【3D目标检测】Part-A^2阅读笔记(2019)
1、为什么要做这个研究(理论走向和目前缺陷) ?2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?PointRCNN的主干网络用pointnet++提取点级特征,本文方法改为稀疏卷积版的U-net提取体素特征。比较有新意的就是在第一阶段对每个体素特征做部件位置预测,然后和原始提取的体素分割结果以及体素特征连接在一块做3D候选框的精细回归。3、发现了什么(总结结果,补充和理论的关系)?论文写
1、为什么要做这个研究(理论走向和目前缺陷) ?
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
PointRCNN的主干网络用pointnet++提取点级特征,本文方法改为稀疏卷积版的U-net提取体素特征。比较有新意的就是在第一阶段对每个体素特征做部件位置预测,然后和原始提取的体素分割结果以及体素特征连接在一块做3D候选框的精细回归。
3、发现了什么(总结结果,补充和理论的关系)?
论文写了很长,看似很多新名词其实都是之前已经有的东西稍微变换一下,不过效果挺好的。
摘要:本文方法是对之前的PointRCNN做的拓展,提出了point-based的包含部件感知阶段(第一阶段)和部件聚合阶段(第二阶段)的Part-A2网络。部件感知阶段用于预测3D候选框和部件位置。同一个候选区内的部件点通过一个新的点云池化方法(RoI-aware point cloud pooling)组合在一块形成候选区特征。部件聚合阶段(第二阶段)对候选框位置精细化。
1、引言(略)
2、相关研究(略)
3、所提出的方法
模型总图: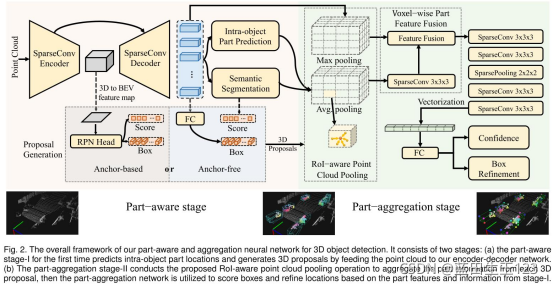
之前的PointRCNN是第一阶段和第二阶段网络分开训练的,到本文时可以同时训练。
部件位置定义:3D点相对与其所属3D框的位置。
3.1 第一阶段:部件感知的3D候选区
部件感知阶段可以为前经典评估其部件位置同时生成3d候选区。候选区生成过程中有两种方式:anchor-based和achor-free。
3.1.1 利用稀疏卷积计算点级特征
这里的点级特征其实是体素级特征,即把每个体素视为一个点。这样就不是向pointRCNN一样用PointNet++来提取点级特征,而是用u-net型的稀疏3D卷积在非空体素上提取体素级特征,这样实际提取的体素级特征可以视为是每个非空体素中心的“点级特征”,这样做更加高效,且几乎跟用pointnet++提取的点级特征效果差不多,甚至召回率比PointNet++还要高。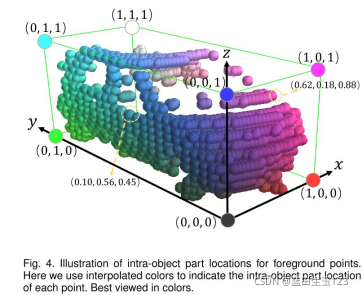
3.1.2 预测前景点和部件位置
前背景点分类和部件位置预测可以为3D目标预测更加丰富的信息。其实可立即为根据候选框及其朝向建立局部坐标系,基于此坐标系计算每个点(其实是体素)的位置,可结合上图理解下部件位置表达式
前背景点分割用的focal loss,前景点的部件位置预测用的是交叉熵损失。
3.1.3 3D候选框生成
基于预测的每个前景点(体素)的部件位置信息和点(体素)特征来进行组合生成3D候选框,为每个体素生成3d候选框的过程中,分割结果和部件位置预测结果是不参与的。在这里尝试了两种方法预测3d候选框:anchor-based和Anchor-free。
anchor-free方案(表示为Part-A2-free)的候选区生成:基于bin的方式预测障碍物中心位置,参考PointRCNN。
anchor-based方案:就是常见的编码方案。
3.2 roi感知的点云特征池化方法
就是roi pooling。对每个3D候选区内的点云(体素)特征做roi pooling。
3.3 第二阶段:部件位置聚合实现3D框精细化
每个3D候选区里的点云特征池化了,但是第一阶段得到的点云分割标签和部件位置预测结果还没池化,这里就是把这两个预测结果连接在一块形成F1(3D候选区内),把之前的主干网络预测3D候选区的点级特征F2(同一个3D候选区内),然后F经过一个稀疏卷积之后和F2连接在一起,再进入一系列稀疏卷积做最终的回归和分类。参照模型总图右侧部分理解。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)