MedAugment:基于医学图像的数据增强方法(针对分类问题及图像分割问题)
基于医学影像的数据增强方法
1. MedAugment 介绍
数据增强(DA)技术已在计算机视觉领域广泛应用,以缓解数据短缺的问题,而医学图像分析(MIA)中的DA仍然主要是经验驱动的。大多数现有的自动数据增强方法最初是为自然图像设计的,并不能直接应用于医学图像分析领域。因此,目前缺乏一种适用于医学图像分析的通用且强大的自动数据增强方法。为了填补这一空白,本文提出了MedAugment(不支持三维图像)。
MedAugment通过将增强空间划分为像素增强空间和空间增强空间,并设计了一种新的操作采样策略(从这两个空间中随机选择增强操作组合成一个增强管道,对增强管道中的操作进行随机排序再应用增强管道到图像上,具体可看下图红框区域),从而解决了自然图像和医学图像之间的差异。该方法在四个分类数据集和三个分割数据集上进行了广泛的实验,结果表明MedAugment优于大多数现有的先进数据增强方法。
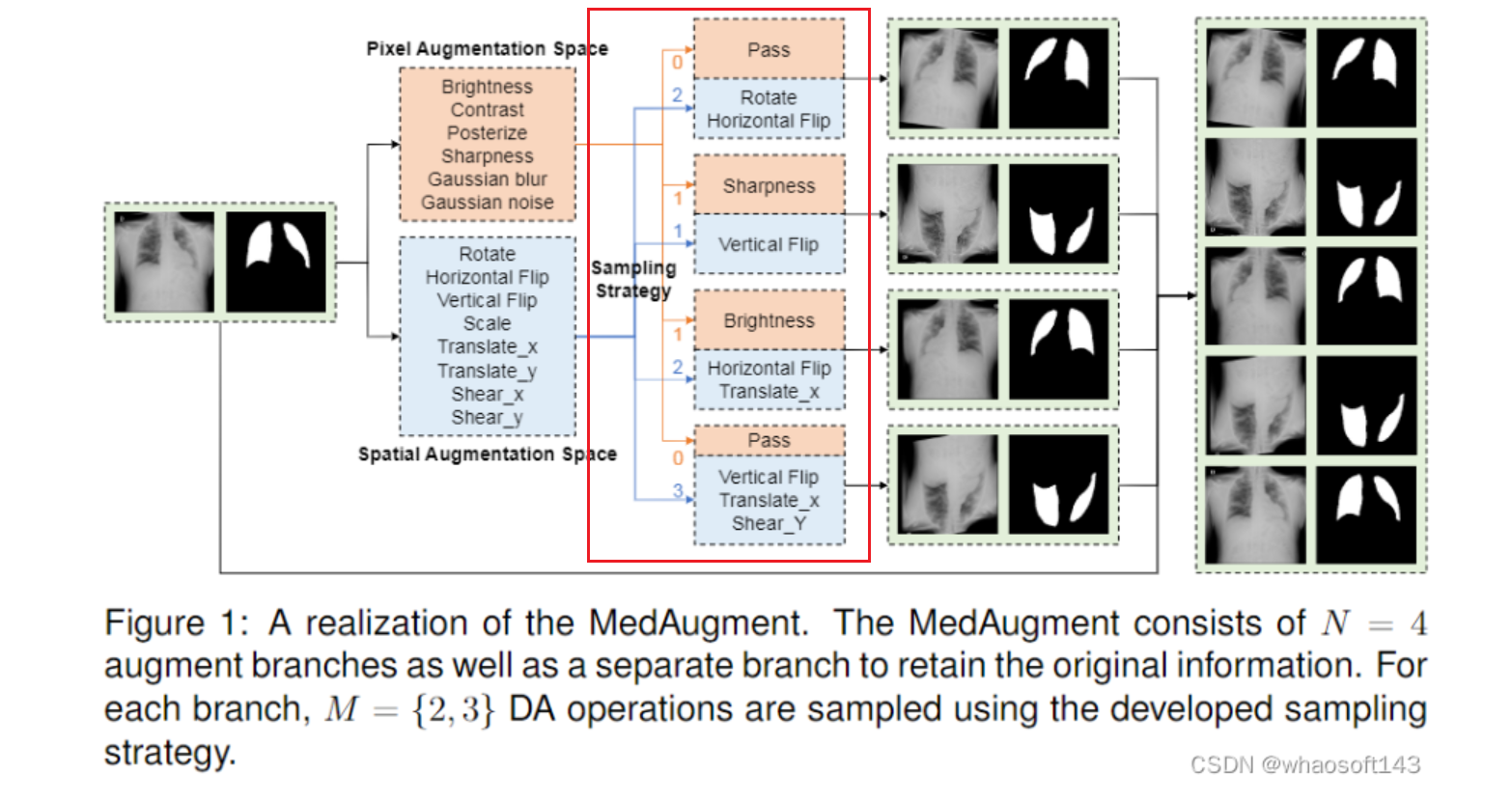
MedAugment中的两种增强空间:像素增强空间(Ap)和空间增强空间(As),具体如下:
像素增强空间(Ap)- 六种
- Brightness(亮度):调整图像的亮度,增强后的图像在视觉上会变得更亮或更暗,从而增加模型对不同光照条件下的图像的鲁棒性。
- Contrast(对比度):改变图像的对比度,使图像中的亮部更亮,暗部更暗,从而突出图像中的细节,帮助模型更好地识别不同组织或器官之间的边界。
- Posterize(降低颜色深度):减少图像的颜色深度,使图像中的颜色数量减少,从而模拟一些低质量的图像数据,增强模型对不同图像质量的适应能力。
- Sharpness(锐化):增强图像的锐度,使图像中的边缘更加清晰,有助于模型更好地识别和定位图像中的结构和细节。
- Gaussian blur(高斯模糊):对图像进行高斯模糊处理,使图像中的细节变得模糊,模拟一些模糊的图像数据,增强模型对不同图像清晰度的鲁棒性。
- Gaussian noise(高斯噪声):在图像中添加高斯噪声,增加图像的随机性,模拟真实世界中图像可能受到的噪声干扰,提高模型的抗噪声能力。
空间增强空间(As)- 八种
- Rotate(旋转):对图像进行旋转操作,使图像在不同的角度下呈现,增加模型对不同方向的图像的识别能力。
- Horizontal flip(水平翻转):将图像沿水平轴进行翻转,生成与原图像左右相反的图像,增加数据的多样性。
- Vertical flip(垂直翻转):将图像沿垂直轴进行翻转,生成与原图像上下相反的图像,进一步丰富数据的多样性。
- Scale(缩放):对图像进行缩放操作,改变图像的大小,使模型能够更好地处理不同尺寸的图像。
- Translate x(水平平移):将图像沿水平方向进行平移,使图像中的内容在水平方向上发生位移,增加模型对图像位置变化的适应能力。
- Translate y(垂直平移):将图像沿垂直方向进行平移,使图像中的内容在垂直方向上发生位移,进一步增强模型对图像位置变化的鲁棒性。
- Shear x(水平剪切):对图像进行水平剪切操作,使图像中的内容在水平方向上发生倾斜,增加图像的多样性。
- Shear y(垂直剪切):对图像进行垂直剪切操作,使图像中的内容在垂直方向上发生倾斜,进一步丰富图像的变化。
这些增强方法在MedAugment中被精心设计和组合,以确保在增强数据的同时不会破坏医学图像的细节和特征,从而保证图像的诊断价值。
2. 代码及实现方法
2.1 代码:GitHub - NUS-Tim/MedAugment — GitHub - NUS-Tim/MedAugment
下载代码至linux目录上,解压,环境可参考requirements.txt,特别是albumentations==1.3.0版本;
2.2 使用方法
准备输入文件(下面仅说明classification任务)
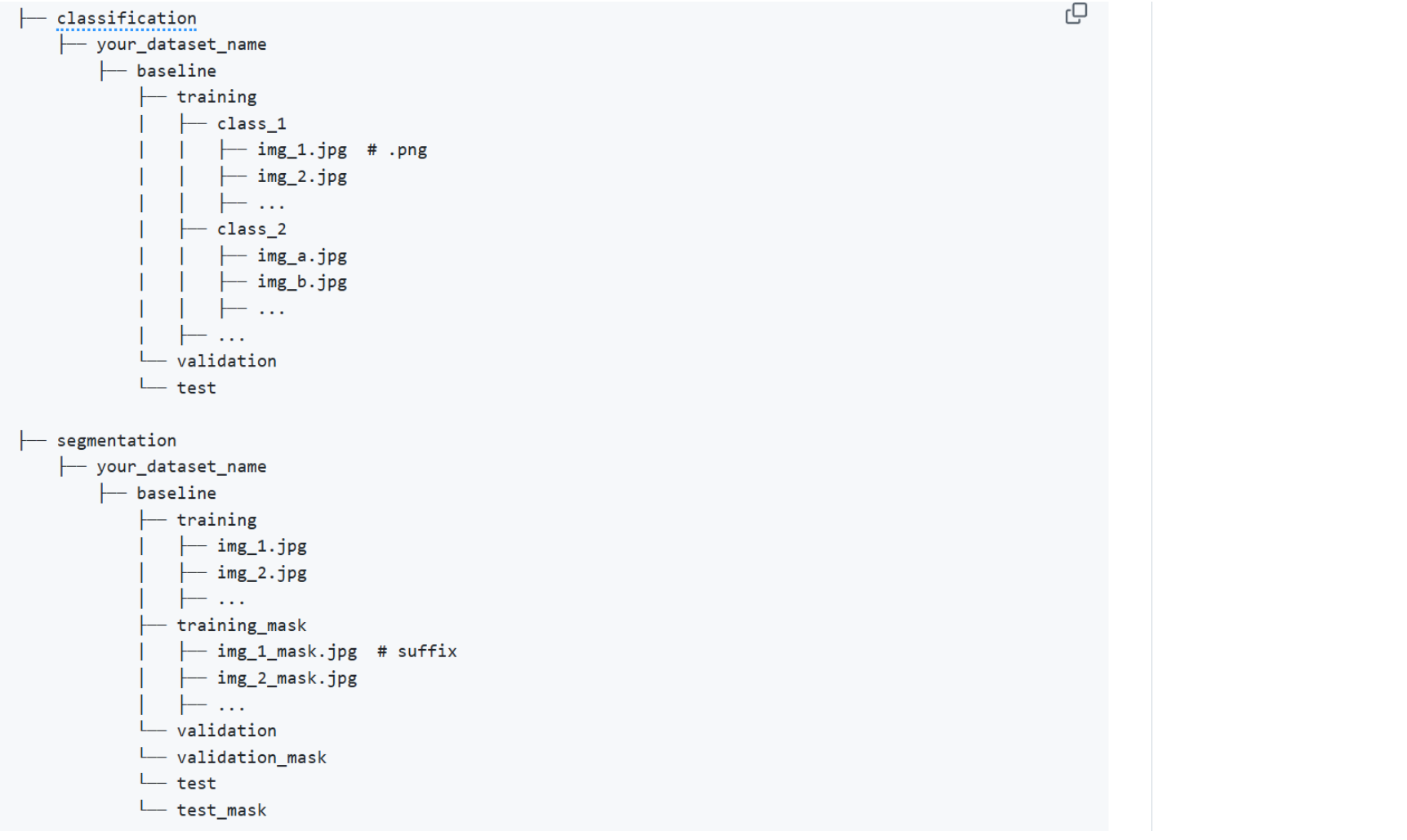
为了方便与后续模型结合,在项目目录下准备dataset目录,其中thyroid_LNM目录包含所有的图片,同时,dataset目录下还存在LNM_image_label.txt的文件内容为文件名,label
-
项目目录如下:

-
dataset目录如下(其中,baseline和medaument为下续代码生成,初始只需要准备thyroid_LNM目录和LNM_image_label.txt文件):

通过下述代码创建baseline目录及子目录,其目录框架如上,0,1代表每张图片的label
import os
import shutil
import random
from collections import defaultdict
import numpy as np
import pandas as pd
# 设置随机种子
random.seed(39)
# 图片目录和txt文件路径
image_dir = '../dataset/thyroid_LNM/'
split_dir = '../dataset/baseline/'
txt_file = os.path.join(image_dir, '../', 'LNM_image_label.txt')
# 创建划分后的目录结构,如果存在则先删除再创建
split_dirs = ['training', 'validation', 'test']
for one_split_dir in split_dirs:
split_dir_path = os.path.join(split_dir, one_split_dir)
if os.path.exists(split_dir_path):
shutil.rmtree(split_dir_path)
os.makedirs(split_dir_path, exist_ok=True)
# 读取txt文件,获取图片名和label
with open(txt_file, 'r') as f:
lines = f.readlines()
# 按label分组
label_dict = defaultdict(list)
for line in lines:
image_name, label = line.strip().split(',')
label_dict[label].append(image_name)
# 按分层划分比例划分图片
split_images = {'training': [], 'validation': [], 'test': []}
# 计算每个label的划分数量
for label, image_names in label_dict.items():
random.shuffle(image_names) # 打乱顺序
total_count = len(image_names)
train_size = int(total_count * 0.7)
val_size = int(total_count * 0.2)
test_size = total_count - train_size - val_size
train_images = image_names[:train_size]
val_images = image_names[train_size:train_size + val_size]
test_images = image_names[train_size + val_size:]
# 将图片添加到对应的划分列表中
split_images['training'].extend([(image_name, label) for image_name in train_images])
split_images['validation'].extend([(image_name, label) for image_name in val_images])
split_images['test'].extend([(image_name, label) for image_name in test_images])
# 确保每个样本只被分配到一个数据集中
all_images = set()
for one_split_dir in split_dirs:
for image_name, label in split_images[one_split_dir]:
all_images.add(image_name)
# 检查是否有重复的样本
assert len(all_images) == sum(len(v) for v in split_images.values()), "样本重复"
# 在每个数据集目录下创建不同类别的文件夹
for one_split_dir in split_dirs:
for label in label_dict.keys():
label_dir = os.path.join(split_dir, one_split_dir, label)
os.makedirs(label_dir, exist_ok=True)
# 将图片复制到对应的目录
for one_split_dir in split_dirs:
for image_name, label in split_images[one_split_dir]:
src_path = os.path.join(image_dir, image_name)
dst_path = os.path.join(split_dir, one_split_dir, label, image_name)
shutil.copy(src_path, dst_path)
print("图片划分完成!")
更改一下文件的输入输出路径,更改为红色边框里的代码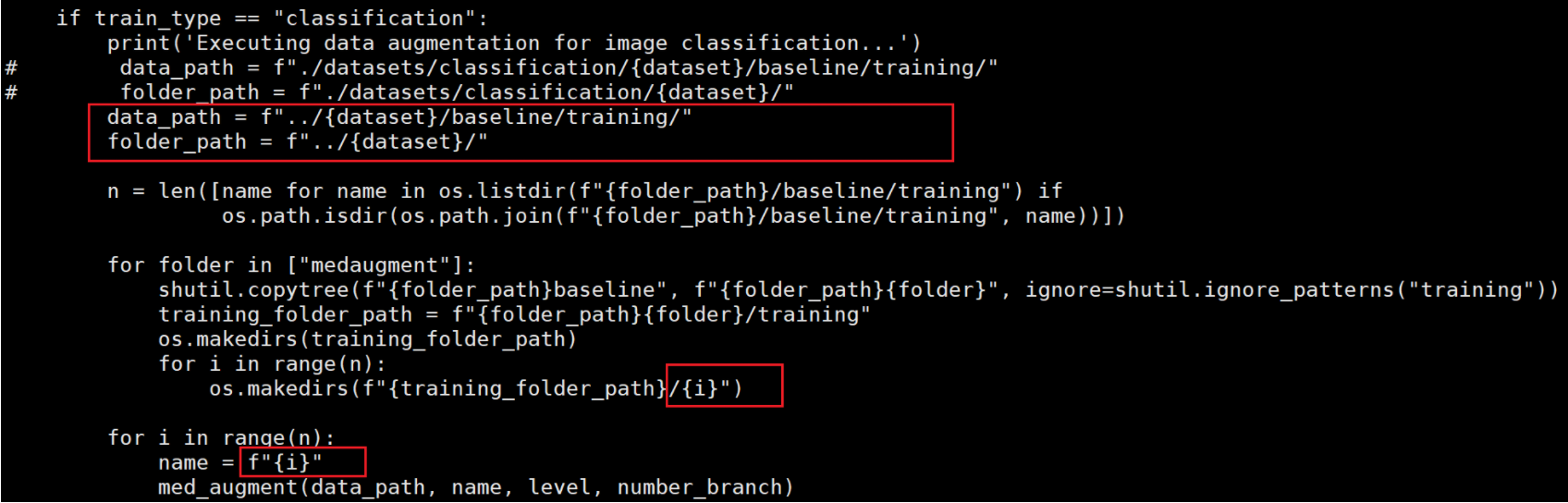
执行命令
python ./utils/medaugment.py --dataset="dataset" --train_type="classification"
# --number_branch 控制每张图片采取多少种增强策略并生成对应图片,默认值为4
# ./utils/medaugment.py里的shield 用于控制是否保存原图,默认保存,目录的最后一个文件默认为保存的原图
输出结果解释
- 在baseline同级目录下生成medaugment目录,如下。

- 进一步查看
../dataset/medaugment/training/0/目录下的内容,可看到当–number_branch为4时,每张图片生成了4张增强图片(_1.jpg,_2.jpg, _3.jpg, _4.jpg)和一张原图(_5.jpg)


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)