深入理解阿里Druid数据库连接池
Druid是阿里巴巴开源的数据库连接池实现,提供了强大的监控功能和多种配置选项,以满足高并发场景下的性能需求。它不仅支持所有JDBC兼容的数据库,还提供了诸如SQL解析、内置的监控页面等功能,极大地提升了开发与运维的效率。Druid数据库连接池提供了丰富的内置过滤器,这些过滤器分别对应着不同的功能和用途。其中一些常见的内置过滤器包括:StatFilter: 统计数据库连接池的使用情况,为监控提供了

简介:阿里Druid是一个高性能、具备丰富监控功能和高度可扩展性的数据库连接池。它通过内置的监控统计、过滤器机制、智能连接管理、SQL解析器等,提供了对数据库连接的实时监控与管理。其设计目标是监控、扩展性和稳定性,能够在复杂企业级系统中提供优秀的性能。Druid支持多种数据库,并提供简单的配置和丰富的API,适用于快速集成和优化。 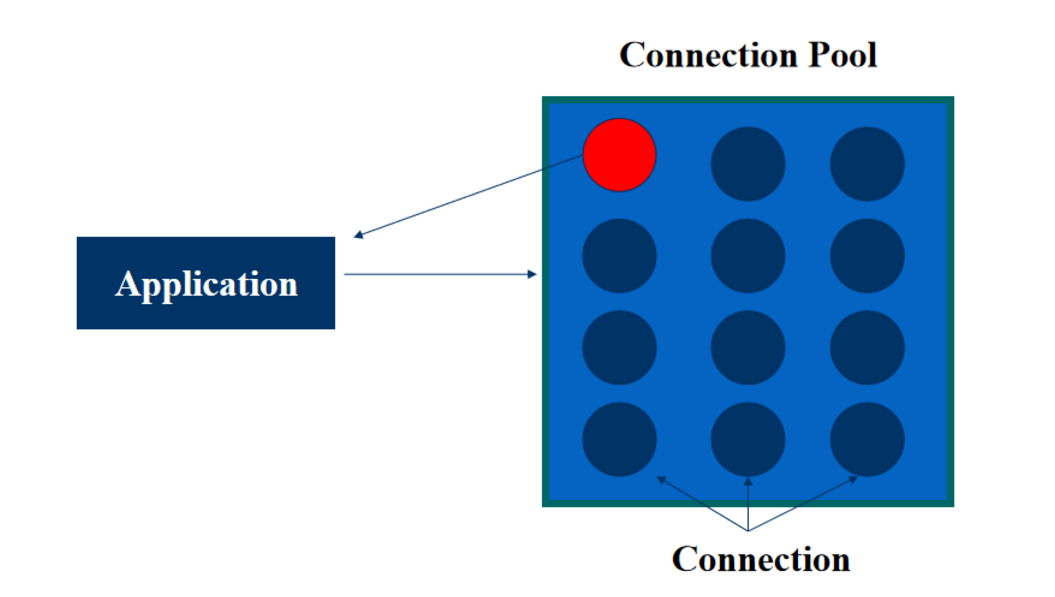
1. 阿里Druid数据库连接池概述
Druid是阿里巴巴开源的数据库连接池实现,提供了强大的监控功能和多种配置选项,以满足高并发场景下的性能需求。它不仅支持所有JDBC兼容的数据库,还提供了诸如SQL解析、内置的监控页面等功能,极大地提升了开发与运维的效率。
1.1 Druid的功能特点
Druid的核心特点之一是性能高,它采用了一系列优化手段,如池化技术、预编译语句缓存等,大幅减少数据库的I/O操作。此外,Druid还内置了强大的监控模块,为开发和运维人员提供了直观的数据库连接池使用情况。
1.2 使用场景与优势
在多线程环境下,Druid可以有效地避免因线程争抢数据库连接资源而产生的性能瓶颈。同时,Druid支持多种SQL数据库,使得它在大数据量的读写和复杂的SQL操作中表现尤为出色。凭借丰富的监控和诊断数据,Druid还可以帮助开发者快速定位和解决数据库连接问题。
2. 监控能力及实时性
2.1 Druid的监控系统架构
2.1.1 监控系统的组件和功能
阿里巴巴的Druid是一个高性能的Java数据库连接池,它不仅提供了标准的连接池功能,还内置了强大的监控功能,允许用户实时监控数据库访问性能。Druid的监控系统主要由以下几个核心组件构成:
- DruidMonitorServlet : 这是一个Servlet,用于收集监控数据,并且能够以JSON格式输出这些数据。
- DruidDataSource : 这是监控数据的主要来源,它会收集连接池的各种运行时数据。
- DruidStatManager : 这是监控管理器,负责维护和管理监控数据的收集,以及提供对外服务的接口。
- DruidWebStatFilter : 这是一个过滤器,它能够拦截Web请求,并与监控数据相结合,进行更丰富的监控展示。
监控系统能够展示出数据库连接池的使用情况,SQL执行情况,以及系统中各个连接的活动情况等关键信息。
2.1.2 实时监控数据的获取与展示
实时监控数据的获取依赖于Druid内部的统计数据,主要包括:
- JDBC统计信息 : 包括执行的SQL语句统计,慢SQL记录,以及SQL执行时间的分布。
- 连接池的使用情况 : 显示当前的活跃连接数,空闲连接数,等待连接的线程数,以及连接池的容量等信息。
- 系统资源使用情况 : 包括CPU使用率,内存使用情况,以及I/O统计信息。
这些数据可以通过Druid内置的web页面进行实时查看,如下图所示:
该页面的数据显示是通过DruidMonitorServlet提供的JSON数据动态加载的。通过这种方式,用户能够在无需添加额外的监控工具的情况下,就能快速地对数据库连接池的性能和健康状况进行实时监控。
2.2 监控信息的实时分析
2.2.1 关键性能指标的分析方法
为了确保数据库连接池性能的稳定性,我们需要对一些关键的性能指标进行实时分析,这些指标包括:
- 响应时间 : 数据库操作的响应时间对于衡量用户体验至关重要。Druid的监控系统能够显示SQL执行的平均响应时间,95%分位数等,这能帮助开发者判断性能是否符合预期。
- 活跃线程数 : 在高并发系统中,活跃线程数需要保持在一定的阈值内,以避免线程竞争太激烈导致系统性能下降。
- 连接池使用率 : 连接池的使用率过高或者过低都可能提示潜在问题,如配置不合理或系统负载异常。
针对这些指标,监控系统通常提供图表展示和数字统计,用户可以通过分析这些数据来快速定位问题。
2.2.2 异常诊断和报警机制
Druid提供的监控系统还包括异常诊断和报警机制,当检测到数据库连接池的异常时,比如:
- 连接泄露 : 当发现连接没有正确关闭,Druid会记录泄露的连接,并在监控界面中展示。
- SQL异常 : 如果某个SQL执行失败,系统会记录错误信息,并且可以设置报警,通知开发者。
- 资源竞争 : 如果长时间存在大量线程等待获取连接,监控系统会发出警报。
以下是一个简单的代码示例,演示了如何配置Druid的报警功能:
DruidDataSource dataSource = new DruidDataSource();
dataSource.setFilters("stat,wall,log4j"); // 开启监控功能
dataSource.setDruidStatPeriodSeconds(30); // 设置统计周期为30秒
dataSource.setDruidStatMaxSqlCount(1000); // 设置SQL统计最大数量
// 配置报警,发送邮件通知
DruidStatManagerFactory.statManager().setMetricRegistry(druidDataSource.getDruidStatManager());
// ...配置报警邮件发送者等相关参数
以上代码段配置了Druid的监控统计周期,以及SQL统计的最大数量,并且通过 DruidStatManagerFactory 设置了发送报警邮件的基本配置。
通过上述的监控能力及实时性分析,开发者可以获得对数据库连接池运行状况的深入洞察,并及时地采取措施,保障系统的稳定运行。
3. 过滤器机制与功能扩展
3.1 过滤器的体系结构和工作原理
3.1.1 常见的内置过滤器介绍
Druid数据库连接池提供了丰富的内置过滤器,这些过滤器分别对应着不同的功能和用途。其中一些常见的内置过滤器包括:
- StatFilter : 统计数据库连接池的使用情况,为监控提供了基础数据。
- WallFilter : 用于SQL语句的防火墙,可以有效防止SQL注入攻击。
- EncodingConvertFilter : 数据库编码转换过滤器,确保不同数据库字符编码之间能够正确转换。
- ConfigFilter : 能够返回当前Druid连接池的配置信息,便于监控与调试。
每个过滤器都有其特定的配置参数,能够满足开发者根据实际应用场景定制化的需求。
3.1.2 过滤器的链式处理机制
Druid过滤器设计的核心思想是链式处理机制。在Druid连接池中,过滤器按照配置顺序形成一个过滤器链(FilterChain)。当有SQL操作发生时,请求会沿着这个链依次经过每一个过滤器进行处理。这种机制的优点是灵活且强大,能够支持开发者在不修改Druid内部代码的情况下,通过配置添加或修改过滤器来扩展连接池的功能。
过滤器的链式处理流程可以用以下步骤简述:
- 初始化 :在Druid连接池初始化时,所有配置的过滤器实例会被创建,并按照指定的顺序加入到过滤器链中。
- 事件传递 :当有数据库操作(如执行SQL语句)发生时,事件会被传递给过滤器链的入口。
- 链式处理 :事件从过滤器链的头部开始传递,每个过滤器根据其功能对事件进行处理。
- 处理完毕 :事件处理完毕后,根据处理结果被传递到下一个过滤器或者最后的结果返回给应用。
3.2 功能扩展与自定义过滤器
3.2.1 自定义过滤器的开发步骤
开发自定义过滤器是提高Druid数据库连接池功能灵活性的有效手段。以下是开发自定义过滤器的基本步骤:
- 创建过滤器类 :继承Druid提供的Filter接口或者继承已有的过滤器类。
- 实现方法 :重写Filter接口中的方法,如
init,filter,close等。 - 配置使用 :在Druid连接池的配置文件中注册自定义过滤器,并设置相应的参数。
- 测试验证 :通过编写测试用例验证过滤器的功能和性能。
自定义过滤器的典型应用场景包括:定制化监控、SQL注入防护规则的扩展、日志记录等。
3.2.2 实例:开发一个监控慢查询的过滤器
慢查询是数据库性能优化中的一个关键点。下面展示如何开发一个监控慢查询的自定义过滤器:
步骤一:创建过滤器类
import com.alibaba.druid.filter.FilterAdapter;
import com.alibaba.druid.filter.FilterChain;
import com.alibaba.druid.proxy.jdbc.SQLStatement;
import com.alibaba.druid.support.http.WebStatFilter;
import com.alibaba.druid.util.JdbcUtils;
import com.alibaba.druid.pool.DruidPooledConnection;
import javax.servlet.http.HttpServletRequest;
import java.sql.SQLException;
public class SlowQueryFilter extends FilterAdapter {
private long slowSqlMillis; // 慢查询时间阈值
private WebStatFilter-statFilter; // 底层使用的统计过滤器
@Override
public void init(FilterConfig filterConfig) {
// 初始化过滤器需要的参数,例如慢查询阈值
this.slowSqlMillis = Long.parseLong(filterConfig.getInitParameter("slowSqlMillis"));
// 初始化底层使用的统计过滤器
this.statFilter = new WebStatFilter();
}
@Override
public boolean filter(FilterChain chain, DruidPooledConnection connection, String sql) {
long start = System.currentTimeMillis();
try {
return chain.doFilter(connection, sql); // 调用过滤器链的下一个过滤器
} finally {
long cost = System.currentTimeMillis() - start;
if (cost > slowSqlMillis) {
// 如果执行时间超过阈值,则认为是慢查询
String slowLog = String.format("Slow SQL: cost=[%d] ms, sql=[%s]", cost, sql);
// 这里可以将慢查询日志输出到文件、发送到邮件或者使用其他方式记录
System.out.println(slowLog);
}
}
}
@Override
public void close() {
// 清理资源
}
}
步骤二:在Druid配置文件中配置使用
<filter>
<filter-name>slowQueryFilter</filter-name>
<filter-class>com.example.SlowQueryFilter</filter-class>
<init-param>
<param-name>slowSqlMillis</param-name>
<param-value>5000</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>slowQueryFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
步骤三:测试验证
可以通过模拟执行一些慢查询的SQL语句来测试过滤器是否能正确地捕获并记录慢查询日志。
以上示例展示了如何创建一个基于阈值的慢查询监控过滤器。它可以通过配置参数调整慢查询阈值,并在每次数据库操作时记录执行时间超过设定阈值的查询。这种自定义过滤器的开发可以大大提高数据库连接池的功能,为开发者提供更多的监控和优化手段。
4. 高性能连接池管理
4.1 连接池的原理与配置
连接池的工作模式
连接池的工作模式主要可以理解为对象池的实现。在数据库连接的上下文中,这意味着池管理一个预创建的数据库连接集合。当应用程序需要进行数据库操作时,它从池中获取一个连接,并在使用完毕后将其返回,而不是每次都创建和销毁连接。这种模式大大减少了连接建立和销毁的开销,因为它重用了现有的连接。
连接池的主要优势在于提高了性能,确保了并发访问的稳定性和效率,同时还可以减少资源消耗。因为它限制了同时打开的连接数量,所以避免了数据库服务器过载的可能性,从而提升了系统的稳定性和可扩展性。
关键配置参数解析
配置连接池时,有几个关键的参数需要考虑,以确保其高效运行:
initialSize: 此参数决定了连接池在启动时创建的数据库连接数量。minIdle: 表示连接池保持的最小空闲连接数。maxActive: 连接池可以包含的最大数据库连接数。maxWait: 当连接资源耗尽时,连接池等待获取新连接的最大等待时间。validationQuery: 当设定此参数后,每次从连接池中获取连接时,都会执行此SQL查询,以验证连接的有效性。
例如,配置Druid连接池的 DruidDataSource 对象可以如下:
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mydb");
dataSource.setUsername("root");
dataSource.setPassword("password");
dataSource.setInitialSize(5);
dataSource.setMinIdle(5);
dataSource.setMaxActive(20);
dataSource.setMaxWait(60000);
dataSource.setValidationQuery("SELECT 1 FROM DUAL");
代码中 validationQuery 参数设置为 SELECT 1 FROM DUAL 是Oracle数据库的验证方式,其他数据库根据其SQL语法有所不同。
4.2 高效资源管理与控制
线程池的合理配置
在使用连接池时,线程池的合理配置同样重要。线程池可以管理应用程序中执行数据库操作的线程,确保它们高效、有序地访问数据库。通常,应用程序中用于数据库操作的线程数不应超过连接池中的连接数。这样可以避免因线程等待数据库连接而造成资源浪费。
合理配置线程池包括设置线程池的核心线程数和最大线程数:
- 核心线程数(
corePoolSize)是指即使线程处于空闲状态,也会保持的线程数。 - 最大线程数(
maximumPoolSize)是指线程池中最多允许存在的线程数。
例如,使用Java中的 ThreadPoolExecutor 来配置一个合理的线程池:
int corePoolSize = 10;
int maxPoolSize = 20;
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(100);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
corePoolSize,
maxPoolSize,
60L,
TimeUnit.SECONDS,
workQueue,
new ThreadPoolExecutor.CallerRunsPolicy()
);
连接池与资源限制的策略
当应用程序的数据库操作非常频繁时,连接池的配置将直接影响应用程序的性能。需要合理配置连接池的最大连接数、最大等待时间等参数以避免资源耗尽。
为了避免过度消耗系统资源,连接池通常会实现一些策略,如:
- 当连接池中的连接达到最大数时,新的请求可能会被阻塞,直到有连接被释放。
- 如果一个连接在指定的时间内无法被获取,可能会抛出异常,告知调用者获取连接失败。
- 连接使用完之后,不是立即关闭,而是返回给池中,这样其他操作可以再次利用该连接。
通过这些策略,连接池能够帮助应用程序更好地控制资源使用,提高性能,同时也保证了系统的稳定运行。
接下来,我们会探讨Druid连接池的高级特性,如SQL解析器的功能,它提供了强大的SQL语句风险防护和性能分析优化建议,这对于优化数据库性能和保障安全具有重要作用。
5. 强大的SQL解析器
5.1 SQL解析器的架构与原理
5.1.1 解析器的基本功能和应用场景
SQL解析器在数据库连接池中扮演着至关重要的角色,它的主要作用是对客户端发送到数据库服务器的SQL语句进行解析和处理。这包括但不限于检查语法的正确性、验证SQL语句的合法性、优化执行计划等。由于SQL解析器的工作是深入到SQL语句层面的,因此它也是数据库安全防御的重要组成部分,可以用来防止诸如SQL注入等攻击。
在具体应用场景上,SQL解析器被广泛应用于:
- 数据库连接池:如阿里Druid,需要对SQL语句进行准确的解析来管理连接。
- 数据库中间件:在中间件层面对SQL进行预处理和优化。
- 安全工具:用于检测SQL语句中的潜在风险,比如SQL注入攻击。
- 性能分析工具:通过解析SQL来分析和优化数据库性能。
5.1.2 SQL语句的解析流程
SQL语句的解析是一个复杂的过程,通常涉及到以下几个步骤:
- 词法分析 :将SQL语句分解为一个个的词法单元(tokens),如关键字、标识符、操作符等。
- 语法分析 :根据SQL语法结构,构建抽象语法树(AST)。
- 语义分析 :对抽象语法树中的各个节点进行语义验证,比如检查表名和字段名是否存在于数据库中。
- SQL优化 :基于数据库的统计信息,选择最优的执行路径。
- 执行计划生成 :根据优化结果生成具体的执行计划。
以Druid为例,SQL解析器不仅支持标准的SQL语法解析,还通过内置的解析规则来实现性能优化和安全性检测。在实际使用中,用户可以通过配置不同的解析规则来达到特定的目的。
5.2 SQL解析器的高级特性
5.2.1 SQL防火墙与风险防护
SQL防火墙是SQL解析器的一个重要功能,它可以帮助防御SQL注入等攻击。SQL防火墙的实现原理是基于预定义的白名单或者黑名单,对所有进来的SQL语句进行检查。如果SQL语句包含在黑名单中,或者不匹配白名单的规则,则会被阻止执行,并记录相应的日志。
Druid SQL解析器提供的SQL防火墙功能支持细粒度的控制,例如:
- 基于语句类型的控制 :可以允许或禁止特定类型的SQL操作,如DDL、DML等。
- 基于模式的控制 :支持对SQL语句中的表名、字段名等进行模式匹配。
- 基于执行时间的控制 :对于执行时间过长的SQL语句,可以设置超时限制,保证数据库的稳定性。
5.2.2 SQL语句性能分析与优化建议
性能分析是SQL解析器的另一高级特性,它通过分析SQL语句的执行计划来识别性能瓶颈。Druid解析器可以输出执行计划的详细信息,帮助开发者理解SQL语句在数据库中的执行情况。
例如,如果一个JOIN操作导致了笛卡尔积的产生,解析器会指出这一点,并建议添加适当的WHERE子句条件来限制结果集大小。性能分析过程中,解析器会考虑如下因素:
- 索引使用情况 :检查SQL语句是否有效利用了数据库索引。
- 表扫描 :识别是否有全表扫描发生,以及如何通过添加索引来避免。
- join顺序和类型 :join的顺序和类型对执行效率有很大影响,性能分析会给出建议。
- 子查询 :复杂的子查询可能会导致性能下降,解析器会尝试优化或重写查询。
在性能优化建议方面,Druid可以提供以下几种方式:
- 自动优化 :根据数据库的统计信息,自动选择更优的查询路径。
- 人工干预 :允许开发者手动调整SQL语句或索引策略。
- 执行计划对比 :对比不同SQL语句的执行计划,找到最优解。
通过这些高级特性,SQL解析器在保证数据库安全的同时,也显著提升了数据库操作的效率。
6. 连接有效性检测策略
6.1 检测策略的基本原理
6.1.1 验证连接的健康状态
在数据库连接池的使用中,确保连接的有效性是保障应用性能和稳定运行的关键。在Druid数据库连接池中,连接的有效性检测策略是通过一系列的健康检查机制来实现的。这些机制主要包括:
- 基于SQL的检测 :通过定期执行预设的SQL命令(如
SELECT 1),以确定连接是否仍然活跃。 - 基于时间的检测 :通过设置超时时间来判断连接是否已经过期,以及是否可以被重用。
- 基于错误计数的检测 :如果连接发生了一定数量的错误,则将其标记为不可用。
在Druid中,这些检测可以在初始化连接或者获取连接时执行。此外,当连接池中的连接处于空闲状态时,也会周期性地进行这些检测,以确保连接池中的连接始终处于可用状态。
6.1.2 配置与调整检测参数
检测参数的配置和调整对于连接池的性能和资源利用效率至关重要。在Druid连接池中,可以通过以下属性进行设置:
validationQuery:定义用于检测连接有效性的SQL语句。validationQueryTimeout:设置检测SQL执行的超时时间。testOnBorrow、testOnReturn、testWhileIdle:分别在借用连接、归还连接和空闲时进行健康检测。
通过这些参数的合理配置,可以确保连接池的性能,同时避免因频繁的检测而导致的资源浪费。例如,如果将 testWhileIdle 设置为 true ,则连接池会在空闲时不断检测连接的健康状态,这可能会带来额外的性能开销,但如果设置为 false ,则可能会出现使用到失效连接的风险。
# Druid连接池配置示例
validationQuery=SELECT 1 FROM DUAL
validationQueryTimeout=3000
testOnBorrow=true
testOnReturn=false
testWhileIdle=true
6.2 高级检测与故障转移
6.2.1 基于心跳的高级检测机制
高级检测机制通常涉及到实时监控连接状态,并在连接出现问题时进行自动的恢复尝试。心跳检测是一种较为常见的高级检测手段。通过发送心跳信号(通常是一个极简单的数据库查询),系统可以判断数据库服务是否仍然可用,以及连接是否仍然有效。
在Druid连接池中,可以通过配置 keepAlive 参数来启用心跳检测,该参数定义了当连接空闲超过指定时间后,是否需要发送心跳检测SQL以确认连接的有效性。如果连接失效,连接池会尝试重新获取一个新的有效连接。
# Druid连接池心跳检测配置
keepAlive=true
timeBetweenEvictionRunsMillis=30000
6.2.2 故障转移机制的实现与优化
故障转移是指在检测到某个数据库实例或连接出现问题时,系统能够自动切换到备用的数据库实例或连接。在Druid中,故障转移机制通常与高可用数据库配置一起使用,比如通过配置多个数据源来实现。
实现故障转移的关键在于合理配置连接池与备用数据源,并确保在发生故障时能够自动切换到备用数据源。此外,还需要优化故障转移的策略,比如设置合理的检测频率和重试次数,以避免频繁切换导致的性能问题。
// 示例代码片段,展示如何在代码中配置故障转移机制
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://primary_host:3306/db");
dataSource.setUsername("user");
dataSource.setPassword("password");
// 配置备用数据源
DruidDataSource standbyDataSource = new DruidDataSource();
standbyDataSource.setUrl("jdbc:mysql://standby_host:3306/db");
standbyDataSource.setUsername("user");
standbyDataSource.setPassword("password");
// 添加到数据源组中
GroupedDataSource groupedDataSource = new GroupedDataSource();
groupedDataSource.addDataSource("primary", dataSource);
groupedDataSource.addDataSource("standby", standbyDataSource);
// 在获取连接时,如果primary数据源失败,则会自动重试standby数据源
DataSource actualDataSource = groupedDataSource.getDataSource("primary");
Connection conn = actualDataSource.getConnection();
在这个示例中,如果primary数据源连接失败,GroupedDataSource将自动尝试从standby数据源获取连接,从而实现故障转移。
总结而言,连接有效性检测策略是保证数据库连接池可靠性和稳定性的基石。合理配置检测参数,并结合心跳检测和故障转移机制,可以显著提升系统的容错能力和用户体验。
7. 平滑扩容与系统稳定性
在现代的高并发应用中,系统的可伸缩性和稳定性是衡量架构能力的关键指标。为了满足不断变化的业务需求,数据库连接池也需要提供平滑的扩容机制以应对负载的增减。在本章中,我们将探讨如何通过Druid实现平滑扩容以及保障系统稳定性的策略。
7.1 扩容机制的工作原理
7.1.1 动态扩容的触发条件
动态扩容通常由以下几个触发条件引起:
- 请求量增加 :当系统接收到的请求量显著增加,导致连接池中的连接数达到上限时,需要动态增加连接池中的连接数。
- 响应时间增加 :系统监控到响应时间超过设定阈值时,可能需要增加更多的连接来分散负载,减少单个连接的处理压力。
- 系统资源监控 :当CPU、内存等资源使用率超过安全阈值,系统可能需要更多连接来分散资源使用,避免资源瓶颈。
7.1.2 扩容过程中的资源平衡
在扩容过程中,需要保证系统资源的平衡,避免由于扩度过快导致的资源争抢或耗尽。Druid提供了多种机制来实现资源平衡:
- 最小/最大连接数配置 :通过设定最小和最大连接数,可以控制动态扩容的范围。
- 空闲连接预检 :Druid在创建连接前会先进行空闲连接的预检,确保增加的连接是可用的。
- 慢启动策略 :在连接池刚扩容后,采用慢启动的策略,避免瞬时大量连接给系统带来的冲击。
7.2 保证系统稳定性的策略
7.2.1 系统压力测试与评估
进行系统压力测试是确保系统稳定性的关键步骤。Druid支持通过压力测试工具模拟高并发场景,监控系统表现,以此来评估系统在极端情况下的稳定性和性能:
- 模拟高并发场景 :使用压力测试工具模拟用户访问高峰,观察系统的处理能力和响应时间。
- 性能监控指标 :关注CPU、内存、线程数等关键指标,在压力测试中评估系统的瓶颈。
- 稳定性评估报告 :根据测试结果输出报告,总结系统表现,为后续优化提供依据。
7.2.2 稳定性保障与应急预案设计
为了保障系统在扩容过程中的稳定性,需要提前设计应急预案,确保能够快速响应可能发生的各种情况:
- 应急预案制定 :预先制定好各种情况下的应对措施,比如自动扩容失败、数据库服务故障等。
- 切换到备用系统 :当主系统发生故障时,能够迅速切换到备用系统,确保服务的连续性。
- 回滚机制 :如果扩容操作造成系统不稳定或性能下降,应有快速回滚到扩容前状态的机制。
系统的可伸缩性和稳定性是确保服务不中断、用户体验良好的基础。通过Druid的高级特性,我们能够灵活地对数据库连接池进行平滑扩容,同时通过持续的监控、压力测试和应急预案设计来保证系统的整体稳定性。在这一过程中,对Druid内部机制的深入理解和优化显得至关重要。接下来的章节将详细介绍如何进一步优化Druid的配置,以实现最优的性能表现。
简介:阿里Druid是一个高性能、具备丰富监控功能和高度可扩展性的数据库连接池。它通过内置的监控统计、过滤器机制、智能连接管理、SQL解析器等,提供了对数据库连接的实时监控与管理。其设计目标是监控、扩展性和稳定性,能够在复杂企业级系统中提供优秀的性能。Druid支持多种数据库,并提供简单的配置和丰富的API,适用于快速集成和优化。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)