【深度学习——初识神经网络代码】线性表示:恋爱次数与外貌、性格、财富、内涵的关系
一 .模型介绍
1.任务介绍
假设影响一个人恋爱次数的因素有: X1外貌,X2性格,X3财富,X4内涵
其中每个因素所占权值不同,分别为: W1 , W2 , W3 , W4
偏差为b
模型可以看作是 y = wi * xi + b (i = 1、2、3、4)
也就是
现给出一批输出X1,X2,X3,X4和y1,y2,y3,y4
推测出真实的权值w1,w2,w3,w4以及偏差b
2.原理
在深度学习简介中提到了损失Loss,这个指标是指真实值Y1与预测值y1之间的差别,通常可用两数差的绝对值或者两数差的平方表示。通过梯度下降的方式一轮一轮优化权值w和偏差b,减小Loss,从而使得模型逼近真实函数。
二.环境配置
1.框架选择(保持版本对应,否则易出BUG)
(1).PyCharm2022.1.3
(2).anaconda3 2022.10
(3).python3.8
(4).torch安装
30系以下显卡
pip install torch==1.10.1+cu102 torchvision==0.11.2+cu102
torchaudio==0.10.1 -f
https://download.pytorch.org/whl/cu102/torch_stable.html
30系以上显卡
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113
torchaudio==0.11.0 --extra-index-url
https://download.pytorch.org/whl/cu113
(5).函数包
pip install pandas
pip install matplotlib
pip install scikit-learn
三.完整代码解析
引用三个库
torch:常用的机器学习库
matplotlib.pyplot:常用于作图,使得结果可视化
random:用于随机数或者随机操作
import torch
import matplotlib.pyplot as plt#画图
import random #随机数 随机操作
训练模型需要原始数据,下面定义一个函数用来生成原始数据
其中w为每一组数据中的权值,b为偏差,data_num为生成数据的数量
首先生成x,torch.normal为创建张量
torch.matmul可以进行矩阵相乘操作,从而得到y
noise为创建噪声,模拟真实数据噪声
最终返回x,y,得到真实的数据x,y
def create_data(w,b,data_num): #自定义一个生成数据的函数
x = torch.normal(0,1,(data_num,len(w)))#形成一个平均值为0,标准差为1,形状为data_num,len(w)的张量
y = torch.matmul(x,w) + b#生成真实的结果y,matmul表示矩阵相乘
noise = torch.normal(0,0.01,y.shape)
y += noise#将y加上噪声
return x,y
真实的数据数量num为500,真实的w,真实的b,用于后续计算loss,对比模型与真实数据的差距
num = 500
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)
创建X和Y,其中X为(500,4)的数据,Y为(500),因为开始给的任务中有四种因素,故有4列,500是指生成了500个数据样本,供后面训练模型使用。使用绘图将Y与每一种X进行对比,可以看出每一种因素X与Y的大致分布关系。其中X[:,0]中的0表示第一种因素,还可以改成1,2,3,代表其他因素与Y的关系
X,Y = create_data(true_w,true_b,num)
plt.scatter(X[:,0],Y,1) #1表示点的大小,X[:,3]表示X取全部行和第3列数据,应为Y为一列数据,这样才能表示对比
plt.show()
用于批量取数据的函数,生成的X(500,4)和Y(500)是所有数据,太大了,我们希望能够一次取少量数据,这里batchsize表示步长,也就是一次取数量的数量。
这里X(500,4)表示有500个数据点,每个数据有4个特征
Y(500)表示有500个目标值,每个目标值有一个数据点
故X与Y的长度都是一样的,为500
将每个数据编号,再用random打散,做到随机取数,使得模型具有普适性。
然后再将每轮取到的数据存起来,而yield则是记录现在数取多少了,方便后续继续取数
注Python语法:get_data = data[get_indices]这里表示取data也就是X里的get_indices行数据,[get_indices,0]则变成取get_indices行,0列数据
def data_provider(data,label,batchsize):#data为x label为y batchsize处理一批表示数量(步长) 此函数表示访问一批数据
length = len(label)#求出数据有多长,data与label一样长,故填哪个都可以
indices = list(range(length))#先将length转化为一个范围,再存到数组里
#不要按顺序取
random.shuffle(indices)
for each in range(0,length,batchsize):
get_indices = indices[each:each + batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #yield表示存档点的return,下此回来可以继续上次步长位置继续向下
步长设置为16
batchsize = 16
# for batch_x, batch_y in data_provider(X,Y,batchsize):
# print(batch_x,batch_y)
#
生成预测的y
#预测的y
def fun(x,w,b):
pred_y = torch.matmul(x,w) + b
return pred_y
计算Loss
#计算loss
def maeLoss(pred_y,y):
return torch.sum(abs(pred_y-y))/len(y)
梯度下降
其中with torch.no_grad():是Pytorch自带的库函数,专用梯度计算更新参数的,它可以确保求一个偏导更新一个数据,偏导数不会累积链式回传
#梯度下降
def sgd(paras,lr): #paras为参数,自带梯度,lr为学习率
with torch.no_grad(): #属于这段代码的部分,不计算梯度
for para in paras:
para -=para.grad*lr #不能写成para = para - para.gran* lr
para.grad.zero_()#使用过的梯度归0
设计学习率lr
随机生成初始的预测w和b
lr = 0.01
w_0 = torch.normal(0,0.01,true_w.shape,requires_grad=True) #创建数据,平均值为0,方差为0.01,形状为真实的w,需要计算梯度
b_0 = torch.tensor(0.01,requires_grad=True) #b为张量,需要计算梯度
print(w_0,b_0)
进行50轮训练
每轮都是以步长16取数据,计算一次这16个数据的损失,然后更新一次w0和b0,直到把500个数据都取完,也就是每一轮都进行了500/16 次更新w0和b0,这一轮结束后打印出当前是第几轮,以及当前轮次总损失,再进行下一轮训练
其中loss.backward()是pytorch中用于计算每个w和b梯度的函数,并自动将所有信息储存到。grad中,用于下面调用sgd梯度下降函数更新参数做准备。
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x,batch_y in data_provider(X,Y,batchsize):
pred_y = fun(batch_x,w_0,b_0)
loss = maeLoss(pred_y,batch_y)#pred_y为预测的y,batch_y为真实的数据里的y
loss.backward()
sgd([w_0,b_0],lr)
data_loss += loss #将损失统计起来
print("epoch %03d: loss: %.6f"%(epoch,data_loss))#%d表示整数 03表示打印三位,.6f表示三位小数
对比真实的w、b以及模型预测的w0和b0
print("真实的函数值是",true_w,true_b)
print("训练的函数值是",w_0,b_0)
可视化对比每一种因素与结果的线性关系
idx表示四种因素中的哪一个因素xi
由于wi和xi一一对应,x和w都是(4,1),而y是一个数,图像是二维图,不能同时表示出四种因素和y的关系,故要一个一个表示,也就是更改idx的值为0,1,2,3
也就是将X改成X[:,idx]格式,但是此时还是不能打印,原因是此时数据在张量网上,张量网上的数据是不能直接打印的,故要将其从张量网上摘下来,改成X[:,idx].detach().numpy()格式
idx = 0
plt.plot(X[:,idx].detach().numpy(),X[:,idx].detach().numpy()*w_0[idx].detach().numpy()+b_0.detach().numpy())
plt.scatter(X[:,idx],Y,1)
plt.show()
至此所有代码分析完毕
下面是完整代码
import torch
import matplotlib.pyplot as plt#画图
import random #随机数 随机操作
def create_data(w,b,data_num):#自定义一个生成数据的函数
x = torch.normal(0,1,(data_num,len(w)))#形成一个平均值为0,标准差为1,形状为data_num,len(w)的张量
y = torch.matmul(x,w) + b#生成真实的结果y,matmul表示矩阵相乘
noise = torch.normal(0,0.01,y.shape)
y += noise#将y加上噪声
return x,y
num = 500
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)
X,Y = create_data(true_w,true_b,num)
plt.scatter(X[:,0],Y,1) #1表示点的大小,X[:,3]表示X取全部行和第3列数据,应为Y为一列数据,这样才能表示对比
plt.show() #X[:,~]中~为0,1,2,3表示哪一行和Y进行对比
def data_provider(data,label,batchsize):#data为x label为y batchsize处理一批表示数量(步长) 此函数表示访问一批数据
length = len(label)#求出数据有多长,data与label一样长,故填哪个都可以
indices = list(range(length))#先将length转化为一个范围,再存到数组里
#不要按顺序取
random.shuffle(indices)
for each in range(0,length,batchsize):
get_indices = indices[each:each + batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #yield表示存档点的return,下此回来可以继续上次步长位置继续向下
batchsize = 16
# for batch_x, batch_y in data_provider(X,Y,batchsize):
# print(batch_x,batch_y)
#
#预测的y
def fun(x,w,b):
pred_y = torch.matmul(x,w) + b
return pred_y
#计算loss
def maeLoss(pred_y,y):
return torch.sum(abs(pred_y-y))/len(y)
#梯度下降
def sgd(paras,lr): #paras为参数,自带梯度,lr为学习率
with torch.no_grad(): #属于这段代码的部分,不计算梯度
for para in paras:
para -=para.grad*lr #不能写成para = para - para.gran* lr
para.grad.zero_()#使用过的梯度归0
lr = 0.01
w_0 = torch.normal(0,0.01,true_w.shape,requires_grad=True) #创建数据,平均值为0,方差为0.01,形状为真实的w,需要计算梯度
b_0 = torch.tensor(0.01,requires_grad=True) #b为张量,需要计算梯度
print(w_0,b_0)
epochs = 50
for epoch in range(epochs):
data_loss = 0
for batch_x,batch_y in data_provider(X,Y,batchsize):
pred_y = fun(batch_x,w_0,b_0)
loss = maeLoss(pred_y,batch_y)#pred_y为预测的y,batch_y为真实的数据里的y
loss.backward()
sgd([w_0,b_0],lr)
data_loss += loss #将损失统计起来
print("epoch %03d: loss: %.6f"%(epoch,data_loss))#%d表示整数 03表示打印三位,.6f表示三位小数
print("真实的函数值是",true_w,true_b)
print("训练的函数值是",w_0,b_0)
idx = 0
plt.plot(X[:,idx].detach().numpy(),X[:,idx].detach().numpy()*w_0[idx].detach().numpy()+b_0.detach().numpy())
plt.scatter(X[:,idx],Y,1)
plt.show()
运行结果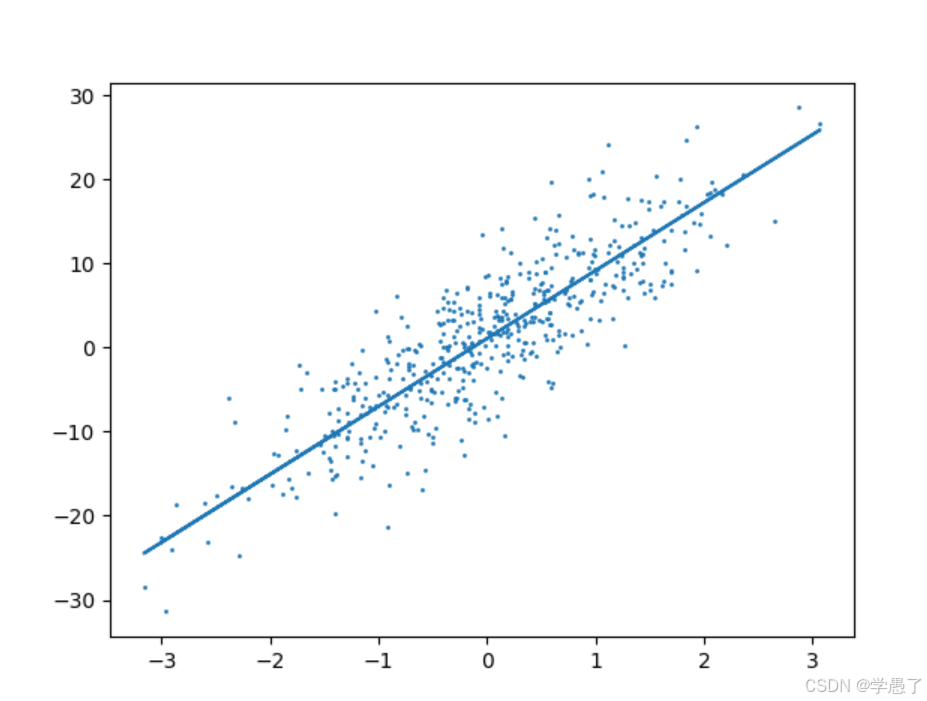

我们可以看到,在整个训练过程中,没有使用到真实值,但最终预测值与真实值非常接近,同时可以尝试更改代码中的lr(学习率,本文中给的是0.01),当lr太大或者太小都会导致最终结果很差,例如将lr改为0.3,则loss会上升到个位数。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)