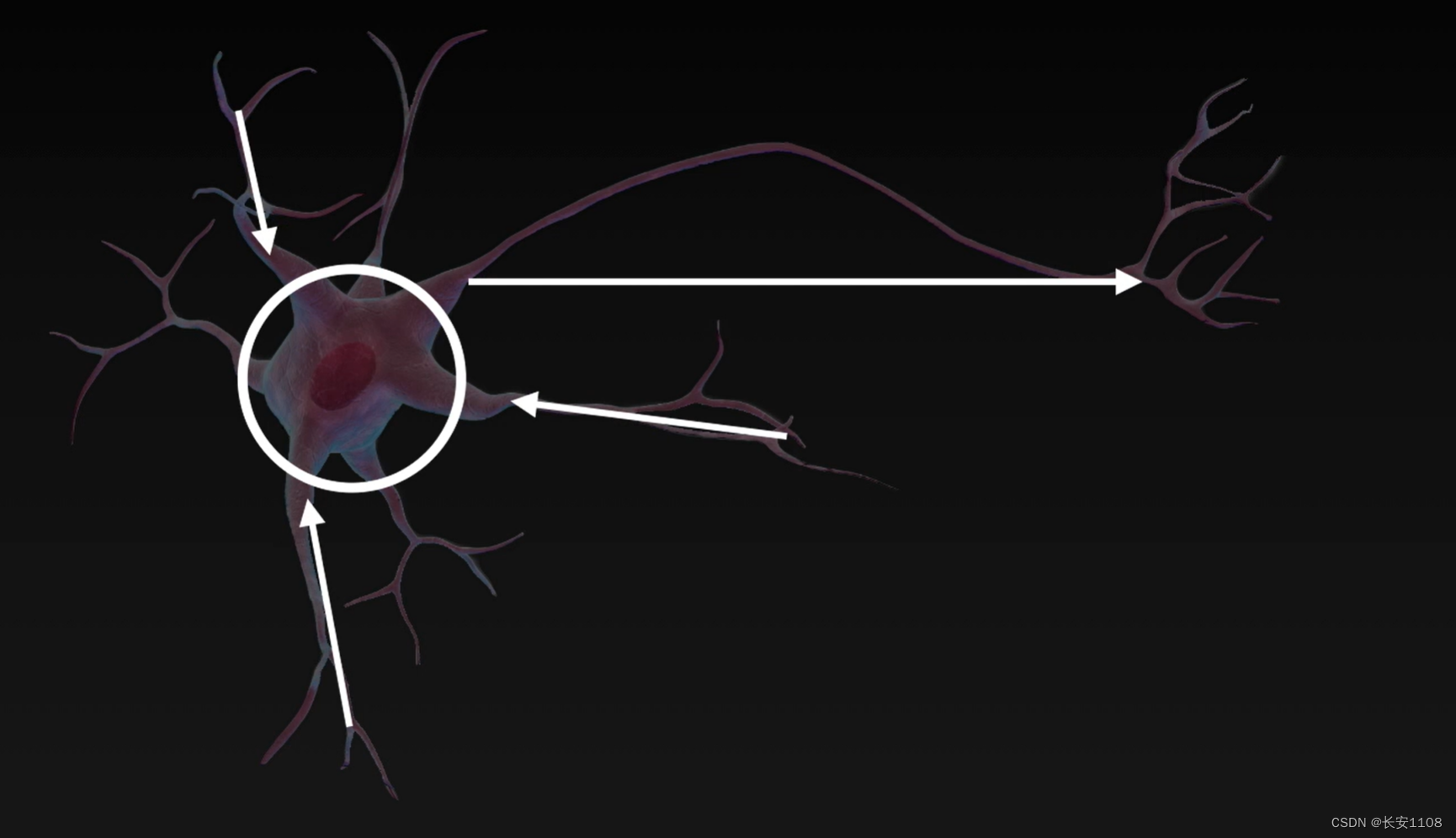
神经网络是参考生物中的神经元进行设计的,有若干个输入和一个输出
实例

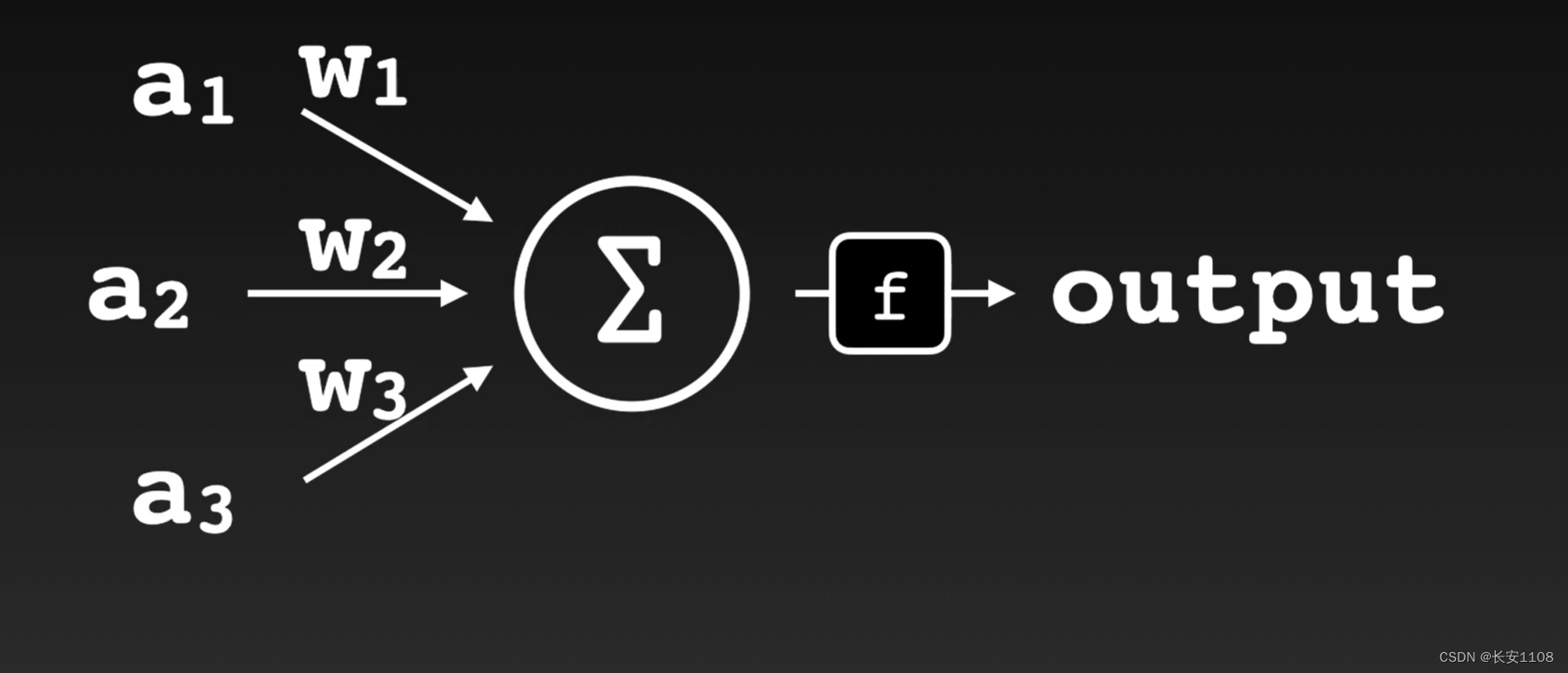
a1 a2 a3在w1 w2 w3的权重下求和,得到的值再经过f函数,会得到结果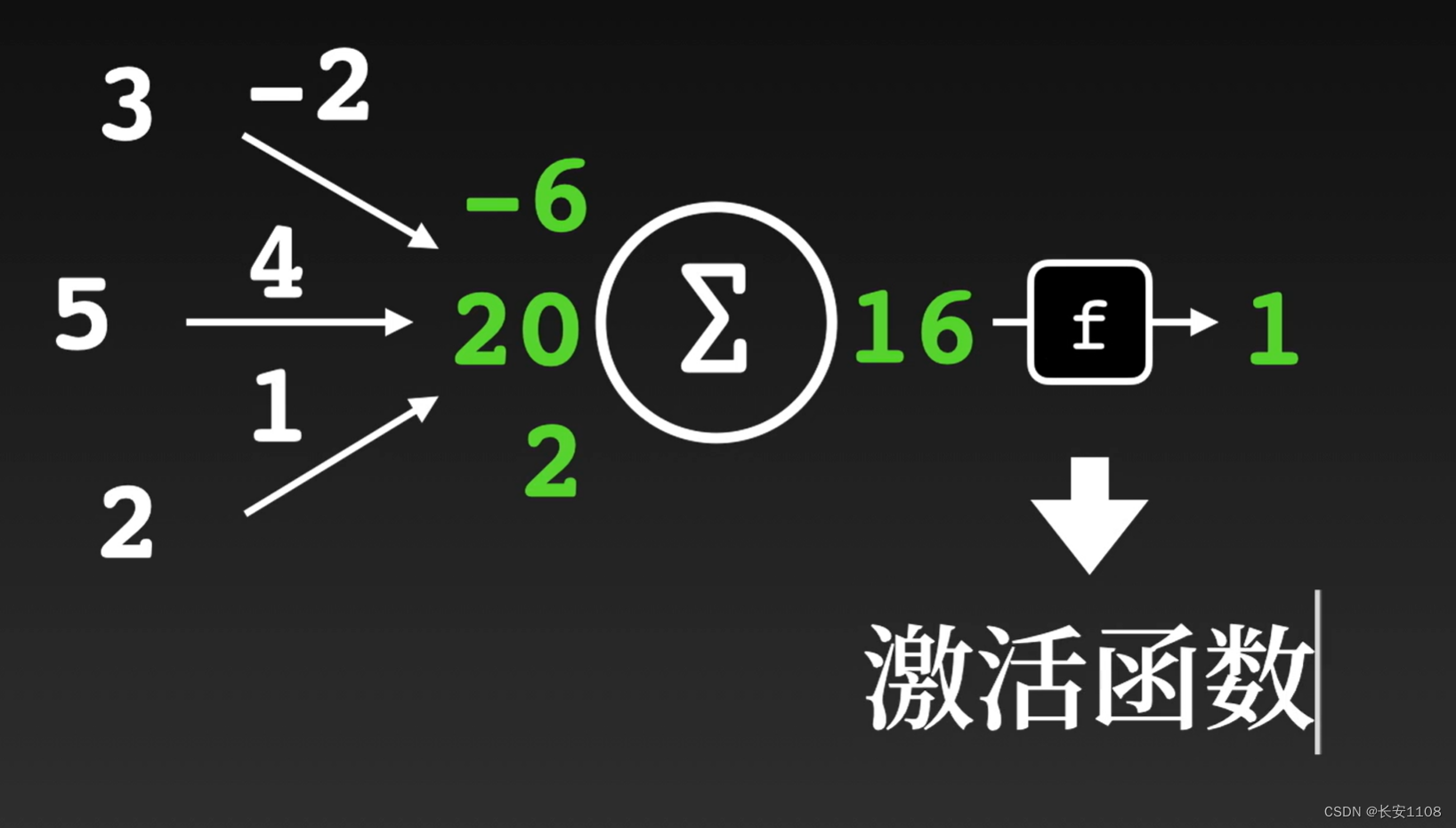
该函数称为激活函数
神经网络
简介

假设我们有五个神经元,即有五个MP模型,将其分成两组,将第一组的输出连到第二组的输入,就构成了神经网络,神经网络的关键就在于将神经元以层级的方式链接起来
两层的神经网络,只有输入层和输出层,他还有一个别称:单层感知机
深度神经网络
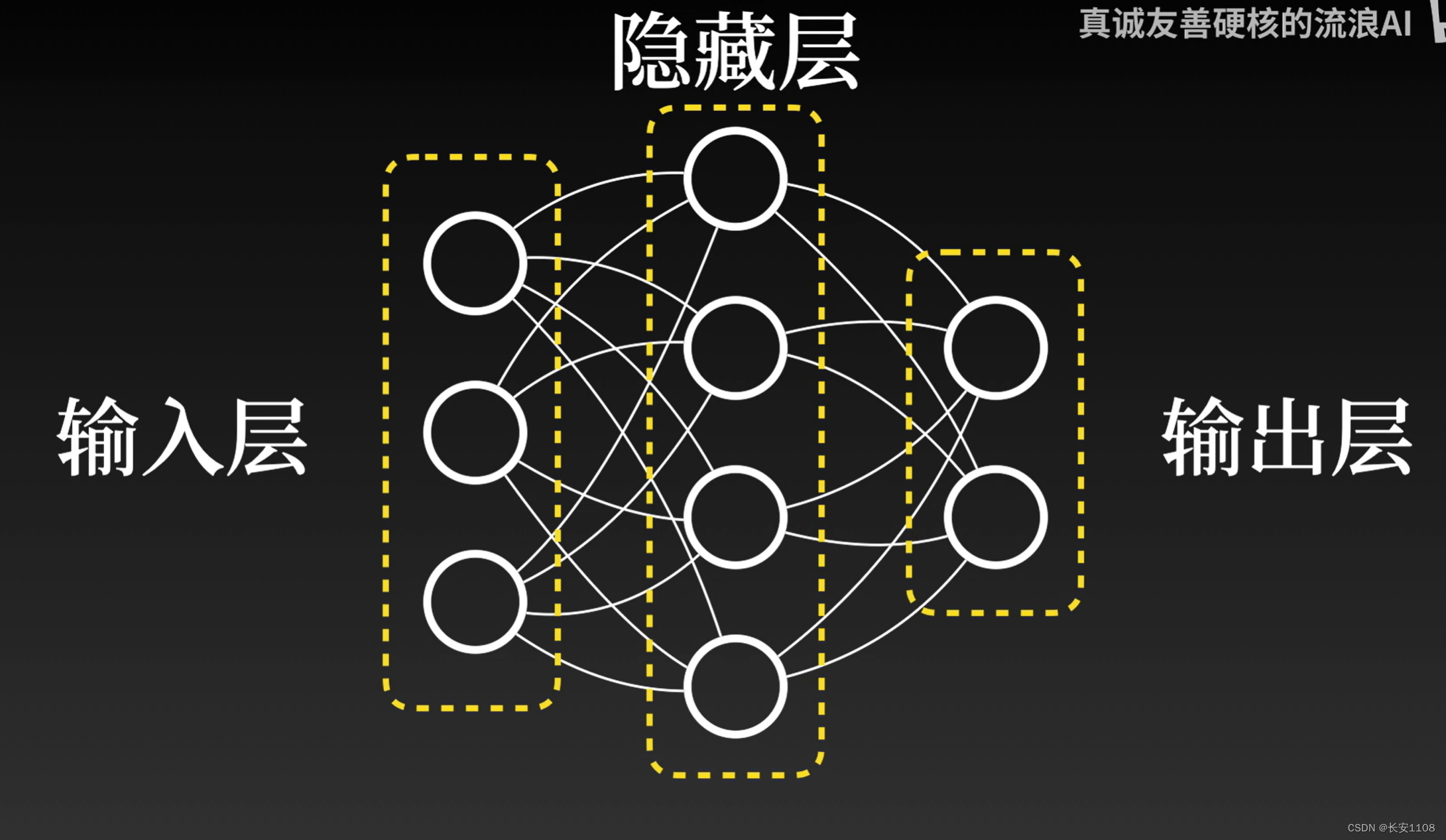
单层感知机:输入层 → 输出层(无隐藏层),只能解决线性问题
多层感知机(MLP):输入层 → 隐藏层(只1层) → 输出层,可以解决非线性问题
深度神经网络:输入层 → 隐藏层(≥2 层) → 输出层隐藏层 ≥ 2 的多层神经网络,可以解决非线性问题
单层感知机只能解决线性问题,而多层感知机、深度神经网络可以解决非线性问题
要注意:
总结


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)