MySQL数据库测试脚本教程及实战应用
本文还有配套的精品资源,点击获取简介:本文档是关于MySQL数据库的测试脚本,其中包含了一系列用于操作MySQL数据库的SQL语句。这些脚本可用于创建数据库、表,插入、查询、更新、删除数据,以及事务处理、权限管理、存储过程、触发器等高级功能。本文档还包含了README.txt文件,提供脚本使用说明和版本信息。在使用这些脚本进行数据库操作时,建议先备份数据...

简介:本文档是关于MySQL数据库的测试脚本,其中包含了一系列用于操作MySQL数据库的SQL语句。这些脚本可用于创建数据库、表,插入、查询、更新、删除数据,以及事务处理、权限管理、存储过程、触发器等高级功能。本文档还包含了 README.txt 文件,提供脚本使用说明和版本信息。在使用这些脚本进行数据库操作时,建议先备份数据,并掌握SQL语法和MySQL的最佳实践。 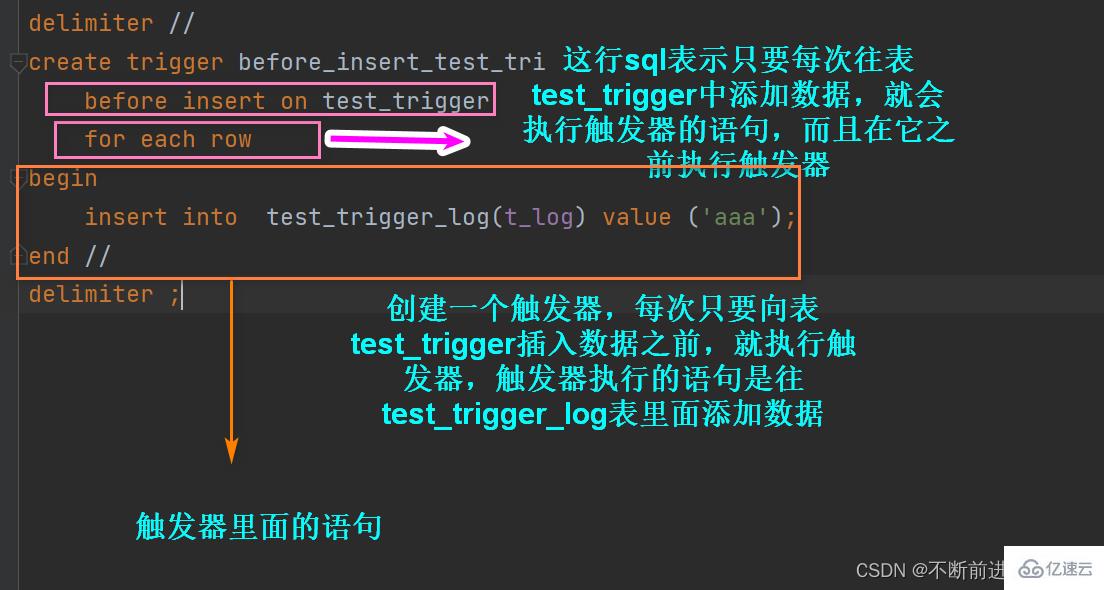
1. MySQL数据库基础操作
在信息技术的世界中,MySQL 是关系型数据库管理系统(RDBMS)的一种,广泛应用于网站后端数据库的管理与维护。本章主要介绍MySQL数据库的基础操作,为后面章节的深入探讨打下坚实的基础。
1.1 数据库的安装与配置
首先,MySQL服务器的安装是开展数据库管理工作的前提。用户需要根据各自的操作系统下载对应的安装包,并按照安装向导完成安装。随后,还需要对MySQL的配置文件进行适当调整,如修改端口、设置字符集等,以满足不同的业务需求。
# 以Linux为例,配置文件一般位于/etc/mysql/my.cnf
[mysqld]
port = 3306
default-character-set=utf8mb4
1.2 数据库的连接与退出
配置完成后,我们需要使用MySQL提供的客户端工具来连接数据库。通过终端或图形界面工具输入以下命令来启动连接:
mysql -u username -p
输入正确的密码后即可进入MySQL命令行界面。退出连接时,只需要执行以下命令:
EXIT;
1.3 数据库的状态检查与维护
连接上数据库后,我们可以通过一些命令来检查数据库的状态,包括版本信息、当前数据库连接数等。维护方面,定期优化数据库表结构、清除无效数据和索引碎片化,都是提升数据库性能的重要手段。
-- 查看MySQL版本信息
SELECT VERSION();
-- 查看当前数据库连接数
SHOW PROCESSLIST;
-- 优化表结构
OPTIMIZE TABLE table_name;
通过上述步骤,我们已经完成了MySQL数据库的基础操作。接下来,随着对SQL语句应用、数据库创建与表管理等章节的学习,我们将逐步探索数据库的更深层次知识。
2. SQL语句在数据库操作中的应用
2.1 SQL的基本概念和分类
2.1.1 SQL语言简介
SQL(Structured Query Language)即结构化查询语言,是一种专门用于与关系数据库通信的标准编程语言。自从1974年由Donald D. Chamberlin和Raymond F. Boyce发明以来,SQL已经成为了数据查询、操作、定义和控制的工业标准。
SQL语言包含多个子集,比如用于操纵数据库中数据的DML(Data Manipulation Language)、定义数据结构的DDL(Data Definition Language),以及用于控制数据库访问权限的DCL(Data Control Language)。此外,还有用于数据查询的DQL(Data Query Language)以及用于事务处理的DCL(Data Control Language)。
2.1.2 SQL语句的分类及功能
- DDL(Data Definition Language):用于定义或修改数据库结构,如创建或删除数据库对象(如数据库、表、索引)。常见的DDL语句包括
CREATE,ALTER, 和DROP。 -
DML(Data Manipulation Language):用于对数据库中数据的增删改操作。主要的DML语句包括
SELECT,INSERT,UPDATE, 和DELETE。 -
DCL(Data Control Language):用于控制数据库访问权限。主要的DCL语句包括
GRANT和REVOKE,用于授权和撤销用户权限。 -
DQL(Data Query Language):是SQL语言中的查询部分,用于检索数据库中的数据,
SELECT是主要的操作。
接下来我们将对DDL和DML语句的应用进行更深入的探讨。
2.2 数据定义语言DDL的应用
2.2.1 创建与修改数据库结构
创建数据库的基本语法是使用 CREATE DATABASE 语句。例如,创建一个名为 mydb 的新数据库可以执行以下命令:
CREATE DATABASE mydb;
创建表结构的命令则使用 CREATE TABLE 语句。以下示例展示了一个带有几个字段的表的创建过程:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
表创建完成后,我们可以使用 ALTER TABLE 语句来修改表结构。例如,添加一个新列:
ALTER TABLE employees ADD middle_name VARCHAR(50);
修改或删除现有列:
ALTER TABLE employees MODIFY middle_name VARCHAR(100);
ALTER TABLE employees DROP COLUMN middle_name;
2.2.2 理解和使用数据类型
选择正确的数据类型对于确保数据的准确性和性能至关重要。MySQL支持多种数据类型,包括数值、日期时间、字符串等。例如,在 employees 表中,我们使用了 INT 类型来存储员工ID, VARCHAR 类型来存储名字和邮箱,以及 AUTO_INCREMENT 关键字来自动递增主键值。
每种数据类型都有其特定的用途和限制。例如, CHAR 类型适合存储长度固定的字符串,如状态代码。 VARCHAR 类型则用于存储长度可变的字符串。选择合适的数据类型有助于优化查询性能和减少存储空间。
2.3 数据操纵语言DML的应用
2.3.1 插入、更新、删除数据记录
向表中插入新记录可以使用 INSERT INTO 语句。以下示例展示了如何向 employees 表中插入一条新记录:
INSERT INTO employees (first_name, last_name, email)
VALUES ('John', 'Doe', 'johndoe@example.com');
更新表中现有数据使用 UPDATE 语句。例如,修改一个员工的邮箱:
UPDATE employees SET email = 'newemail@example.com' WHERE id = 1;
删除表中的记录使用 DELETE 语句。以下示例展示如何删除ID为1的员工:
DELETE FROM employees WHERE id = 1;
2.3.2 事务控制语句的应用
事务是一组操作,这些操作作为一个整体执行,要么全部成功,要么全部失败。在SQL中,事务控制通过 BEGIN , COMMIT , ROLLBACK 语句来实现。
事务的开始使用 BEGIN 或 START TRANSACTION 语句。使用 COMMIT 来提交事务,使得自 BEGIN 以来的修改永久生效。如果在事务中需要回滚,使用 ROLLBACK 来撤销所有修改。
BEGIN;
INSERT INTO employees (first_name, last_name, email) VALUES ('Jane', 'Doe', 'janedoe@example.com');
-- 在这期间可能有其他操作
COMMIT;
通过正确使用事务控制语句,我们能够确保数据的一致性并防止错误的数据操作。
在本章中,我们深入探讨了SQL语句在数据库操作中的应用,包括其基本概念、数据定义语言DDL的使用,以及数据操纵语言DML的详细操作。接下来的章节,我们将进一步探讨如何创建和管理数据库与表,以及如何高效地进行数据的插入、查询、更新与删除操作。
3. 创建数据库与表
3.1 数据库的创建和维护
3.1.1 创建新数据库
创建一个新的数据库是开始任何项目之前的重要步骤。在MySQL中,创建数据库的过程相对简单。使用CREATE DATABASE语句可以创建新的数据库。以下是一个简单的例子:
CREATE DATABASE IF NOT EXISTS my_new_database;
这条SQL语句首先检查是否存在名为 my_new_database 的数据库,如果不存在,则创建一个新的数据库。 IF NOT EXISTS 是一个实用的选项,因为它可以帮助避免在尝试创建已存在数据库时产生错误。创建数据库后,你需要使用该数据库以执行后续的操作,可以通过以下SQL语句选择要使用的数据库:
USE my_new_database;
创建数据库之后,接下来的任务之一可能是备份数据库,以防数据丢失或需要从备份中恢复数据。对于数据库备份,你可以使用mysqldump工具:
mysqldump -u username -p my_new_database > backup_file.sql
以上命令将备份 my_new_database 数据库,并将备份文件保存为当前目录下的 backup_file.sql 。之后,你可以通过执行以下命令恢复数据库:
mysql -u username -p my_new_database < backup_file.sql
3.1.2 数据库的备份与恢复
数据备份是数据库管理中一个非常关键的方面。它确保在发生硬件故障、数据损坏或其他灾难性事件时,数据不会丢失。MySQL提供了多种备份数据的方法,包括逻辑备份和物理备份。逻辑备份通过导出数据为SQL语句来执行,而物理备份则是复制数据库文件。逻辑备份可以使用mysqldump工具完成,如前文所述。物理备份通常涉及到复制整个数据目录,这可以使用操作系统的命令实现。
数据恢复是备份过程的逆过程。在备份过程中记录的所有数据库操作将被逆转,以使数据库回到之前的状态。对于逻辑备份,我们通常通过命令行运行备份文件来恢复数据:
mysql -u username -p my_database < backup_file.sql
数据库恢复到一个特定的时刻,可以利用二进制日志(binlog)来完成。首先,你需要确定二进制日志文件和位置,然后使用mysqlbinlog工具处理日志文件,并通过mysql命令将数据导入数据库:
mysqlbinlog --start-datetime="2023-01-01 12:00:00" --stop-datetime="2023-01-01 13:00:00" binary_log_file.log | mysql -u username -p my_database
上述命令将会将指定时间范围内的更改应用到数据库。
3.2 表的创建和管理
3.2.1 设计表结构
在数据库创建后,接下来的重要任务是设计表结构。这包括定义表名、字段名、数据类型以及可能的约束条件,比如主键(PRIMARY KEY)、外键(FOREIGN KEY)、唯一约束(UNIQUE)、检查约束(CHECK)等。良好的表结构设计对于保证数据的完整性、一致性和优化查询性能至关重要。
以下是创建表的一个简单示例:
CREATE TABLE customers (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
reg_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB;
在这个例子中,我们创建了一个名为 customers 的表,包含 customer_id 、 first_name 、 last_name 、 email 和 reg_date 五个字段。其中 customer_id 字段设置为自增主键, email 字段是唯一约束,而 reg_date 字段自动记录了用户的注册时间。 ENGINE=InnoDB 指定了表的存储引擎为InnoDB,它支持事务处理。
3.2.2 修改和删除表
在设计好表结构后,可能会遇到需要对表结构进行修改的情况。这可能包括添加、删除或修改字段,以及更改数据类型等操作。MySQL提供了ALTER TABLE语句来完成这些任务。
添加字段
如果需要向现有表中添加一个新字段,可以使用ALTER TABLE语句:
ALTER TABLE customers ADD COLUMN middle_name VARCHAR(50);
这将在 customers 表中添加一个名为 middle_name 的新字段。
删除字段
删除一个字段则需要使用DROP COLUMN:
ALTER TABLE customers DROP COLUMN middle_name;
修改字段
如果你想要修改字段的数据类型或其属性,比如将其设置为非空:
ALTER TABLE customers MODIFY COLUMN email VARCHAR(100) NOT NULL;
以上命令会将 customers 表的 email 字段修改为非空。
删除表
在某些情况下,可能需要删除整个表。使用DROP TABLE语句可以实现这一点:
DROP TABLE IF EXISTS customers;
上述命令会删除名为 customers 的表,如果表不存在则不会有任何操作。
设计表结构和管理表是数据库设计和维护的核心。一个合理的表结构设计能够帮助我们更好地存储和检索数据,而表的修改与删除也是维护数据库时必不可少的操作。在实际操作中,我们需要仔细考虑每次操作可能带来的影响,确保数据安全和操作的正确性。
4. 数据的插入、查询、更新与删除
4.1 数据查询基础
4.1.1 SELECT语句的使用
在数据库操作中,查询是获取数据最直接的方法。SQL的SELECT语句是执行查询的核心,它能够从数据库中检索数据,并返回一个结果集。查询数据的最简单形式如下:
SELECT column_name(s) FROM table_name;
在这个基本的SELECT语句中, column_name(s) 是你想要查询的列名,而 table_name 是包含这些列的表名。这条语句将返回一个包含指定列数据的表。例如,如果你有一个名为 employees 的表,并且想要查询所有员工的姓名和薪水,你可以写出如下的SQL查询:
SELECT name, salary FROM employees;
参数说明与执行逻辑
SELECT关键字用于指定要查询的列。column_name(s)代表了要查询的列,可以是单个列名,也可以是多个列名,列名之间用逗号分隔。FROM关键字后面跟着的是要从中检索数据的表名。- 执行这个查询后,数据库管理系统(DBMS)会处理这个请求,从
employees表中检索出所有员工的姓名和薪水,并将结果以表格形式展示给用户。
4.1.2 条件查询与聚合函数
简单的查询往往不足以满足复杂的数据检索需求。这时,我们可以使用条件查询和聚合函数来扩展我们的查询能力。
条件查询
条件查询允许我们通过 WHERE 子句对数据进行筛选。以下是条件查询的结构:
SELECT column_name(s)
FROM table_name
WHERE condition;
WHERE 子句可以使用各种条件操作符,如 > 、 < 、 = , != , >= , <= , BETWEEN , LIKE , IN , NULL , NOT NULL , AND , OR 等。
例如,如果你想要查询薪水高于50000的员工,可以使用如下查询:
SELECT name, salary
FROM employees
WHERE salary > 50000;
聚合函数
聚合函数用于执行一个计算,并返回单个值。常见的聚合函数包括 COUNT() , SUM() , AVG() , MAX() , MIN() 等。聚合函数经常与 GROUP BY 子句一起使用,来对分组后的数据执行计算。
以下是一个使用聚合函数的查询示例:
SELECT department, AVG(salary) AS average_salary
FROM employees
GROUP BY department;
在这个例子中,我们计算了每个部门的平均薪水,并使用 AS 关键字给结果列起了一个别名 average_salary 。
代码逻辑的逐行解读分析
SELECT关键字后跟要展示的列名和聚合函数。FROM子句指定要查询的表。WHERE子句限制了查询结果必须满足的条件,例如薪水大于50000。GROUP BY子句用于将结果集按一个或多个列进行分组,对每个分组执行聚合函数。
使用聚合函数和条件查询可以帮助我们进行更深入的数据分析,而不仅仅是检索原始数据。在实际应用中,这些技术对于生成报告、监控数据变化等场景至关重要。
5. 高级数据库操作
5.1 索引的创建与管理
5.1.1 索引的作用与类型
索引在数据库中起着至关重要的作用,它是一种数据结构,可以帮助MySQL更快地定位到表中的特定值,从而加快查询的速度。索引的类型主要有普通索引、唯一索引、主键索引、全文索引和空间索引。
- 普通索引:允许出现重复值和空值。
- 唯一索引:保证列的唯一性,不允许有重复值。
- 主键索引:一种特殊的唯一索引,不允许有空值。
- 全文索引:用于对文本字段进行全文搜索。
- 空间索引:用于MyISAM和InnoDB表的地理空间数据类型。
5.1.2 创建和优化索引策略
创建索引的基本语法是:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
ON table_name (column_name [(length)] [ASC|DESC], ...);
优化索引时,应该考虑以下几点:
- 选择合理的列来创建索引,通常在WHERE子句、JOIN条件或ORDER BY子句中使用到的列是建索引的好选择。
- 为经常作为查询条件的列创建索引,但索引并不是越多越好,因为索引会占用磁盘空间并影响写入性能。
- 使用EXPLAIN分析查询计划,评估现有索引的使用情况。
EXPLAIN SELECT * FROM table_name WHERE column_name = value;
5.2 权限管理与用户访问控制
5.2.1 用户账户的创建与管理
在MySQL中,可以使用 CREATE USER 语句来创建一个新的用户账户,并指定该用户的权限。创建新用户的命令如下:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
用户创建后,可以使用 GRANT 语句来赋予用户特定的权限,例如:
GRANT SELECT, INSERT ON database_name.* TO 'username'@'host';
5.2.2 权限的分配与撤销
权限的分配是指给用户授权,使其可以执行特定的操作。权限的撤销是指收回用户的权限。例如,如果需要撤销之前授予用户的权限,可以使用以下命令:
REVOKE SELECT, INSERT ON database_name.* FROM 'username'@'host';
用户账户的管理还包括密码的修改、用户的锁定和解锁等操作。例如,更新用户密码的命令为:
SET PASSWORD FOR 'username'@'host' = PASSWORD('new_password');
5.3 事务处理的实现与应用
5.3.1 事务的基本概念
事务是由一个或多个SQL语句组成的逻辑单元,这些语句要么全部执行,要么全部不执行。事务处理保证了数据库的完整性,MySQL使用事务来保证数据操作的ACID属性:
- 原子性(Atomicity):事务作为一个整体执行,要么全部完成,要么全部不完成。
- 一致性(Consistency):事务保证数据库的状态从一个一致状态转变到另一个一致状态。
- 隔离性(Isolation):事务之间的操作是隔离的,彼此不会互相影响。
- 持久性(Durability):一旦事务被提交,其结果就是永久性的。
5.3.2 高级事务控制技巧
MySQL支持两种事务控制的方法:自动提交模式和手动事务控制。在自动提交模式下,每个单独的SQL语句都被视为一个事务。手动事务控制使用 START TRANSACTION 或 BEGIN 语句开始一个事务,并使用 COMMIT 来提交事务,或者使用 ROLLBACK 来回滚事务。
START TRANSACTION;
-- 执行SQL语句
COMMIT;
5.4 存储过程和函数的编写与使用
5.4.1 存储过程的创建与调用
存储过程是预编译的SQL语句集合,可以接受参数并返回结果。创建存储过程的语法如下:
CREATE PROCEDURE procedure_name (IN/OUT parameter_name type)
BEGIN
-- SQL语句
END;
调用存储过程的语法是:
CALL procedure_name (value);
5.4.2 函数的定义与应用
函数类似于存储过程,但必须返回一个值。创建函数的语法如下:
CREATE FUNCTION function_name (param1 type, ...) RETURNS type
BEGIN
-- SQL语句
RETURN value;
END;
函数调用的语法是:
SELECT function_name (value);
5.5 触发器的定义与触发条件
5.5.1 触发器的概念与作用
触发器是一种特殊类型的存储过程,它会在INSERT、UPDATE或DELETE等数据库事件发生时自动执行。触发器可以用来审核操作、自动化复杂的数据校验等。
5.5.2 设计触发器的场景分析
设计触发器时,需要考虑触发器的事件类型和触发时间。例如,可以在插入新记录之前或之后执行触发器。创建触发器的基本语法是:
CREATE TRIGGER trigger_name
{BEFORE|AFTER} {INSERT|UPDATE|DELETE}
ON table_name FOR EACH ROW
BEGIN
-- SQL语句
END;
5.6 测试脚本的使用说明与注意事项
5.6.1 测试脚本编写原则
编写测试脚本时,应遵循以下原则:
- 确保测试用例覆盖所有主要功能。
- 测试脚本应保持简洁,易于理解和维护。
- 避免在测试脚本中使用硬编码值,使用变量或参数代替。
- 定期运行测试脚本,及时发现并解决问题。
5.6.2 测试脚本的维护与更新
随着项目的发展,需求可能会变更,新的功能可能会被添加。因此,测试脚本需要定期维护和更新以适应这些变化。更新测试脚本时,要确保:
- 新增的测试用例能够覆盖新功能或变更。
- 删除不再适用或重复的测试用例。
- 更新维护测试脚本的文档,记录变更。
通过遵循以上各点,可以确保测试脚本始终与项目保持同步,有效地进行质量控制。
简介:本文档是关于MySQL数据库的测试脚本,其中包含了一系列用于操作MySQL数据库的SQL语句。这些脚本可用于创建数据库、表,插入、查询、更新、删除数据,以及事务处理、权限管理、存储过程、触发器等高级功能。本文档还包含了 README.txt 文件,提供脚本使用说明和版本信息。在使用这些脚本进行数据库操作时,建议先备份数据,并掌握SQL语法和MySQL的最佳实践。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)