oracle数据库---视图、物化视图、序列、同义词、索引
视图是一种数据库对象,是从一个或者多个数据表或视图中导出的虚表,视图所对应的数据并不真正地存储在视图中,而是存储在所引用的数据表中,视图的结构和数据是对数据表进行查询的结果。一个视图所存储的并不是数据,而是一条预定义】SQL语句。根据创建视图时给定的条件,视图可以是一个数据表的一部分,也可以是多个基表的联合,它存储了要执行检索的查询语句的定义,以便在引用该视图时使用。使用视图的优点:1.简化数据操
思维导图


视图
什么是视图
视图是一种数据库对象,是从一个或者多个数据表或视图中导出的虚表,视图所对应的数据并不真正地存储在视图中,而是存储在所引用的数据表中,视图的结构和数据是对数据表进行查询的结果。一个视图所存储的并不是数据,而是一条【预定义】SQL语句。
根据创建视图时给定的条件,视图可以是一个数据表的一部分,也可以是多个基表的联合,它存储了要执行检索的查询语句的定义,以便在引用该视图时使用。
使用视图的优点:
1.简化数据操作:视图可以简化用户处理数据的方式。
2.着重于特定数据:不必要的数据或敏感数据可以不出现在视图中。
3.视图提供了一个简单而有效的安全机制,可以定制不同用户对数据的访问权限。
4.提供向后兼容性:视图使用户能够在表的架构更改时为表创建向后兼容接口。
创建或修改视图语法
CREATE [OR REPLACE] [FORCE] VIEW view_name
AS
subquery
[WITH CHECK OPTION ]
[WITH READ ONLY]选项解释:
|
OR REPLACE |
若所创建的试图已经存在,ORACLE 自动重建该视图 |
|
FORCE |
不管基表是否存在 ORACLE 都会自动创建该视图 |
|
subquery |
一条完整的 SELECT 语句,可以在该语句中定义别名; |
|
WITH CHECK OPTION |
插入或修改的数据行必须满足视图定义的约束; |
|
WITH READ ONLY |
该视图上不能进行任何 DML 操作 |
删除视图语法
DROP VIEW view_name案例
简单视图的创建与使用
什么是简单视图?如果视图中的语句只是单表查询,并且没有聚合函数,我们就称之为简单视图。
需求:创建视图:业主类型为 1 的业主信息
语句:
create or replace view view_owners1 as
select * from t_owners where ownertypeid=1利用该视图进行查询
select * from view_owners1 where addressid=1;结果如下:

就像使用表一样去使用视图就可以了。
对于简单视图,我们不仅可以用查询,还可以增删改记录。
我们下面写一条更新的语句,试一下:
update view_owners1 set name='王刚' where id=2;再次查询:
select * from view_owners1;查询结果如下:

结果已经更改成功。
我们再次查询表数据(注意:记得提交事务)
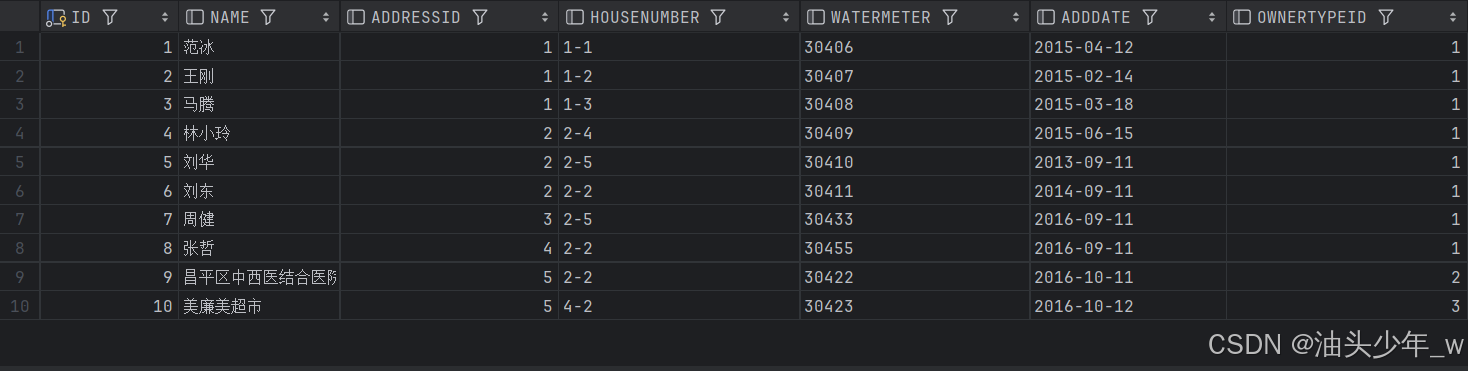
发现表的数据也跟着更改了。由此我们得出结论:视图其实是一个虚拟的表,它的数据其实来自于表。如果更改了视图的数据,表的数据也自然会变化,更改了表的数据,视图也自然会变化。一个视图所存储的并不是数据,而是一条 SQL 语句。
案例
|
-- todo 1 创建视图: 查询 区域类型为2的地址信息 |
实现
-- todo 1 创建视图: 查询 区域类型为 2 的地址信息
create or replace view view_addr
as
select * from T_ADDRESS
where AREAID=2;
-- todo 2 使用视图 查询 区域类型为2的地址信息
select * from view_addr;
-- todo 3 修改视图的列值 存在
update view_addr set name='霍营地铁站' where id=5;
commit;
-- todo 4 修改视图的列值 不存在
update view_addr set name='流星花园' where id=1;
commit;
-- todo 5 验证
select * from view_addr;
select * from T_ADDRESS;带检查约束的视图
需求:根据地址表( T_ADDRESS)创建视图 VIEW_ADDRESS2 , 内容为区域 ID 为 2 的记录。
重点:(with check option)
语句:
create or replace view view_address2 as
select * from T_ADDRESS where areaid=2
with check option;执行下列更新语句:
update view_address2 set areaid=1 where id=4;系统提示如下错误信息。因为前面我们在创建视图时指定了witch check option关键字,这也就是说,更新后的每一条数据仍然要满足创建视图时指定的where条件,所以我们这里发生了错误ORA-01402。

案例
|
-- todo 1 创建视图: 查询 区域类型为 3 的地址信息, 携带 with check option |
实现
-- todo 1 创建视图: 查询 区域类型为 3 的地址信息, 携带 with check option
create or replace view view_addr_2
as
select * from T_ADDRESS
where areaid=3
with check option;
-- todo 2 使用视图 查询 区域类型为 3 的地址信息
select * from view_addr_2;
-- todo 3 修改视图的列值 name=新值, 是否报错?
update view_addr_2 set name='霍营地铁站' where id=6;
commit;
-- todo 4 修改视图的列值 areaid=新值, 是否报错?
update view_addr_2 set areaid=4 where id=6;
commit;
-- todo 5 验证
select * from view_addr_2;
select * from T_ADDRESS;只读视图的创建与使用
如果我们创建一个视图,并不希望用户能对视图进行修改,那我们就需要创建视
图时指定 WITH READ ONLY 选项,这样创建的视图就是一个只读视图。
需求:将上边的视图修改为只读视图
重点:(with read only)
语句:
create or replace view view_owners1 as
select * from T_OWNERS where ownertypeid=1
with read only;修改后,再次执行 update 语句,会出现如下错误提示
update view_owners1 set name='和珅' where id=2;
案例
|
-- todo 1 创建视图: 查询 区域类型为 3 的地址信息, 只读 |
实现
-- todo 1 创建视图: 查询 区域类型为 3 的地址信息, 只读
create or replace view view_addr_3
as
select * from T_ADDRESS
where areaid=3
with read only;
-- todo 2 使用视图 查询 区域类型为 3 的地址信息
select * from view_addr_3;
-- todo 3 修改视图的列值 name=新值, 是否报错?
update view_addr_3 set name='西三期' where id=7;
commit;创建带错误的视图
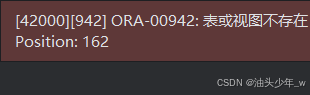
我们创建一个视图,如果视图的 SQL 语句所设计的表并不存在,如下
create or replace view view_temp as
select * from t_temp;T_TEMP 表并不存在,此时系统会给出错误提示
有的时候,我们创建视图时的表可能并不存在,但是以后可能会存在,我们如果
此时需要创建这样的视图,需要添加 FORCE 选项,SQL 语句如下:
create or replace force view view_temp as
select * from t_temp; -- [不存在]此时视图创建成功。
此时虽然视图创建成功了,但查询的时依然会报错,如图:

但如果创建相对应的表,重新查询视图,视图依然可以找到
复杂视图的创建与使用
所谓复杂视图,就是视图的 SQL 语句中,有聚合函数或多表关联查询。
我们看下面的例子:
多表关联查询的例子
需求:创建视图,查询显示业主编号,业主名称,业主类型名称
语句:
create or replace view view_owners as
select o.id 业主编号, o.name 业主名称, ot.name 业主类型
from t_owners o, t_ownertype ot
where o.ownertypeid=ot.id;使用该视图进行查询
select * from view_owners;那这个视图能不能去修改数据呢?
我们试一下下面的语句:
update view_owners set 业主名称='范小冰' where 业主编号=1;可以修改成功。
我们再试一下下面的语句:
update view_owners set 业主类型='普通居民' where 业主编号=1; -- 高版本不会报错。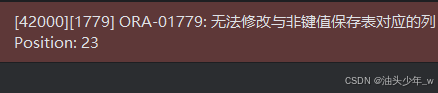
当对复杂视图进行update时, 容易会出现ora-01779错误, 这个错误是因为要修改的字段在视图中不能保证物理上唯一,多出现在与多表关联时, 一个表因与另一个表的关联, 原表中的字段产生了多条记录的原故. 具体可以见 http://forums.oracle.com/forums/message.jspa?messageID=1266445
分组聚合统计查询的例子
需求:创建视图,按年月统计水费金额,效果如下
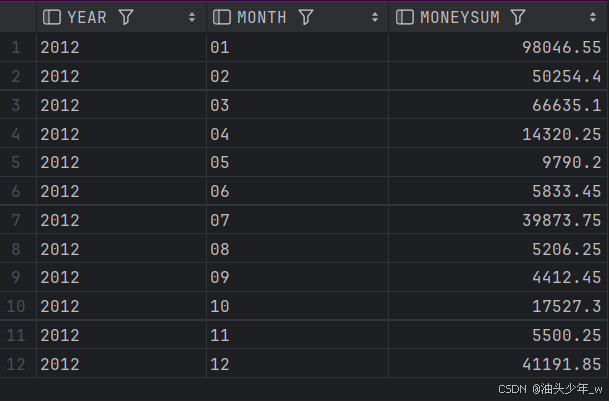
语句:
create view view_accountsum as
select year,month,sum(money) moneysum
from t_account
group by year, month
order by year, month;
select * from view_accountsum;那这个视图能不能去修改数据呢?
update view_accountsum set year='2023' where month='01'发现修改失败。
此例用到聚合函数,没有键保留表,所以无法执行 update 。
案例
|
-- todo 1 创建视图: 查询 地址id, 地址名称, 区域名称 |
实现
-- todo 1 创建视图: 查询 地址id, 地址名称, 区域名称
create or replace view view_addr_area
as
select
t1.id,
t1.name ad_name,
t2.name ar_name
from T_ADDRESS t1, T_AREA t2
where t1.AREAID=t2.ID;
-- todo 2 查询视图内容
select * from view_addr_area;
-- todo 3 修改 地址名称
update view_addr_area set ad_name='流行花园' where id=1;
-- todo 4 修改 区域名称
update view_addr_area set ar_name='海淀区' where id=1;
-- todo 5 创建视图2: 在地址表 查询每个区域的地址数量
create or replace view view_addr_2
as
select
t1.areaid,
(select name from t_area t2 where t1.AREAID=t2.ID) area_name,
count(1) as cnt
from T_ADDRESS t1
group by t1.areaid;
select * from view_addr_2;
-- todo 6 修改 视图的区域值
update view_addr_2 set area_name='海淀' where areaid=1;
-- todo 7 修改 视图的数量值
update view_addr_2 set cnt=666 where areaid=1;物化视图
什么是物化视图
视图是一个虚拟表(也可以认为是一条语句),基于它创建时指定的查询语句返回的结果集。每次访问它都会导致这个查询语句被执行一次。为了避免每次访问都执行这个查询,可以将这个查询结果集存储到一个物化视图(也叫实体化视图)。
物化视图与普通的视图相比的区别是物化视图是建立的副本,它类似于一张表,需要占用存储空间。
而对一个物化视图查询的执行效率与查询一个表是一样的。
创建物化视图语法
create materialized view view_name
[build immediate | build deferred ]
refresh [fast|complete|force]
[
on [commit | demand ] | start with (start_time) next
(next_time)
]
as
subquery- BUILD IMMEDIATE 是在创建物化视图的时候就生成数据
- BUILD DEFERRED 则在创建时不生成数据,以后根据需要再生成数据。
- 默认为 BUILD IMMEDIATE。
- 刷新( REFRESH ):指当基表发生了 DML 操作后,物化视图何时采用哪种方式和基表进行同步。
- REFRESH 后跟着指定的刷新方法有三种:FAST、COMPLETE、FORCE。
- FAST 刷新采用增量刷新,只刷新自上次刷新以后进行的修改。
- COMPLETE 刷新对整个物化视图进行完全的刷新。
- 如果选择 FORCE 方式,则 Oracle 在刷新时会去判断是否可以进行快速刷新,
- 如果可以则采用 FAST 方式,否则采用 COMPLETE的方式
- FORCE 是默认的方式。
- 刷新的模式有两种:ON DEMAND 和 ON COMMIT 。
- ON COMMIT 指在基表发生 COMMIT 操作时自动刷新。
- ON DEMAND 指需要 手动刷新物化视图(默认)。
删除物理视图语法
drop materialized view mv_address3;案例
创建手动刷新的物化视图
需求:查询地址 ID,地址名称和所属区域名称, 结果如下:
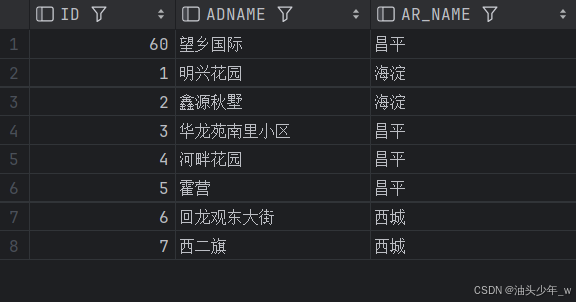
语句:
create materialized view mv_address
as
select ad.id, ad.name adname, ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id;执行上边的语句后查询
select * from mv_address查询结果如下:
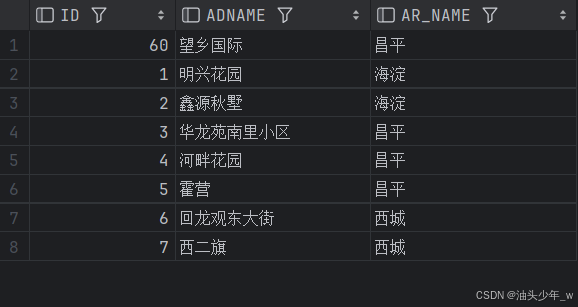
这时,我们向地址表( T_ADDRESS)中插入一条新记录,
insert into t_address values(8,'宏福苑小区',1,1);
select * from mv_address;再次执行上边的语句进行查询,会发现新插入的语句并没有出现在物化视图中。
我们需要通过下面的语句(PL/SQL),手动刷新物化视图:
begin
dbms_mview.refresh('mv_address','C');
end;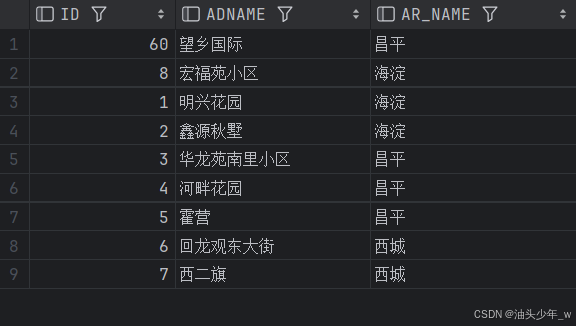
创建自动刷新的物化视图,和上例一样的结果集
需求: 当 T_ADDRESS 表发生变化时,物化视图 自动跟着改变。重点(on commit)
语句如下:
create materialized view mv_address2
refresh
on commit
as
select ad.id,ad.name adname,ar.name ar_name
from t_address ad, t_area ar
where ad.areaid=ar.id;创建此物化视图后,当 T_ADDRESS 表发生变化时,MV_ADDRESS2 自动跟着改变。
创建时不生成数据的物化视图
重点:(build deferred)
create materialized view mv_address3
build deferred
refresh
on commit
as
select ad.id,ad.name adname,ar.name ar_name
from t_address ad,t_area ar
where ad.areaid=ar.id;创建后执行下列语句查询物化视图
select * from mv_address3;查询结果:

执行下列语句生成数据
begin
dbms_mview.refresh('MV_ADDRESS3','C');
end;再次查询,得到结果:
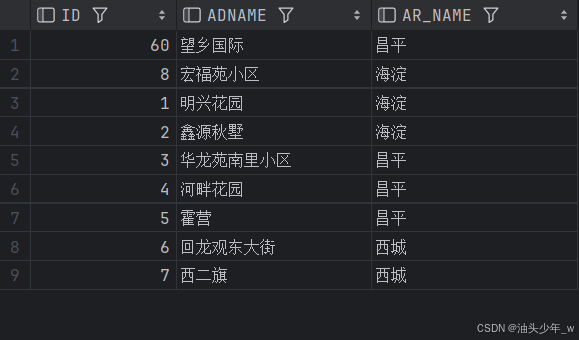
由于我们创建时指定的 on commit ,所以在修改数据后能立刻看到最新数据,无须再次执行 refresh
-- 插入一条数据然后提交--观察是否有数据进入物化视图。-- 延期视图必须手动刷新。才会有数据。
insert into t_address values(10,'中粮海景壹号2',1,1);
commit ;
-- 刷新后再插入--验证自动刷新是否成功。。。
insert into t_address values(11,'中粮海景壹号3',1,1);
commit ;创建增量刷新的物化视图
如果创建增量刷新的物化视图,必须首先创建物化视图日志记录基表发生了哪些变化,用这些记录去更新物化视图 要基于基表的rowid创建视图日志,视图中的查询语句中要有每张基表的rowid字段。
create materialized view log on t_address with rowid;
create materialized view log on t_area with rowid;创建的物化视图日志名称为 MLOG$_表名称

创建物化视图
create materialized view mv_address4
refresh fast
as
select ad.rowid adrowid, ar.rowid arrowid, ad.id,ad.name adname,ar.name ar_name
from t_address ad, t_area ar
where ad.areaid=ar.id;注意:创建增量刷新的物化视图,必须:
1. 创建物化视图中涉及表的物化视图日志。
2. 在查询语句中,必须包含所有表的 rowid ( 以 rowid 方式建立物化视图日志 )
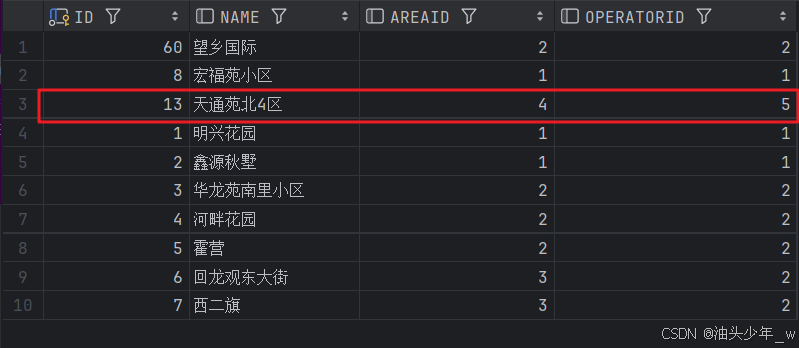
当我们向地址表插入数据后,物化视图日志的内容:
insert into t_address values(11, '天通苑北4区', 4, 5);
SNAPTIME$$:用于表示刷新时间。
DMLTYPE$$:用于表示 DML 操作类型,I 表示 INSERT ,D 表示 DELETE ,U 表示 UPDATE。
OLD_NEW$$:用于表示这个值是新值还是旧值。 N(EW)表示新值,O( LD ) 表示旧值,U 表示 UPDATE 操作。
CHANGE_VECTOR$$:表示修改矢量,用来表示被修改的是哪个或哪几个字段。
此列是 RAW 类型,其实 Oracle 采用的方式就是用每个 BIT 位去映射一个列。
插入操作显示为:FE, 删除显示为:OO, 更新操作则根据更新字段的位置而显示不同的值。
当我们手动刷新物化视图后,物化视图日志被清空,物化视图更新。
begin
DBMS_MVIEW.refresh('MV_ADDRESS4','C');
end;再次查询,得到结果:
案例1
|
-- todo 1 增加物化视图日志 |
实现
-- todo 1 增加物化视图日志
drop materialized view log on T_ADDRESS;
create materialized view log on T_ADDRESS with rowid;
create materialized view log on T_AREA with rowid;
-- todo 2 创建增量物化视图: 地址id 地址名称 区域名称
create materialized view mv_addr_5
refresh fast
as
select
t1.ROWID as addr_rowid,
t2.ROWID as area_rowid,
t1.id,
t1.name addr_name,
t2.name area_name
from T_ADDRESS t1, T_AREA t2
where t1.AREAID=t2.id
;
-- todo 3 添加一个新的地址
insert into T_ADDRESS values(10, '天通苑4区', 2, 1);
commit;
delete from T_ADDRESS where id=8;
delete from T_ADDRESS where id=9;
commit;
-- todo 4 查看日志
-- todo 5 刷新
begin
DBMS_MVIEW.refresh('mv_addr_5','C');
end;
-- todo 6 验证
select * from mv_addr_5;创建全量刷新的物化视图
介绍
全量刷新(Full Refresh)是指在数据库中更新物化视图(Materialized View)时,从源表或基础事实表中获取所有数据,并将这些最新数据复制到视图中。这通常发生在视图第一次创建、视图结构发生变化或者是定期执行计划的时候。
物化视图是一种预先计算和存储的结果集,可以提高查询性能,因为对于频繁读取的数据,可以直接从视图获取而无需每次都从原始表中重新计算。然而,全量刷新意味着每次刷新都需要消耗较多的资源,因为它涉及到大量的数据传输和可能的排序操作。
案例
|
-- todo 1 创建全量物化视图: 统计每个区域的地址数量 |
实现
-- todo 1 创建全量物化视图: 统计每个区域的地址数量
create materialized view mv_addr_7
refresh
on commit
as
select
areaid,
count(1) as cnt
from t_address
group by areaid;
-- todo 2 添加数据 测试
insert into T_ADDRESS values(11, '天通苑5区', 2, 1);
commit;
-- 3 验证
select * from mv_addr_6;全量刷新的物化视图和自动刷新的物化视图的区别
全量刷新的物化视图(Materialized View)是指每次需要查询时,都会从其源表中提取完整数据并存储到视图中。这通常发生在首次创建或手动触发时。如果源表的数据发生变化,再次查询物化视图时,会重新进行全量计算,因此可能会消耗较多时间和资源。
而自动刷新的物化视图则是定期或基于特定条件(如时间间隔、数据量变化等)自动更新的。它并非实时同步源表的最新数据,而是按照预设策略周期性地进行刷新,减少了对性能的影响,适合于对实时性要求不高的场景。当源表数据改变时,物化视图不会立即更新,只有到了预定的时间点才会执行刷新操作。
两者的主要区别在于更新频率和响应实时性上。全量刷新提供最新的数据,但可能导致更高的延迟;自动刷新则可以降低资源占用,但可能存在一定的数据一致性偏差。
序列
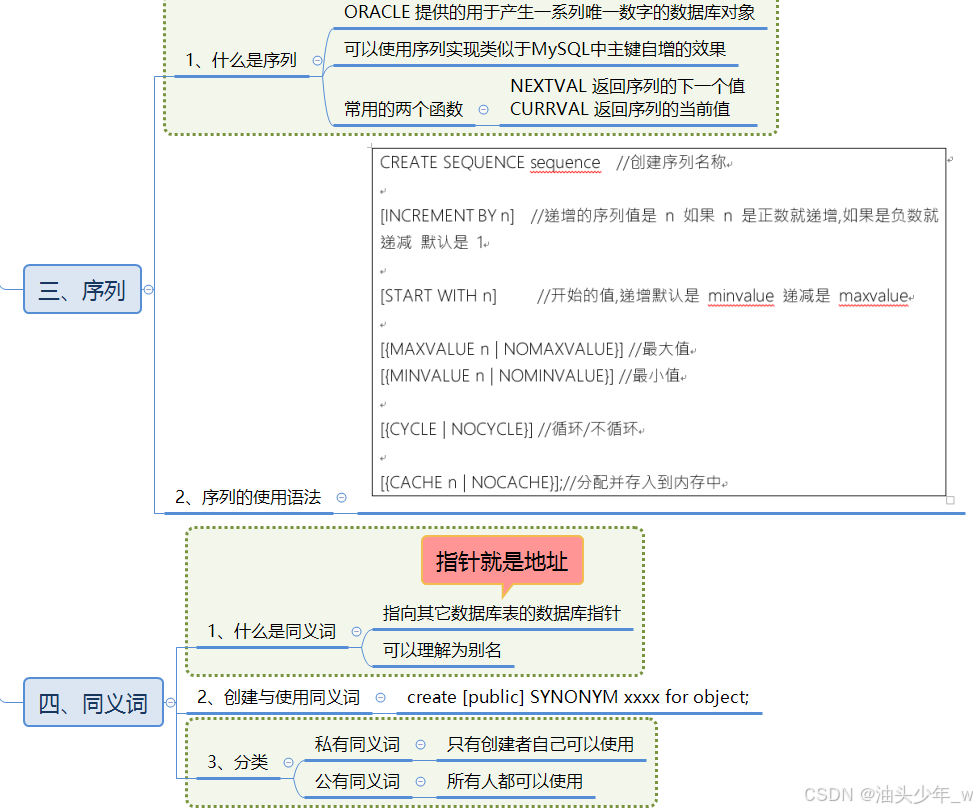
什么是序列
序列是 ORACLE 提供的用于产生一系列唯一数字的数据库对象。
创建与使用简单序列
创建序列语法:
create sequence 序列名称通过序列的伪列来访问序列的值
NEXTVAL 返回序列的下一个值
CURRVAL 返回序列的当前值
注意:我们在刚建立序列后,无法提取当前值,只有先提取下一个值时才能再次提取当前值。
提取下一个值
select 序列名称.nextval from dual提取当前值
select 序列名称.currval from dual创建复杂序列
语法:
CREATE SEQUENCE sequence //创建序列名称
[INCREMENT BY n] //递增的序列值是 n 如果 n 是正数就递增,如果是负数就递减 默认是 1
[START WITH n] //开始的值,递增默认是 minvalue 递减是 maxvalue
[{MAXVALUE n | NOMAXVALUE}] //最大值
[{MINVALUE n | NOMINVALUE}] //最小值
[{CYCLE | NOCYCLE}] //循环/不循环
[{CACHE n | NOCACHE}];//分配并存入到内存中案例
有最大值的非循环序列
创建序列的语句:
create sequence seq_test1
increment by 10
start with 10
maxvalue 300
minvalue 20
以上的错误,是由于我们的开始值小于最小值 。开始值不能小于最小值,修改
以上语句:
create sequence seq_test1
increment by 10
start with 10
maxvalue 300
minvalue 5我们执行下列语句提取序列值,当序列值为 300(最大值)的时候再次提取值,
系统会报异常信息。
--提取值 当序列值为 300(最大值)的时候再次提取值 会报错
select seq_test1.nextval from dual;
需求
|
-- todo 需求1: 创建序列名为 seq_a,它以5递增,从10开始,最大值为30,最小值为2。 |
实现
-- todo 创建序列名为 seq_a,它以5递增,从10开始,最大值为30,最小值为2。
create sequence seq_a
increment by 5
start with 10
maxvalue 30
minvalue 2;
select seq_a.nextval from dual;有最大值的循环序列
create sequence seq_test2
increment by 10
start with 10
maxvalue 300
minvalue 5
cycle;当序列当前值为 300(最大值),再次提取序列的值
select seq_test2.nextval from dual;
select seq_test2.currval from dual;提取的值为:
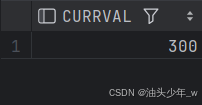
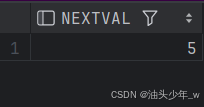
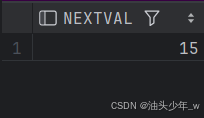
由此我们得出结论,循环的序列,第一次循环是从开始值开始循环,而第二次循环是从最小值开始循环。
思考问题:
下列语句是否会报错?为什么?
create sequence seq_test3
increment by 10
start with 10
minvalue 5
cycle;答:此为错误的语句。因为你创建的是一个循环的序列,所以必须指定最大值,否则会报错。
|
-- todo 需求2: 创建序列名为 seq_b,它以5递增,从10开始,最大值为30,最小值为2, 带循环 |
实现
-- todo 需求2: 创建序列名为 seq_b,它以5递增,从10开始,最大值为30,最小值为2, 带循环
create sequence seq_b
increment by 5
start with 10
maxvalue 30
minvalue 2
cycle
cache 3;
select seq_b.nextval from dual;带缓存的序列
oracle带缓存的序列中缓存的作用:
Oracle数据库中的序列是一种特殊类型的生成器,用于自动递增计数。当序列启用缓存时,它会预先存储一定数量的下一个值。这个缓存的设计是为了提高性能,特别是对于频繁需要获取下一个ID的情况,例如插入新行时。
使用缓存的好处包括:
- 减少I/O操作:由于序列通常用于数据插入,缓存可以避免每次请求时都去表中查找或计算新的ID,减少了对磁盘或内存的访问次数。
- 提高并发效率:多个并发进程请求序列时,可以从缓存直接读取而无需等待序列的更新,提升了系统响应速度。
- 减少锁竞争:序列的缓存降低了对序列表的锁定需求,因为不需要每次都去检查和更新序列。
然而,缓存也有其限制,比如如果缓存溢出(超出预设的最大值),序列将不得不从数据库中刷新新的值,这可能会导致短暂的性能下降。此外,如果应用的ID生成模式不稳定,如跳跃式增长,缓存策略可能不再适用。
我们执行下列语句:
其中cache表示存入缓存(也就是内存)序列值的个数
create sequence seq_test3
increment by 10
start with 10
maxvalue 300
minvalue 5
cycle
cache 50;我们执行上边语句的意思是每次取出 50 个缓存值,但是执行会提示错误

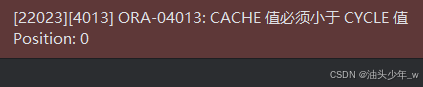
上边错误提示的意思是:缓存设置的数必须小于每次循环的数。
我们缓存设定的值是 50,而最大值是 300,那么为什么还会提示这样的信息呢?
其实我们的 cache 虽然是 50,但是我们每次增长值是 10。这样 50 次缓存提取出的数是 500 (50*10)
我们更改为下列的语句:
create sequence seq_test4
increment by 10
start with 10
maxvalue 500
minvalue 10
cycle
cache 50;下列语句依然会提示上边的错误,这是因为还存在一个 minvalue,minvalue 和 maxvalue 之间是 49 个数,也就是一次循环可以提取 490,但是我们的缓存是 500。
我们再次修改语句:
create sequence seq_test5
increment by 10
start with 10
maxvalue 500
minvalue 9
cycle
cache 50;把最小值减 1,或把最大值加 1 ,都可以通过。
修改和删除序列
修改序列:使用 ALTER SEQUENCE 语句修改序列,不能更改序列的 START
WITH 参数
alter sequence 序列名称 maxvalue 5000 cycle;删除序列:
DROP SEQUENCE 序列名称;综合案例
|
-- 1 创建序列 seq_student, 每次递增2, 从1000开始 -- 2 创建学生表 tb_student(sid, sname) -- 3 插入数据, sid 使用序列生成的值 -- 4 验证 |
实现
-- 1 创建序列 seq_student, 每次递增2, 从1000开始,
create sequence seq_student2
increment by 2
start with 1000;
-- 2 创建学生表 tb_student(sid, sname)
create table tb_student(
sid int primary key,
s_name varchar2(32)
);
-- 3 插入数据, sid 使用序列生成的值
insert into tb_student values(seq_student.nextval, '张三');
insert into tb_student values(seq_student.nextval, '李四');
insert into tb_student values(seq_student.nextval, '王五');
insert into tb_student values(seq_student.nextval, '赵六');
insert into tb_student values(seq_student.nextval, '刘备');
-- 4 验证
select * from tb_student;同义词
什么是同义词
同义词是一个计算机术语,英文(synonym)是指向其它数据库表的数据库指针。
同义词有两种类型:私有(private)和公有(public)
私有的同义词是在指定的模式中创建并且只有创建者使用的模式访问。
公有同义词是由public指定的模式访问,所有数据库模式(用户)都可以访问它。
对于同一服务器上的不同数据库,我们可以使用同义词,将其他数据库中的表或view等对象,在本数据库中映射别名。这样,就可以不用更改连接字符串,而在当前对话数据库的情况下,获取其他数据库的数据,并对它进行,查询,更新,删除和插入工作。
同义词实质上是指定方案对象的一个别名。通过屏蔽对象的名称和所有者以及对分布式数据库的远程对象提供位置透明性,同义词可以提供一定程度的安全性。同时,同义词的易用性较好,降低了数据库用户的 SQL 语句复杂度。
只允许特定用户或者有基对象访问权限的用户进行访问。
同义词本身不涉及安全,当你赋予一个同义词对象权限时,你实质上是在给同义词的基对象赋予权限,同义词只是基对象的一个别名。
创建与使用同义词
创建同义词的具体语法是:
create [public] SYNONYM synooym for object;其中 synonym 表示要创建的同义词的名称,object 表示表,视图,序列等我们要创建同义词的对象的名称。
案例
私有同义词
需求:为表 T_OWNERS 创建( 私有 )同义词 名称为 OWNERS
语句:
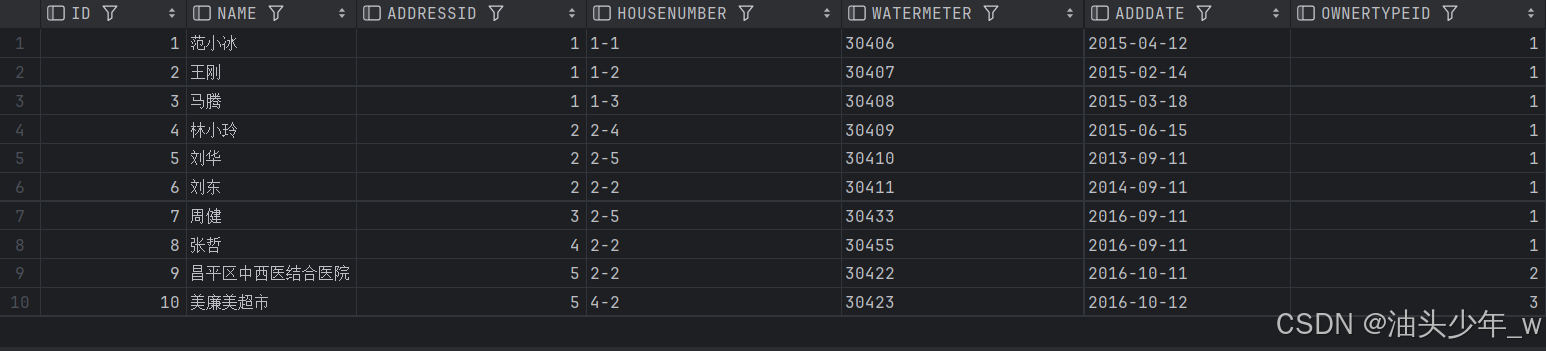
create synonym owners for t_owners;使用同义词:
select * from owners;查询结果如下:
公有同义词
需求:为表 T_OWNERS 创建( 公有 )同义词 名称为 OWNERS2:
create public synonym owners2 for t_owners;以另外的用户登陆,也可以使用公有同义词:
select * from owners;案例
|
-- 1 需求:为表 T_AREA 创建( 私有 )同义词 名称为 AREA -- 2 需求:为表 T_AREA 创建( 共有 )同义词 名称为 AREA2 -- 3 验证 其他用户 |
实现
-- 1 需求:为表 T_AREA 创建( 私有 )同义词 名称为 AREA
create synonym area for t_area;
select * from area;
-- 2 需求:为表 T_AREA 创建( 共有 )同义词 名称为 AREA2
create public synonym area2 for t_area;
-- 3 验证
select * from area2;删除同义词
drop synonym SYNONYM;其中 SYNONYM 表示要创建的同义词的名称
索引
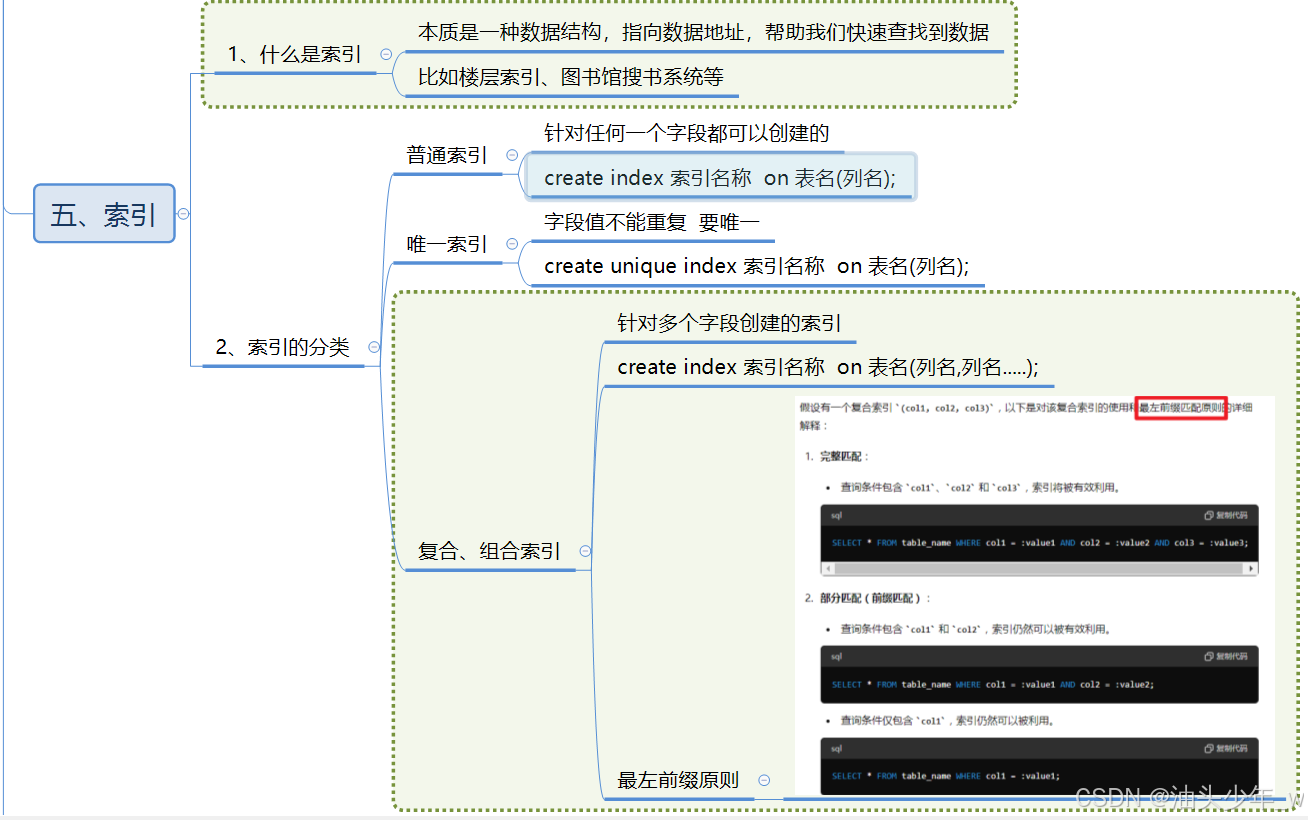
什么是索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低 i/o 次数,从而提高数据访问性能。
索引是需要占据存储空间的,也可以理解为是一种特殊的数据。形式类似于 下图的一棵“树”,而树的节点存储的就是每条记录的物理地址,也就是我们提到的伪列(ROWID)

普通索引
语法:
create index 索引名称 on 表名(列名);需求:我们经常要根据业主名称搜索业主信息,所以我们基于业主表的 name 字
段来建立索引。语句如下:
create index index_owners_name on t_owners(name);
索引性能测试:
创建一个两个字段的表
create table t_indextest (
id number,
name varchar2(30)
);编写 PL/SQL 插入 100 万条记录(关于 PL/SQL 我们在后面会学到)
begin
for i in 1 .. 1000000 loop
insert into t_indextest values (i, 'dev' || i);
end loop;
commit;
end;创建完数据后,根据 name 列创建索引
create index index_testindex on t_indextest(name); -- 创建索引消耗性能。执行下面两句 SQL 执行
SELECT * from T_INDEXTEST where ID=765432;
SELECT * from T_INDEXTEST where NAME= 'dev765432';
我们会发现根据 name 查询所用的时间会比根据 id 查询所用的时间要短
唯一索引
如果我们需要在某个表某个列创建索引,而这列的值是不会重复的。这是我们可以创建唯一索引。
语法:
create unique index 索引名称 on 表名(列名);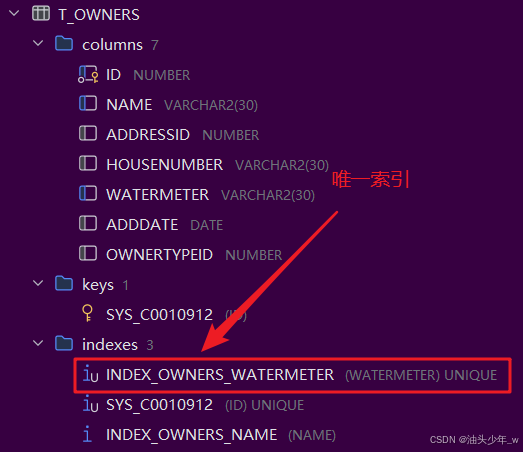
需求:在业主表的水表编号一列创建唯一索引
语句:
create unique index index_owners_watermeter on t_owners(watermeter);复合索引、组合索引
我们经常要对某几列进行查询,比如,我们经常要根据学历和性别对学员进行搜 索,如果我们对这两列建立两个索引,因为要查两棵树,查询性能不一定高。那 如何建立索引呢?我们可以建立复合索引,也就是基于两个以上的列建立一个索引 。
语法:
create index 索引名称 on 表名(列名,列名.....);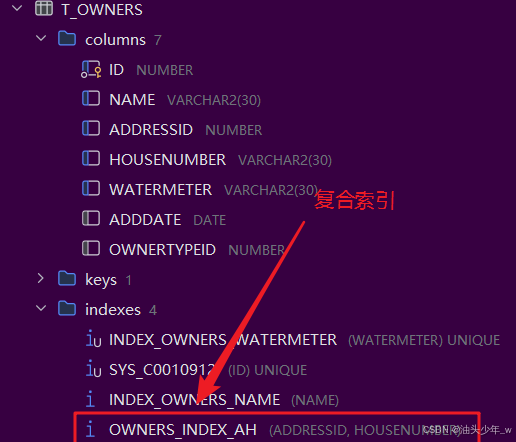
-- todo 复合索引、组合索引
create index owners_index_ah on t_owners(addressid, housenumber);
select * from T_OWNERS where HOUSENUMBER='1-1' and ADDRESSID = '1';
select * from T_OWNERS where ADDRESSID = '1' and HOUSENUMBER='1-1' ;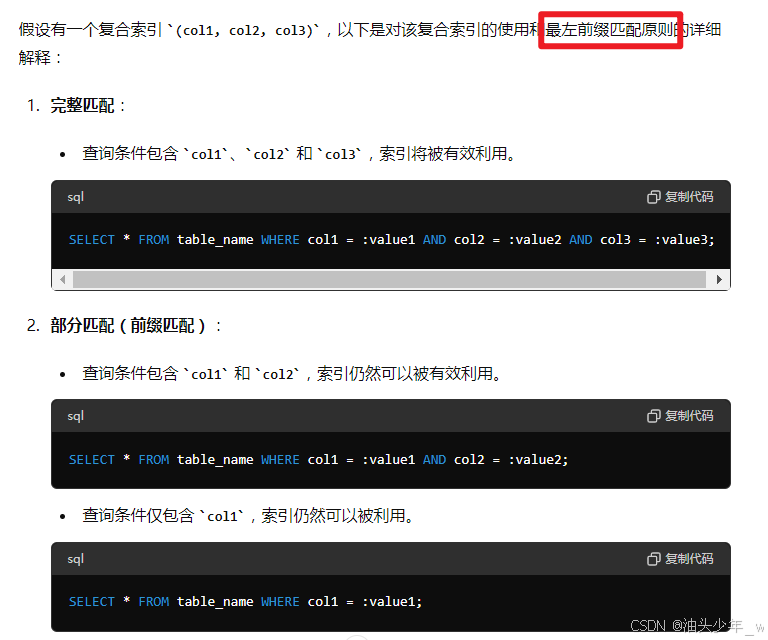


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)