《向量数据库指南》——Late Chunking:重塑长文本Embedding的新篇章
而Late Chunking则是先过 Embedding 模型再分块(late的含义就是在于此,先向量化再分块),我们先将 Embedding 模型的 transformer 层应用到整个文本,为每个 token 生成一个包含丰富上下文信息的向量表示序列。尽管有一些启发式算法试图缓解这一问题,如滑动窗口重新采样、重叠的上下文窗口长度以及多次文档扫描等,然而,像所有启发式算法一样,这些方法时灵时不灵
Late Chunking是什么
传统的分块在处理长文档时可能会丢失文档中长距离的上下文依赖关系,这对于信息检索和理解是一大隐患。即当关键信息散落在多个文本块中,脱离上下文的文本分块片段很可能失去其原有的意义,导致后续的召回效果比较差。
以Milvus 2.4.13 release note为例,假如分为如下两个文档块,如果我们要查询Milvus 2.4.13有哪些新功能?
,直接相关内容在分块2里,而Milvus版本信息在分块1里,此时,Embedding 模型很难将这些指代正确链接到实体,从而产生质量不高的Embedding。
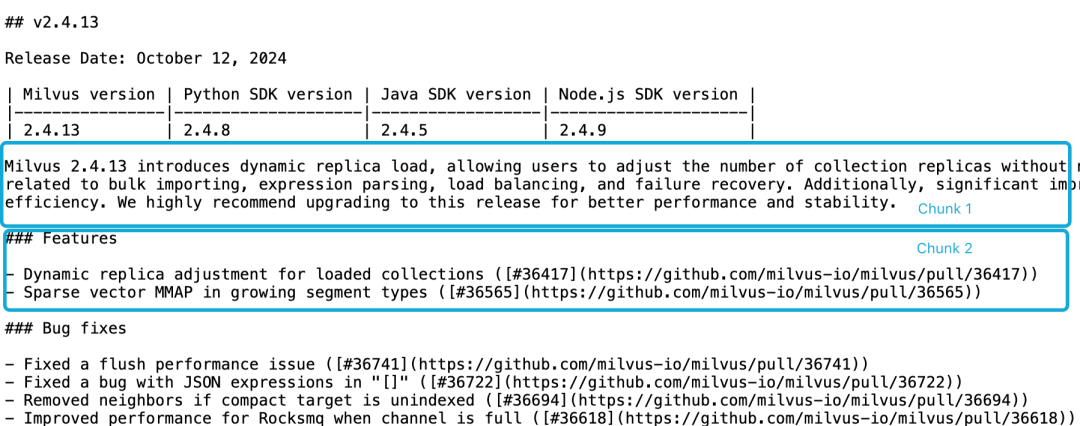
由于功能描述与版本信息不在同一个分块里,且缺乏更大的上下文文档,LLM 难以解决这样的关联问题。尽管有一些启发式算法试图缓解这一问题,如滑动窗口重新采样、重叠的上下文窗口长度以及多次文档扫描等,然而,像所有启发式算法一样,这些方法时灵时不灵,它们可能在某些情况下有效,但是没有理论上的保证。
传统的分块采用一种预先分块的策略,即先分块,再过 Embedding 模型。首先依据句子、段落或预设的最大长度等参数对文本进行切割。然后Embedding 模型会对这些分块逐一进行处理,通过平均池化等方法,将 token 级的 Embedding 聚合成单一的块 Embedding 向量。而Late Chunking则是先过 Embedding 模型再分块(late的含义就是在于此,先向量化再分块),我们先将 Embedding 模型的 transformer 层应用到整个文本,为每个 token 生成一个包含丰富上下文信息的向量表示序列。然后,再对这些 token 向量序列进行平均池化,最终得到考虑了整个文本上下文的块 Embedding。
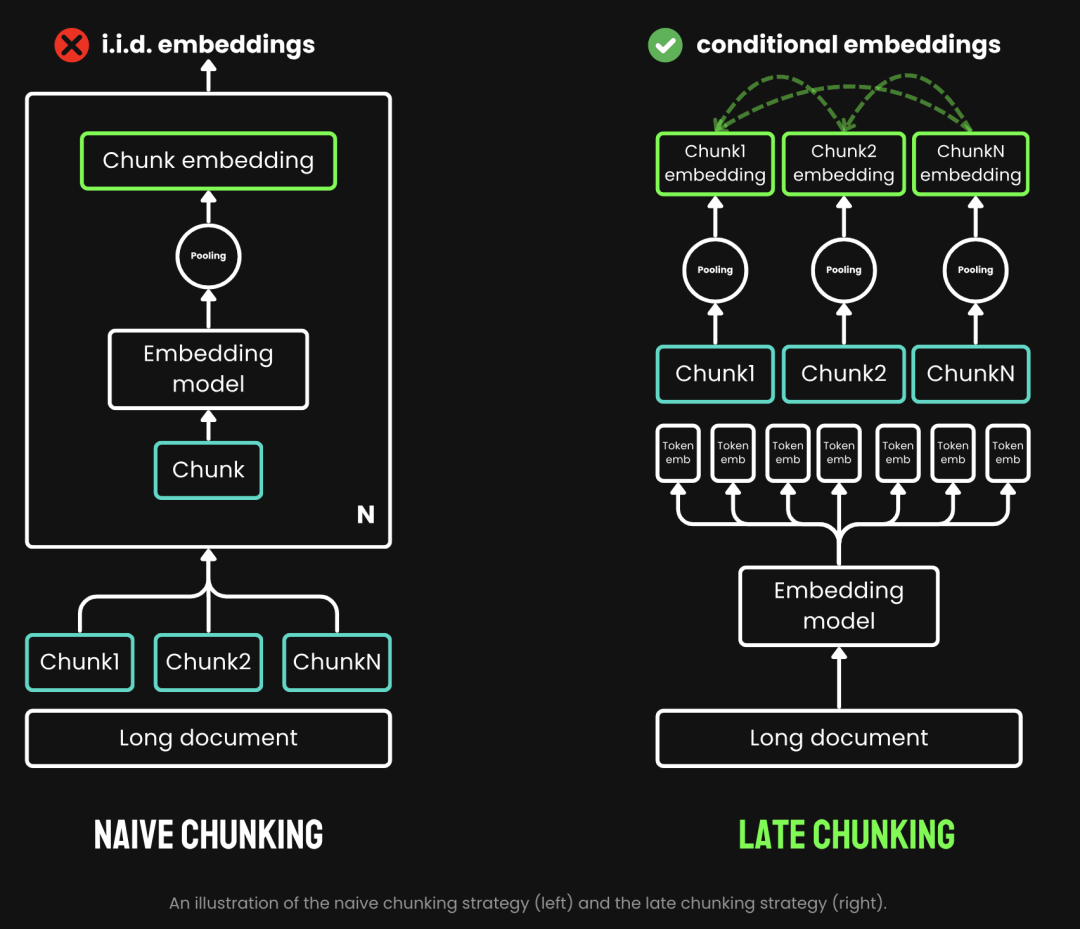
(图片来源:https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Late Chunking生成的块Embedding,每个块都编码了更多的上下文信息,从而提高了编码的质量和准确性。我们可以通过支持长上下文的 Embedding 模型,如 jina-embeddings-v2-base-en
,它能够处理长达8192个token 的文本(相当于 10 页 A4 纸),基本满足了大多数长文本的上下文需求。
综上所述,我们可以看到Late Chunking在RAG应用中的优势:
-
提高准确性:通过保留上下文信息,与简单分块相比,Late Chunking为查询返回了相关度更高的内容。
-
高效的LLM调用:Late Chunking可以减少传递给LLM的文本量,因为它返回的分块更少且相关度更高。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)