目标检测(Object Detection)技术综述
目标检测技术经历了从传统手工特征到深度学习的跨越式发展,当前主流方法在精度与速度上已达到较高水平。然而,小目标检测、开放词汇扩展、边缘部署等挑战仍需进一步突破。随着Transformer、自监督学习等新技术的引入,目标检测将在更多复杂场景中发挥关键作用。的技术综述,涵盖其发展历史、核心方法、评价指标、应用场景及未来趋势。内容整合自知识库中的多篇文献和技术资料,旨在提供全面的概述。目标检测是计算机视
以下是关于 目标检测(Object Detection) 的技术综述,涵盖其发展历史、核心方法、评价指标、应用场景及未来趋势。
一、目标检测的定义与核心任务
目标检测是计算机视觉的基本任务之一,旨在识别图像或视频中的物体类别并定位其位置(通常用边界框表示)。其核心目标是回答两个问题:
- 什么对象存在?(分类)
- 对象的位置在哪里?(定位)
比如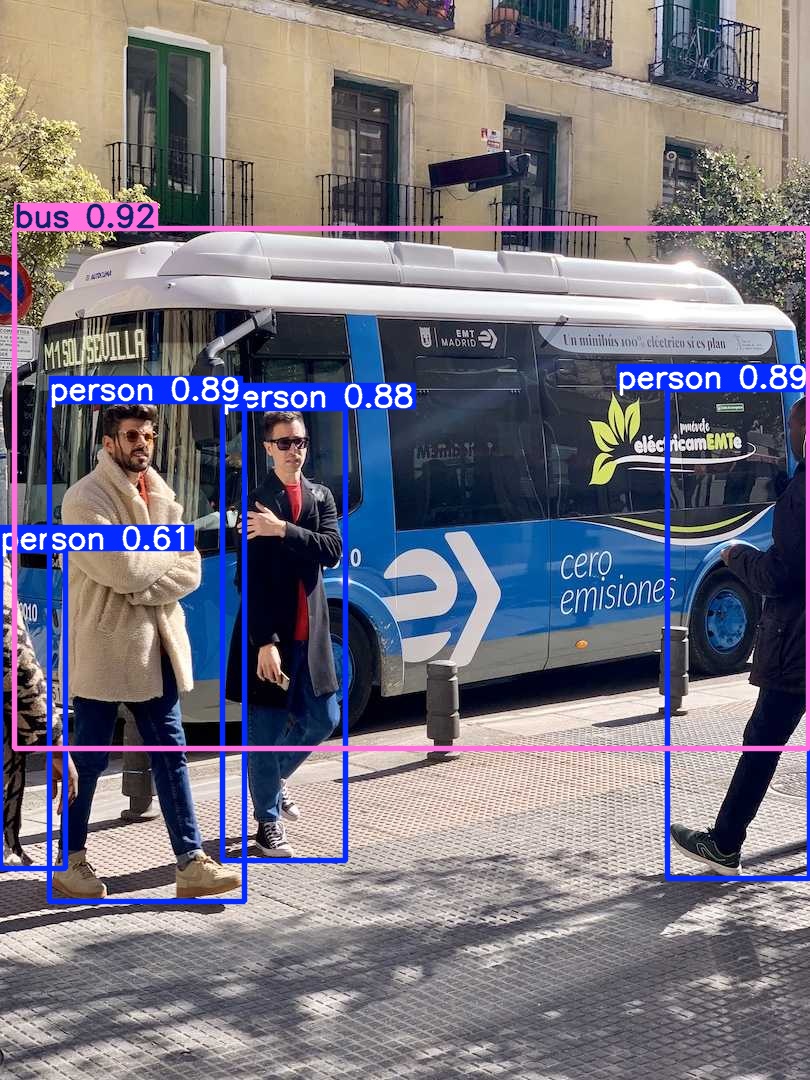
目标检测广泛应用于自动驾驶、医学影像分析、智能监控、无人系统等领域。
二、技术演进与主流方法
1. 传统目标检测(2014年前)
- 基于手工特征的方法:
- Viola-Jones检测器(2001):首个实时人脸检测算法,采用积分图像(Integral Image)、Adaboost特征选择和检测级联(Detection Cascade)技术。
- HOG(Histogram of Oriented Gradients,2005):通过计算图像局部梯度直方图提取特征,结合线性分类器(如SVM)进行检测。
- DPM(Deformable Part Models,2008):将目标分解为多个部件(如汽车的车窗、车身),通过部件间的组合提升检测性能,曾是传统方法的巅峰。
2. 深度学习目标检测(2014年后)
深度学习显著提升了目标检测的精度和效率,主流方法分为两大类:
(1) Two-Stage 检测器
- R-CNN 系列:
- R-CNN:通过选择性搜索生成候选区域(Region Proposals),利用CNN提取特征,最后进行分类和边界框回归。
- Fast R-CNN:共享特征图,减少重复计算;引入ROI Pooling层统一特征尺寸。
- Faster R-CNN:用RPN(Region Proposal Network)替代选择性搜索,实现端到端训练。
- 特点:精度高,但速度较慢(因需生成候选区域)。
(2) One-Stage 检测器
- YOLO 系列:
- YOLOv1(2015):将图像划分为网格,每个网格预测边界框和类别概率,实现单次推理。
- YOLOv3/v5/v8:引入多尺度预测、特征金字塔(FPN)、注意力机制等改进,兼顾速度与精度。
- SSD(Single Shot MultiBox Detector):通过多尺度特征图直接预测边界框和类别,支持多尺度目标检测。
- 特点:速度快,适合实时场景,但小目标检测精度略逊于Two-Stage方法。
(3) 其他创新方法
- RetinaNet:针对类别不平衡问题,引入Focal Loss,显著提升小样本类别的检测性能。
- CenterNet:基于关键点检测(中心点+宽高),简化检测流程。
- Transformer-based 检测器:如DETR(Detection Transformer),利用Transformer的全局注意力机制,逐步取代传统CNN架构。
三、核心评价指标
目标检测的性能评估依赖以下指标:
-
IoU(Intersection over Union)
- 定义:预测框与真实框的交集面积除以并集面积,衡量定位准确性。
- 阈值:通常设为0.5(mAP@0.5)或0.5~0.95的平均值(mAP@0.5:0.95)。
-
TP/FP/FN
- TP:IoU ≥ 阈值且类别正确的检测框。
- FP:IoU < 阈值、类别错误或冗余检测。
- FN:未检测到的真实目标。
-
Precision & Recall
- Precision:TP/(TP+FP),反映查准能力。
- Recall:TP/(TP+FN),反映查全能力。
-
AP(Average Precision)
- 定义:PR曲线下的面积,反映某一类别的综合检测性能。
- 计算方式:在不同置信度阈值下计算Precision和Recall,绘制曲线后积分。
-
mAP(mean Average Precision)
- 定义:所有类别的AP平均值,是目标检测的核心评价指标。
- COCO标准:mAP@0.5:0.95(IoU从0.5到0.95,步长0.05的平均值)。
-
速度指标
- FPS(Frames Per Second):每秒处理的图像帧数,衡量实时性。
- Inference Time:单张图像的处理耗时。
四、应用场景与挑战
1. 应用场景
- 自动驾驶:检测车辆、行人、交通标志(如YOLO、Faster R-CNN)。
- 智能医疗:医学影像中的病灶检测(如肺结节、肿瘤)。
- 零售与物流:无人超市的商品识别、货架补货检测。
- 安防监控:异常行为检测、人群计数。
- 农业与无人机:作物监测、果实识别(如LSOD-YOLO针对小目标检测的改进)。
2. 技术挑战
- 小目标检测:分辨率低、特征模糊(如LSOD-YOLO通过跨层特征融合和注意力机制优化)。
- 遮挡与复杂背景:多目标重叠、背景干扰(如混合图像生成技术增强鲁棒性)。
- 实时性要求:One-Stage方法(如YOLO)更适合高帧率场景。
- 开放词汇检测:扩展检测器到未标注类别(如基于视觉语言模型的方法)。
五、未来趋势
-
开放词汇目标检测(Open Vocabulary Detection)
- 目标:无需人工标注即可检测新类别(如基于大规模图像-文本数据或预训练视觉语言模型)。
- 技术:CLIP(Contrastive Language-Image Pretraining)等跨模态模型的应用。
-
轻量化与边缘部署
- 方向:模型压缩(如知识蒸馏、剪枝)、硬件加速(如NPU、GPU优化)。
- 案例:LSOD-YOLO通过轻量化设计实现在边缘设备的实时小目标检测。
-
多模态融合
- 技术:结合RGB图像、LiDAR点云、红外数据等多源信息,提升复杂场景下的检测鲁棒性。
-
自监督与少样本学习
- 目标:减少对大规模标注数据的依赖,提升模型泛化能力。
-
动态场景适应
- 方向:实时调整模型参数以适应环境变化(如光照、天气)。
六、总结
目标检测技术经历了从传统手工特征到深度学习的跨越式发展,当前主流方法在精度与速度上已达到较高水平。然而,小目标检测、开放词汇扩展、边缘部署等挑战仍需进一步突破。随着Transformer、自监督学习等新技术的引入,目标检测将在更多复杂场景中发挥关键作用。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)